redis笔记
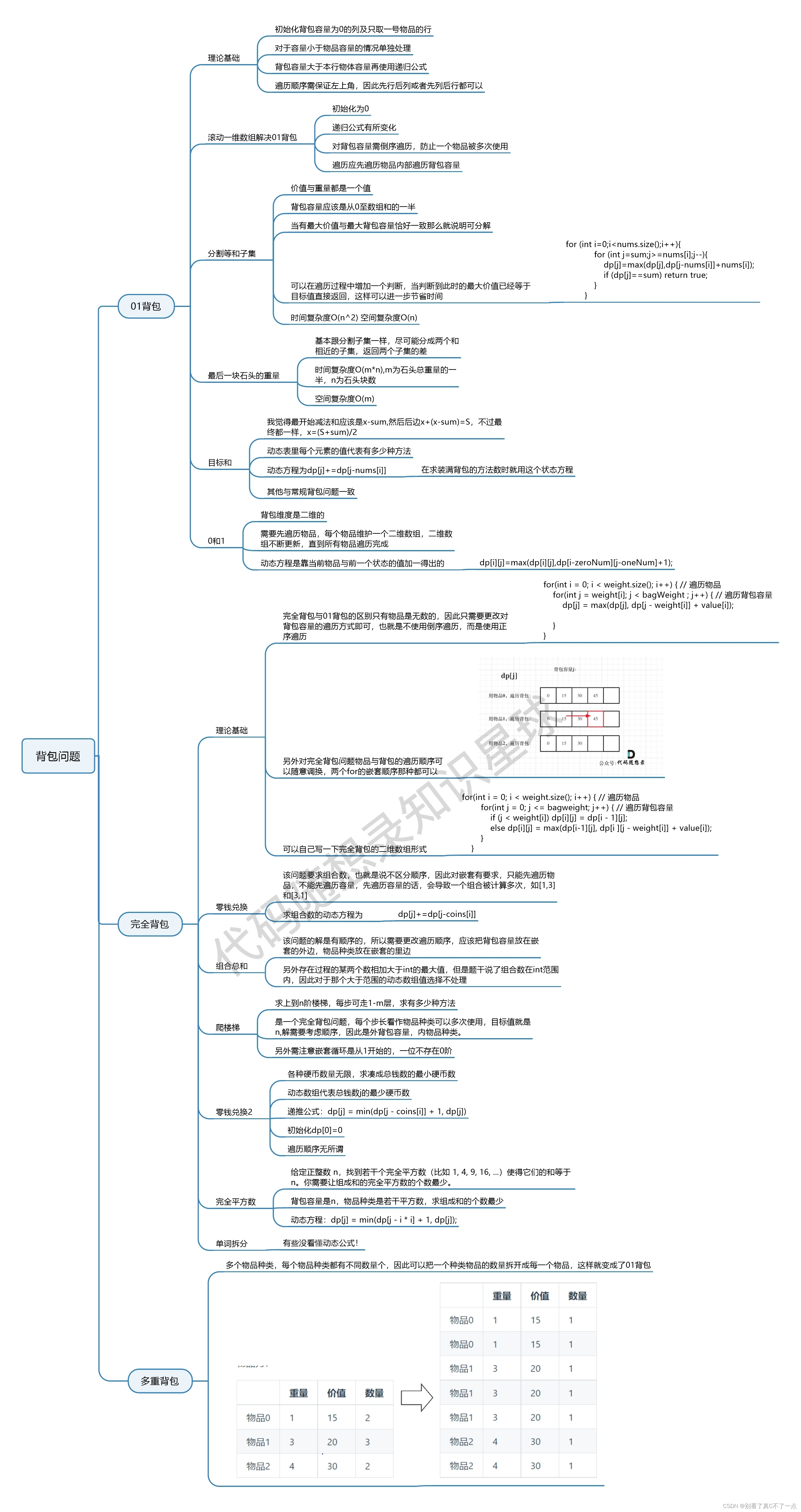
基础的数据结构:string、list、hash、set、zset
容器型数据结构(list、hash、set、zset)通用规则
- 如果容器不存在,就创建一个,再进行操作
- 如果容器里没有数据了,就立即删除,回收内存
String
如图:
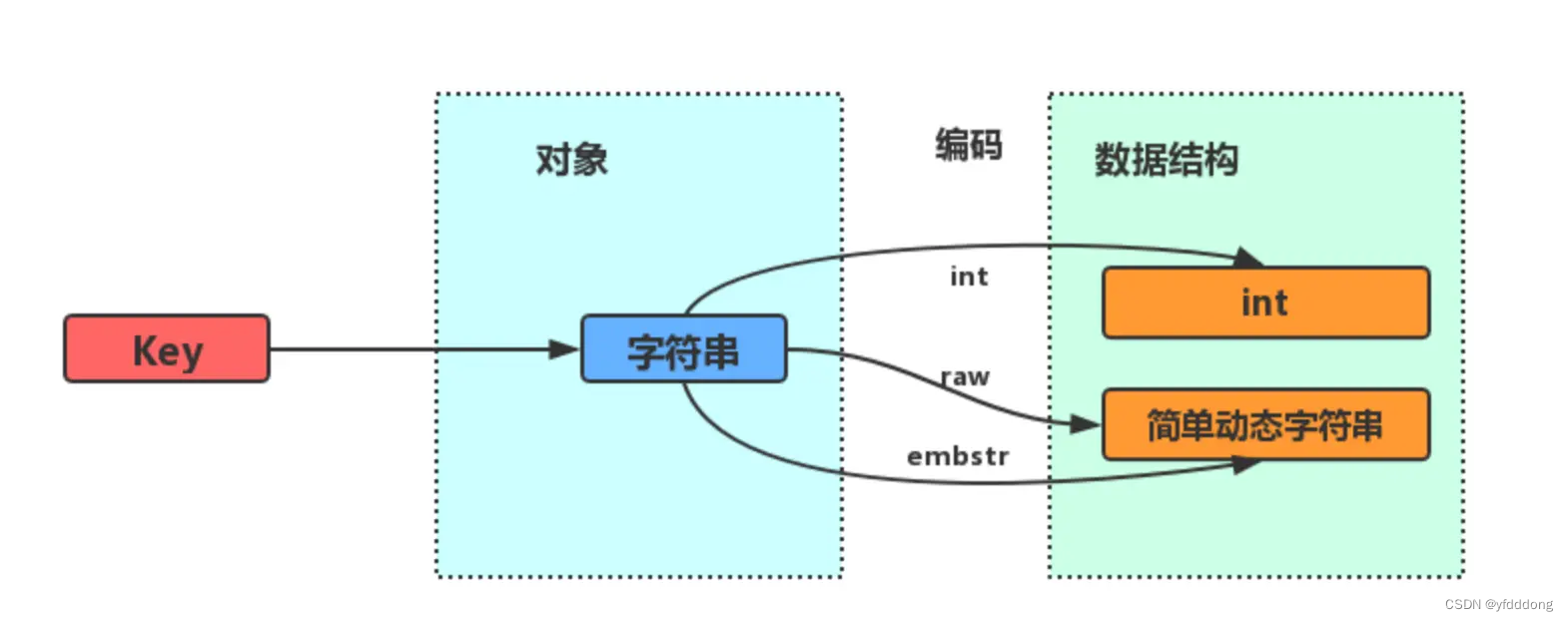
String 是reids 中最常见的数据类型
内部编码3种:int、raw、embstr
- int: 保存在字符串对象结构的ptr属性里(将void*转换成 long),并将字符串对象的编码设置为int
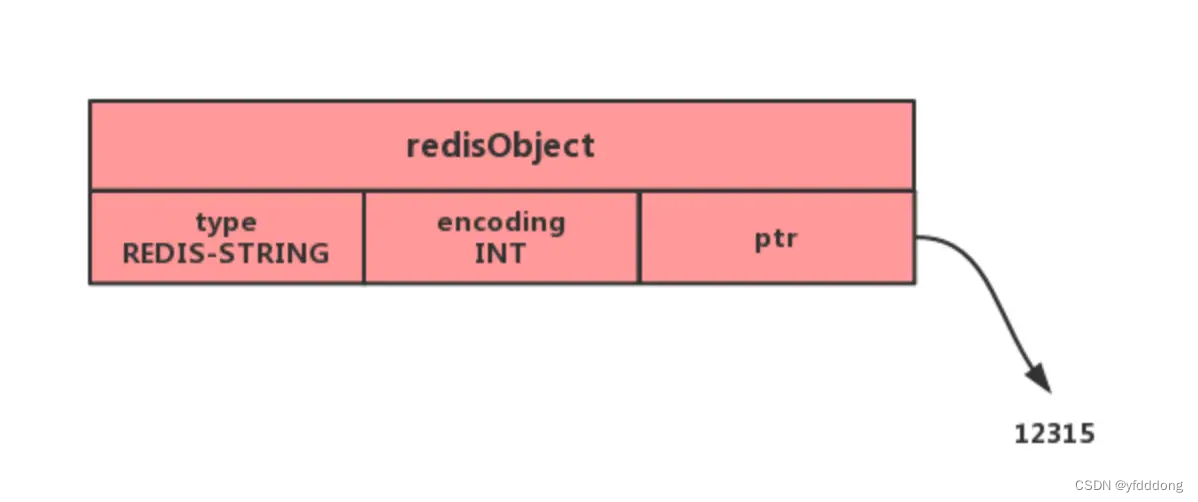
- embstr编码是专门用于保存短字符串的一种优化编码方式。
mbstr会通过一次内存分配函数来分配一块连续的内存空间来保存redisObject和SDS;
