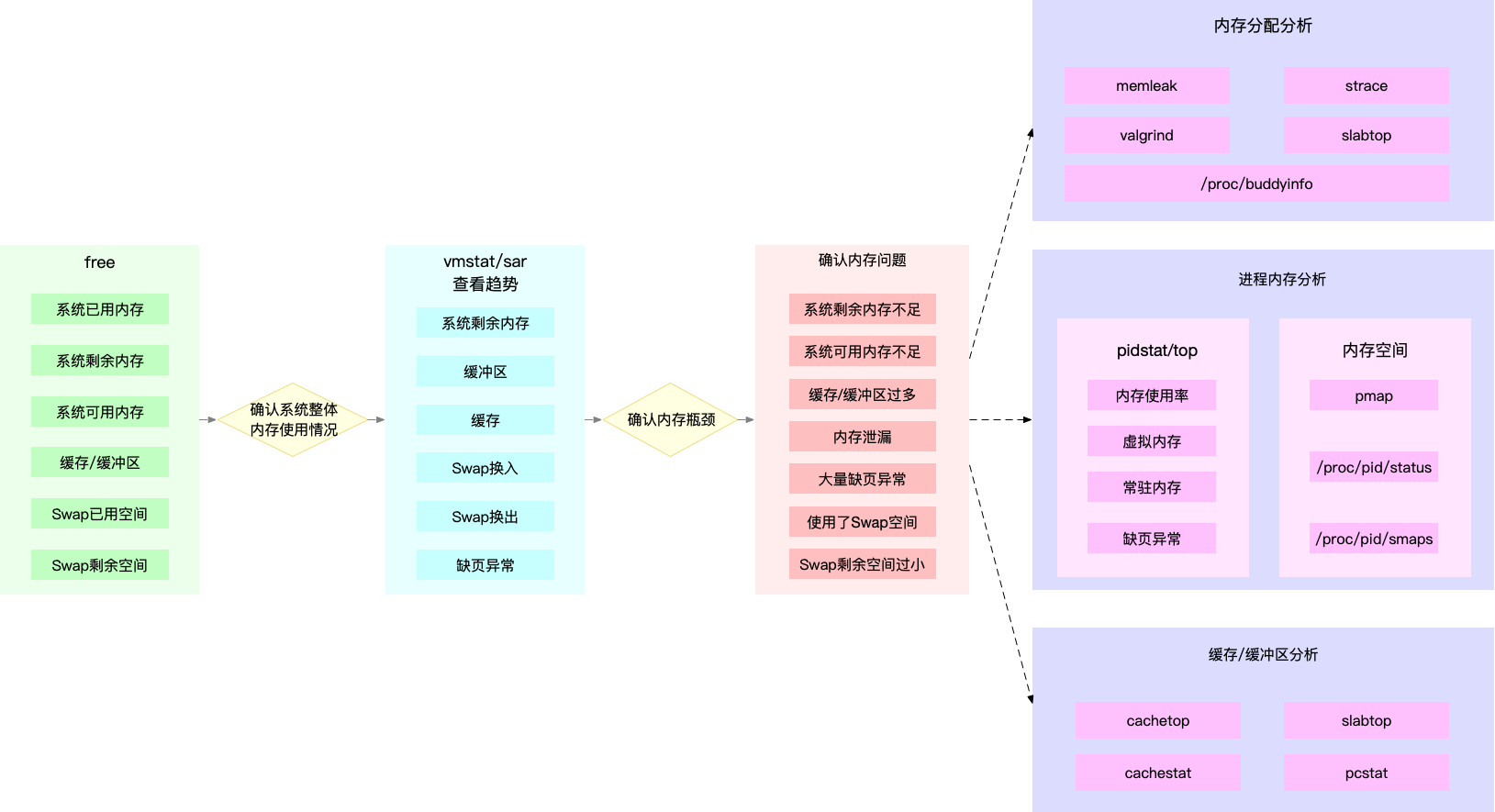
在全直径数字岩心中,如何获取每张切片的不同PEF区间值的百分比?
import os
import datetime
from PIL import Image
import numpy as np
import csv
import easygui as g
class Table(object):
def __init__(self, table_data_path):
self.table_data_path = table_data_path
def get_data(self):
self.image = Image.open(self.table_data_path)
self.array = np.array(self.image).flatten()
self.table_data = [i for i in self.array if i > 0]
if self.array.any() != 0:
# Mode_value = round(stats.mode(self.table_data)[0][0], 2)
# Mode_count = stats.mode(self.table_data)[1][0]
# Count = np.size(self.table_data)
Min = round(np.min(self.table_data), 5)
min_list.append(Min)
Max = round(np.max(self.table_data), 5)
max_list.append(Max)
Mean = round(np.mean(self.table_data), 5)
mean_list.append(Mean)
StdDev = round(np.std(self.table_data), 5)
stdDev_list.append(StdDev)
for a in range(len(data_range_use)):
range_percent = round(len([j for j in self.table_data if
(j > data_range_use[a][0]) and (j <= data_range_use[a][1])]) / len(
self.table_data) * 100, 4)
prepare_list['range_percent_list_%s' % a].append(range_percent)
else:
min_list.append(0)
max_list.append(0)
mean_list.append(0)
stdDev_list.append(0)
for m in range(len(data_range_use)):
prepare_list['range_percent_list_%s' % m].append(0)
if __name__ == '__main__':
start = datetime.datetime.now()
print(start)
list_name = []
min_list, mean_list, max_list, stdDev_list = [], [], [], []
data_range = [[i / 10, (i + 2) / 10] for i in range(60)]
data_range_use = [data_range[i] for i in range(len(data_range)) if (i % 2 == 0)]
data_range_end = [[6, 100]]
data_range_use.extend(data_range_end)
prepare_list = {} # 定义空字典
def test_list_pre():
prepare_list = locals() # 返回prepare_list中当前位置每个字典里的全部局部变量(也就是键)
for l in range(len(data_range_use)):
prepare_list['range_percent_list_' + str(l)] = []
slice_name = []
rootpath = g.diropenbox()
print(rootpath)
for i in os.listdir(rootpath):
print(os.path.join(rootpath, i))
slice_name.append(i)
t = Table(os.path.join(rootpath, i))
t.get_data()
data0 = {'slice_name': slice_name,
'Min': min_list,
'Max': max_list,
'Mean': mean_list,
'StdDev': stdDev_list,
}
data1 = {}
for b in range(len(data_range_use)):
k = '%s-%s' % (data_range_use[b][0], data_range_use[b][1])
v = prepare_list['range_percent_list_%s' % b]
data1.update({k: v})
data = {}
data.update(data0)
data.update(data1)
# print(data)
csv_file = open('%s—2.csv' % rootpath.split("\\")[-1], 'w', newline='')
writer = csv.writer(csv_file)
table_head = ['slice_name', 'Min', 'Max', 'Mean', 'StdDev']
table_head1 = [('%s-%s' % (data_range_use[i][0], data_range_use[i][1])) for i in range(len(data_range_use))]
table_head.extend(table_head1)
# print(table_head)
writer.writerow(table_head)
for ii in range(len(data['Min'])):
writer.writerow([data[m][ii] for m in table_head])
csv_file.close()
print('the data has been saved!')
stop = datetime.datetime.now()
print(stop)
time = (stop - start).seconds
print("Total time (min):%s" % round((time / 60), 2))
处理结果如下表: