目录
再次认识进程
用户视角
内核视角
引入线程
概念
调度的基本单位
模拟出图像
思考
线程的本质
线程和进程的区别
线程哪些结构是共享的
引入
地址空间
系统资源
编辑
线程哪些结构是单独拥有
引入
地址空间
系统资源
线程间切换的成本更低
linux和windows下的线程
再次认识进程
用户视角
- 之前我们对进程有一个概念,进程 = 进程相关内核数据结构 + 代码数据:
- 这些都是我们可以看到的,进程确实有代码数据,有task_struct等等结构:

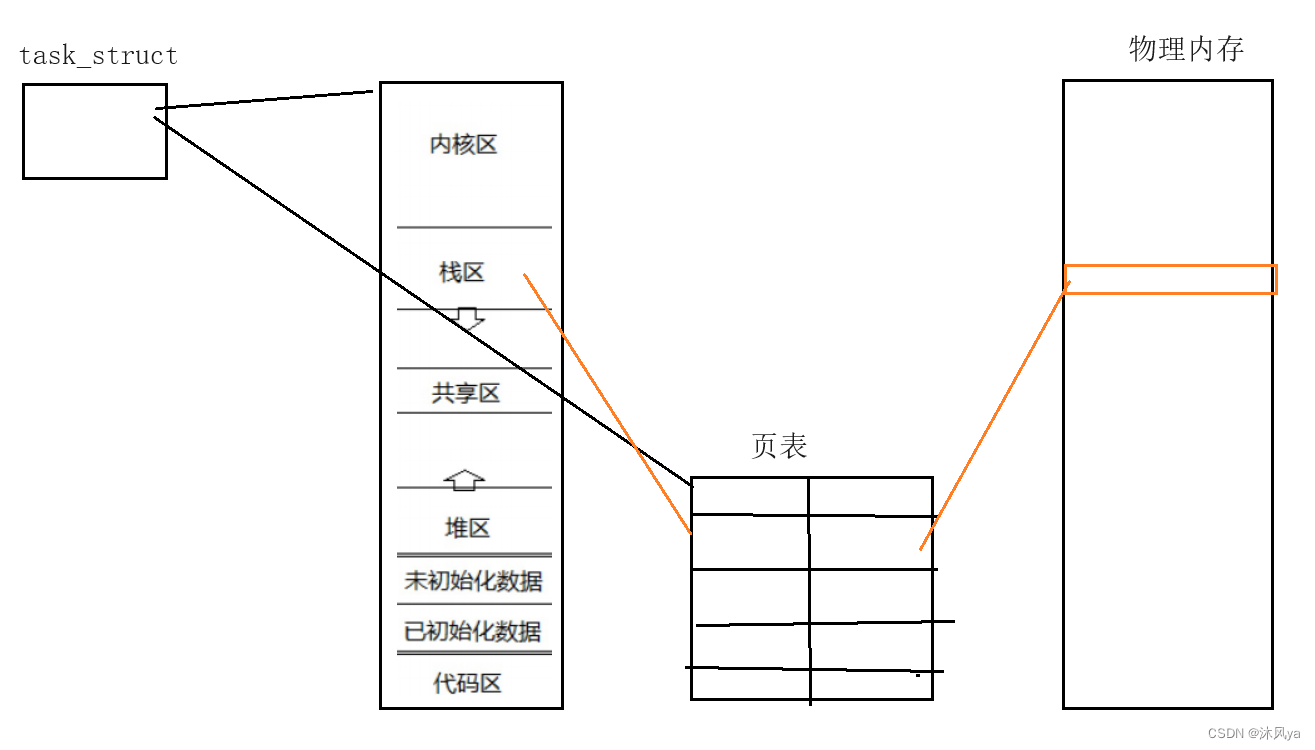
内核视角
- 我们看到的那些,都是必须占用内存资源的,否则凭什么可以被我们看到
- 并且,进程包括的这些内容,都必须一起被开辟空间,不然单独申请一个页表或者别的属实没啥用
- 也就是说 -- 我们申请资源时,都是以进程为单位的
- 说的高级一点就是 -- 进程是承担分配系统资源的基本实体
引入线程
概念
- 多线程可以实现并发执行,它使得程序能够在同一进程内并发执行多个任务
- 每个线程都可以独立执行不同的部分,从而使得多个任务可以同时进行,提高了程序的整体性能
调度的基本单位
- 之前我们曾说,cpu调度时,调度的是进程
- 这里说的更清晰一点,其实调度的是task_struct
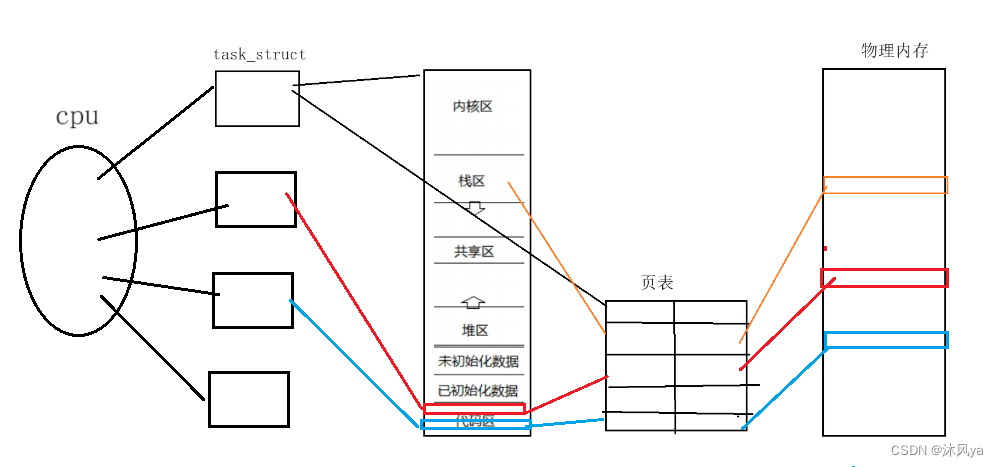
模拟出图像
通过从上面的概念,我们可以模拟出它在内核中的样子:
思考
我们是如何得到这幅图像的呢?
由于线程可以执行任务,且cpu调度的单位是pcb
- 所以我们的线程至少需要一个pcb
因为线程可以在进程内执行任务
- 所以首先明确,线程是囊括在进程范围内的
- 不然如何拿到进程的资源呢?
因为执行的是进程派给它的任务
- 所以线程可以直接使用进程的数据结构和资源
- 因为进程在申请空间时,就已经创建过了,不需要线程再创建
因为在进程内执行
- 进程内,实际上就是在进程的地址空间上执行
- 因为线程执行任务用的就是进程的地址空间
然后将当前进程的资源分配给线程,这样线程就可以执行分配给他的那一部分的代码
通过cpu的调度,就可以实现并发
线程的本质
