上一节我们运行了 gcc 使用的词法解析器,使用它从.l 文件中生成对应的词法解析程序。同时我们用相同的词法规则对 golex 进行测试,发现 golex 同样能实现相同功能,当然这个过程我们也发现了 golex 代码中的不少 bug,本节我们继续对 golex 和 flex 进行比较研究,首先我们在上一节.l 文件的基础上增加更多的判断规则,其内容如下:
{
/*
this sample demostrates simple recognition: a verb/ not a verb
*/
%}
%%
[\t ]+ /* ignore witespace */;
is |
am |
are |
were |
was |
be |
being |
been |
do |
does |
did |
will |
would |
should |
can |
could |
has |
have |
had |
go {printf("%s: is a verb\n", yytext);}
very |
simply |
gently |
quitely |
calmly |
angrily {printf("%s: is an adverb\n", yytext);}
to |
from |
behind |
above |
below |
between {printf("%s: is a preposition\n", yytext);}
if |
then |
and |
but |
or {printf("%s: is a conjunction\n", yytext);}
their |
my |
your |
his |
her |
its {printf("%s: is a adjective\n", yytext);}
I |
you |
he |
she |
we |
they {printf("%s: is a pronoun\n", yytext);}
[a-zA-z]+ {printf("%s: is not a verb\n", yytext);}
%%
main() {
yylex();
}
将上面内容存储城 ch1-03.l然后运行如下命令:
lex ch1-03.l
gcc lex.yy.c -o ch1-03
于是在本地目录就会生成 ch1-03 的可执行文件,通过./ch1-03 运行该程序,然后输入文本如下:

我们将相同的词法规则内容放到 golex 试试,于是在 input.lex 中输入内容如下:
%{
/*
this sample demostrates simple recognition: a verb/ not a verb
*/
%}
%%
is|
am|
are|
was|
be|
being|
been|
do|
does|
did|
will|
would|
should|
can|
could|
has|
have|
had|
go {printf("%s is a verb\n",yytext);}
very|
simply|
gently|
quietly|
calmly|
angrily {printf("%s is a adverb\n", yytext);}
to|
from|
behind|
above|
below|
between {printf("%s is a preposition\n", yytext);}
if|
then|
and|
but|
or {printf("%s is a conjunction\n", yytext);}
their|
my|
your|
his|
her|
its {printf("%s is a adjective\n", yytext);}
I|
you|
he|
she|
we|
they {printf("%s is a pronoun\n", yytext);}
[a-zA-Z]+ {printf("%s is a not verb\n", yytext);}
(\s)+ {printf("ignoring space\n");}
%%
int main() {
int fd = ii_newfile("/Users/my/Documents/CLex/num.txt");
if (fd == -1) {
printf("value of errno: %d\n", errno);
}
yylex();
return 0;
}
然后执行 golex 程序生成 lex.yy.c,将其内容拷贝到 CLex 项目的 main.c,然后编译。在 num.txt 中添加内容如下:
did I have fun?
I should have had fun
he and she has fun from the park
they are enjoying the day very much
运行 CLex 项目,所得结果如下:
Ignoring bad input
did is a verb
ignoring space
I is a pronoun
ignoring space
have is a verb
ignoring space
fun is a not verb
Ignoring bad input
Ignoring bad input
I is a pronoun
ignoring space
should is a verb
ignoring space
have is a verb
ignoring space
had is a verb
ignoring space
fun is a not verb
Ignoring bad input
he is a pronoun
ignoring space
and is a conjunction
ignoring space
