👉博__主👈:米码收割机
👉技__能👈:C++/Python语言
👉公众号👈:测试开发自动化【获取源码+商业合作】
👉荣__誉👈:阿里云博客专家博主、51CTO技术博主
👉专__注👈:专注主流机器人、人工智能等相关领域的开发、测试技术。

python天气数据抓取与数据分析(源码+论文)【独一无二】
目录
- python天气数据抓取与数据分析(源码+论文)【独一无二】
- 一、项目概述
- 二、项目环境需求
- 三、数据库设计
- 1)数据库设计概述
- 2)逻辑结构设计(E-R图)
- 3)物理结构设计数据表
- 四、数据获取实现
- 4.1 网络请求
- 4.2 数据解析
- 4.3 提取具体数据
- 五、数据存储
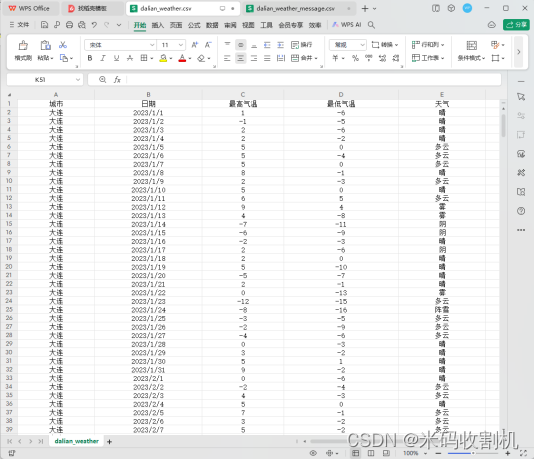
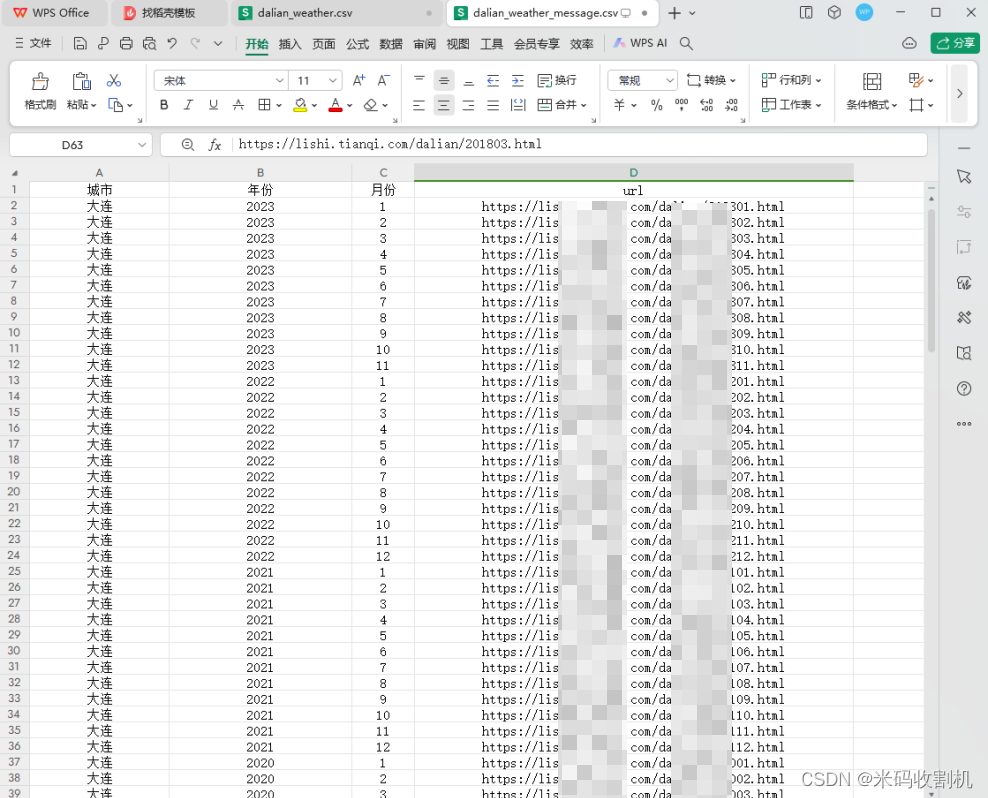
- 5.1. CSV文件存储
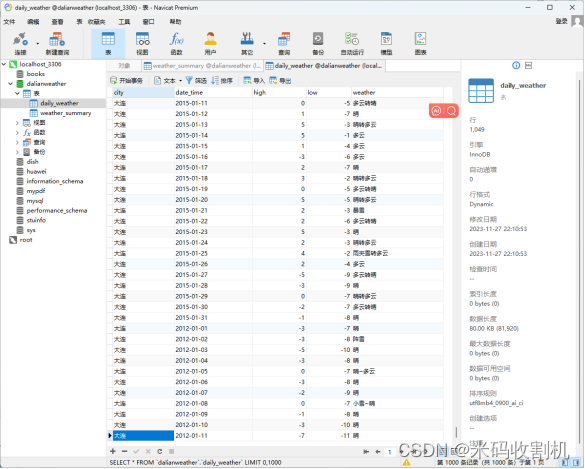
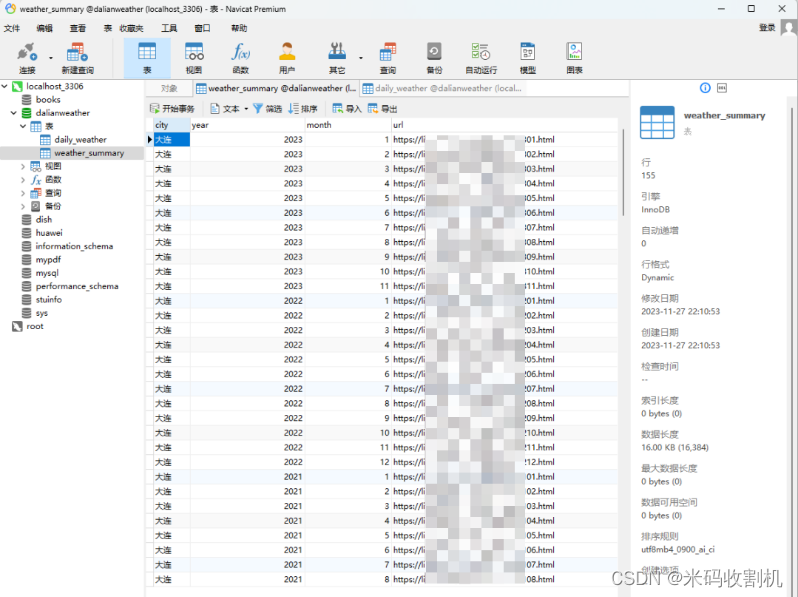
- 5.2 SQL数据库存储
- 6. 数据呈现
- 7. 数据分析
- (1)统计各类天气所占比例
- (2)统计每年中气温最高的日期
- (3)统计每年气温的平均值
- (4)最高气温与最低气温的散点图
- (5) 统计最高气温分布的箱线图
一、项目概述
本项目包括四个核心部分:数据爬取、数据存储、数据分析和数据可视化。首先,利用Python编写的网络爬虫从专业的历史天气网站上爬取大连市从2011年至2023年的天气数据,包括日期、最高气温、最低气温和天气状况等信息。爬取过程中应用了requests库来模拟浏览器请求和lxml库来解析HTML文档,确保了数据的准确性和完整性。接着,将爬取到的数据存储在两个CSV文件中,并利用pymysql库将数据导入MySQL数据库,便于后续的数据处理和分析。在数据分析阶段,使用pandas库对CSV中的数据进行读取和处理,计算出如每年的平均气温、最高气温的日期等关键统计信息。最后,利用pyecharts库将分析结果以图表的形式进行可视化展示,生成了五种图表:各类天气所占比例的饼图、每年最高气温的日期折线图、每年平均气温的柱状图、最高气温与最低气温的散点图和最高气温分布的箱线图。
