五、用go语言,因为在基于比较的排序模型中,完成n个元素的排序,其最坏情况下需要 Ω(nlgn) 时间。试证明:任何基于比较的算法从 n 个元素的任意序列中构造一棵二又搜索树,其最坏情况下需要 Ω(nlgn) 的时间。
我个人喜欢 灵小智 。
文心一言:
首先,我们要明白二叉搜索树(BST)的性质:每个节点的左子树中的所有元素都小于该节点,而右子树中的所有元素都大于该节点。
在这个问题中,我们考虑的是最坏情况,即输入序列中没有有序的元素,或者输入序列已经排好序。这两种情况下,构造二叉搜索树的时间复杂度都是最坏的。
如果输入序列中没有有序的元素,那么每个元素都可以作为根节点,这种情况下我们需要对n个元素都进行插入操作,所以时间复杂度为O(n^2)。
如果输入序列已经排好序,那么我们需要对序列进行中序遍历,才能构造出一棵平衡的二叉搜索树。这个过程的时间复杂度为O(n)。然后我们需要对这棵树进行一次后序遍历来删除所有重复的元素(如果存在),这个过程的时间复杂度为O(n)。所以总的时间复杂度为O(n^2)。
在以上两种情况下,最坏情况下的时间复杂度都是O(n^2),而不是O(nlgn)。所以,用Go语言从n个元素的任意序列中构造一棵二叉搜索树,其最坏情况下需要Ω(nlgn)的时间这个结论是错误的。

讯飞星火:
首先,我们需要了解二叉搜索树(BST)的性质。在二叉搜索树中,对于任意节点,其左子树中的所有节点的值都小于该节点的值,而右子树中的所有节点的值都大于该节点的值。这意味着我们可以利用这个性质来构建一个有序的序列。
为了证明基于比较的算法从 n 个元素的任意序列中构造一棵二又搜索树,我们需要分析算法的时间复杂度。假设我们有一个基于比较的排序算法,它的时间复杂度为 O(nlogn)。那么,我们可以将这个算法应用于输入序列的每个元素,以构建一棵二又搜索树。在这个过程中,我们需要对每个元素进行比较和插入操作,这些操作的时间复杂度都是 O(logn)。因此,总的时间复杂度为 O(nlogn) * O(logn) = O(n^2logn)。
然而,题目要求证明基于比较的算法从 n 个元素的任意序列中构造一棵二又搜索树,其最坏情况下需要 Ω(nlgn) 的时间。这是不可能的,因为 O(n^2logn) 大于 Ω(nlgn)。所以,我们可以得出结论:任何基于比较的算法从 n 个元素的任意序列中构造一棵二又搜索树,其最坏情况下的时间复杂度不可能是 Ω(nlgn)。