she is a pronoun
ignoring space
has is a verb
ignoring space
fun is a not verb
ignoring space
from is a preposition
ignoring space
the is a not verb
ignoring space
park is a not verb
Ignoring bad input
they is a pronoun
ignoring space
are is a verb
ignoring space
enjoying is a not verb
ignoring space
the is a not verb
ignoring space
day is a not verb
ignoring space
very is a adverb
ignoring space
much is a not verb
可以看到 CLex的输出结果跟 flex一致,这意味着golex 和 flex 目前在功能上等价。可以看到当前我们的词法解析程序不够灵活,每次相应增加新的解析规则或是要判断新单词时,我们需要更改.lex 文件,然后重新编译,执行并生成新的 lex.yy.c 文件。
下面我们希望能做到不要重新编译执行 golex,我们也能动态识别新增加的单词。这里我们需要使用符号表的方法,同时我们需要在.l 或.lex 文件中设置更加复杂的规则和代码,首先我们定义模板文件的头部,内容如下:
%option noyywrap
%{
/*word recognizer with a symbol table*/
enum {
LOOKUP = 0,
VERB,
ADJ,
ADV,
NOUN,
PREP,
PRON,
CONJ
};
int state;
int add_word(int type, char* word);
int lookup_word(char* word);
%}
在上面内容,我们先定义一系列命令关键字,也就是当我们在命令行输入 “verb"时,state 变量的值就是 verb,此时 add_word 将把用户在 verb 命令之后的单词作为类型 verb 加入到符号表中。此时用户输入的单词"verb”, “ADJ"等都会作为命令来使用,这些词就相当于编程语言中的关键字。函数 add_word 将把用户输入的单词加入到符号表对应类别,例如"verb has”,这条命令就会将单词has加入到符号表,并且设置其类型为 verb。lookup_word 用于在符号表中查询给定单词是否已经存在。
我们看模板文件的接下来部分:
\n {state = LOOKUP;}
^verb {state = VERB;}
^adj {state = ADJ;}
^noun {state = NOUN;}
^prep {state = PREP;}
^pron {state = PRON;}
^conj {state = CONJ;}
[a-zA-Z]+ {
if (state != LOOKUP) {
add_word(state, yytext);
}else {
switch(lookup_word(yytext)) {
case VERB: printf("%s: verb\n", yytext); break;
case ADJ: printf("%s: adjective\n", yytext); break;
case ADV: printf("%s: adverb\n", yytext); break;
case NOUN: printf("%s: noun\n", yytext); break;
case PREP: printf("%s: propsition\n", yytext); break;
case PRON: printf("%s: pronoun\n", yytext); break;
case CONJ: printf("%s: conjunction\n", yytext); break;
default:
printf("%s: don't recognize\n", yytext); break;
}
}
}
%%
可以看到上面代码比较复杂,首先它规定如果用户输入的是换行,那么程序进入 LOOKUP 状态,后续输入的字符串就会在符号表中进行匹配。如果在一行的起始用户输入的是关键字例如 verb, adj 等,那么程序进入单词插入状态,如果命令是 verb,那么后面输入的字符串都会以 verb 类型加入到符号表,其他命令例如 adj, adv 等的逻辑也相同。
我们看模板文件第三部分的内容:
main() {
yylex();
}
struct word {
char* word_name;
int word_type;
struct word* next;
};
struct word* word_list;
extern void *malloc();
int add_word(int type, char* word) {
struct word* wp;
if (lookup_word(word) != LOOKUP) {
printf("!!! warning: word %s already defined\n", word);
return 0;
}
wp = (struct word*)malloc(sizeof(struct word));
wp->next = word_list;
wp->word_name = (char*) malloc(strlen(word)+1);
strcpy(wp->word_name, word);
wp->word_type = type;
word_list = wp;
return 1;
