ViLT 论文精读【论文精读】_哔哩哔哩_bilibili
目录
ViLT 论文精读【论文精读】_哔哩哔哩_bilibili
1 地位
2 ViLT做了什么能让它成为这种里程碑式的工作?
3 ViLT到底把模型简化到了什么程度?到底能加速到什么程度?
2.1 过去的方法是怎么做的:ViLBERT,UNITER,Oscar这些工作
4 文章的整体结构
5 标题
5.1之前大部分的多模态任务很多都是用了transformer,那大家都用,你和别人的区别在哪呢?
6 摘要
7 引言
7.1 作者上来说,多模态学习最近也是非常的火,提升也是非常的快,为什么呢?
7.2 从宏观上把先预训练再微调的结构讲完之后,接下来就是该讲一些具体的了,就是说具体怎么去处理文本和图像。
7.2.1 文本用transformer,图像怎么给transformer处理?
1、vit打patch
2、vit之前大家是怎么考虑的?目标检测器,但是这个方法太贵了
7.2.2 引出本文动机:过去的方法只看性能不看效率,我们关注的是更轻量简单的图像特征抽取方法,做法和VIT一模一样
7.3 模型ViLT
7.4ViLT的三个贡献
8 背景知识
8.1 2.1节VLP领域中模型的划分
8.2 2.2之前的方法都是怎么做模态融合的
8.3 2.3在融合之前特征该怎么抽取(文本、图像怎么抽特征)
9 模型结构
9.1 模型是什么,输入输出是什么
9.2 怎么训练ViLT
9.2.1 图文匹配loss
9.2.2 Word Patch Alignment loss
9.2.3 Masked Language Modeling
9.3 训练过程中好用的小技巧:文本上whole word masking
10 实验
10.1 数据集
10.2 对比实验
10.2.1 分类任务
10.2.2 检索任务
10.3 消融实验
11结论
摘要
引言
1 地位
ViLT是做视觉文本多模态任务的,中稿于2021年的ICML,而且是一个口头报告。ViLT提出了一个极其简单的做多模态学习的一个框架结构,把模态的特征抽取做到了极小化,把主要的计算量都放到了后面的模态融合上,大大提高了模型的推理速度,而且让整个方法的建模变得特别简单,所以在很大程度上推动了过去一年多模态学习的进展,算的上多模态领域这两年来一个里程碑式的工作
2 ViLT做了什么能让它成为这种里程碑式的工作?
其实它主要的贡献就是把目标检测,也就是这篇论文里反复强调的Region Feature区域性特征,从多模态学习的框架中移除了,这简直是大快人心,因为天下苦目标检测久矣,DETR这篇论文,就因为把目标检测的框架做的非常简单,不仅可以端到端的训练,而且还不需要复杂的后处理,所以立刻得到了大家的追捧,基本整个目标检测领域都往DETR那个方向去走了
ViLT直接把目标检测从多模态学习的框架中移除了,所以更是极大的简化了所有的这些方法,让广大研究者开心的不得了
3 ViLT到底把模型简化到了什么程度?到底能加速到什么程度?
2.1 过去的方法是怎么做的:ViLBERT,UNITER,Oscar这些工作
一般文本这边都是很简单的,直接把文本通过一个embedding矩阵,变成一个个的word embedding就好了,就可以直接和visual embedding扔到最后的transformer里去做模态之间的融合
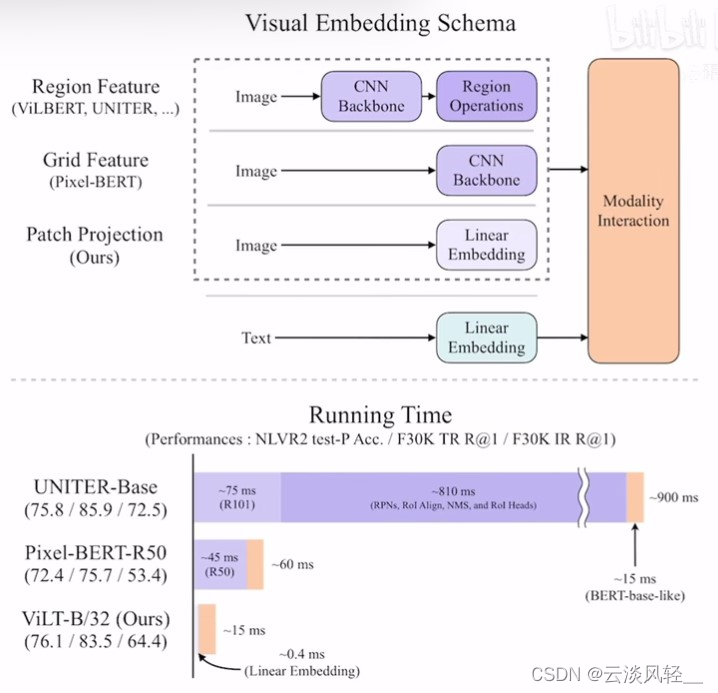
视觉这边就不同了,最流行的区域特征(第一种region feature)来说,他们一般都是先给定一个图像,然后通过一个卷积神经网络的backbone,最后在通过一些ROI抽到一些区域性特征,相当于是做了一个目标检测的任务,因为抽出来的特征都是区域性的,都是一个个的bounding box,所以就跟文本那边的单词一样都是离散形式的,可以想象成是一个序列,接下来就可以把这个序列直接扔给transformer去做模态之间的融合,所以这也就是为什么之前的多模态学习里,大家喜欢把图像这边建模成为一个目标检测的任务,但是它带来的缺点也是显而易见的,作者下来就在运行时间这做了一个对比,会发现用了目标检测的方法,整个模型的运行时间才900毫秒,但是视觉部分的运行时间就占到了810毫秒,文本只占了15毫秒,所以说为了达到很好的效果,模型在视觉这边浪费了太多计算资源,在过去的4-5年间,多模态这边也有专门的一个方向,如何把视觉这边的时间降下来。
总之在和本文提出的ViLT相比,它的视觉部分只有0.4毫秒,跟文本比,基本上可以忽略不计了,跟之前的这种视觉方面的885毫秒相比直接是上千倍的运行时间的减少,所以这张图带来的效果是非常震惊的(这种写作手法是很值得学习的)
因为虽然ViLT把这个模型做的这么简单,但它真的训练时间会很短吗?并不是,它需要64张32g的v100的卡,非常贵的一个配置,而且还要训练三天才能训练完,甚至比之前的很多方法训练时间都要久。
它效果怎么样?其实在图中也可以看到,它的效果也一般,尤其是跟之前用这种区域特征的方法,也是远远不如的。
但是它把它最重要的特征,也就是运行时间这种上千倍的减少,作为最大的卖点,然后整个文章的故事也是围绕这个来讲,文章的结果也是围绕这个来阐述,所以让他们的优势得到了最大化的体现,让读者始终在跟着它的节奏来走,就对这篇文章的印象分非常不错
4 文章的整体结构
- 摘要、
- 引言、
- 两页篇幅的相关工作(总结之前的方法,分为了四种形式,ViLT是第四种,因为它是宏观上的对所有之前的方法的一个总结,他们的方法也是在宏观上做的一种改变。一点一点把为什么要做ViLT,以及ViLT和之前方法的区别在哪说的非常清楚,这样才能知道他们的区别在哪,我们的贡献在哪)
- 主体方法部分两页,真正说模型的只有一小段。模型怎么训练的目标函数半页,训练模型的小技巧半页。 之所以这么短,是因为ViLT确实比较简单,说白了它只是用了两个模态的输入,模型就是一个transformer
- 讲完了方法,作者就做了大量的实验,三页多
- 最后一页做了一些可视化、分析、和消融实验
5 标题
标题:ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision,ViLT就是Vision-and-Language Transformer 的缩写,就是拿transformer去做多模态的任务,
5.1之前大部分的多模态任务很多都是用了transformer,那大家都用,你和别人的区别在哪呢?