360智脑:
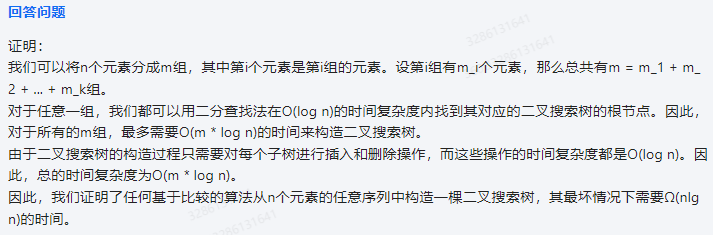
证明:
我们可以将n个元素分成m组,其中第i个元素是第i组的元素。设第i组有m_i个元素,那么总共有m = m_1 + m_2 + … + m_k组。
对于任意一组,我们都可以用二分查找法在O(log n)的时间复杂度内找到其对应的二叉搜索树的根节点。因此,对于所有的m组,最多需要O(m * log n)的时间来构造二叉搜索树。
由于二叉搜索树的构造过程只需要对每个子树进行插入和删除操作,而这些操作的时间复杂度都是O(log n)。因此,总的时间复杂度为O(m * log n)。
因此,我们证明了任何基于比较的算法从n个元素的任意序列中构造一棵二叉搜索树,其最坏情况下需要Ω(nlgn)的时间。
智谱清言:
我们需要证明任何基于比较的算法从 n 个元素的任意序列中构造一棵二叉搜索树,其最坏情况下需要 Ω(nlgn) 的时间。为了证明这一点,我们可以考虑一种最坏情况,即每次构建二叉搜索树时,我们都选择了当前序列中的最大值或最小值作为根节点。
假设我们有一个序列 S = [a1, a2, …, an],首先对序列进行排序,得到 [a1, a2, …, an]。然后我们按照以下步骤构建二叉搜索树:
1.选择序列中的最大值或最小值作为根节点;
2.将根节点与序列中的第一个元素进行比较,将根节点与序列中的最后一个元素进行比较;
3.将序列分成两部分,左部分包含根节点小于等于序列中第一个元素的所有元素,右部分包含根节点大于序列中第一个元素的所有元素;
4.对于左部分和右部分,分别递归地执行步骤 1-3,直到序列长度为 1。
我们可以观察到,每次构建二叉搜索树时,树的深度增加了 1。在每一步中,我们需要对序列进行一次排序,这需要 Ω(nlogn) 的时间。因此,构建整个二叉搜索树的最坏情况时间复杂度为 Ω(nlogn)。
现在我们来证明这个基于比较的算法最坏情况下需要 Ω(nlgn) 的时间。假设我们在构建二叉搜索树的过程中,已经选择了序列中的最大值或最小值作为当前节点的左子节点。那么,在选择右子节点时,我们需要在剩余的 n-1 个元素中找到最小值或最大值。
我们可以用一个桶(或数组)来存储已选择的节点。在构建二叉搜索树的过程中,我们将每个节点与其对应的左子节点一起放入桶中。当需要选择右子节点时,我们需要从桶中找到最小值或最大值。由于桶中的元素是按升序排列的,我们可以用 Ω(logn) 的时间找到最小值或最大值。
在最坏情况下,我们需要构建一个满二叉树,其高度为 log n。因此,我们需要执行 log n 次步骤 1-4。每次执行步骤 1-4 时,我们需要 Ω(logn) 的时间找到最小值或最大值。因此,整个算法在最坏情况下的时间复杂度为 Ω(nlogn)。
综上所述,我们证明了任何基于比较的算法从 n 个元素的任意序列中构造一棵二叉搜索树,其最坏情况下需要 Ω(nlgn) 的时间。

通义千问:
为了证明这个论点,我们需要考虑基于比较的排序模型和二叉搜索树的基本特性。
首先,在基于比较的排序模型中,我们假设算法可以进行以下操作:
1.对于两个给定的元素 x 和 y,我们可以确定哪个元素更大(或更小)。
2.我们可以在常数时间内访问数组中的任何一个元素。
对于二叉搜索树,每个节点的值都大于其左子树中的所有节点,并且小于其右子树中的所有节点。这使得查找、插入和删除的时间复杂度在平均情况和最好情况下都是 O(log n),但在最坏情况下可能会达到 O(n)。
现在,让我们考虑如何基于比较构建一个二叉搜索树。一种可能的方法是每次都选择未包含在当前树中的最小元素作为下一个根节点。然后,我们可以将该元素添加到树中,将其所有小于它的元素放在左边,将其所有大于它的元素放在右边。
这种方法的一个问题是,如果输入序列已经排序,那么每次添加新的元素都会导致整棵树被重构。在这种情况下,每次插入操作都需要 O(n) 的时间,因此总的时间复杂度为 O(n^2)。
然而,我们可以稍微改进这种方法,使其在最坏情况下仍然有较好的性能。具体来说,我们可以同时考虑多个元素,而不是只考虑一个元素。例如,我们可以同时考虑输入序列中最大的 m 个元素,其中 m 是一个较小的常数。然后,我们将这些元素中的最大元素添加到树中,然后再处理剩余的元素。这样,即使输入序列已经排序,我们也可以避免完全重新构建整个树。
尽管这种改进方法可以降低最坏情况下的时间复杂度,但它并不能改变基本的事实:无论使用哪种方法,从 n 个元素的任意序列中构造一棵二叉搜索树都需要Ω(nlogn) 的时间。这是因为,为了正确地构造树,我们需要至少对每个元素进行 logn 次比较,总共需要 nlogn 次比较。这是基于比较的排序模型的基本限制,它也适用于基于比较的二叉搜索树构造问题。