优点:
embstr相对于raw,创建字符串对象所需的内存分配次数从两次变为一次;
释放 embstr编码的字符串对象同样只需要调用一次内存释放函数;
embstr编码的字符串对象的所有数据都保存在一块连续的内存里面可以更好的利用 CPU 缓存提升性能。
缺点:
embstr编码的字符串对象实际上是只读的
对embstr编码的字符串对象执行任何修改命令(例如append)时,程序会先将对象的编码从embstr转换成raw,然后再执行修改命令。
应用场景
缓存对象
- 直接缓存整个对象的JSON
- 将key分离为user:ID:属性, MSET存储。MGET 获取各属性值
常规计数(计算访问次数 点赞 转发 库存数量的场景)
Redis 处理命令是单线程,所以执行命令的过程是原子的。
分布式锁 SETNX
分布式锁命令:
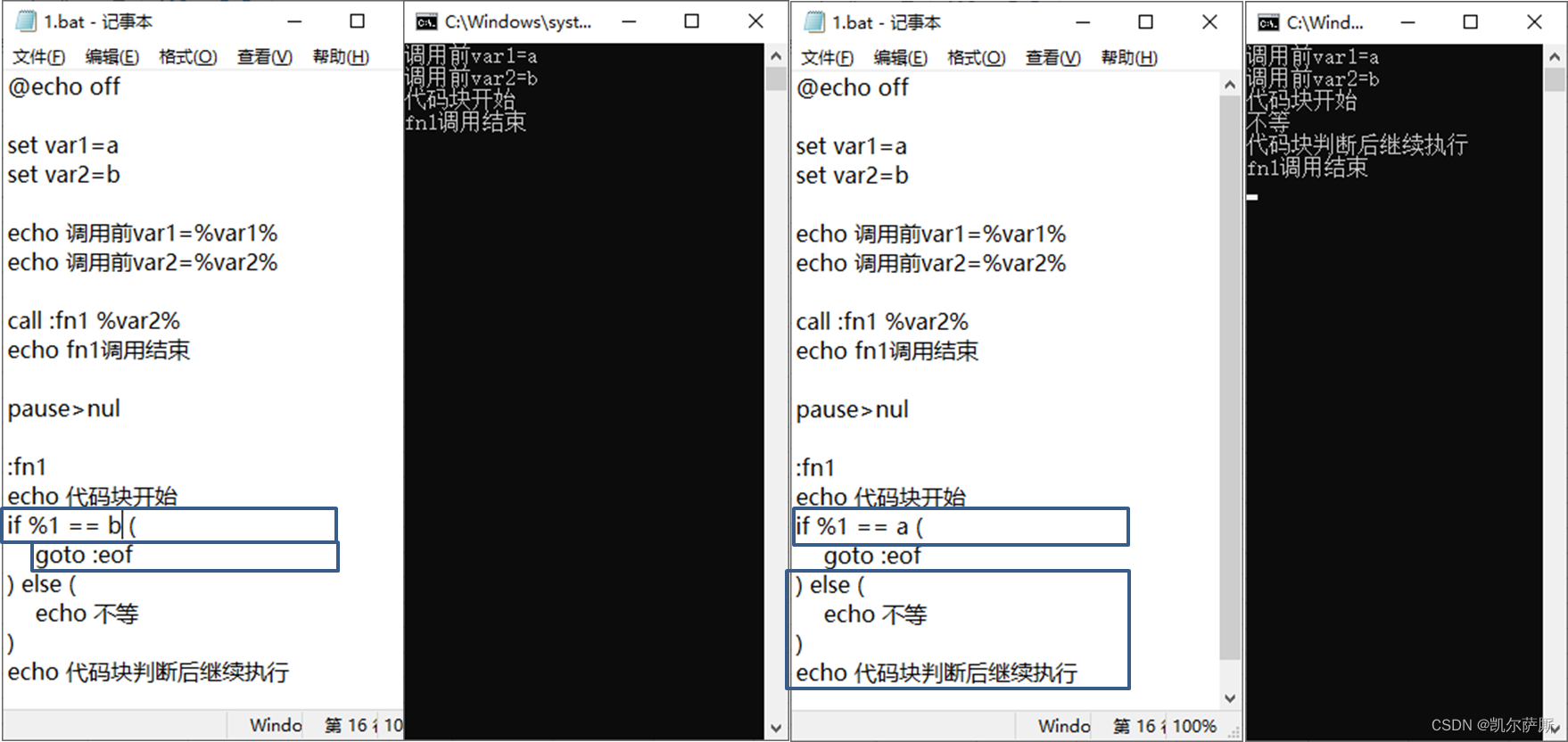
