文章目录
- 前言
- 一、获取cookie
- 二、程序实现
- 三、动态获取cookie
- 四、其他
- 关于Python爬虫技术储备
- 一、Python所有方向的学习路线
- 二、Python基础学习视频
- 三、精品Python学习书籍
- 四、Python工具包+项目源码合集
- ①Python工具包
- ②Python实战案例
- ③Python小游戏源码
- 五、面试资料
- 六、Python兼职渠道
前言
很多时候,我们要查看的内容必须要先登录才能找到,比如知乎的回答,QQ空间的好友列表、微博上关注的人和粉丝等。要使用爬虫直接登录抓取这些信息时,有一个不太好解决的难题,就是这些网站设置的登录规则以及登录时的验证码识别。不过,我们可以想办法绕过去,思路是这样的:先使用浏览器登录,从浏览器获取登录后的“凭证”,然后将这个“凭证”放到爬虫里,模拟用户的行为继续抓取。这里,我们要获取的凭证就是cookie信息。
这次我们尝试使用python和cookie来抓取QQ空间上的好友列表。使用的工具是FireFox浏览器、FireBug和Python。

一、获取cookie
打开FireFox浏览器,登录QQ空间,启动FireBug,选择FireBug中的Cookies页签,点击页签中的cookies按钮菜单,选择“导出本站点的cookie”即可完成cookie的导出。
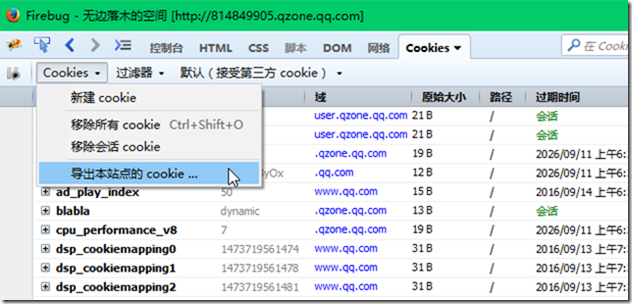
导出cookie会以一个名为cookies.txt文本文件形式存在。
二、程序实现
然后我们会使用获取的cookie新建一个opener来替换之前请求时使用的默认的opener。将获取的cookies拷贝到程序目录下,编写脚本如下:
#!python
# encoding: utf-8
from http.cookiejar import MozillaCookieJar
from urllib.request import Request, build\_opener, HTTPCookieProcessor
DEFAULT\_HEADERS = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0"}
DEFAULT\_TIMEOUT = 360
def grab(url):
cookie = MozillaCookieJar()
cookie.load('cookies.txt', ignore\_discard=True, ignore\_expires=True)
req = Request(url, headers=DEFAULT\_HEADERS)
opener = build\_opener(HTTPCookieProcessor(cookie))
response = opener.open(req, timeout=DEFAULT\_TIMEOUT)
print(response.read().decode('utf8'))
if \_\_name\_\_ == '\_\_main\_\_':
grab(<a href="http://user.qzone.qq.com/QQ号/myhome/friends" rel="external nofollow" >http://user.qzone.qq.com/QQ号/myhome/friends</a>)
因为我们使用的是FireFox浏览器导出的cookie文件,所以这里使用的cookieJar是MozillaCookieJar。
执行脚本…然而报错了:
Traceback (most recent call last):
File "D:/pythonDevelop/spider/use\_cookie.py", line 17, in <module>
start()
File "D:/pythonDevelop/spider/use\_cookie.py", line 9, in start
cookie.load('cookies.txt', ignore\_discard=True, ignore\_expires=True)
File "D:\\Program Files\\python\\python35\\lib\\http\\cookiejar.py", line 1781, in load
self.\_really\_load(f, filename, ignore\_discard, ignore\_expires)
File "D:\\Program Files\\python\\python35\\lib\\http\\cookiejar.py", line 2004, in \_really\_load
filename)
http.cookiejar.LoadError: 'cookies.txt' does not look like a Netscape format cookies file
问题出在cookies文件上,说是不像一个Netscape格式的cookie文件。不过也好解决,只需要在cookies文件开始一行添加如下内容即可:
\# Netscape HTTP Cookie File
通过这行内容提示python cookie解析器这是一个FireFox浏览器适用的cookie。
再次执行,还是会报错,因为比较长我就只贴关键的部分出来:
http.cookiejar.LoadError: invalid Netscape format cookies file 'cookies.txt': '.qzone.qq.com\\tTRUE\\t/\\tFALSE\\tblabla\\tdynamic'
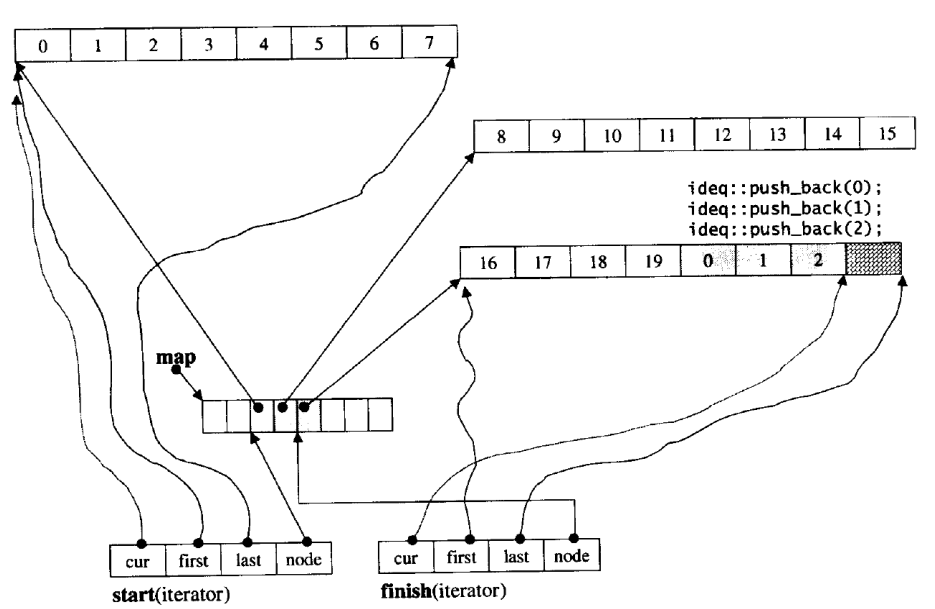
意思是cookie中某些行存在格式错误。具体错在哪儿,需要先了解下FireFox浏览器的cookie格式。MozillaCookieJar认为每行cookie需要包含以下信息,每条信息以制表符分隔:
| 名称 | domain | domain_specified | path | secure | expires | name | value |
| 类型 | 字符串 | 布尔型 | 字符串 | 布尔型 | 长整型 | 字符串 | 字符串 |
| 说明 | 域名 | — | 适用路径 | 是否使用安全协议 | 过期时间 | 名称 | 值 |
其中domain_specified是什么意思我不很清楚,以后弄明白了再补上。再来看看我们获取的cookie的部分行:
user.qzone.qq.com FALSE / FALSE 814849905\_todaycount 0
user.qzone.qq.com FALSE / FALSE 814849905\_totalcount 0
.qzone.qq.com TRUE / FALSE 1473955201 Loading Yes