Without Convolution or Region Supervision就说明了区别,我们既没有用卷积特征带来的这种监督信号,也没有用区域特征带来的监督信号,这里的卷积特征其实就指代了一个预训练好的分类模型,也就是一个backbone抽出来的特征图,而这里的区域特征其实是说,用了一个图像的backbone之后然后又做了一下目标检测,出来的那些框所代表的那些区域特征。
所以一看题目,不用看论文,都知道大概这个论文想讲什么,肯定意思就是说,之前的方法要么用了卷积的特征,要么用了区域性的特征,总之就是用了之后效果比较好,但是肯定也带来一些相应的问题,这篇论文就是把这些东西都拿掉,但是还能保证性能下降的不要太多,甚至能保持不变,其实也就跟很多论文标题里说的那些anchor free、bn free、nms free、motion free都差不多意思,意思就是用了这些信息之后可能之前那些方法能得到很好的效果,但是现在为了简化这个流程,不用它也能得到差不多的效果
6 摘要
作者上来就说视觉文本的预训练任务,缩写为VLP任务,在过去几年发展的不错,在各种各样的视觉文本的下游任务上都取得了很好的成绩。但是之前的这些方法,为了在那些下游任务上获得很好的结果,大家发现往往你在视觉方面花的精力越多,也就是视觉的网络越复杂、越好,最后的结果就会越好,所以之前大部分的VLP的方法,都非常依赖于图像特征的抽取过程,要么是把它看成是一个目标检测的问题,这里就像图1画的一样,不仅有一个图像backbone,还有一个region operation,所以就很贵。或者稍微轻量一点,就是直接用一个resnet去抽特征,也就是图1中的CNN backbone,但其实还是需要一个额外的网络去抽这些特征,还是相对而言比较贵的。所以这篇论文,作者就针对这个展开了研究。【针对什么问题展开研究】
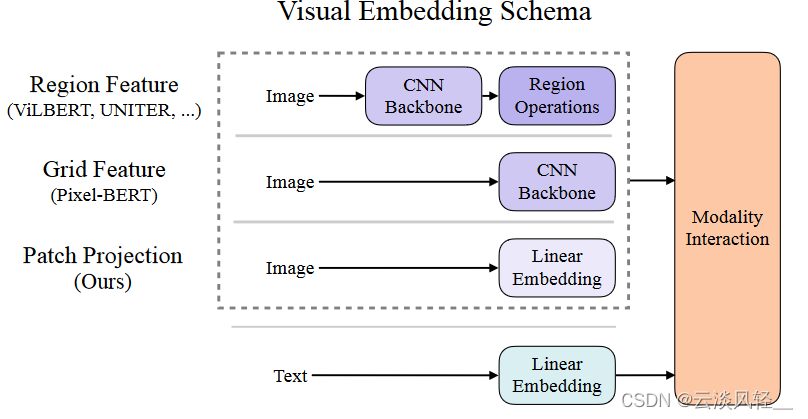
作者发现用这种方式,至少有两个问题,第一个问题就是说:效率不行,速度太慢了,光是抽特征就花费了大量时间,甚至在抽取图像特征上花的时间比后面做多模态融合花的时间还多,这个可能对大部分多模态下游任务来说都不是那么好,毕竟如果只是把两个单模态做的很好,然后简单融合一下效果就能很好的话,那大家还研究多模态学习干什么。所以多模态的融合,按道理来说应该是花费更多时间,或者花费更多的精力去提高它的。就跟无人驾驶一样,传感器那么多,传感器的融合才是最关键的一步。作者这里说的第二个问题,就是如果你只用一个预训练好的模型去抽特征,你这个模型的表达能力,肯定是很受限的,比如说用一个已经预训练好的目标检测器,大家也都知道,现在这个目标检测的数据集都不大,最大的数据集也无非是检测几百类,也就几十万或者上百万个目标检测框,它的规模还没有特别大,所以它不能涵盖到这个问题的边边角角,这就导致说如果你这个模型,不是端到端学习,只是从预训练模型中抽特征的话,你大概率来说不是最优解。而且深度学习时代,大家都是要端到端。
所以针对这两个痛点,这篇论文ViLT,它就提出了一个极简化的VLP模型,受到vision transformer的启发,把图像这边的预处理做的和文本那边的预处理一样了,都是通过一个linear embedding层就结束了。
最后作者说,因为这种极简化的设计,所以他们的ViLT比之前这种VLP模型都快了不少,但是性能还是非常具有竞争力的,甚至在有些下游任务上还能取得更好的结果。
摘要写的非常直白,最后因为作者本身卖的就是这个方法的简单性,而且希望更多人来用,所以毋庸置疑,必须是要把代码放出来的否则影响力肯定是就大打折扣了。
7 引言

7.1 作者上来说,多模态学习最近也是非常的火,提升也是非常的快,为什么呢?
是因为多模态领域现在也采取了这么一种先预训练,再微调的方式。这个方式不论之前是在视觉领域还是NLP领域,大家都是这么做的,都是先预训练,然后再去微调,所以说当把它拓展到多模态领域的时候,它的效果也不错。因为在这种模式之下,预训练比较重要,因为他要在更多的数据集上去做训练,从而能提供一个很好的初始化,甚至能够直接zero shot去做下游任务。所以说预训练阶段就更为重要,所以也就催生了多模态领域的视觉文本联合在一起的这种预训练模型,那它到底有多火呢,我们可以看到从2019年到2021年,它就罗列了这么多工作
而且这些工作基本上都是引用上百,已经很有影响力的工作了。从而也就说明肯定还有成百上千篇,这种跟进性的工作。所以可见多模态学习在过去的两三年之间发展的有多快,比如说刚开始,其实在2019年的时候就出来了三篇名字非常像的论文VILbert,visual bert,VLbert他们的做法其实也非常类似。所以多模态听起来好像是一个比较新的领域,但竞争早已是非常激烈了,不仅拼手速也拼积累。然后作者罗列完这么多工作以后呢,就是说一般这些模型,全都是用这种图像文本对去进行预训练的,他们的目标函数基本上就是这种image text matching,也就是图像文本匹配的loss,还有就是NLP专属的这种mask language modeling,也就是bert使用的掩码学习,作者这里还给了一个脚注,说,其实这么多工作肯定是有别的工作提出新的目标函数的,但是图文匹配loss和掩码loss基本是所有的vlp模型都用到了,所以他们这篇文章也同样用到了这两个目标函数。一旦预训练完成,拿到了预训练好的模型,接下来就是做一些微调,这些下游任务往往涉及到两个模态,也就是文本和图像,当然了,不光是说一张图像和一个文本,有的时候可能是两个图像一个文本,或者一个图像两个文本
7.2 从宏观上把先预训练再微调的结构讲完之后,接下来就是该讲一些具体的了,就是说具体怎么去处理文本和图像。
7.2.1 文本用transformer,图像怎么给transformer处理?
