【大家好,我是爱干饭的猿,本文重点介绍YOLOv5入门-目标检测的任务、性能指标、yolo算法基本思想、yolov5网络架构图。
后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍,关注一下吧】
上一篇文章:《【python高级】asyncio 并发编程》
YOLOv5入门
1. 目标检测-任务
目标检测 (Object Detection ) = What, and Where
类别标签(Category label)
置信度得分(Confidence score)
定位和检测:
- 定位是找到检测图像中带有一个给定标签的单个目标
- 检测是找到图像中带有给定标签的所有目标
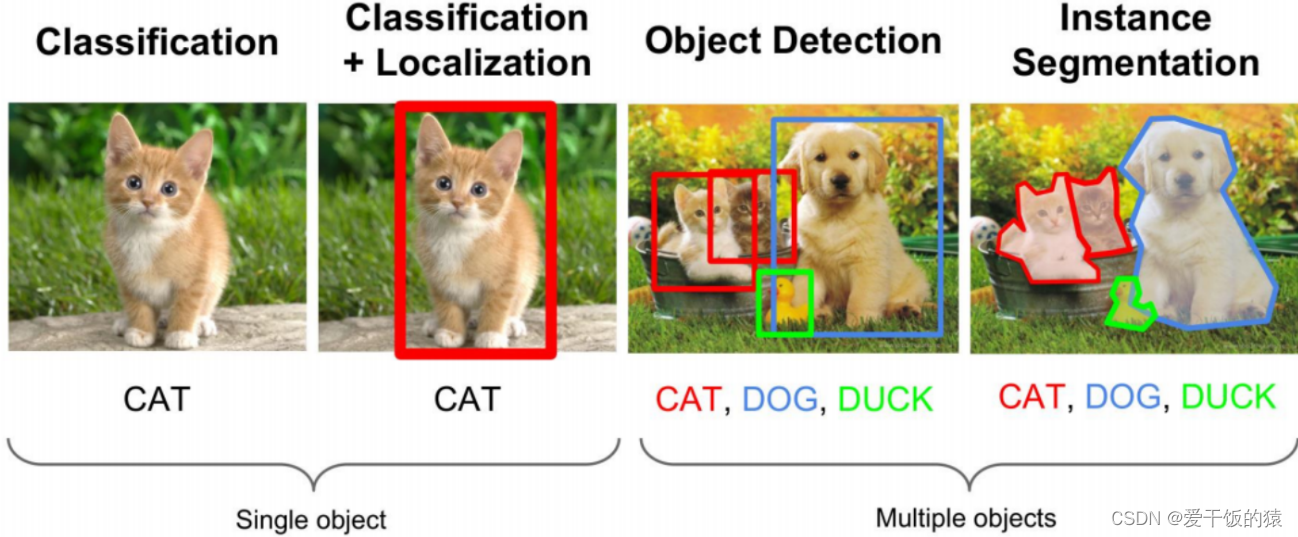
2. 目标检测-性能指标
检测精度
- Precision, Recall, F1 score
- IoU (Intersection over Union)
- P-R curve (Precison-Recall curve)
- AP (Average Precision)
- mAP (mean Average Precision)
检测速度
- 前传耗时
- 每秒帧数 FPS (Frames Per Second)
- 浮点运算量(FLOPS)