.qzone.qq.com TRUE / FALSE 1789265237 QZ\_FE\_WEBP\_SUPPORT 0
前两行格式是错误的,后两行格式是正确的。前两行缺少“expires”属性。该怎么办呢——补上就好了呗。在其他的cookie中随意选一个时间补上就OK了。
补全cookie后,再次执行是正常的,没有报错。但是没有如预期的打印出好友信息,因为网址错了。使用firebug可以找出正确的网址:
https://h5.qzone.qq.com/proxy/domain/r.qzone.qq.com/cgi-bin/tfriend/friend\_ship\_manager.cgi?uin=QQ号&do=1&rd=0.44948123599838985&fupdate=1&clean=0&g\_tk=515169388
这样就抓取到好友列表了。好友列表是一个json字符串。
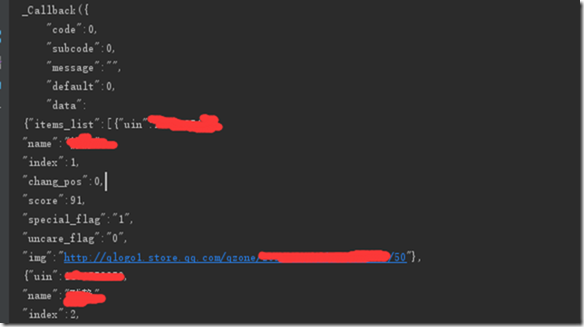
至于如何解析json,会在下一节进行说明。
三、动态获取cookie
cookie是有过期时间的。如果想长时间抓取网页,就需要每隔一段时间就更新一次cookie。如果都是从FireFox浏览器来手动获取显得有些笨了。从浏览器获取的cookie只是作为一个入口,之后再进行请求还是要依靠python主动获取cookie。下面是一段获取cookie的程序:
#!python
# encoding: utf-8
from http.cookiejar import CookieJar
from urllib.request import Request, HTTPCookieProcessor, build\_opener
DEFAULT\_HEADERS = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0"}
DEFAULT\_TIMEOUT = 360
def get(url):
cookie = CookieJar()
handler = HTTPCookieProcessor(cookie)
opener = build\_opener(handler)
req = Request(url, headers=DEFAULT\_HEADERS)
response = opener.open(req, timeout=DEFAULT\_TIMEOUT)
for item in cookie:
print(item.name + " = " + item.value)
response.close()
在示例程序中演示了如何获取cookie,并打印了cookie的name和value两项属性。通过实例可以看到每次执行http请求都会重新获取cookie,因此可以将我们的程序调整一下:执行第一次请求时使用我们通过浏览器获取的cookie,之后的每次请求都可以使用上次请求时获取的cookie。调整后的程序:
#!python
# encoding: utf-8
from http.cookiejar import MozillaCookieJar, CookieJar
from urllib.request import Request, build\_opener, HTTPCookieProcessor, urlopen
DEFAULT\_HEADERS = {"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0"}
DEFAULT\_TIMEOUT = 360
def gen\_login\_cookie():
cookie = MozillaCookieJar()
cookie.load('cookies.txt', ignore\_discard=True, ignore\_expires=True)
return cookie
def grab(cookie, url):
req = Request(url, headers=DEFAULT\_HEADERS)
opener = build\_opener(HTTPCookieProcessor(cookie))
response = opener.open(req, timeout=DEFAULT\_TIMEOUT)
print(response.read().decode("utf8"))
response.close()
def start(url1, url2):
cookie = gen\_login\_cookie()
grab(cookie, url1)
grab(cookie, url2)
if \_\_name\_\_ == '\_\_main\_\_':
u1 = "https://user.qzone.qq.com/QQ号/myhome/friends"
u2 = "https://h5.qzone.qq.com/proxy/domain/r.qzone.qq.com/cgi-bin/tfriend/friend\_ship\_manager.cgi?uin=QQ号&do=2&rd=0.44948123599838985&fupdate=1&clean=0&g\_tk=515169388"
start(u1, u2)
就这样。
四、其他
其实在登录QQ空间时使用cookie还有另一种法子——通过观察,也可以在http 请求头中添加cookie信息。
获取请求头中cookie的方式:打开FireFox浏览器,打开FireBug并激活FireBug的network页签,在FireFox浏览器上登录QQ空间,然后在FireBug中找到登录页请求,然后就可以找到请求头中的cookie信息了。
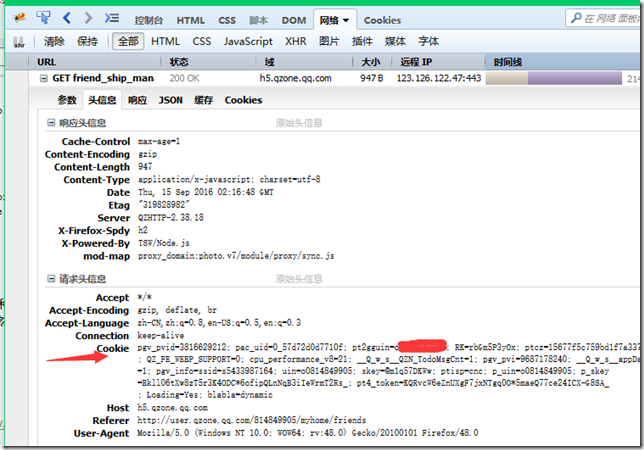
将cookie信息整理成一行,添加到请求头中就可以直接访问了。这个方法相对简单,减少了修改cookie文件的步骤。这算是已知最好的法子了,只要腾讯不改变登录规则就能很简单的执行请求获取cookie。不过年代久远,不知规则是否还适用。(案例仅提供思路,网站不断在更新
关于Python爬虫技术储备
学好 Python爬虫 不论是就业还是做副业赚钱都不错,但要学会 Python 还是要有一个学习规划。最后大家分享一份全套的 Python 学习资料,给那些想学习 Python 的小伙伴们一点帮助!
保存图片微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、Python所有方向的学习路线
Python所有方向的技术点做的整理,形成各个领域的知识点汇总,它的用处就在于,你可以按照上面的知识点去找对应的学习资源,保证自己学得较为全面。
二、Python基础学习视频
② 路线对应学习视频
还有很多适合0基础入门的学习视频,有了这些视频,轻轻松松上手Python~在这里插入图片描述