文本其实没什么好说的,因为从17年开始大家就已经用transformer去做文本了,而且基本上transformer已经一统江湖了,文本就只能这么做
但是对于图像来说,这个故事就完全不一样了,作者说,因为你要做这种图文预训练,你的图像的像素就必须变成某一种形式,比如说一种离散的,带有很高语义的这种特征形式,能跟language token匹配起来,这样才能一股脑的扔进transformer,然后transformer自己跟自己自注意力去学,你不能直接把图像的像素扔给transformer,因为vit中就提到过,如果这么做,序列的长度就太长了,transformer根本接受不了,所以说如何把图像的像素变成带有语义性、离散型的特征就是大家主要要研究的问题了,
1、vit打patch
对于vit这篇论文来说,为了避免这种情况的发生,它不是在图像像素上去做,而是把图像分成了16*16这种patch大小,让这个patch去得到一个特征,然后把特征扔给transformer去学习,
2、vit之前大家是怎么考虑的?目标检测器,但是这个方法太贵了
但是vit已经是2021年的工作,那在这之前,大家是怎么去考虑这个问题的?作者这里说,大部分的VLP的工作都是依赖于一个目标检测器。
为什么选择目标检测器呢?其实有很多原因,第一个原因就是:你不是想要一个语义性强的,而且是离散的这种特征表示形式吗,目标检测就是一个天然的离散化的过程,你给我一个图片,我还给你n个bounding box,这些bounding box就是一个又一个的物体,有明确的语义信息,而且它是离散化的,直接用ROI去抽特征就好了,非常简单粗暴,所以不管他的效果如何,大家肯定都是先愿意让它尝试一下的,因为这里面的region,就是目标检测所用的区域其实就可以想象为是句子里面的某个单词。第二个原因可能跟下游任务也有关系,因为对于当时的vision language下游任务来说,大部分可能就是VQA、visual captioning、image text retrieval这些任务往往和物体有非常直接的关系。比如说对VQA任务而言,问题可能就是问这张图片里有没有这个物体;对于视觉定位(visual grounding)任务而言,文本query可能就是问物体在图片的哪个地方,其实这本身就已经是一个目标检测的问题了,然后对于visual reasoning、image text retrieval这些任务而言其实都跟物体有着非常强烈的联系,一旦检测到某个物体,你很有可能就能匹配到那张正确的图片。所以一切的一切,这些已有的数据集它都有非常强的对物体的依赖性,所以说选择目标检测系统作为多模态的一部分也是非常合理的。
然后作者接下来说,目前大部分的这些 VLP模型,都是用了一个预训练好的目标检测器,这个目标检测器是在Visual Genome数据集上预训练的,这个数据集上有1600个物体的类别,还有400个属性类别,之所以选择visual Genome这个数据集,就是看上了它有这么多类。因为对于多模态学习而言,视觉这边就是直接抽特征,直接拿到这些bounding box,模型肯定是希望它能覆盖的类别数越多越好,因为文本那边没有任何的限制,文本那边可以是任何的词,也可以描述任何的一个物体,所以如果图像这边只限制到比如说COCO的80个类,那图像文本就匹配不起来了,所以说图像那边类别数越多越好,越多元化越好。另外也是出于公平比较,如果之前一个工作用了目标检测器,你接下来最好也用目标检测器,这样你才能证明你的性能提升是由你的方法带来的,而不是因为你用了一个更强的检测器。所以导致之前大部分的VLP模型用的都是以前预训练好的检测器(Krishna et al.,2017Visual Genome: Connecting Language and Vision Using Crowdsourced Dense Image Annotations)。
但是用目标检测的思路去抽图像特征确实是太贵,所以也有一些工作尝试去把计算量降下来,其中就有一个工作就叫做pixelbert,它其实就是用了一个在imagenet上预训练好的一个残差网络,然后直接把残差网络最后得到的特征图,当成是一个离散的序列就跟vit hybrid一样:先用一个卷积神经网络去抽一些特征,然后再把这些特征当成sequence token,扔给一个transformer去学,这样计算量就只有backbone了,而没有后面的这些目标检测相关的东西,比如ROI、NMS这些东西,操作速度能快不少。但是不论你是用一个简单的残差网络抽特征,还是用一个复杂的目标检测的流程去抽特征,作者都认为它还是太贵了。
7.2.2 引出本文动机:过去的方法只看性能不看效率,我们关注的是更轻量简单的图像特征抽取方法,做法和VIT一模一样
作者说,截止到目前为止,大部分工作还是聚焦在如何通过提升视觉编码器,从而能提升最后的性能的,因为在学术界大家不怎么关心运行速度或者效率这个问题,大家看中的更多的还是性能,性能实在刷不动了才去关注效率。尤其在多模态学习领域,大家没太把这个当回事,其实在训练的过程中,大家可以提前把这个目标检测这个特征都抽好,然后存在本地的硬盘上,训练的时候直接用就好了,所以虽然听起来很贵,像我们刚才看到的一样,那个图表里图像抽特征需要800多毫秒,是文本的好几十倍,但其实抽特征的过程其实是在线下完成的,特征早已被抽好存在硬盘上了,所以真正训练的时候是没有那么贵的,训练上还是很轻量的,所以大家也就没太当回事,但事实上这是一个非常严重的问题,因为当你在真实世界中去做应用的时候,数据都是每时每秒在实时生成的新数据,对于新数据,都要去抽取特征,那个时候在做推理的时候,这个时间就不可忽略了,你没有办法提前抽取好存在硬盘上,所以说局限性还是非常大的,于是乎,作者说我们的重心就转移到怎么设计一个更轻量更简单的图像特征抽取的方法。
其实ViLT这篇论文的想法,在vit这篇论文出来之后其实并不难想到,因为它就是受启发于VIT的工作,利用这种把图像打成patch,然后用一个简单的linear projection层去把patch变成embedding的方式,从而取消掉了繁琐的图像特征抽取的过程,它的做法和VIT是一模一样的,所以从某种意义上来说,ViLT这篇论文也是Vit之后一个手快的,在多模态领域里的扩展应用。
7.3 模型ViLT
说完了之前的工作,和之前工作的缺陷和不足,然后作者也讲了自己接下来打算怎么做,就是用patch embedding去替换之前的一些繁琐的图像抽特征的过程,所以作者就在下一段提出了他们的模型ViLT,因为模型实在太简单,所以他也就只用了一小段来写,这里我们直接看图1

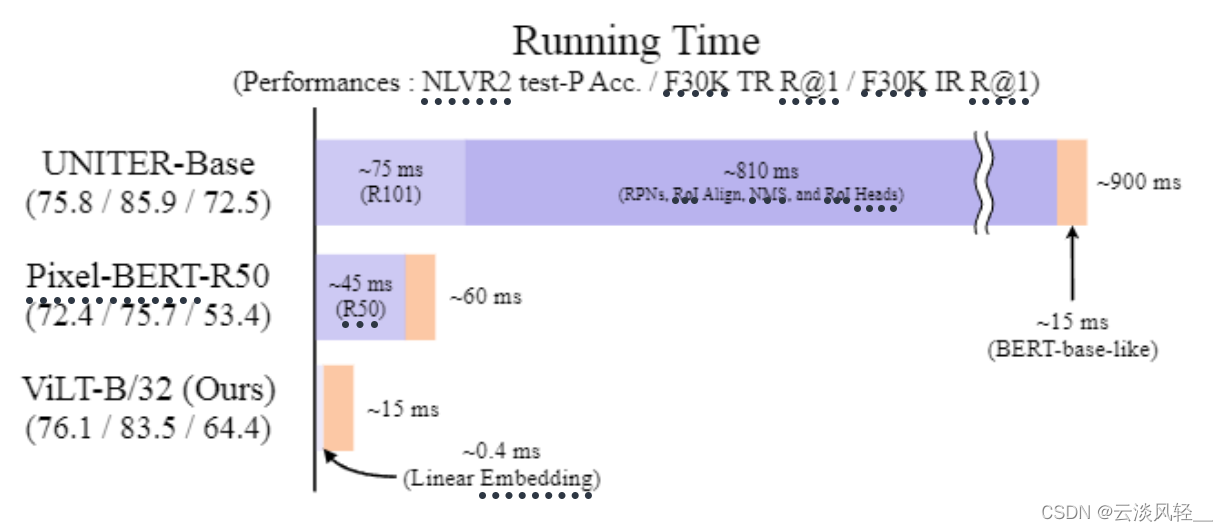