}
int lookup_word(char* word) {
struct word* wp = word_list;
for(; wp; wp = wp->next) {
if (strcmp(wp->word_name, word)==0) {
return wp->word_type;
}
}
return LOOKUP;
}
在上面代码中,我们用一个列表来存储插入的单词,每个插入单词对应一个 Word 结构,它包含了单词的字符串,类型,还有指向下一个 Word对象的指针。lookup_word 函数遍历整个列表,看看有没有与给定字符串匹配的单词,add_word新增加一个 Word 结构,将给定字符串写入 Word 结构的 word_name 对象,设置其类型,也就是 word_type 的值,然后插入队列的开头。
将上面内容存为文件 ch1-04.l,使用如下命令构建 lex.yy.c:
lex ch1-04.l
gcc lex.yy.c -o 1-04
我们看看生成程序 1-04 的执行效果:

为了实现对应功能,GoLex 需要做相应修改,它需要做到如果输入是从控制台进来,那么每次读完一行数据后,它下次还需要再次从控制台读取,因此我们需要在 CLex 程序中增加一个 ii_console 函数,它判断当前输入是否来自控制台,在 input.c中添加如下代码:
int ii_console() {
//返回输入是否来自控制台
return Inp_file == STDIN;
}
同时在 l.h 中增加该函数的声明:
extern int ii_console();
接下来我们需要修改 yywrap,它需要判断当前输入是否来自控制台,如果是,那么它要再次打开控制台获取输入,在 GoLex中的 lex.par 中修改 yywrap 如下:
int yywrap() {
//默认不要打开新文件
if (ii_console()) {
//如果输入来自控制台,那么程序不要返回
ii_newfile(NULL);
return 0;
}
return 1;
}
在上面代码实现中,如果输入来自控制台,那么 ii_console 返回 1,ii_newfile 调用时传入 NULL,输入系统就会再次打开控制台,然后等待用户输入。同时在这次比较中我也发现 GoLex 有 bug,那就是在 LexReader 的Head 函数中,当我们从输入读入一行字符串时,我们没有检测读入的是否是空字符串,如果是空字符串,我们需要继续读入下一行,因此在 LexReader.go 中我们做如下修改:
func (l *LexReader) Head() {
/*
读取和解析宏定义部分
*/
transparent := false
for l.scanner.Scan() {
l.ActualLineNo += 1
l.currentInput = l.scanner.Text()
if l.Verbose {
fmt.Printf("h%d: %s\n", l.ActualLineNo, l.currentInput)
}
//bug here
//如果读入的行为空,那么重新读入下一行
if len(l.currentInput) == 0 {
continue
}
if l.currentInput[0] == '%' {
。。。。
有了上面修改后,GoLex 基本上也能做到前面 flex 程序的功能,但还有一个问题,那就是如果我们把前面 ch01-4.l 中的如下所示的代码直接放到 input.lex 中,GoLex 就会崩溃:
[a-zA-Z]+ {
if (state != LOOKUP) {
add_word(state, yytext);
}else {
switch(lookup_word(yytext)) {
case VERB: printf("%s: verb\n", yytext); break;
case ADJ: printf("%s: adjective\n", yytext); break;
case ADV: printf("%s: adverb\n", yytext); break;
case NOUN: printf("%s: noun\n", yytext); break;
case PREP: printf("%s: propsition\n", yytext); break;
case PRON: printf("%s: pronoun\n", yytext); break;
case CONJ: printf("%s: conjunction\n", yytext); break;
default:
printf("%s: don't recognize\n", yytext); break;
}
}
}
这是因为 GoLex 的 RegParser 在解析正则表达式时,它一次只读入一行。上面代码中正则表达式在匹配后对应的处理代码跨越了多行,因此这种格式会导致我们 RegParser 解析出错。一种解决办法是修改 RegParser 的解析方法,让他能解析跨越多行的匹配处理代码,这种修改比较麻烦,我们暂时放弃。一种做法是将上面多行代码全部放入一行,但这样会导致一行内容长度过长,使得模板文件很难看,目前我们的解决办法是用一个函数将这些代码封装起来,例如使用一个 Handle_string()函数来封装上面代码,于是上面部分修改如下:
[a-zA-Z]+ {handle_string();}
%%
void handle_string() {
f (state != LOOKUP) {
add_word(state, yytext);
}else {
switch(lookup_word(yytext)) {
case VERB: printf("%s: verb\n", yytext); break;