二、项目环境需求
- 开发环境:Python3.7
- 运行系统:Windows
- 软件:Pycharm
三、数据库设计
1)数据库设计概述
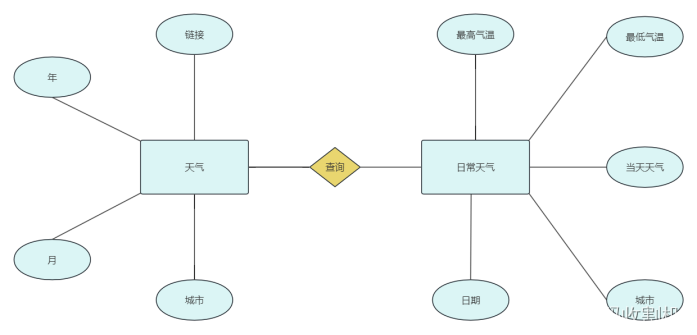
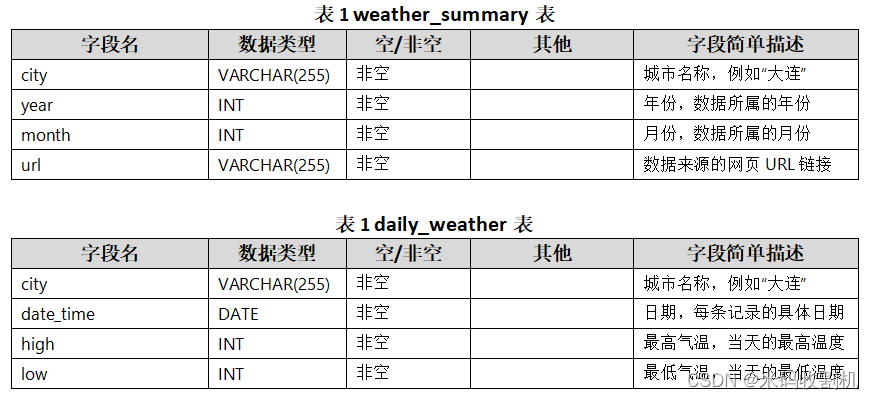
本项目的数据库设计关键在于有效地组织和存储从网上爬取的大连市历史天气数据。为了实现这一目标,设计了两个主要的数据表:weather_summary和daily_weather,以及相应的字段来存储和索引数据。这些设计考虑到了数据的完整性、查询效率和易于理解性。
weather_summary 表:
此表用于存储每个月的天气摘要信息,包括城市名、年份、月份以及对应的网页URL。
字段设计:
- city (VARCHAR(255)):城市名称,存储城市名,如“大连”。
- year (INT):年份,存储数据所属的年份。
- month (INT):月份,存储数据所属的月份。
- url (VARCHAR(255)):URL地址,存储爬取该月数据的网页链接。
这个表有助于快速定位某个特定时间段的天气数据来源和基本信息。
daily_weather 表:
此表更加详细,用于存储每天的天气数据,包括城市、日期、最高气温、最低气温和天气状况。
字段设计:
- city (VARCHAR(255)):城市名称。
- date_time (DATE):日期,存储每条记录对应的具体日期。
- high (INT):最高气温,存储当天的最高气温值。
- low (INT):最低气温,存储当天的最低气温值。
- weather (VARCHAR(255)):天气,存储当天的天气情况描述。
该表的设计允许进行详细的日常天气数据分析,如温度变化、极端天气事件等。
关注公众号,回复 “天气数据抓取” 获取源码
2)逻辑结构设计(E-R图)
3)物理结构设计数据表
四、数据获取实现
4.1 网络请求
使用requests库发起HTTP GET请求到目标网站。这里的目标网站是以https://lishi.xxx.com/xxx/YYYYMM.html格式的URL,其中YYYY和MM分别代表年份和月份。