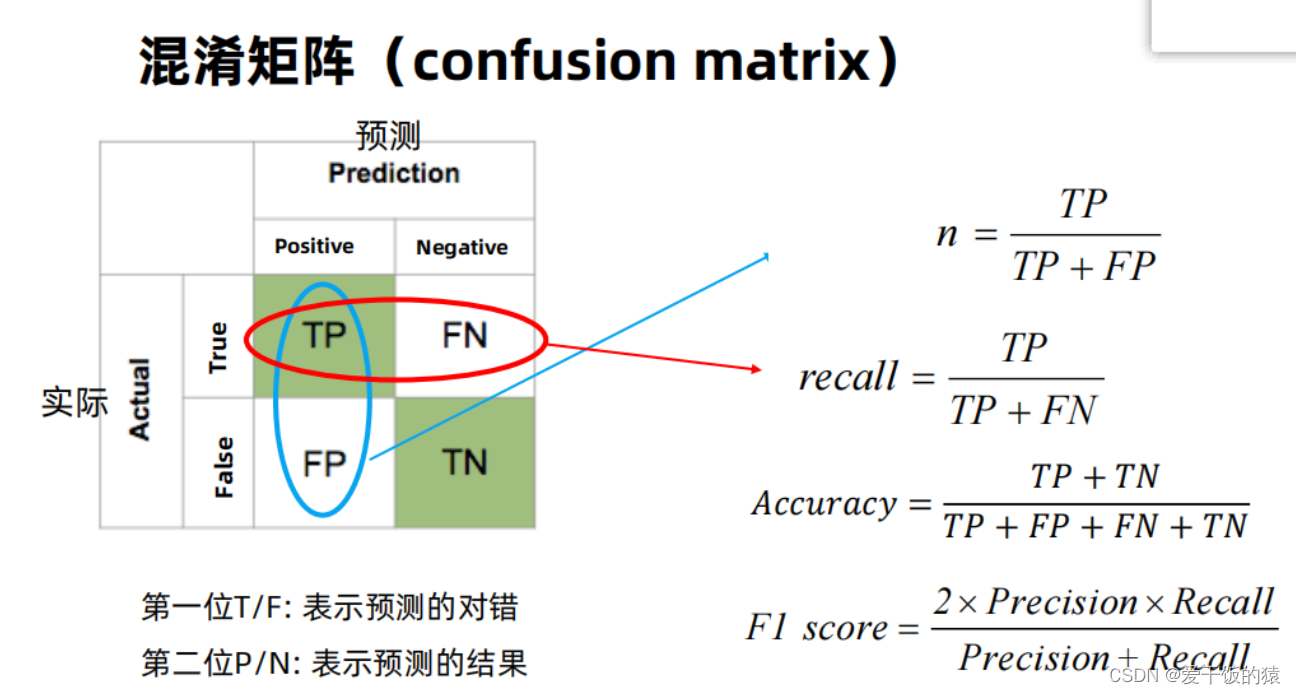
- 精度Precision(查准率)是评估预测的准不准(看预测列)
- 召回率Recall(查全率)是评估找的全不全(看实际行)
2.1 检测精度
-
IoU:
An IoU of 1 implies that predicted and the ground-truth bounding boxes perfectly overlap.
You can set a threshold value for the IoU to determine if the object detection is valid or not.
Let’s say you set IoU to 0.5, in that case
• if IoU ≥0.5, classify the object detection as True Positive(TP)
• if IoU <0.5, then it is a wrong detection and classify it as False Positive(FP)
• When a ground truth is present in the image and model failed to detect the object, classify it as False Negative(FN).