加锁:
SET lock_key unique_value NX PX 10000 // unique_value是客户端生成的唯一标识
解锁(判断锁的 unique_value 是否为加锁客户端 – 是则将 lock_key 键删除):
解锁是有两个操作,这时就需要 Lua 脚本来保证解锁的原子性, Redis 在执行 Lua 脚本时,可以以原子性的方式执行
// 释放锁时,先比较 unique_value 是否相等,避免锁的误释放
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end
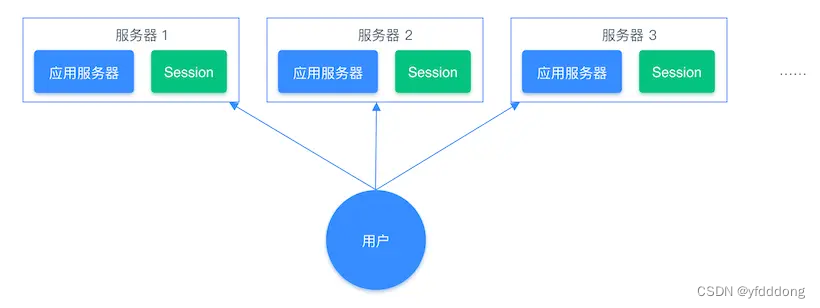
共享Session信息
分布式系统单独存储 Session 流程图:
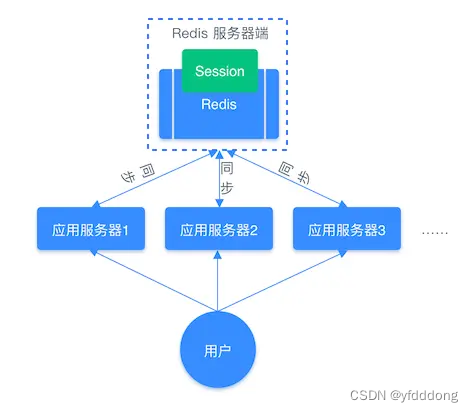
借助 Redis 对这些 Session 信息进行统一的存储和管理:
list 简单的字符串列表 按插入顺序排序 可以从头部或尾部向 List 列表添加元素
底层数据结构是由双向链表或压缩列表实现…
redis3.2后List 数据类型底层数据结构就只由 quicklist 实现
应用场景
消息队列
需求: 消息保序 处理重复消息 保证消息的可靠性
基于List的消息队列实现
- 消息保序

生产者使用 LPUSH key value[value…] 将消息插入到队列的头部,如果 key 不存在则会创建一个空的队列再插入消息。
消费者使用 RPOP key 依次读取队列的消息,先进先出。
问题: 消费者不停调用RPOP命令, 消耗CPU.
解决:Redis提供BRPOP命令阻塞式读取, 客户端在没有读到队列数据时,自动阻塞,直到有新的数据写入队列,再开始读取新数据。 - 处理重复的消息
方案: 自行为每个消息生成一个全局唯一ID. 用LPUSH命令将消息插入队列时,在消息中包含全局唯一ID.