为了避免被网站服务器识别为爬虫,代码中设置了请求头headers,其中包含一个User-Agent,模仿常见浏览器的身份。
4.2 数据解析
使用lxml库对响应的HTML内容进行解析。lxml是一个强大的库,可以处理HTML和XML文档,支持XPath查询语言,用于提取HTML文档中的数据。
代码中利用etree.HTML(resp.text)将获取的HTML文本转换成了lxml的HTML对象,方便后续使用XPath进行数据提取。
4.3 提取具体数据
通过XPath定位HTML文档中存储天气数据的部分,具体是寻找类名为thrui的ul元素下的所有li元素。对于每个li元素,代码进一步提取了日期(date_time)、最高气温(high)、最低气温(low)和天气状况(weather)。
数据清洗:提取的气温数据中包含了摄氏度符号(℃),代码中通过字符串操作去除这个符号,只保留温度的数值部分。
主要代码如下:
weather_info = [] # 新建一个列表,将爬取的每月数据放进去
# 请求头信息:浏览器版本型号,接收数据的编码格式
headers = {
# 必填,不填拿不到数据
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/14.0.835.163 Safari/535.1'
}
# 请求 接收到了响应数据
resp = requests.get(url, headers=headers)
# 数据预处理
resp_html = etree.HTML(resp.text)
# xpath提取所有数据
resp_list = resp_html.xpath("//ul[@class='thrui']/li")
# for循环迭代遍历
五、数据存储
5.1. CSV文件存储
在项目中,CSV文件存储是数据管理的重要环节,利用Python的标准库csv实现。这一过程首先通过open()函数打开或创建一个CSV文件,如dalian_weather.csv,以便写入数据。这种文件格式的普遍兼容性使其成为数据共享和轻量级存储的理想选择。在写入数据之前,通过csv.writer()函数创建一个写入器对象,它是后续所有CSV操作的核心。
👇👇👇 关注公众号,回复 “天气数据抓取” 获取源码👇👇👇
weathers = []
message = []