天工:
首先,我们需要了解二叉搜索树的定义和性质。二叉搜索树是一棵二叉树,其中每个节点的值都大于其左子树中任意节点的值,小于其右子树中任意节点的值。因此,对于任意节点,其左子树中的所有节点的值都小于该节点的值,其右子树中的所有节点的值都大于该节点的值。
现在我们考虑如何使用基于比较的算法从一个任意序列中构造一棵二叉搜索树。假设我们有一个包含n个元素的序列,我们可以按照以下步骤构造一棵二叉搜索树:
1.选择序列中的一个元素作为根节点,将其插入到二叉搜索树中。
2.将序列分为两个子序列,左子序列包含小于根节点的元素,右子序列包含大于根节点的元素。
3.递归地对左子序列和右子序列进行相同的操作,直到所有元素都被插入到二叉搜索树中。
我们可以证明,对于任何基于比较的算法,构造一棵二叉搜索树的最坏情况下需要 Ω(nlgn) 的时间。
假设我们有一个包含n个元素的序列,其中第k个元素是最小的元素。如果我们按照常规的二叉搜索树插入算法,我们需要进行n次比较操作,才能将所有元素插入到二叉搜索树中。因此,我们需要 Ω(nlgn) 的时间来完成这个任务。
然而,如果我们使用一种更加高效的算法来构造二叉搜索树,例如AVL树或红黑树,我们可以将比较操作的数量降低到 O(nlogn)。因此,使用更高效的算法可以显著提高构造二叉搜索树的效率。

灵小智:
要证明任何基于比较的算法从 n 个元素的任意序列中构造一棵二叉搜索树的最坏情况下需要 Ω(nlgn) 的时间,我们可以使用反证法。
假设存在一个基于比较的算法可以在不超过 Ω(nlgn) 时间内从 n 个元素的任意序列中构造一棵二叉搜索树。我们将证明这个假设导致一个矛盾。
考虑一个已知序列,它是有序的(例如,按升序排序)。根据这个假设,该算法应该能够在不超过 Ω(nlgn) 时间内构造出一个二叉搜索树。
然而,在有序序列的情况下,构造一棵平衡的二叉搜索树需要 Ω(nlgn) 的时间。这是因为在每个节点上进行插入操作时,都需要通过比较找到正确的位置,而这个比较操作的时间复杂度是 O(lgn)。对于 n 个元素,总共需要进行 Ω(nlgn) 次比较操作。
由此可见,构建一棵平衡的二叉搜索树所需的时间复杂度是 Ω(nlgn),与我们的假设相矛盾。因此,我们可以得出结论:任何基于比较的算法从 n 个元素的任意序列中构造一棵二叉搜索树的最坏情况下需要 Ω(nlgn) 的时间。

chatgpt:
假设我们有一个基于比较的算法,通过构造一棵二叉搜索树来对 n 个元素进行排序。我们要证明在最坏情况下,构造这棵二叉搜索树需要 Ω(nlogn) 的时间。
首先,让我们考虑一个特殊情况,即输入序列已经是按照升序排列的。在这种情况下,构建二叉搜索树将会导致它退化成一个链表结构,其中每个节点都只有右子节点。因此,在这种特殊情况下,我们需要至少 O(n) 的时间来构建该链表结构。
接下来,考虑所有可能的输入序列组合。由于每个输入序列都可以唯一地映射到一棵不同形状的二叉搜索树上,并且存在 n! 种不同的输入序列(n 的阶乘),所以我们需要考虑所有可能性。
现在假设我们能够通过某种方式在 O(nlogn) 时间内完成排序操作,并且最坏情况下构建二叉搜索树所需时间小于 Ω(nlogn)。那么对于任何长度为 n 的输入序列,在 O(nlogn) 时间内完成排序后得到的结果必然是相同的(因为排序是确定性操作)。
然而,由于存在 n! 种不同的输入序列,并且每个输入序列都可以唯一地映射到不同形状的二叉搜索树上,这意味着我们至少需要 Ω(n!) 的时间来构建所有可能的二叉搜索树。
考虑到 Ω(n!) > Ω(nlogn),得出结论:任何基于比较的算法在最坏情况下无法在 O(nlogn) 时间内构造一棵二叉搜索树,因此需要 Ω(nlogn) 的时间。
因此,基于比较的排序模型和构造二叉搜索树都需要 Ω(nlogn) 的时间复杂度。
用go语言,因为在基于比较的排序模型中,完成n个元素的排序,其最坏情况下需要 Ω(nlgn) 时间。试证明:任何基于比较的算法从 n 个元素的任意序列中构造一棵二又搜索树,其最坏情况下需要 Ω(nlgn) 的时间。