- 之前表现好的一些模型,就是使用这些检测特征的这些模型,他们都是给定一个图片,先通过一个resnet50/101的backbone得到一些特征,然后基于这些特征,利用ROI就是这些region operation(RPN、ROI、NMS)去抽出属于物体的这些特征,这些特征都是离散的,比如说抽出来了100个物体,这时候就有一个长度为100的序列,
- 文本那边同样的道理,有一个文本,通过一个linear embedding层,就会得到一些word embedding,假设word embedding也是一个长度100的序列,在得到了文本这边的序列和图像这边的序列之后,我们可以把两个序列,扔给后面的transformer模型去做模态之间的融合。
这里也有很多种做法,常见的有两种,在相关工作里会提到,这里简单说一下,要么是简单的把两个序列直接concatenate,就是连接到一起当成一个序列,直接扔给一个transformer去学,这也叫single stream 就是一条通路的网络结构。
还有一个更直接的方法,就是文本的特征先通过一些文本的模型,图像的特征过一个图像的模型,然后两个单独模态的模型,可能在某一个时间点上,再做一些融合,得到最后的结果,这也叫two stream也就是两个通道的结构。
- 但是我们刚才也提过这种用目标检测抽图像特征的方式,实在是太贵了,它的backbone就要75毫秒,后面的目标检测这些专有的rpn roi nms要占到800毫秒,所以肯定就会有人想,能不能把这个目标检测拿掉,所以就有了后面pixel bert这个工作,他就利用了这种grid fearture,也就是网格特征,其实说白了就是把一个图片扔给一个卷积神经网络,然后就把它最后一层比如说7*7的特征图拿出来,拉直了以后变成一个序列长度为49的序列了。如果你想要更多的序列,你也可以用之前的卷积层,比如之前14*14,那你就会有一个长度为196的序列。好处就是直接用一个卷积神经网络的特征图就够了,就不需要后面这一系列,直接和目标检测相关的东西了,所以一下计算复杂度就锐减到45毫秒。
- 但是ViLT论文的作者觉得这还不够,尤其是看到vit火了之后,觉得vit这个patch embedding工作的也很好,而且在vit的这篇论文里,vit的作者也对比过,前面只用一个简单的linear projection层,要使用一个res50去抽取这些图像像素级别的特征,最后发现了两个结果差不多,甚至是这种可以学习的linear projection层表现得更好。所以ViLT这里就直接照搬,把前面的CNN backbone直接就换成了一个非常简单的linear embedding层,这个时候图像和文本就完全对应起来了,图像也是打成patch然后通过一个linear embedding层,得到图像初始的token,文本也是通过一个linear embedding层,得到初始的word token,这样就可以直接都扔给transformer了。从时间上我们可以看到,这个patch linear embedding非常的快速,只要0.4毫秒,基本上什么时间都不费,比原来的800多毫秒,简直不知道快到哪里去了
然后这里除了看运行时间,还可以看一下性能,作者这里就比较了几个NLVR2这个数据集,其实是做vision reasoning的,还有就是Flikr30K上面去做text retrieval和image retrieval的任务。我们可以看到其实还是利用之前的这种目标检测的特征,达到的效果是最好的,如果换成网格特征性能下降的非常厉害,尤其是对于retrieval任务而言,文本检索性能下降了近十个点,图像检索性能下降了十几个点。ViLT算是取舍做的非常好的,它不仅比pixel bert快,性能还处于pixel bert和UNITER之间,甚至在visual reasoning任务上,ViLT甚至还比uniter高了一点点,所以从这个图看起来是非常有竞争力的
7.4ViLT的三个贡献
说完了ViLT这个方法到底干了什么事,作者就罗列了一下ViLT的三个贡献,
- 第一个就是ViLT最大的卖点,ViLT是迄今为止最简单的用来做vision language的模型,因为它除了做模态之间融合的transformer,它就没有再用别的模型了,而不像之前一样还需要一个残差网络,甚至还有一些额外的目标检测的网络结构在里面,所以说ViLT的这种设计,带来了非常显著的运行时间和参数量的减少
- 第二个贡献,作者就是说在我们减少计算复杂度的同时,我们还能保证性能不掉。因为之前也有一些工作,能把运行速度降得比较低,但是他们的性能都差了很远,而我们能够在不使用这种区域特征,或者残差网络特征的情况下达到和之前差不多的效果,这是第一次
- 第三个贡献,作者说我们还有一个第一次是说,我们在训练的时候用了更多的数据增强的方式,比如说在文本那边,我们就用了整个词mask掉的方式,在图像这边我们尝试使用了RandmAugment,这两种数据增强的方式之前在多模态领域都没有被用过,因为多模态学习总要考虑到,图像文本对之间匹配的问题,不论是给图像这边做了增强还是给文本做了增强,你很有可能得到的新的图像文本它的语义就不对了。举个最简单的例子,草地上有一只小白兔,这时候图像做一下数据增强,把颜色改了一下,它可能就不是白色的兔子了,也不是绿色的草地了,这时候新生成的图像文本对就不是一个正确的对了。所以因为有这个问题呢,之前做多模态学习的人就没有考虑用过强的数据增强的方式,因为他们担心这种问题会发生,但是ViLT这里就巧妙的利用了这些数据增强的方式,稍微改了一点,然后发现效果还是非常好,即使你有很多图像文本对,你用上数据增强以后,效果还是会更好,这对于当时的多模态领域来说也是第一次,
所以总体而言,ViLT还是提出了一个非常简单,而且强大的基线模型性能,而且也得出了很多很有意思的结论,很多对训练有帮助的小技巧,然后再加上transformer,在视觉领域大杀四方。所以在多模态领域,新工作也是如雨后春笋一般,迅速的全都冒了出来
8 背景知识
ViLT这篇论文的背景知识比后面的方法部分还要长,它的第二段已经写的有点像综述论文了,只不过没有铺开来讲而已,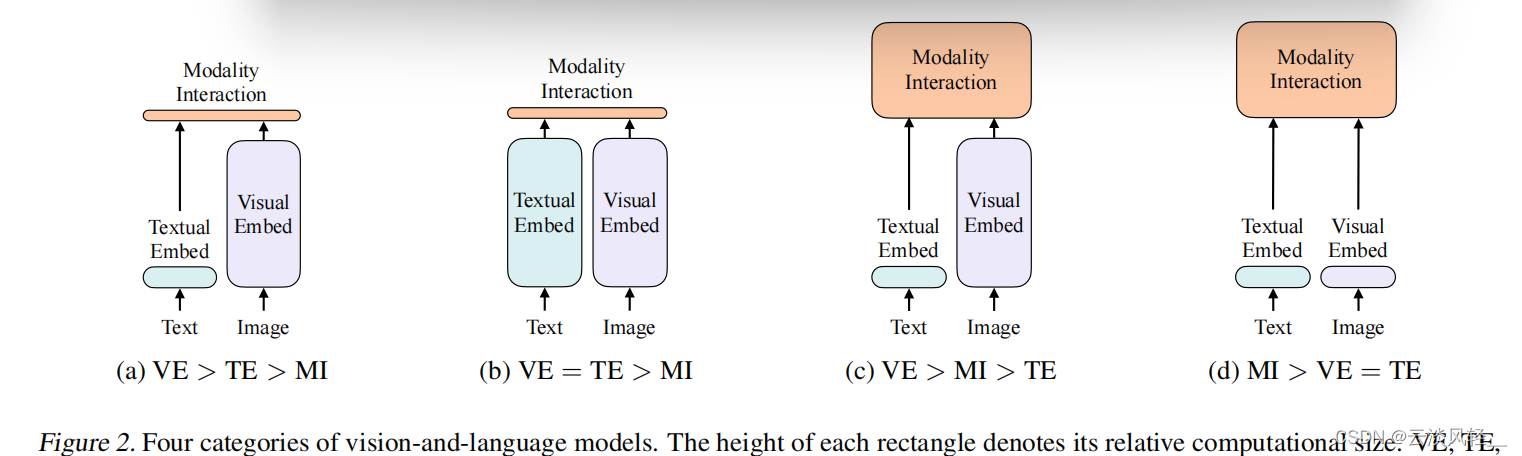
- 比如说,他刚开始2.1节就讲了一下,现在这个VLP整个这些模型,都能大概被分成哪几类,就画在了图2里
- 2.2节就讲了一下,当你有了这些图像和文本抽出来的这些token之后,怎么做模态之间的融合。
- 然后接下来因为文本那边,大家处理的都是一样的。就这个图像不一样,所以作者就把图像怎么抽特征单独拿出来写了整整一页。从刚开始大家使用这种目标检测的这种区域特征,到后来使用残差网络最后的特征图,到最新的VIT出来,用一个简单linear projection layer完成对视觉特征的抽取
8.1 2.1节VLP领域中模型的划分