for year in ['2023', '2022', '2021', '2020', '2019', '2018', '2017', '2016', '2015', '2014', '2013', '2012', '2011']:
# for循环生成有顺序的1-12
for month in range(1, 13):
try:
# ... 忽略 ...
urls = {
f'https://xxx.xxx.com/xxx/{weather_time}.html': '大连'
}
for url, city in urls.items():
# 爬虫获取这个月的天气信息
weather = getWeather(city, url)
# 存到列表中
weathers.append(weather)
message.append([city, year, month, url])
except Exception as e:
continue
print(weathers)
print(message)
# 数据写入(一次性写入)
with open("dalian_weather.csv", "w", newline='') as csvfile:
writer = csv.writer(csvfile)
# 先写入列名:columns_name 日期 最高气温 最低气温 天气
writer.writerow(["城市", "日期", "最高气温", "最低气温", '天气'])
# 一次写入多行用writerows(写入的数据类型是列表,一个列表对应一行)
writer.writerows([list(day_weather_dict.values()) for month_weather in weathers for day_weather_dict in month_weather])
# 数据写入(一次性写入)
with open("dalian_weather_message.csv", "w", newline='') as csvfile:
writer = csv.writer(csvfile)
# 先写入列名:columns_name 日期 最高气温 最低气温 天气
writer.writerow(["城市", "年份", "月份", "url"])
