1 背景
数据服务与数据分析场景是数据团队在数据应用上两个大的方向,行业内大家有可能会遇到下面的问题:
1.1 数据服务
- 烟囱式开发模式:每来一个需求开发一个数据服务,数据服务无法复用,难以平台化,技术上无法积累
- 服务维护难度大:当开发了大量数据服务后,后期维护是大问题,尤其是618、双11大促期间,在没有统一的监控、限流、灾备方案的情况下一个人维护上百个数据服务是一件很痛苦的事,也造成了很大的安全隐患
- 业务需求量大:数据开发的同学常常会被大量重复枯燥的数据服务开发束缚,大量的时间投入在业务数据服务开发中
1.2 数据分析
- 找数据难:用户难以找到自己想要,即便找到名称相近的指标或数据,由于指标口径不明确也不统一也无法直接使用
- 用数难:由于目前数据分布在各个系统中,用户无法用一个系统满足所有的数据需求。特别是一线运营人员要通过每个从各个系统导出大量Excel的方式做数据分析,费时费力,同时也造成数据安全隐患
- 查询慢:用传统的Olap引擎,用户跑SQL往往需要几分钟才出结果,大大降低了分析人员的效率。
- 查询引擎不统一:系统可能有多种查询引擎组成,每一种查询引擎都有自己的DSL,增大了用户的学习成本,同时需要跨多数据源查询也是一件很不方便的事。异构查询引擎带来的另一个问题是形成了数据孤岛,各系统间的数据之间无法相互关联
- 数据实时更新:传统离线T+1方式数据更新已经无法满足当今的实时化运营的业务诉求,这就要求系统需要到达秒级别的延迟
除了以上问题,数据服务和数据分析系统也是无法统一,分析产生的数据结果往往是离线的,需要额外开发数据服务,无法快速转化为线上服务赋能外部系统,使得分析和服务之间难以快速形成闭环。而且在以往数据加工过程中存储往往只考虑了当时的需求,当后续需求场景扩展,最初的存储引擎可能不适用,导致一份数据针对不同的场景要存储到不同的存储引擎,带来数据一致性隐患和成本浪费问题。
2 基于StarRocks 的数据服务分析一体化实践
基于以上这些业务痛点京东物流运营数据产品团队研发了服务分析一体化系统——UData(Universal Data),UData系统是以StarRocks引擎为技术基础的实现的。UData把数据指标生成的过程抽象出来,用配置的方式低代码化生成数据服务,大大降低的开发复杂性和难度,让非研发同学也可以根据自己的需求配置和发布自己数据服务,指标的开发时间由之前的一两天缩短为30分钟,大大解放了研发力。平台化的指标管理体系和数据地图的功能,让用户更加直观和方便地查找与维护指标,同时也让指标复用变成可能。
在数据分析方面,我们用基于StarRocks的联邦查询方案打造了UData统一查询引擎,解决了查询引擎不统一和数据孤岛问题,同时StarRocks提供了强悍的数据查询性能,无论是大宽表还是多表关联查询性能都十分出色。StarRocks提供数据实时摄入的能力和多种实时数据模型,可以很好的支持数据实时更新场景。UData系统把分析和服务结合在一起,让分析和服务不再是分割的两个过程,用户分析出有价值的数据后可以立即生成对应的数据服务,让服务分析快速闭环。
数据流程架构图:
改造前的架构:

图1 改造前架构图
改造前实时数据由JDQ(京东日志消息队列,类似Kafka)和JMQ导入Flink做实时数据加工,加工后数据写入Clickhouse和ElasticSearch,为数据服务和数据分析提供Olap查询服务。离线数据由Spark做个数仓层级加工,APP层数据会同步至Mysql或Clickhouse做Olap查询。此架构中,在数据服务和数据分析是两个分隔的部分,分析工具由于要跨多数据源和不同的查询语言做数据分析比较困难的,数据服务也是烟囱式开发。
改造后的架构:

图2 改造后的架构