2.1节,这里作者煞费苦心,为了能凸显ViLT模型的优势,而且为了能用一个很好的方式,一个很好的故事把ViLT介绍出来。作者这里甚至先做了一个总结,而且把整个vision language模型都又重新定义了一下,作者说它是根据两点把所有现在的VLP模型做了一个分类,
第一就是看图像和文本的表达力度到底平衡不平衡,具体怎么去衡量这个表达力度,作者这里说就是说你这个模型用了多少参数量、计算量是多少。因为图像和文本其实都是非常重要的模态,并没有说谁比谁更重要。所以其实理论上,他俩的比重应该差不多,不应该像现在大多数方法一样,视觉要比文本这边贵这么多。第一点就是讲怎么从各个模态里,先抽一些特征,先做一些预处理。第二点就是说两个模态怎么去融合。然后根据这两点,作者把所有现在的方法,分类成了四个类,画到了图2里,

在图2里,ve:visual embedding,怎么去抽图像特征;te:textual embedding,怎么抽文本特征;mi:modality interaction,两个模态怎么进行融合。
- 第一类,也就是比较早之前的一些工作了,比如说visual semantic embedding,就是VSE系列的工作,他们的文本端非常轻量,视觉端还是非常贵,也就是图中所示的ve远大于te,然后他们的融合也是非常轻量,就是一个简单的点乘或者一个非常浅层的神经网络
- 第二类的一个代表性的工作就是之前讲过的CLIP模型,非常的好用,它主要的特点就是图像和文本的表达力度是一样的,他用的这两个模型在计算量上基本上是等价的,这也就是他这里说的ve=te,但是他们在做模态融合的时候也是非常轻量,就直接把两个得到的特征做个点乘就结束了,所以处理clip这个模型非常适合去做抽特征,或者retrieval的任务,但是如果去做别的多模态的下游分类任务,比如说vqa或者visual reasoning,它的效果就略逊一筹,因为毕竟只是抽到两个特征,你得把他们好好的融合一下,你才能知道他们之间的对应关系是什么,一个不可学习的简单的点乘,是没办法做到深层次的分析的。
- 所以说基于此,其实前两年的还有另外一系列特别多的工作,也就是我们刚才说过的:ViLBERT,UNITER,Oscar其实都属于这一系列工作,基本前两年百分之八十的工作,都是方向c,就是文本端非常轻量,图像端基本就用的目标检测的系统,非常的贵,不仅抽特征贵,在后面做模态融合的时候也非常贵,就是后面又跟了一个transformer,就是他可能有两个模型,前面有一个visual backbone,后面还有一个大的transformer,但是就像我们在图1里看到的一样,它的性能确实不错,把各个多模态的下游任务的性能,全都刷的非常高。
- 然后作者这里就找准了机会,当他把之前的方法做了这种总结之后,它就发现对于大部分的这种视觉文本的多模态下游任务来说,模态融合一定要比较大,你得好好做这种模态融合,你最后的效果才能好,跟你之前抽的特征关系不太大,然后再加上这个vision transformer的出现,patch embedding layer直接就工作的很好,所以ViLT直接就把patch embedding拿过来,所以视觉这边抽特征也很轻量,现在他们之间的关系就变成MI>VE和TE,而且ve和te是等价的
这张图画的真的是非常好,自从ViLT这篇论文出来了,讨论这篇论文的人虽然不是那么多,但是借用这个图2的人非常的多,很多人写的博客或者学习知识的时候,都会把这个图2直接复制过去,帮助大家理解。所以这也同时告诉我们,对现有领域里比较好的方法做一个分类,是非常有助于我么加深对这个领域的理解的,而且很有可能当你做完总结之后,你也就知道当前领域的痛点在哪里,而且很有可能你就会有很多新的想法,所以说对于初入一个领域的人来说,不妨尝试去写一篇综述论文,不管他中不中稿或者中在哪,但是写这一篇论文的意义,远远大于这篇论文中稿的意义,因为它不仅能让你加深对这个领域的理解,而且还能提高你写作的能力,因为你要把几十篇甚至上百篇的论文写到一个综述论文里的时候,你的逻辑性也要非常清楚,你对他们之间的划分必须划分的非常合理,才能让你最后写出的这篇综述论文看起来非常合理,非常有信服力
8.2 2.2之前的方法都是怎么做模态融合的
在2.1里作者介绍完了整个领域里对模型的划分,接下来2.2作者就大概介绍一下之前的方法都是怎么做模态融合的,但这一段写的非常的简短,因为确实也没有什么好讲的,主要之前的方法就被分成了两类,
一个就是single-stream 方法,另外一种是dual-stream,single-stream顾名思义就是只用一个模型,那怎么用一个模型处理两个输入呢,最简单的就是我把这两个输入直接concat起来,把两个序列直接变成一个序列,就可以用一个模型去处理了,至于他们之间怎么交互我不管,transformer自己去学就好了,
对于dual-stream来说,就是我有两个模型,这两个模型先各自对各自的输入做一些处理,充分去挖掘单独模态里包含的信息,然后在后面的某一个时间点,在做融合,比如说加一些transformer layer,
整体上来看这两个方向的工作都非常多,而且他们的性能也都差不多。dual-stream在有些情况下稍微好一点,但是dual-stream就像作者这里说的那样,它引入了更多的参数,因为毕竟刚开始是两个模型,后面还有一个模型要做融合,他肯定是更贵一些,所以作者这里还是选择这种single-stream的方法,就是说,一旦抽完文本和图像特征之后直接就把他们concat到一起,然后送给一个transformer去学就好了
8.3 2.3在融合之前特征该怎么抽取(文本、图像怎么抽特征)
2.2说完了模态之间怎么融合,2.3作者就说了一下在融合之前,这些特征该怎么抽取,因为对于大部分VLP模型来说,他们文本端都是用一个预训练好的bert里的tokenizer,所以都是一样的,而且还很轻量,所以这里就不过多复述了,所以2.3主要就是讲的视觉怎么抽特征
作者这里就先从这种区域特征开始,就讲了一下之前的方法,是怎么把一个目标检测系统嵌入到多模态学习里面的,大概就是分了三步,
- 就是说当你给定一个图像之后,它先通过一个backbone,比如一个resnet101去抽一些特征,
- 抽完特征之后第二步是有一个rpn网络抽一些ROI出来,然后再做一次NMS把ROI降到一个固定的数量,这个数量其实就是序列的长度了,当你得到这些bonding box之后。
- 第三步就是把这些,把这些bondingbox通过ROI head就能得到一些一维的向量,而这些就是本文里说的region feature,
然后作者在这里说,虽然这种方法听起来很合理,你把一个连续的图片变成了一些离散的bonding box,然后每个box都有一个对应的特征,所以说这就跟文本那边匹配起来了,但是整个过程非常贵,即使现在目标检测我们想把它做的更轻量,或者做的更实时化,而且现在很多模型确实也跑得很快,但是你整个这一套操作下来,你肯定是不如一个简单的CNN的backbone,或者说只有一层的patch embedding来的快,
所以作者接下来就又讨论一下grid feature,就怎么用一个预训练好的CNN,直接把他的特征图抽出来,就能拿到grid feature,但可惜用grid feature虽然比用region feature要便宜一些,但它还是相对而言比较贵的,而且它的性能也非常不好,我们刚才在图一里看到,它有的任务降了十几个点,这个性能的下降大家一般是不愿意接受的,
所以作者最后就自然而然引出了他们的方法,就是说借鉴与vit的patch embedding层,我直接就用一层patch projection层就把这个图像特征抽了,比之前用一个卷积神经网络的backbone或者甚至用一个目标检测的系统去做要快很多倍,而且效果基本还能持平,不怎么掉点,这个框架肯定就非常具有吸引力了,大家接下来肯定就想在它上面再去做进一步的修改,而不是在之前那一套框架,就是图2 c里那种继续去缝缝补补做改进了,所以说ViLT确实算一个里程碑式,或者说比较有影响力的工作了
9 模型结构
介绍完这些所有的背景工作,接下来是文章的主体部分,第三段就在这里简单介绍一下,模型的结构,
9.1 模型是什么,输入输出是什么
 但因为确实很简单,模型就是一个transformer,前面就是两个linear embedding层,很多概念技巧都是之前transformer那边有的,所以并没有太多可以讲的新的东西,然后模型的训练所用的目标函数就是3.2节,其实也跟之前的方法差不多,就是图像文本匹配的loss,还有就是NLP专属的这种mask language modeling loss。
但因为确实很简单,模型就是一个transformer,前面就是两个linear embedding层,很多概念技巧都是之前transformer那边有的,所以并没有太多可以讲的新的东西,然后模型的训练所用的目标函数就是3.2节,其实也跟之前的方法差不多,就是图像文本匹配的loss,还有就是NLP专属的这种mask language modeling loss。
那你可能会问,那这篇文章的方法创新点到底在哪呢?那其实除了把图像特征这边从目标检测换成一层的patch embedding层之外,它主要就是在训练的过程中,有一些非常有用的技巧,比如说在3.3节,他就用了NLP那边比较常用的一个技巧,whole word masking,这种做法在很多论文中都被证实非常有效,图像这边作者就用了很强的这个数据增强,用了RandAugment,效果提升也非常多,而且之后的大部分工作从ViLT开始也都纷纷使用了RandmAugment作为图像这边的数据增强
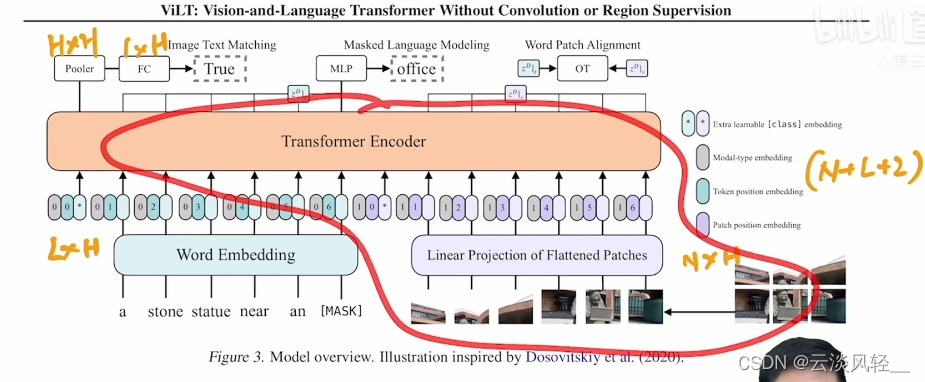
我们回到第三节,也就是文章的主体方法部分,这里其实就照着这个图3讲就完全够了,如果需要一些细节可以再去看文字,总之ViLT模型就像作者说的一样,是一个single stream的方法,它只有一个模型也就是这里的transformer encoder。  它的输入都在下面,分别一个是文本,一个是图像
它的输入都在下面,分别一个是文本,一个是图像
文本就是说,如果你有一个句子,先过一个bert的tokenizer(),就会得到一些word embedding,也就是文本这边的序列,假设我们文本这边的序列长度是L,这个h就是那个token embedding的维度,一般对于transformer这个base模型来说他就是768,所以这里的这个输入其实就是一个L*H的矩阵,
同样的道理,因为有了vison transformer之后,这个图像也可以打成patch,每一个patch过一个patch embedding就会变成这样一系列的token,假设图像这边的token长度是n,它的维度也是H就是768,所以图像这边就是n*H的矩阵,
这里面五颜六色的颜色都代表什么呢,首先是灰色的,指代你是什么模态,我们可以看到文本这边全是000,意味着0就是指的文本模态,1就指的是图像模态,那为什么需要有这个0和1的modeltype的embedding呢,至于对ViLT模型或者说对于这种single stream的模型方法来说,它们是把图像和文本的输入直接拼接在了一起,所以如果你不告诉模型哪块是文本哪块是图像的话,他自己是不知道的,因为在他看来这就是一系列的token,所以可能不利于它学习,如果告诉它了哪块是哪块,他可能就能互相去找,他们之间的关系能够学的更好。星号,它其实就是我们之前讲过的cls token,classing embedding,分别代表文本和图像的cls token。接下来就是老生常谈的位置编码,对于文本来说也有位置编码123456,对于图像来说也有patch的embedding也是123456,这里需要注意的是,你别看这三个东西是放在一起的,好像感觉是在拼接,但其实不是,这三个东西是加在一起的,也就是模态类型和位置编码和文本本身的embedding是加在一起的,至于在哪concat呢,每三个作为一个整体concat在一起变成了整个的序列,这样就完成了transformer模型的输入,这个输入序列的长度是多少呢,其实就是1+L+1+n,整个的输入就是(L+N+2)*H,序列长度L,N 图像token的长度,H token的维度。
讲完了输入的序列是这么长,经过transformer之后呢,输出的序列还是这么长
9.2 怎么训练ViLT
至于怎么训练ViLT这个模型,文章说他们用了两个loss,但其实在图文匹配loss,这里还用了一个小的loss(Word Patch Alignment)。都是想算一下文本和图像之间的距离是多少,他们之间有多相似,
9.2.1 图文匹配loss
具体来说图文匹配loss是人为设计的一个任务,就是说,本来你文字和图片应该是配对的,如果这时候我把图片随机换成数据集里任意一张别的图片,那你这张随机的新的图片和原来的旧的文本,它就不是一个对儿了,这个时候我把ground truth这一对儿和新生成的不是一对儿的数据,就可以把他们都通过网络得到一些特征,我看看能不能根据模型给我的特征去判断出来哪个是真的图片文本对,哪个是假的图片文本对,所以这里其实是一个二分类的任务,所以顾名思义,也就是看图片文本到底匹配不匹配,这里细致一点说其实它的输出,就是整个序列输出的第一个位置上,就跟之前用clstoken一样

整个序列输出的第一个位置输出的特征是1*h,然后这里这个pooler其实是一个matrix,就相当于是一个权重矩阵一样,它是h*h,所以说1*h*h,最后就会得到一个1*h的输出,这个输出再通过一个fc层,去做二分类任务就好了。然后像作者说的一样,大部分的VLP模型的训练,就用的是图文匹配的loss,
9.2.2 Word Patch Alignment loss
