Matplotlib散点图的创建
- plot绘制散点图
- scatter画散点图
- plot与scatter效率对比
plot绘制散点图
散点图也是在数据科学中常用图之一,前面的文章我们学习了使用plt.plot/ax.plot画线形图的方法。同样的,现在用这些函数来画散点图:
x = np.linspace(0, 10, 30)
y = np.sin(x)
plt.plot(x, y, 'o', color='black')
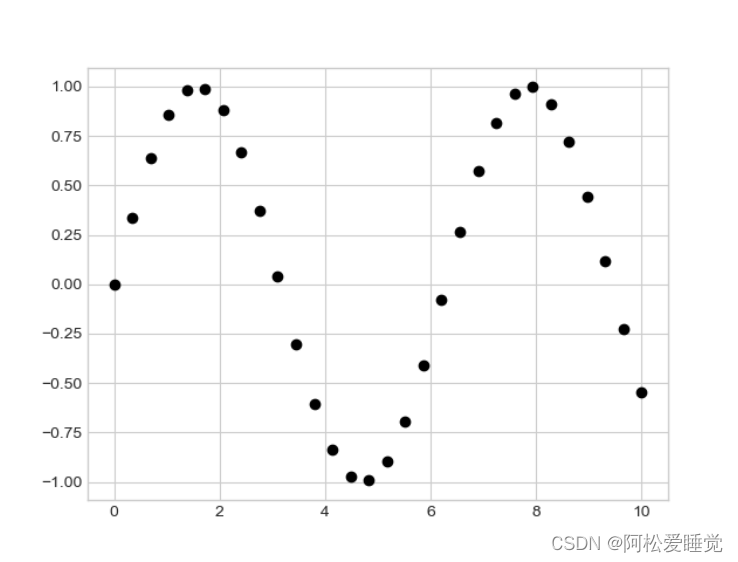
函数的第三个参数是一个字符,表示图形符号的类型。与我们之前用-和--设置线条属性类似,对应的图形标记也有缩写形式。
rng = np.random.RandomState(0)
for marker in ['o', '.', ',', 'x', '+', 'v', '^', '<', '>', 's', 'd']:
plt.plot(rng.rand(5), rng.rand(5), marker,label="marker='{0}'".format(marker))
plt.legend(numpoints=1)
plt.xlim(0, 1.8);
plt.savefig("T1.png")
plt.show()
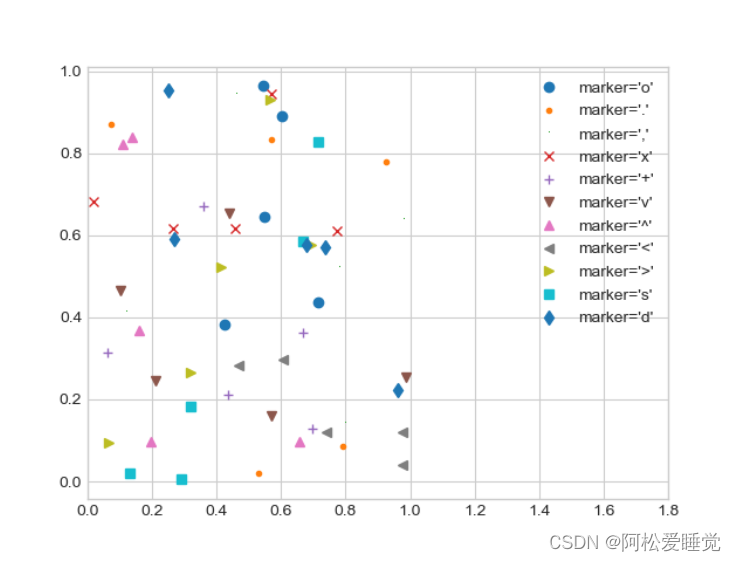
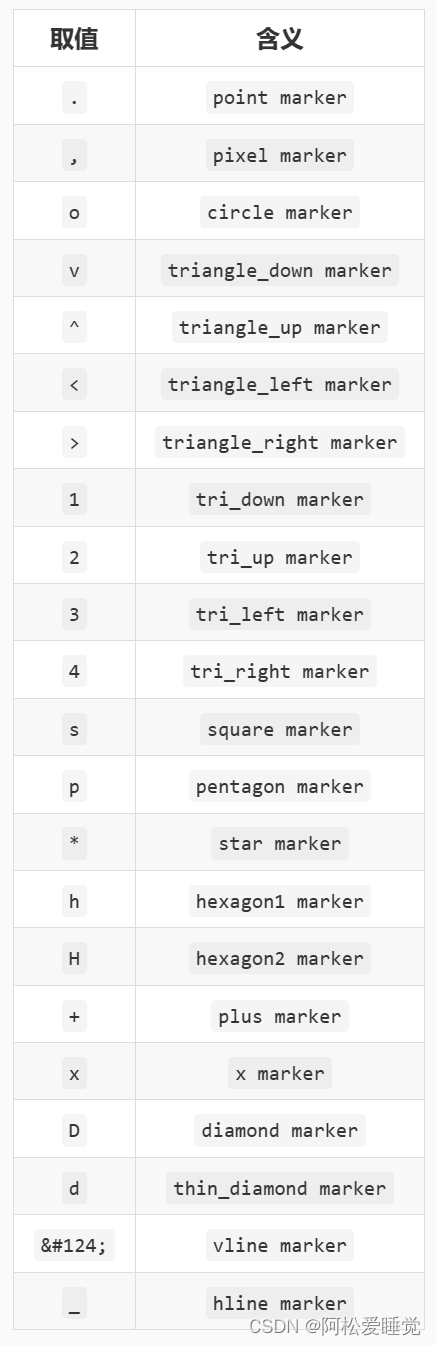
常用标记如下:
plt.plot函数非常灵活,可以满足各种不同的可视化配置需求。
(由于文章篇幅有限,关于具体配置的完整描述,可以参考plt.plot文档,这里就不多介绍了,大家多多尝试就好。)
scatter画散点图
另一个可以创建散点图的函数是plt.scatter。它的功能非常强大,其用法与plt.plot函数类似:
x = np.linspace(0, 10, 30)
y = np.sin(x)
plt.scatter(x, y, marker='o');
结果和前面plt.plot画的一样。plt.scatter和plt.plot的主要差别在于,前者在创建散点图时具有更高的灵活性,可以单独控制每个散点与数据匹配,也可以让每个散点具有不同的属性(大小、颜色等)。
接下来画一个随机散点图,里面有各种颜色和大小的散点。为了能更好的显示重叠部分,用alpha参数来调整透明度:
rng = np.random.RandomState(0)
x = rng.randn(100)
y = rng.randn(100)
colors = rng.rand(100)
sizes = 1000 * rng.rand(100)
plt.scatter(x, y, c=colors, s=sizes, alpha=0.3,
cmap='viridis')
plt.colorbar() # 显示颜色条
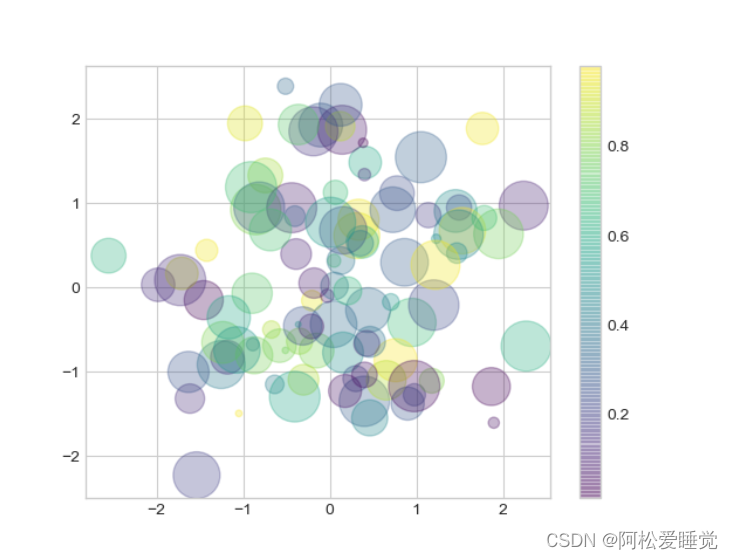
这里散点的大小以像素为单位。颜色为浮点数,自动映射成颜色条(color scale,通过colorbar()显示)。当取值为浮点数时,它所对应的颜色则是对应的colormap上对应长度的取值,colormap就像以下这样的条带:
这样,散点的颜色与大小就可以在可视化图中显示多维数据的信息了。例如,可以使用sklearn程序库中的鸢尾花数据来演示。它里面有三种花,每个样本是一种花,其花瓣与花萼的长度与宽度都经过了测量:
from sklearn.datasets import load_iris
iris = load_iris()
features = iris.data.T#加载数据
plt.scatter(features[0], features[1], alpha=0.2,
s=100*features[3], c=iris.target, cmap='viridis')
plt.xlabel(iris.feature_names[0])
plt.ylabel(iris.feature_names[1]);
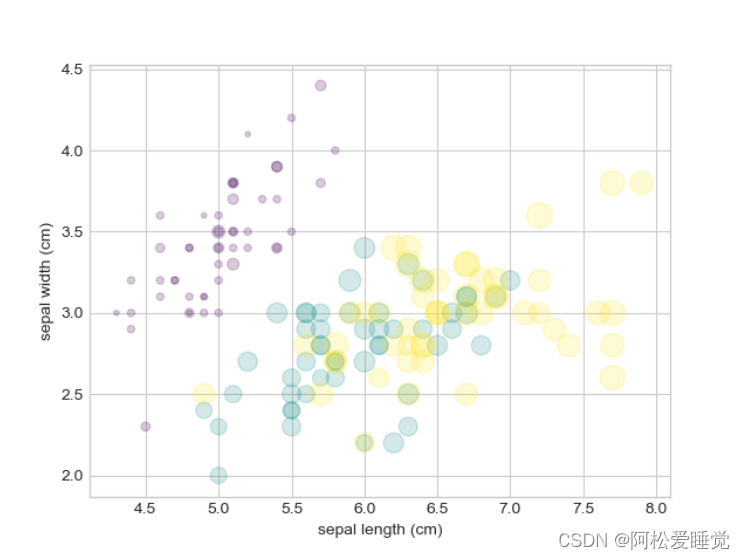
散点图可以让我们同时看到不同维度的数据:每个点的坐标值(x, y)分别表示花萼的长度和宽度,而点的大小表示花瓣的宽度,三种颜色对应三种不同类型的鸢尾花。
这类多颜色与多特征的散点图在探索与演示数据时非常有用。
plot与scatter效率对比
plot与scatter除了特征上的差异之外,在数据量较大时,plot的效率将大大高于scatter。
这时由于scatter会对每个散点进行单独的大小与颜色的渲染,因此渲染器会消耗更多的资源。而在plot中,散点基本都彼此复制,因此整个数据集中的所有点的颜色、大小只需要配置一次。所以面对大型数据集时,plot方法比scatter方法好。