• True Negative (TN): TN is every part of the image where we did not predict an object. This metrics is not useful for object detection, hence we ignore TN. -
AP衡量的是学习出来的模型在每个类别上的好坏
-
mAP衡量的是学出的模型在所有类别上的好坏。mAP就是取所有类别上AP的平均值。
对于PASCAL VOC挑战,如果IoU> 0.5,则预测为正样本(TP)。 但是,如果检测到同一目标的多个检测,则视第一个检测为正样本(TP),而视其余检测为负样本(FP)。
2.2 检测速度
- 前传耗时(ms): 从输入一张图像到输出最终结果所消耗的时间,包括前处理耗时(如图像归一化)、网络前传耗时、后处理耗时(如非极大值抑制)
- 每秒帧数 FPS (Frames Per Second):每秒钟能处理的图像数量
- 浮点运算量(FLOPS):处理一张图像所需要的浮点运算数量, 跟具体软硬件没有关系,可以公平地比较不同算法之间的检测速度。
3. YOLO算法的基本思想
3.1 基本思想
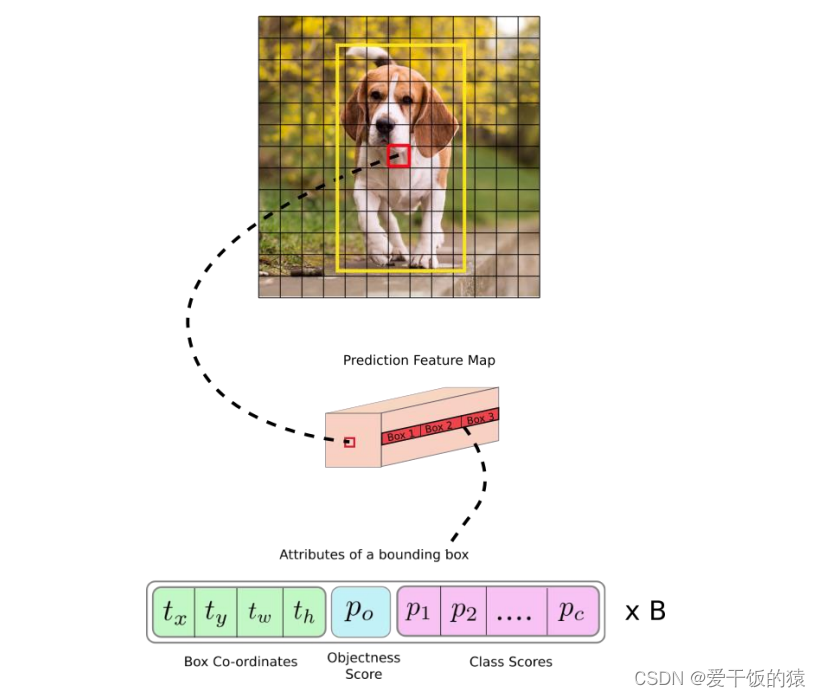
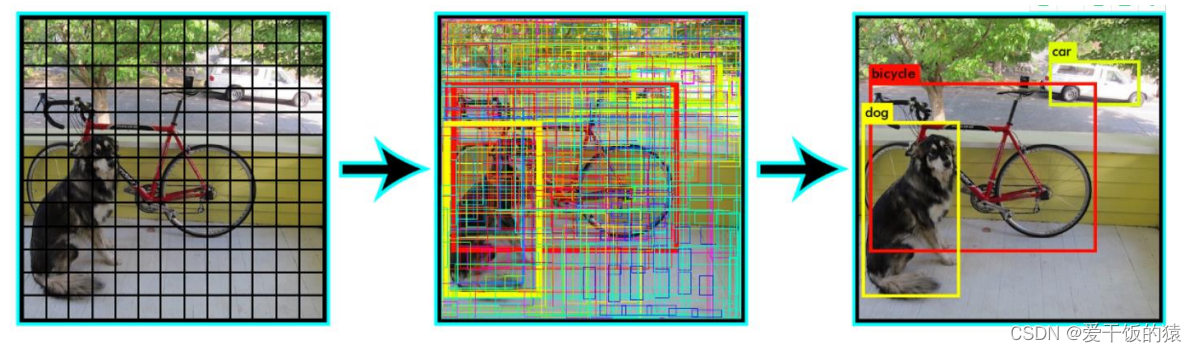
首先通过特征提取网络对输入图像提取特征,得到一定大小的特征图,比如1313(相当于416416图片大小 ),然后将输入图像分成13*13个grid cells