但是在ViLT这篇论文里,作者还用了一个附加的loss,叫做word patch alignment他也是想算一下图文之间的相似度如何,但它是通过另外一种方法算的,他利用了optimal transport就是最优运输理论,这是一个能把几何和概率连在一起的很好的工具,可以理解为作者就是把
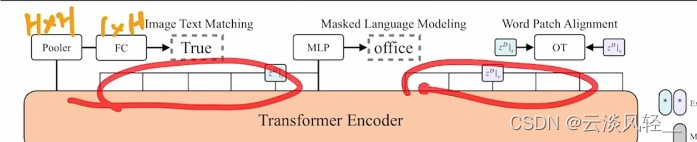 文本和图像的输出当做一个概率分布,然后计算一下他们这两个分布之间的距离,
文本和图像的输出当做一个概率分布,然后计算一下他们这两个分布之间的距离,
 因为输入是一个图文对儿,那么按道理来说是匹配的,所以作者也就希望这里的距离越小越好
因为输入是一个图文对儿,那么按道理来说是匹配的,所以作者也就希望这里的距离越小越好
9.2.3 Masked Language Modeling
除了这两个loss之外。作者还专门针对文本,做了一个文本上面的目标函数,也就是nlp常用的完形填空,就是随机mask掉一个单词,然后想把这个单词重建出来,基本上现在只要涉及NLP的任务,大家多多少少都会把这个完形填空的loss加上,因为确实比较好用。那为什么不给图像这边也加上完形填空loss呢?毕竟当时,beit和mae这些工作都还没有出来,图像这边没法很有效的去做重建的任务,所以作者就没有加,现在有没有这个呢?其实最近就已经出来新的工作了,叫做vlbeit其实就已经把视觉这边无监督的重建loss加进去
这就把方法讲完了,我们可以看到ViLT确实非常简单,如果把图像也看成文本的那些token的话,其实输入全是文本,经过一个transformer,最后再做完形填空,这其实就是个bert。
如果只看图片的这个部分,其实就是个VIT,所以作者这里也不得不说这张图是收到vit的启发画出来的
9.3 训练过程中好用的小技巧:文本上whole word masking
讲完了模型的大体结构,ViLT的另外两个非常有用的小点,第一个就是whole word masking,为什么要这么做呢?看作者的举例就可以知道,作者这个例子举得还是非常好的,就是如果你有一个单词,比如说giraffe,你先用tokenizer,比如说bpe或者bert这些,把它p成小的词根的时候,他就变成了这种,
 就跟我们汉字能p成偏旁部首一样,这些小部分才是真正的token,这个时候你要说我在这个token的序列上把raf给mask掉,其实以gi开头,以fe结尾的单词不多,那就会导致模型很容易就猜出来,根本就不用学,记住就行了,这就会导致一个什么问题呢?就是说我真的在做多模态这些任务的时候,我根本不需要借助图像这边的信息,就可以直接判断中间的是raf,那这个loss就失去意义了,就有点像是学了一个shortcut,为了避免这种情况的发生,作者说,那就还不如把整个单词给mask掉,这个时候如果想把giraffe重建出来,你肯定得借助图像的信息,因为如果原来的句子是在草原上有一个长颈鹿,如果把长颈鹿直接抹掉,他可以换成任何一个动物,所以这时候句子重建就变的非常困难,只能通过图像那边获得信息。所以作者通过把nlp那边mask掉整个单词的方式,非常巧妙地进一步加强了图像和文本之间的联系
就跟我们汉字能p成偏旁部首一样,这些小部分才是真正的token,这个时候你要说我在这个token的序列上把raf给mask掉,其实以gi开头,以fe结尾的单词不多,那就会导致模型很容易就猜出来,根本就不用学,记住就行了,这就会导致一个什么问题呢?就是说我真的在做多模态这些任务的时候,我根本不需要借助图像这边的信息,就可以直接判断中间的是raf,那这个loss就失去意义了,就有点像是学了一个shortcut,为了避免这种情况的发生,作者说,那就还不如把整个单词给mask掉,这个时候如果想把giraffe重建出来,你肯定得借助图像的信息,因为如果原来的句子是在草原上有一个长颈鹿,如果把长颈鹿直接抹掉,他可以换成任何一个动物,所以这时候句子重建就变的非常困难,只能通过图像那边获得信息。所以作者通过把nlp那边mask掉整个单词的方式,非常巧妙地进一步加强了图像和文本之间的联系
9.3 训练过程中好用的小技巧:图像上加数据增强
说完了文本这边的小技巧,那么图像这边有什么小技巧可以用呢?那毋庸置疑图像这边最好用最常用的技巧就是加数据增强了,但可惜在之前的那些多模态的方法里,尤其是图2c里面画的那种,借鉴于目标检测系统的多模态学习,它是没法使用数据增强的,因为他们在训练的时候都是提前把特征抽出来存在本地硬盘里了,原图长什么样,这个特征就是什么样,如果你想把原图做数据增强,那特征就要重新抽取,这就变得很麻烦而且很贵了,所以没人这么做过,也就意味着之前所有那些工作,包括21年的工作,都没有用什么数据增强,这听起来就很不合理对吧,明明你知道数据增强很有用却不用,
所以作者这里就想,既然我把它做成端到端了,那我肯定要上数据增强,效果应该肯定是会变好的,所以呢作者这里也不废话直接就上了最好的数据增强randaugment,但是作者这里也做了稍微的改动,我们之前也说过多模态学习主要是看图像和文本的匹配,你这个图像如果做了数据增强,会导致和文本不匹配了,作者这里针对这个问题做了很小的改动,我用了之前randaugment里所有的策略但是有两个不用,就是color inversion和cutout,这样就最大程度的保证了图像和文本尽可能的还能匹配在一起,作者这里肯定也是进行了相当多的调参,最后才得到最优的结果
10 实验
说完了方法,最后来看一下实验部分
10.1 数据集
ViLT在预训练的阶段就用了四个数据集

这四个数据集合起来,一般大家把它叫做4million的一个设置,是因为把数据集的图片的个数加在一起大概是400万出头,所以接下来大家都沿用了这套设定,事实上这些数据集都有一些自己的特性,
- 比如说coco数据集,每个图片都对应了5个caption,因为针对一个图片,每个人可能都有自己的方式去描述这个图片,这样当初在建这个coco数据集的时候,作者就给每个图片都配了5个caption,这样不论你的模型生成的caption长什么样,只要能和我这5个caption尽可能的相似,我就认为你生成的还不错,所以这也就意味着虽然coco这个数据集,只有十万个图片,但是它有效的图文对其实是有50万个的,它的标题也相对较长,就是每个标题平均的单词数都超过了10个,
- 像visualGenome这个数据集就更夸张了,虽然只有10万个图片,但是它对应的标题数有500万,因为它这个标题太多了,所以其实标题的长度并不长,基本就是5、6个单词这么长,很短。
- 然后对于剩下两个数据集来说,都相对大一些,而且这两个数据集都是一个图片对应一个标题,标题长度也比较长,
所以正是因为数据集的这些特性,所以大家都喜欢用你这个数据集有多少图片来衡量你这个数据集有多大,而不是你有多少图文对,然后还要注意的是,前两个数据集可以下载到源数据,但是后两个因为是提供的链接,已经不能下到完整的数据了。
10.2 对比实验
10.2.1 分类任务