改造后,我们在数据存储层引入了StarRocks,StarRocks提供了极速的单表和多表查询能力,同时以StarRocks为基础我们打造了统一查询引擎,统一查询引擎根据京东的业务特点增加数据源和聚合下推等功能,UData在统一查询引擎的基础上统一了数据分析和数据服务功能。
打造一款数据服务分析一体化系统对查询引擎有比较高的要求,需要同时满足:极速的查询性能、支持联邦查询、实时与离线存储统一。基于这三点要求,下面我们就StarRocks极速的查询性能的原因、我们对联邦查询的改造、实时场景的实践展开讨论。
2.1 StarRocks极速的查询性能的原因
极速查询的单表查询:
StarRocks在极速查询方面上做了很多,下面着重介绍下面四点:
- 向量化执行:StarRocks实现了从存储层到查询层的全面向量化执行,这是SR在速度上优势的基础。向量化执行充分发挥了CPU的处理能力。全面向量化引擎按照列式的方式组织和处理数据。StarRocks的数据存储、内存中数据的组织方式,以及SQL算子的计算方式,都是列式实现的。按列的数据组织也会更加充分的利用CPU的Cache,按列计算会有更少的虚函数调用以及更少的分支判断从而获得更加充分的CPU指令流水。另一方面,StarRocks的全面向量化引擎通过向量化算法充分的利用CPU提供的SIMD指令。这样StarRocks可以用更少的指令数目,完成更多的数据操作。经过标准测试集的验证,StarRocks的全面向量化引擎可以将执行算子的性能,整体提升3—10倍。
- 物化视图加速查询:在实际分析场景中,我们经常遇到分析上百亿的大表情况,尽管SR性能优异但数据量过大查询速度还是有影响的,此时在用户经常聚合的维度加上了物化视图,在不用改变查询语句的情况下查询速度提升10倍以上,SR智能化的物化视图可以让请求自动匹配视图,无需手动查询视图。
- CBO:CBO(Cost-based Optimizer ) 优化器采用 Cascades 框架,使用多种统计信息来完善成本估算,同时补充逻辑转换(Transformation Rule)和物理实现(Implementation Rule)规则,能够在数万级别执行计划的搜索空间中,选择成本最低的最优执行计划。
- 自适应低基数优化:StarRocks可以自适的根据数据分布,对低基数的字符串类型的列构建一张全局字典,用Int类型做存储和查询,使得内存开销更小,有利于SIMD指令执行,加快了查询速度。与此对应Clickhouse也有LowCardinality方式优化,只是需要在建表时候需要声明,使用起来会麻烦一些。
极速的多表关联:
在实时数据分析场景中只满足单表极速查询是不够的,目前为了加速查询速度行业内习惯于把多张表打成一张大宽表,大宽表虽随度快,但是带来的问题是极其不灵活,实时数据加工层是用flink将多表 join成一张表写入大宽表,当业务方想修改或增加分析维度时往往数据开发周期过长,数据加工完成后发现已经错过了分析最佳时机。所以需要更灵活的数据模型,比较理想的方法是把大宽表模式退归回星型模型或者雪花模型。在此场景下查询引擎对多表数据关联查询的性能成了关键,以往clickhouse以大宽表为主,多表联查情况下无法保证查询相应时间,甚至有很大几率出现OOM。SR很好解决了这个问题,大表join性能提升3~5倍以上,成为星型模型分析利器。CBO(Cost-based Optimizer )是多表关联极致性能关键,同时StarRocks 支持Broadcost Join、Shuffle Join、Bucket shuffle Join、Colocated Join、Replicated Join等多种join方式,CBO可以智能的选择join顺序和join方式。
2.2 对StarRocks联邦查询的改造