# 一次写入多行用writerows(写入的数据类型是列表,一个列表对应一行)
writer.writerows(message)
5.2 SQL数据库存储
SQL数据库存储部分是项目中处理和维护大规模数据集的关键。使用pymysql库与MySQL数据库建立连接,此过程涉及数据库的基本操作,如创建表格、插入数据和事务管理。在数据存储的初始阶段,代码通过执行SQL语句创建weather_summary和daily_weather两个数据表,这些表格的设计旨在准确地反映天气数据的结构和关系。其中,weather_summary表存储每个月的天气摘要。
# 第一组数据插入 weather_summary 表
with conn.cursor() as cursor:
sql = "INSERT INTO weather_summary (city, year, month, url) VALUES (%s, %s, %s, %s)"
cursor.executemany(sql, message)
# 第二组数据插入 daily_weather 表
data2 = []
for month_data in weathers:
for day_data in month_data:
record = (day_data['city'], day_data['date_time'], day_data['high'], day_data['low'], day_data['weather'])
6. 数据呈现
关注公众号,回复 “天气数据抓取”
7. 数据分析
(1)统计各类天气所占比例
首先,使用pandas库中的value_counts()方法来统计df[‘天气’]列中各个唯一天气类型的出现次数。这个方法返回一个新的Series对象,其索引是唯一的天气类型,值是每种天气类型的出现次数。接下来,使用pyecharts库中的Pie类创建一个饼图对象。Pie类是一个专门用于生成饼图的类,能够轻松地实现数据的可视化。
关注公众号,回复 “天气数据抓取” 获取源码
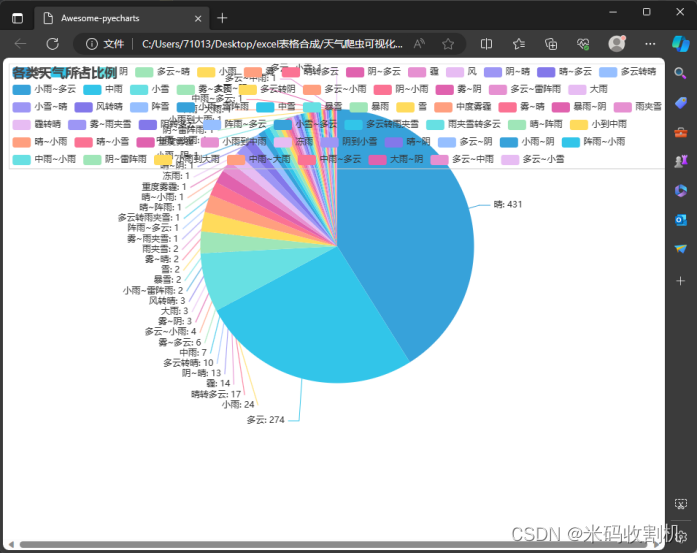
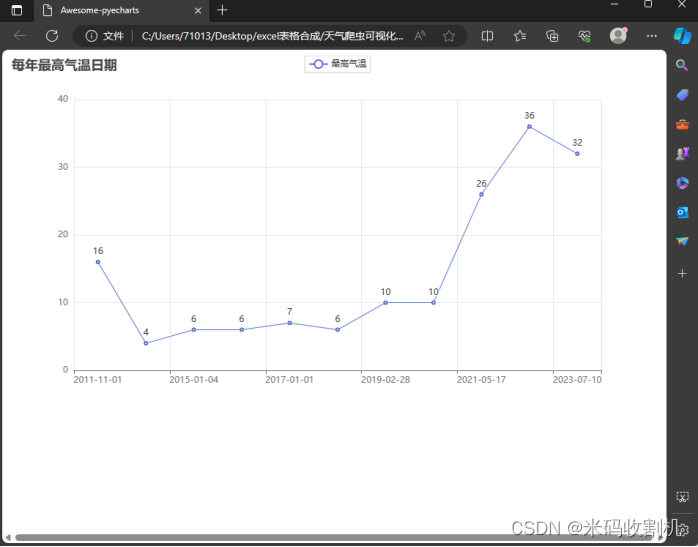
(2)统计每年中气温最高的日期