说完了预训练的数据集,接下来我们看一下在下游任务上ViLT的性能和之前的方法比到底如何。首先就看在VQA和NLVR(自然语言视觉推理)这两个任务上的表现,这两个都算是多模态里的分类任务,所以作者就把它放到一起了
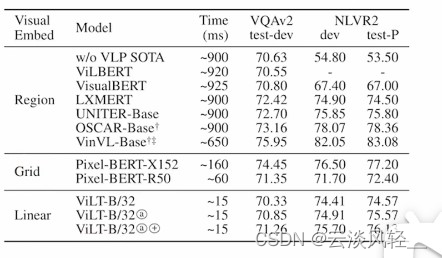
可以看到先是用了区域特征,然后是网格特征,然后是ViLT的方法linear embedding
- 第一列:运行时间快了非常多
- 第二列:结果可以看到用了区域特征这些的效果是很好的,其实在比较新的VLP模型里,比较差的visualBERT,也是70 67 67 与ViLT相比其实在VQA上基本上保持不变的,到了NLVR2这个数据集上,ViLT表现更好,但如果跟之前最强的比,比如oscar,vinvl比,就是远远不如了
所以总结来说就是ViLT取了一个比较好的tradeoff折中,结合起来比之前的方法都好
10.2.2 检索任务
除了分类任务,多模态里面最重要的另一个任务就是检索任务,检索一般大家都在两个数据集上做,flikr30k和coco数据集,分了两个表格来说,上面的表格是zeroshot,下面做的微调,zeroshot的意思就是我训练好这个模型之后,就固定住这个模型,直接拿这个特征过来做检索,是不在两个数据集上去做微调的。下面的表格就是在这两个数据集上去做微调
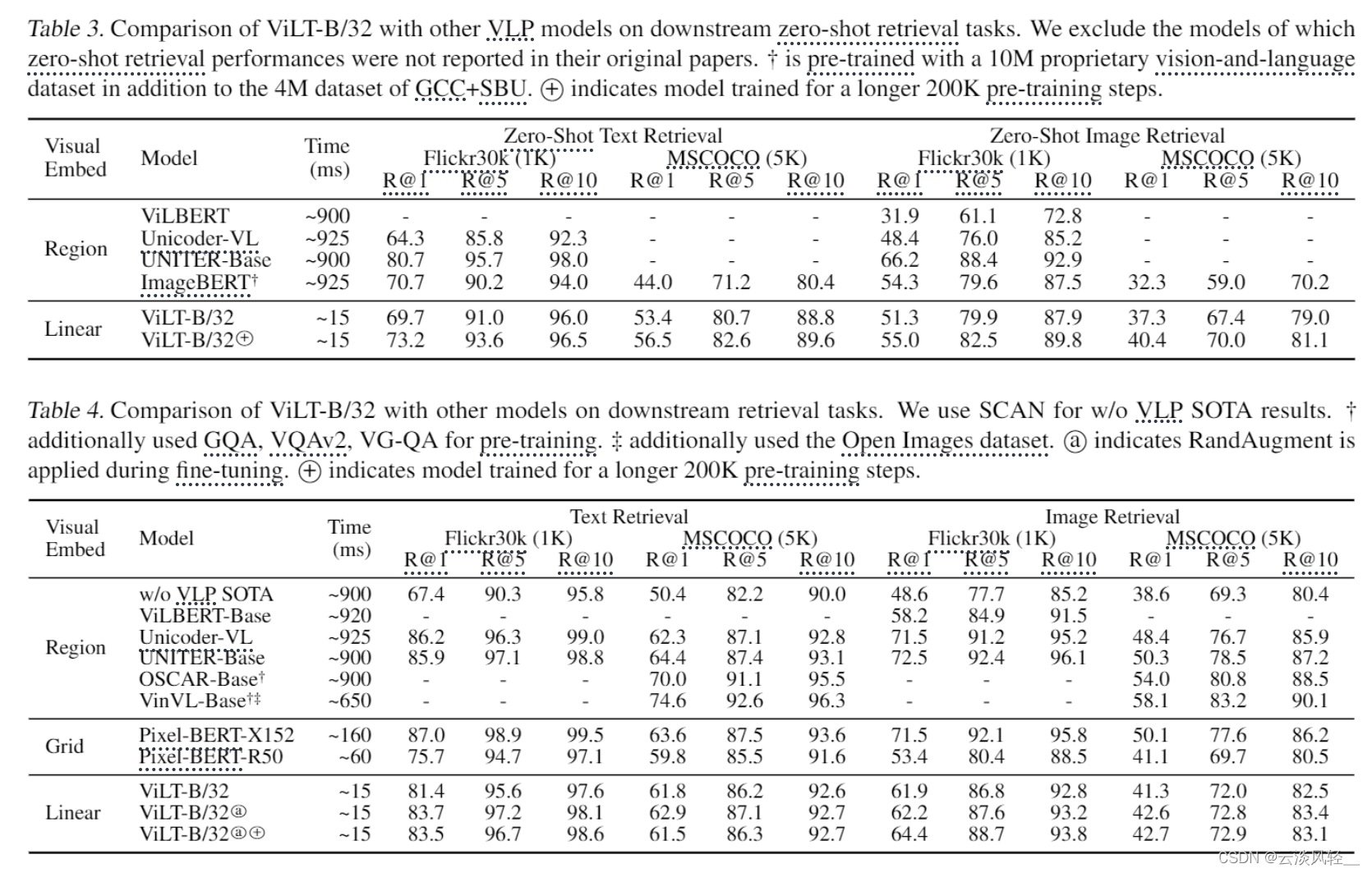
所以上面的性能是比下面低得多的,毕竟zeroshot是没有训练的
在这两个数据集上和之前两个数据集上的结论差不多,就是取舍做的比较好,速度很快,性能不掉。总之就是ViLT的性能还没有做上去,但是在简易性和快速性上做的非常好,这个其实挺好的,因为性能不做那么高,接下来大家才会在你的上面继续去做改进,然后把你刷高,如果你上来就做了一个特别好的分数,直接把这个数据集刷爆了,其实也就没有人再去跟进你的工作了,但是说白了这篇论文其实给了一个很好地insight,大家接下来顺着他往后做,但是其实他这个工作本身并不是那么容易跟进的,有几个原因,首先他是用pytorch lightning写的代码这跟原生的pytorch还是很不一样的,上手有一定的难度。第二就是像之前说的,它需要用64个32g的v100GPU训练三天,这个代价其实是很多人都不能承受的。所以接下来很快在【1】 Align before Fuse: Vision and Language Representation Learning with Momentum Distillation nips21的时候,就出了另外一个工作ALBUF,那个工作训练起来就很轻量,单机8卡训练两三天就可以了,所以接下来大家都会顺着albuf往后做,
【2】 BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation 接下来ALBUf的作者又推出了BLIP,
【3】 Masked Unsupervised Self-training for Zero-shot Image Classification 最近又推出了mast,这一系列工作做的都非常好,
10.3 消融实验
最后看一下消融实验,因为我们可以看一下到底提出来的哪个东西效果最好,对最后的性能提升最大。
作者上来首先验证了,训练时间到底有多管用
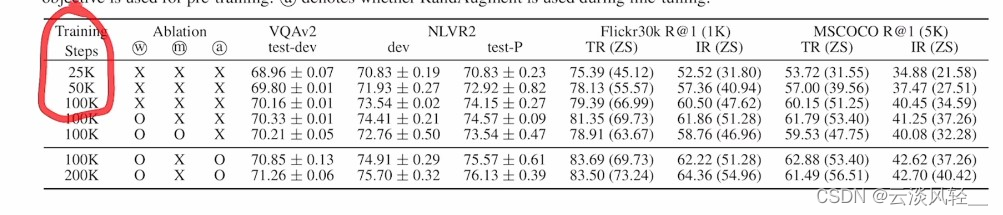
因为有很多自监督或者无监督的工作中,他们都说只要你训练的时间越长,性能就越好,比如之前讲过的moco simclear bull,像MAE他都预训练到1600个epoch去了,所以说它的训练时间非常长,作者这里也就做了一下尝试,看到底25k 50k 100k对最后的性能有多大的影响,我们可以看到确实性能是在一直增加的,但是增加的并不多,我估计作者做消融实验,其实也是因为如果你(100k设置)64个GPU训3天的话是在是吃不消,所以作者想在跑这些消融实验的时候,尽可能跑一个短一点的,只要能看出来趋势,看出来谁比谁好就可以了,所以他们发现,估计降到最后25k的时候,性能并没有下降多少,还能看出规律,所以他们的各种消融实验应该是在25k上做的,但是刷分肯定是要用最后的100k去训练,然后在得到100k的baseline之后,就慢慢网上加东西,先是把w加上去(whole word masking),确实有一些提升,但是提升还是比较小的。
然后作者这里还尝试了一个有意思的东西,他在论文主体部分没有说,但是在实验中做了,就是他们也像vit一样在图像这边做了一下完形填空,其实也就是重建图像了,他们管这个叫MPP,但确实效果不怎么样,因为当时重建图像还不work,一直到后面beit和mae才work,所以作者当时就没有用m,就用了两个技巧,
我们就会发现图像这边的数据增强还是不同凡响,性能确实提升了很多,是比nlp那边的整个单词遮盖还要有效,这些消融实验全部做完,作者一看我已经找到最佳组合了,所以我把它再训练的久一点变成200k,最后就得到了他要报告的结果
文章后面还有一些消融实验,还有一些可视化就跳过了
11结论
这个结论写的稍微有点非主流,就是,不光写了结论,还把未来工作写进去了,这个未来工作确实写的很好,可以一一来过一下
首先我们先来看结论,作者说在论文里我们展示了一个极小化的VLP模型,ViLT,他既没有用原来特别贵的embedding的方式,比如说用fasterRcnn或者残差网络直接抽特征,我们就像vit里一样直接用了一个patch embedding层就把图像抽特征这部分解决了,从而让我们的模型整体结构又简单速度又快,结果还好,但是因为确实没有比过之前的sota,作者就说我认识到我们的性能不是最好的,但是我只是说ViLT只是想证明我既不用卷积的监督也不用区域的监督,我用一个最简单的baseline模型就能达到很好的性能,就有点像之前论文里写的embarrassing simple baseline,就是非常尴尬特别简单的baseline,就比很多很好很复杂的方法做的好了,ViLT这里也就是想表达这个意思,然后他就顺带手介绍了几个比较有前途的扩展方向,
- 规模,transformer都是越大越好,数据集越大越好,所以这里也不例外,作者说如果你有更多的数据你肯定效果就更好,比如CLIP,或者如果把模型做大,做成ViLTlarge或者huge效果肯定也更好。albuf用了14million,加入了12GCC数据集。
- 图像重建,mae工作,也已经有人把mae的loss用到多模态学习里了
- 数据增强,消融可以看出就是效果很好 ,也能提高数据的有效性,可能就不需要这么多数据了




![[原创][1]探究C#多线程开发细节-“Thread类的简单使用“](https://img-blog.csdnimg.cn/9a161eea09e04fecab169b4ef51de48c.png)