在存储层层由于需求、场景、历史等原因是很难做到真正统一的存储的,在过去的数据服务开发中由于存储层不统一、数据库查询语法不同,开发基本是烟囱式开发,已开发的指标很难复用,也很难管理大量的已开发指标。联邦查询可以很好的解决这个问题,使用统一的查询引擎屏蔽了不同olap的引擎的专有DSL,大大提升了开发效率和学习成本,同时可以用ONE SQL方式整合来自不同数据源的指标形成新的指标,从而提高了指标的复用性。StarRocks外表扩展功能让它具备了实现联邦查询的基础,但细节上我们有一些自己的业务需求。
StarRocks在联邦查询上支持了多种外表如ES、Mysql、hive、数据湖等,已经有了很好的联邦查询的基础。不过在实际的业务场景需求中,一些聚合类的查询需要从外部数据源拉取数据再聚合,而且这些数据源自身的聚合性能也不错,这反而增加了查询时间。我们的思路是让这部分擅长聚合的引擎自己做聚合,把聚合操作下推到外部引擎,目前符合这个优化条件的引擎有:Mysql、ElasticSearch、Clickhouse。同时为了兼容更多的数据源,我们还增加了 JSF(京东内部RPC服务)/HTTP 数据源,下面简单介绍下这两部分:
1.Mysql、ElasticSearch的聚合下推功能
现在StarRocks对于聚合外部数据源的方案是拉取谓词下推后的全量的数据,虽然谓词下推后已经过滤一部分数据但是把数据拉取到StarRocks再聚合是一个很重的操作,导致聚合时间不理想。我们的思路是下推聚合操作,让外部表引擎自己做聚合,节省数据拉取时间,同时本地化聚合效率更高。聚合下推的优化在某些场景下有10倍以上的性能提升。

图3 物理计划优化图
在物理执行计划层我们做了再次优化,当遇到ES、Mysql、clickhouse的聚合造作时,会把ScanNode+AGGNode的执行计划优化为QueryNode,QueryNode为一种特殊的ScanNode,与普通的ScanNode区别为QueryNode会直接把聚合查询请求直接发送到对应外部引擎,而不是scan数据后在本地执行聚合。其中EsQueryNode我们会在FE端就生成ES查询的DSL语句,直接下推到BE端查询 。在同时在BE端我们实现了EsQueryNode 和MysqlQueryNode这两种QueryNode。
2.增加 JSF(京东内部RPC服务)/HTTP 数据源
数据服务中可能会涉及到整合外部数据服务和复用原先已开发指标的场景,我们的思路是把JSF(京东内部RPC服务)/HTTP也抽象成StarRocks的外部表,用户可以通过SQL像查询数据库一样访问数据服务,这样不仅可以复用老的指标还可以结合其他数据源的数据生成新的复合指标。我们在FE和BE端同时增加JSF和HTTP 两种ScanNode。
2.3 实时场景的实践
京东物流实时数据绝大多数属于更新场景,运单类数据会根据业务状态的改变而改变,下面介绍我们在生产中的三种实时更新方案:
方案一:基于ES的实时更新方案
原理如下:
- 内部先get获取document
- 内存中更新老的document
- 将老的document标记为deleted
- 创建新的document
优点:
- 支持数据实时更新,可以做到partail update
缺点:
- ES 聚合性能较差,当出现多个聚合维度时查询时间会很长
- ES 的DSL语法增加了开发工作,虽然ES可以支持简单SQL但是无法满足复杂的业务场景
- 旧数据清理难,当触发compaction物理删除标记位文档的时候会触发大量的io操作,如果此时写入量又很大,严重影响读写性能
方案二:基于clickhouse实现准实时的方案
原理如下:
- 使用ReplacingMergeTree 的方式实现
- 将Primary key相同的数据分发到同一个数据节点的同一个数据分区
- 查询时做Merge on read ,合并多版本数据读取
优点:
- clickhouse 写入基本是append写入,所以写入性能强
缺点:
- 由于读取时做版本合并,查询和并发性能较差
