题目:
表:
Person+-------------+---------+ | Column Name | Type | +-------------+---------+ | id | int | | email | varchar | +-------------+---------+ id 是该表的主键(具有唯一值的列)。 此表的每一行都包含一封电子邮件。电子邮件不包含大写字母。编写解决方案来报告所有重复的电子邮件。 请注意,可以保证电子邮件字段不为 NULL。
以 任意顺序 返回结果表。
结果格式如下例。
来源:力扣(LeetCode)
链接:力扣(LeetCode)官网 - 全球极客挚爱的技术成长平台
示例:
示例 1:
输入:
Person 表: +----+---------+ | id | email | +----+---------+ | 1 | a@b.com | | 2 | c@d.com | | 3 | a@b.com | +----+---------+
输出:+---------+ | Email | +---------+ | a@b.com | +---------+
解释:a@b.com 出现了两次。
解法:
现在person表中加入1列,记录email是否重复,接着把重复的留下,然后去重。
知识点:
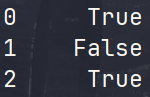
1.DataFrame.duplicated(subset=None, keep=‘first’):查找和处理数据中的重复项,返回布尔值的Series。subset:默认为None,需要标记重复的标签或标签序列;keep:默认为‘first’,如何标记重复标签,first:将除第一次出现以外的重复数据标记为True;last:将除最后一次出现以外的重复数据标记为True;False:将所有重复的项都标记为True(不管是不是第一次出现)。比如:
data = [[1, 'a@b.com'], [2, 'c@d.com'], [3, 'a@b.com']] person = pd.DataFrame(data, columns=['id', 'email']).astype({'id': 'Int64', 'email': 'object'})person['duplicated'] = person.duplicated(subset='email', keep=False)返回如下:
代码:
import pandas as pd def duplicate_emails(person: pd.DataFrame) -> pd.DataFrame: person['duplicated'] = person.duplicated(subset='email', keep=False) email = person[person['duplicated'] == True].drop_duplicates(subset='email') del email['id'] del email['duplicated'] return email