首先,代码通过pd.to_datetime(df[‘日期’])将df中的’日期’列转换为pandas的DateTime对象。这种转换对于后续的日期处理和分析至关重要,因为它允许使用丰富的日期时间函数。利用DateTime对象的dt属性,代码提取了每条记录的年份信息,并将其存储在新的列’年份’中。这样做便于按年份对数据进行分组和分析。使用groupby(‘年份’)对数据按年份进行分组,然后对每个分组应用idxmax()函数来找出最高气温出现的索引(即日期)。idxmax()函数返回的是最高气温值所在行的索引。
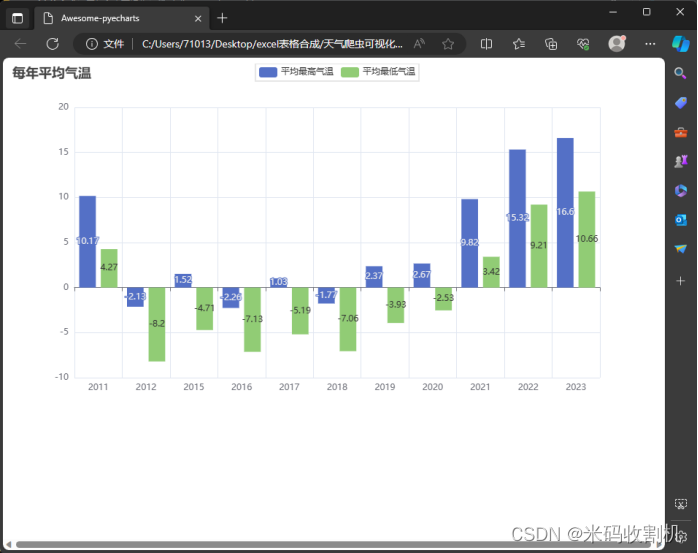
(3)统计每年气温的平均值
使用groupby(‘年份’)对df中的数据按照’年份’列进行分组。这意味着数据将根据年份被组织起来,每个组包含该年份的所有数据记录。接着,应用agg函数对分组后的数据进行聚合计算。在这里,针对每个年份组,分别计算’最高气温’和’最低气温’的平均值(mean)。这一步骤提供了每年的平均最高气温和平均最低气温的关键数据。
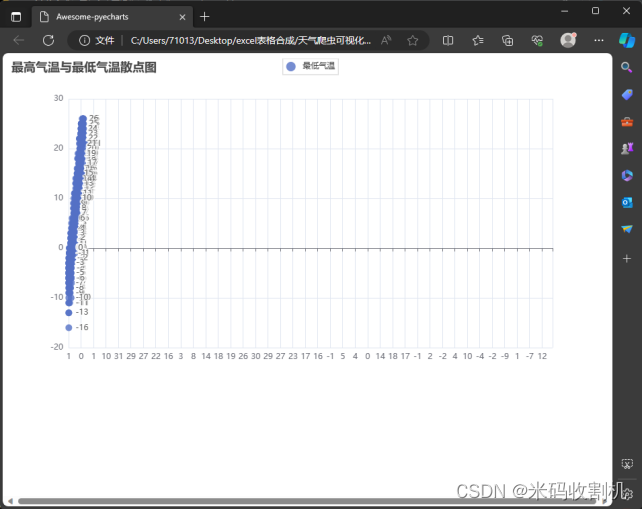
(4)最高气温与最低气温的散点图
通过绘制一个散点图来探索最高气温和最低气温之间的关系。以下是对这部分代码的详细分析,使用pyecharts库中的Scatter类来创建一个散点图对象。散点图是用于展示两个变量之间关系的理想图表,特别适合于揭示变量之间的相关性或模式。通过Scatter()构造函数初始化了一个散点图实例。
设置X轴和Y轴数据使用add_xaxis()方法设置X轴数据,这里选择了df[‘最高气温’]作为X轴数据,它代表数据集中记录的每天的最高气温。
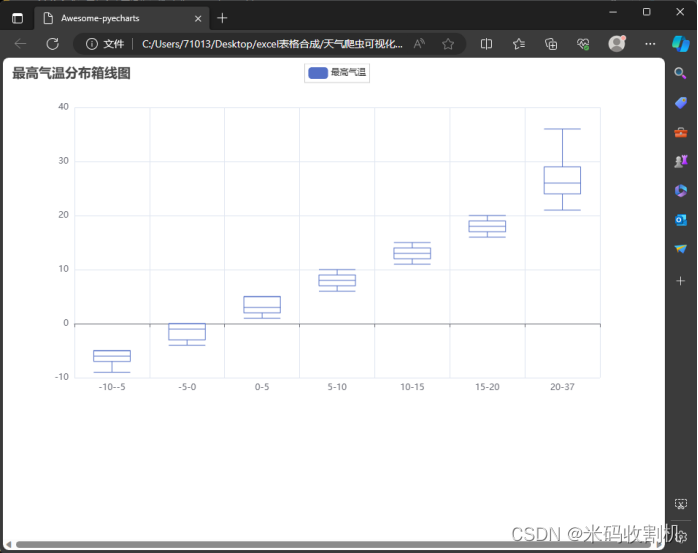
(5) 统计最高气温分布的箱线图
创建温度区间,利用pandas的cut函数,代码首先定义了一系列温度区间(temp_bins),这些区间用于对最高气温数据进行分类。这些区间从-10℃开始,每个区间的跨度不同,直到超过数据集中的最高气温。pd.cut函数将df[‘最高气温’]中的每个值分配到这些预定义的区间中。结果存储在新的列’温度区间’中,为每个最高气温值标记了对应的温度区间。
👇👇👇 关注公众号,回复 “天气数据抓取” 获取源码👇👇👇