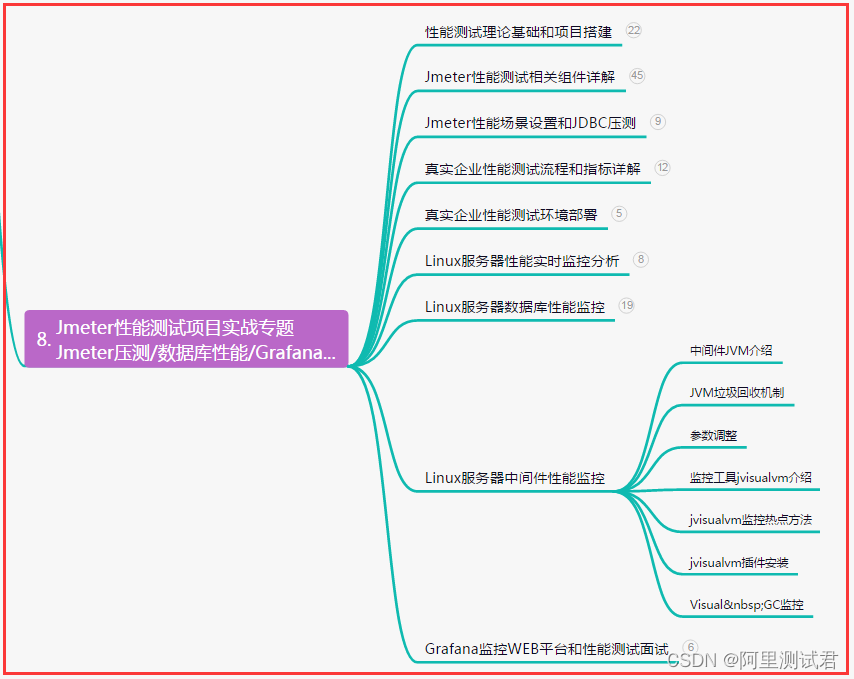
文章目录
- 基本概念
- 模型
- 小结
基本概念
我们可以用独立学习得到的h组不同的 线性投影来变换查询、键和值。 然后,这h组变换后的查询、键和值将并行地送到注意力汇聚中。 最后,将这h个注意力汇聚的输出拼接在一起, 并且通过另一个可以学习的线性投影进行变换, 以产生最终输出。 这种设计被称为多头注意力。对于h个注意力汇聚输出,每一个注意力汇聚都被称作一个头(head)。
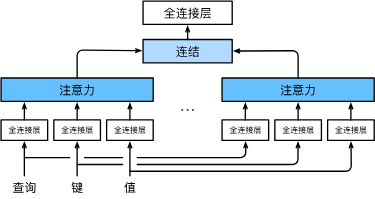
模型
每个注意力头
h
i
h_i
hi的计算公式为
h
i
=
f
(
W
i
(
q
)
q
,
W
i
(
k
)
k
,
W
i
(
v
)
v
)
∈
R
p
v
,
\mathbf{h}_i = f(\mathbf W_i^{(q)}\mathbf q, \mathbf W_i^{(k)}\mathbf k,\mathbf W_i^{(v)}\mathbf v) \in \mathbb R^{p_v},
hi=f(Wi(q)q,Wi(k)k,Wi(v)v)∈Rpv,
其中q-查询、k-键、v-值。
W
i
(
q
)
W_i^(q)
Wi(q)为q通过全连接层后得到的参数、
W
i
(
k
)
W_i^(k)
Wi(k)为k通过全连接层后得到的参数、
W
i
(
v
)
W_i^(v)
Wi(v)为v通过全连接层后得到的参数。
f f f为注意力汇聚函数,f内的注意力评分函数可以是加性注意力、缩放点击注意力。
多头注意力的输出需要经过另一个线性转换, 它对应着h个头连结后的结果,因此其可学习参数是
W
o
W_o
Wo
W
o
[
h
1
⋮
h
h
]
∈
R
p
o
.
\begin{split}\mathbf W_o \begin{bmatrix}\mathbf h_1\\\vdots\\\mathbf h_h\end{bmatrix} \in \mathbb{R}^{p_o}.\end{split}
Wo
h1⋮hh
∈Rpo.
基于这种设计,每个头都可能会关注输入的不同部分, 可以表示比简单加权平均值更复杂的函数。
小结
-
多头注意力融合了来自于多个注意力汇聚的不同知识,这些知识的不同来源于相同的查询、键和值的不同的子空间表示。
-
基于适当的张量操作,可以实现多头注意力的并行计算。