case ADJ: printf("%s: adjective\n", yytext); break;
case ADV: printf("%s: adverb\n", yytext); break;
case NOUN: printf("%s: noun\n", yytext); break;
case PREP: printf("%s: propsition\n", yytext); break;
case PRON: printf("%s: pronoun\n", yytext); break;
case CONJ: printf("%s: conjunction\n", yytext); break;
default:
printf("%s: don't recognize\n", yytext); break;
}
}
}
综上所述,GoLex 中 input.lex 的文本内容如下:
%{
#include<string.h>
enum {
LOOKUP = 0,
VERB,
ADJ,
ADV,
NOUN,
PREP,
PRON,
CONJ
};
int state;
int add_word(int type, char* word);
int lookup_word(char* word);
void handle_string();
%}
%%
^verb {state = VERB;}
^adj {state = ADJ;}
^noun {state = NOUN;}
^prep {state = PREP;}
^pron {state = PRON;}
^conj {state = CONJ;}
(\n) {state = LOOKUP;}
[a-zA-Z]+ {handle_string();}
%%
int main() {
yylex();
return 0;
}
struct word {
char* word_name;
int word_type;
struct word* next;
};
struct word* word_list;
extern void *malloc();
int add_word(int type, char* word) {
struct word* wp;
if (lookup_word(word) != LOOKUP) {
printf("!!! warning: word %s already defined\n", word);
return 0;
}
wp = (struct word*)malloc(sizeof(struct word));
wp->next = word_list;
wp->word_name = (char*) malloc(strlen(word)+1);
strcpy(wp->word_name, word);
wp->word_type = type;
word_list = wp;
return 1;
}
int lookup_word(char* word) {
struct word* wp = word_list;
for(; wp; wp = wp->next) {
if (strcmp(wp->word_name, word)==0) {
return wp->word_type;
}
}
return LOOKUP;
}
void handle_string() {
if (state != LOOKUP) {
add_word(state, yytext);
}else {
switch(lookup_word(yytext)) {
case VERB: printf("%s: verb\n", yytext); break;
case ADJ: printf("%s: adjective\n", yytext); break;
case ADV: printf("%s: adverb\n", yytext); break;
case NOUN: printf("%s: noun\n", yytext); break;
case PREP: printf("%s: propsition\n", yytext); break;
case PRON: printf("%s: pronoun\n", yytext); break;
case CONJ: printf("%s: conjunction\n", yytext); break;
default:
printf("%s: don't recognize\n", yytext); break;
}
}
}
注意上面代码增加了一句#include<string.h>,这是因为我们在代码中使用了 malloc 函数,这个函数声明在 string.h 头文件中。完成上面修改后运行 GoLex,将生成的 lex.yy.c 里面的内容拷贝到 CLex 中的 main.c中,编译运行后结果如下:
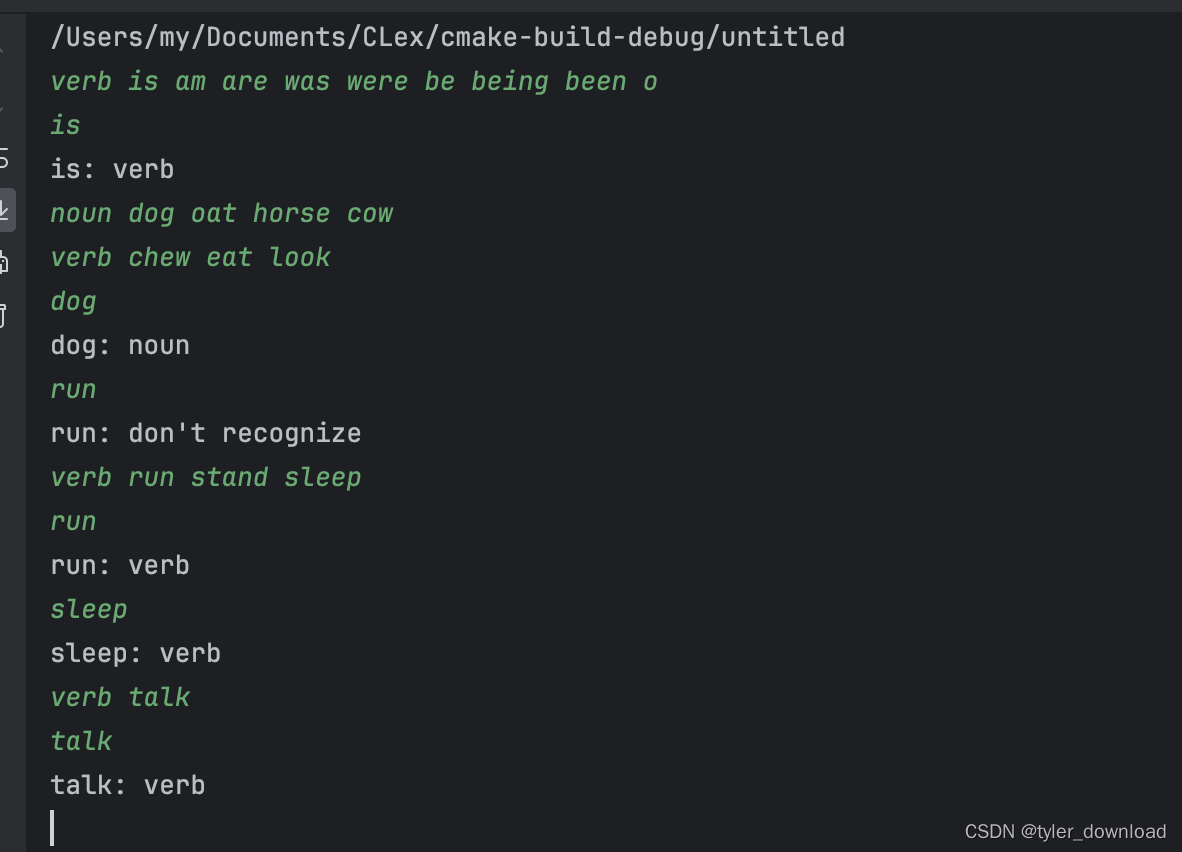
从上图执行效果可以看到,这次我们用 flex 实现的比较复杂功能,在 GoLex 上稍微修改也能实现同等功能。更多调试演示请在 B 站搜索 coding 迪斯尼。代码下载:
链接: https://pan.baidu.com/s/1Yg_PXPhWD4RlK16Fk7O0ig 提取码: auhs
github:
https://github.com/wycl16514/golang-implement-compiler-flex.git



![[原创][1]探究C#多线程开发细节-“Thread类的简单使用“](https://img-blog.csdnimg.cn/9a161eea09e04fecab169b4ef51de48c.png)