③练习题
每节视频课后,都有对应的练习题哦,可以检验学习成果哈哈!

因篇幅有限,仅展示部分资料
三、精品Python学习书籍
当我学到一定基础,有自己的理解能力的时候,会去阅读一些前辈整理的书籍或者手写的笔记资料,这些笔记详细记载了他们对一些技术点的理解,这些理解是比较独到,可以学到不一样的思路。
四、Python工具包+项目源码合集
①Python工具包
学习Python常用的开发软件都在这里了!每个都有详细的安装教程,保证你可以安装成功哦!
②Python实战案例
光学理论是没用的,要学会跟着一起敲代码,动手实操,才能将自己的所学运用到实际当中去,这时候可以搞点实战案例来学习。100+实战案例源码等你来拿!
③Python小游戏源码
如果觉得上面的实战案例有点枯燥,可以试试自己用Python编写小游戏,让你的学习过程中增添一点趣味!
五、面试资料
我们学习Python必然是为了找到高薪的工作,下面这些面试题是来自阿里、腾讯、字节等一线互联网大厂最新的面试资料,并且有阿里大佬给出了权威的解答,刷完这一套面试资料相信大家都能找到满意的工作。


六、Python兼职渠道
而且学会Python以后,还可以在各大兼职平台接单赚钱,各种兼职渠道+兼职注意事项+如何和客户沟通,我都整理成文档了。


这份完整版的Python全套学习资料已经上传CSDN,朋友们如果需要可以保存图片微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】