eg. 把一条全局 ID 为 111000102、库存量为 99 的消息插入消息队列
> LPUSH mq "111000102:stock:99"
- 保证消息可靠性
**问题:**如果消费者程序在处理消息的过程出现了故障或宕机,就会导致消息没有处理完成,那么,消费者程序再次启动后,就没法再次从 List 中读取消息了。
解决:BRPOPLPUSH
问题: List 不支持多个消费者消费同一条消息
List实现消息队列优点:
- redis存储,不受限于JVM内存上限
- Redis具有持久化机制,数据安全性有保障
Hash
Key-value 集合, 适合用于存储对象
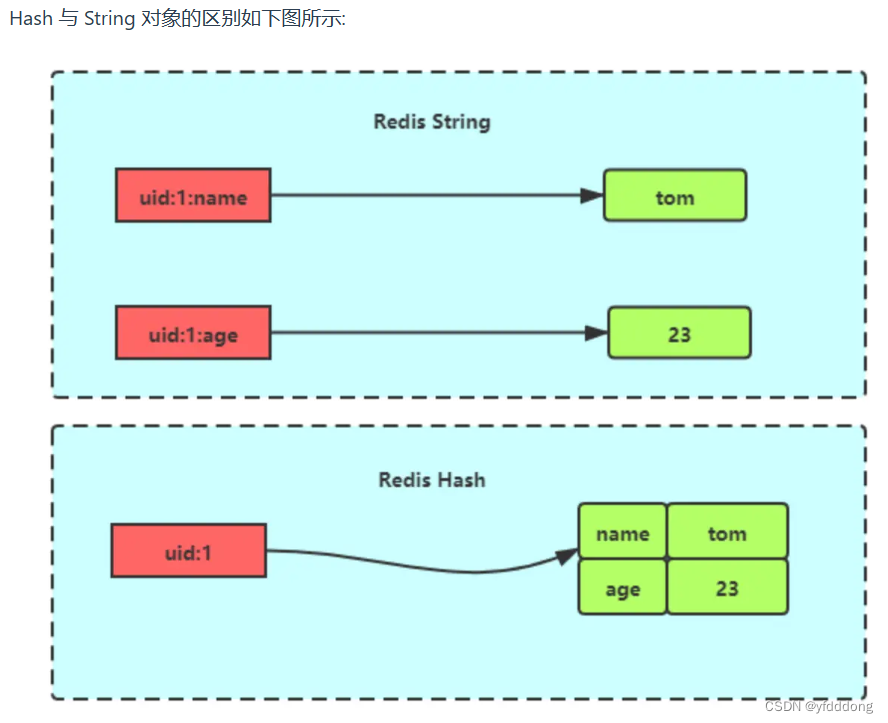
数据结构: 哈希表, 如果哈希类型元素个数小于 512 个, 所有值小于 64,会使用压缩列表作为底层数据结构.
应用场景
缓存对象
一般对象用 String + Json 存储,对象中某些频繁变化的属性可以考虑抽出来用 Hash 类型存储。
# 存储一个哈希表uid:1的键值
> HMSET uid:1 name Tom age 15
2
# 存储一个哈希表uid:2的键值
> HMSET uid:2 name Jerry age 13
2
# 获取哈希表用户id为1中所有的键值
> HGETALL uid:1
1) "name"
2) "Tom"
3) "age"
4) "15"
购物车
案例待学习
Set
哈希表或整数集合实现
- 适合用来数据去重和保障数据的唯一性
- 可以用来统计多个集合的交集、错集和并集等
- Set 的差集、并集和交集的计算复杂度较高,在数据量较大的情况下,如果直接执行这些计算,会导致 Redis 实例阻塞。
在主从集群中,为了避免主库因为 Set 做聚合计算(交集、差集、并集)时导致主库被阻塞,我们可以选择一个从库完成聚合统计,或者把数据返回给客户端,由客户端来完成聚合统计.
点赞
Set 类型可以保证一个用户只能点一个赞,这里举例子一个场景,key 是文章id,value 是用户id。
共同关注
抽奖活动
- 如果允许重复中奖,可以使用 SRANDMEMBER 命令。
- 如果不允许重复中奖,可以使用 SPOP 命令。
Zset
压缩列表或跳表
排行榜
电话\姓名排序
待补充:
BitMap
HyperLogLog
GEO
Stream
使用场景
消息队列,相比于基于 List 类型实现的消息队列,有这两个特有的特性:自动生成全局唯一消息ID,支持以消费组形式消费数据。
Redis 是否适合做消息队列?
- 如果你的业务场景足够简单,对于数据丢失不敏感,而且消息积压概率比较小的情况下,把 Redis 当作队列是完全可以的。
- 如果你的业务有海量消息,消息积压的概率比较大,并且不能接受数据丢失,那么还是用专业的消息队列中间件吧。