- clickhouse的join性能不佳,会造成数据孤岛问题
方案三:基于StarRocks主键模型的实时更新方案
原理:StarRocks收到对某行的更新操作时,会通过主键索引找到该条记录的位置,并对其标记为删除,再插入一条新的记录。相当于把Update改写为Delete+Insert。StarRocks收到对某行的删除操作时,会通过主键索引找到该条记录的位置,对其标记为删除。这样在查询时不影响谓词下推和索引的使用, 保证了查询的高效执行。查询速度比Merge on read方式快5-10倍。
优点:
- 只有唯一版本数据,查询性能强,实时更新
- 虽然Delete+Insert在写入性能有轻微损失,但总体上还是十分强悍
- Mysql协议,使用简单
缺点:
- 目前版本在数据删除上有一些限制,无法使用delete语句进行删除,新版本中社区会增加此功能
实时更新场景总的来说有以下几种方案:
- Merge on read :StarRocks 的聚合、Unique模型和Clickhouse的ReplacingMergeTree、AggregatingMergeTree都是用的此方案。此方案特点是append方式写入性能好,但是查询时需要合并多版本数据导致查询性能不佳。适合数据查询性能要求不高的实时分析场景。
- Copy on write :目前一些数据湖系统如hudi、iceberg都有copy on write 的方案现实,此方案原理是当有更新数据后,会合并新老数据并重写一份新的文件替换掉老文件,查询时无需做merge操作,所以查询性能很好。带来的问题是写和数据合并的操作很重,所以此方案不适合实时性强的写入场景。
- Delete and insert:此方案是upsert 方案,通过内存中的主键索引定位要更新的行,标记删除然后插入。在牺牲了部分写入性能的情况下,带来查询上数倍于Merge on read 的提升,同时也提升了并发性能。
实时更新在Olap领域一直是一个技术难点,以往的解决方案很难同时具备写入性能好、读取性能好、使用简单这几个特性。StarRocks的Delete and insert方式目前更接近于理想的方案,在读写方面都有很优秀的性能,支持Mysql协议使用上简单友好。同时离线分析Udata也是用StarRocks完成,让我们实现了实时离线分析一体化的目标。
3 后续方向
数据湖探索:批流一体已经成为今后发展的大趋势,数据湖作为批流一体的存储载体已经成为标准,我们以后大方向也必然是批流一体。目前批流一体中一个大痛点问题是没有一种查询引擎可以在数据湖上做极速查询,后期我们会借助SR打造在湖上的极速分析能力,让批流一体不只停留在计算阶段。
架构图如下:
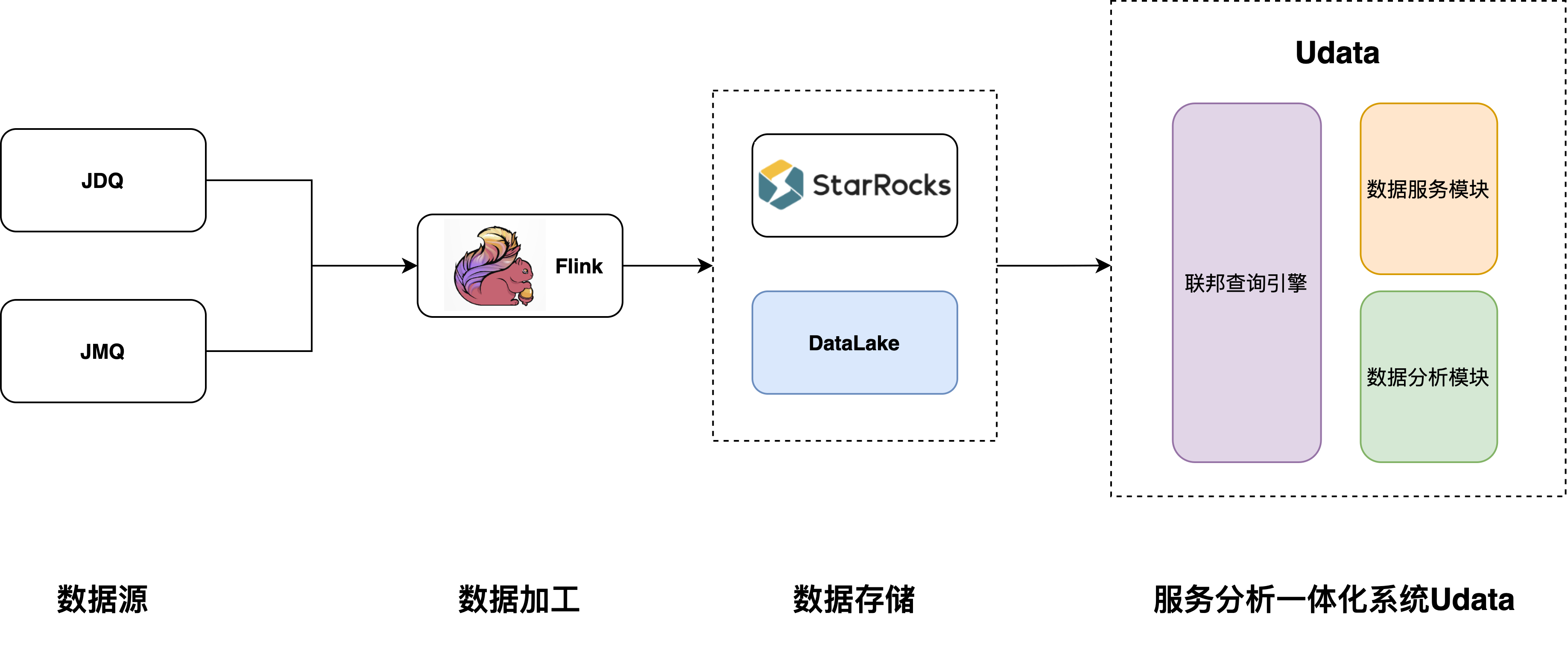
图4 后期计划架构图
- 实时数据存储统一:目前系统中还是有多套实时存储方案,运维成本还是相当高,后期我们会逐步把ES、Clickhouse替换为StarRocks,在实时层做到存储统一。我们也很期待StarRocks后期关于主键模型支持detele语句方式删除数据的Feature,这个Feature可以简化目前的数据清除问题。
- 支持更多的数据源:今后我们还会支持更多的数据源,如Redis、Hbase等kv类型的Nosql数据库,增强SR的点查能力。
- StarRocks集群间的联邦查询:在实际生产中很难做到只用一个大集群,特别是当实时有大量实时写入的情况,比较安全的做法是拆分不同的小集群,当一个集群出问题时不会影响其他业务。但是带来的问题是,集群间可能又会变为数据孤岛,即便把StarRocks伪装成Mysql创建外表,但也需要工具去同步各个集群的表结构等信息,管理起来费时费力,后续我们也会和社区讨论如何实现集群间的联邦功能。
作者:京东物流 张栋 贺思远
来源:京东云开发者社区 自猿其说Tech 转载请注明来源