从图上来看,那些task_struct其实就可以被看作是线程
- 因为比起进程来说,线程只是创建出更多的task_struct
前面说过,cpu调度的是task_struct
- 那么也可以说 -- cpu的调度单位是线程
- 其实cpu不关心它调度的是进程还是线程,它只认pcb
因为线程是cpu调度的基本单位
- 所以线程也可以被叫做是进程内部的执行流
并且,线程的资源来自于进程,进程的资源来自于内核,这是有先后顺序的
线程和进程的区别
这张图是我们之前认识的进程,一个进程只有一个pcb:
今天我们拓展了进程的概念,它可以拥有多个pcb,一个pcb就是一个线程:
通过这两张图我们可以发现:
- 我们介绍的线程在调度时,和之前认识的进程,流程是一样的,将虚拟地址转换为物理地址,然后进行访问
- 唯一不同的就是pcb的数量不同(也就是内部执行流数量不同)
- 所以,我们之前学习的进程,实际上就是只拥有一个线程的进程
- 下面那张图属于单进程多线程的进程
线程哪些结构是共享的
引入
- 线程的资源都来源于进程
- 为了更好的执行任务,很多资源都是被线程共享的
- 比如多个线程共用一个地址空间
地址空间
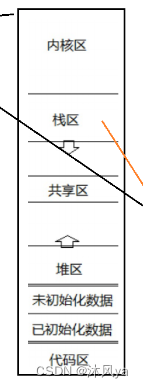
所以,对于地址空间来说(从下往上看):
- 代码区肯定是共享的,毕竟线程要执行的任务需要用到代码区的数据(比如函数,线程是可以调用的)
- 全局区也是共享的,线程可以拿到全局变量
- 堆区也是共享的,线程可以访问堆区上已经开辟的空间,但是一般访问不到(因为访问空间需要拿到起始地址)
- 共享区肯定是可以共享的,他本来就是用于进程/线程共享的
系统资源
- 这些基本的系统资源,都是共享的
- 毕竟线程是用来完成同一进程的任务的,有些数据还是统一的比较好

线程哪些结构是单独拥有
引入
- 难道所有资源都是共享的吗?
- 肯定不是这样的
- 因为不同的线程执行的任务一般是不一样的,拥有的上下文数据肯定也不一样
地址空间
- 栈区是不可以共享的,因为任务用到的变量肯定是不一样的
- 所以要为每个线程分配不同的栈区域
系统资源
- 因为执行的任务不同,线程也不同
- 为了区分每个线程,以下资源是不可以共享的
- 线程id用于区分线程,就像进程pid一样
- 寄存器用于存放上下文数据,肯定要为每个线程单独配套,不然就乱了
- 每个线程的状况不同,errno,信号屏蔽字,优先级自然也要不同

线程间切换的成本更低
为什么会这样说呢?
- 切换的时候,是需要更换上下文数据的,不同的进程用到的资源一般不同,所以需要全部切换
- 但是,线程的切换不需要切换地址空间和页表,以及其他的一些资源
当然,这些都只占原因的一部分,最大原因在于cpu的缓存机制:
- 如果cpu直接与硬件交流,效率会很低,会耽误cpu的执行(因为要等待外设读取成功)
- 所以cpu内置了cache,作为中间介质,提高io效率
- 它会根据局部性原理,将内存的部分数据预读到cpu内部,方便cpu读取
- 对于线程之间切换,他们很可能会用到相同的数据,所以缓存中的数据不会清除
- 对于进程来说,由于进程的独立性,每次进程切换,都需要重新预读数据
linux和windows下的线程
- 所以,linux下是没有真正意义上的线程结构的
- 他是用pcb模拟出线程,而不是单独定义一种结构
- 而windows下有真正的线程结构
- 这两者比起来,linux中的线程执行任务时更加轻量化
为什么这么说呢?
- windows中有单独的数据结构,那么在调度时,就会比linux更加频繁的切换上下文
- 维护的成本也更加高(比如创建/释放线程,管理线程),而不像linux中,直接复用管理task_struct的方式即可

这样会造成什么结果呢?
- 就是因为windows中调度时,数据结构更加复杂,所以它不能长时间运行,不然肯定会出问题
- 而linux可以一直运行很久
所以,我们一般将linux中的的进程,称为轻量化进程
- 就是因为它和单独定义了线程结构的操作系统比起来,运行更加轻量化 :
- 在linux的cpu眼中,它看到的pcb的量级 <= 线程拥有单独数据结构的系统中的pcb
- 其他系统的pcb,代表的是完整的一个进程
- 而linux中的pcb可能只代表进程中的一个执行流,那么它要调度的资源就比完整进程的要少 ; 也可能代表的也是完整进程,那么此时量级就相等了