➢ YOLOv3/v4: 如果GT中某个目标的中心坐标落在哪个grid cell中,那么就由该grid cell来预测该目标。每个grid cell都会预测3个不同尺度的边界框 。
➢ YOLOv5: 不同于yolov3/v4,其GT可以跨层预测,即有些bbox在多个预测层都算正样本;匹配数范围可以是3-9个。
- 预测得到的输出特征图有两个维度是提取到的特征的维度,比如13
*13,还有一个维度(深度)是 B *(5+C)
➢ 注:B表示每个grid cell预测的边界框的数量 (YOLO v3/v4中是3个);
C表示边界框的类别数(没有背景类,所以对于VOC数据集是20); 5表示4个坐标信息和一个目标性得分(objectness score)。
3.2 计算
每个预测框的类别置信度得分(class confidence score ) 计算如下:

它测量分类和定位(目标对象所在的位置)的置信度。
3.3 NMS (Non-Maximum Suppression) 非极大抑制
测试时没有GT框,只能比较多个预测框,比较相互之间的IOU,做NMS
3.4 损失函数(Loss function)
损失函数包括:
• classification loss, 分类损失
• localization loss, 定位损失(预测边界框与GT之间的误差)
• confidence loss, 置信度损失(框的目标性;objectness of the box)
总的损失函数:
classification loss + localization loss + confidence loss
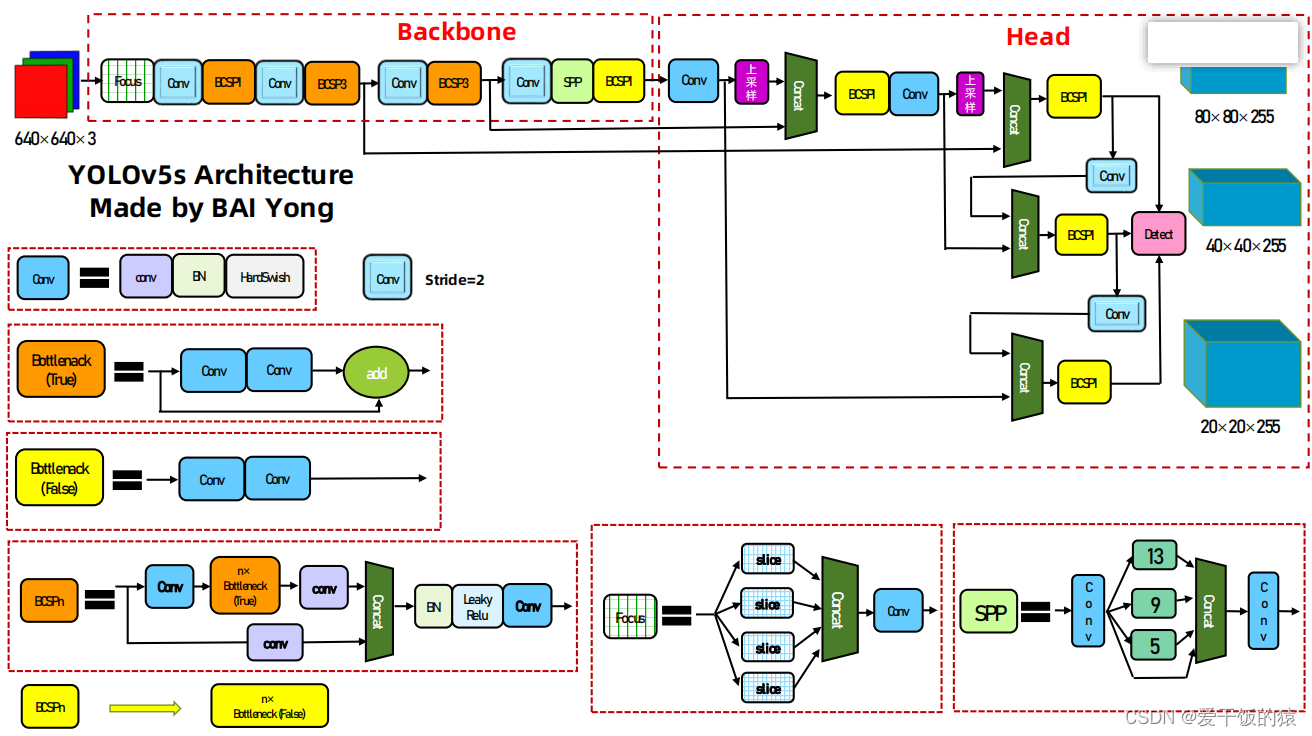
4. YOLOv5的网络架构图