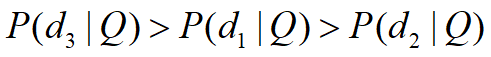时间序列预测是数据科学和商业分析中基于历史数据预测未来价值的一项重要技术。它有着广泛的应用,从需求规划、销售预测到计量经济分析。由于Python的多功能性和专业库的可用性,它已经成为一种流行的预测编程语言。其中一个为时间序列预测任务量身定制的库是skforecast。
在本文中,将介绍skforecast并演示了如何使用它在时间序列数据上生成预测。skforecast库的一个有价值的特性是它能够使用没有日期时间索引的数据进行训练和预测。
数据集
我在本文中使用的数据集来自Kaggle,它通过加速度计数据提供了一个全面的窗口来了解各种体育活动。我们这里只提取了其中一个参与者的代表步行活动的加速信号。
数据集见这里:https://avoid.overfit.cn/post/de4e26b02fb74fb58c65ac2f86dce87c
超参数调优和滞后选择
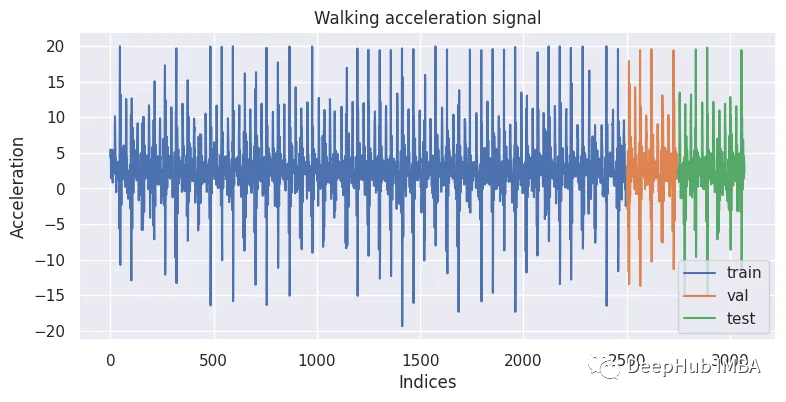
第一步:将时间序列信号分为训练集、验证集和测试集。
end_train = 2500
end_val = 2750
data_train = acc_x_walking[:end_train]
data_val = acc_x_walking[end_train:end_val]
data_test = acc_x_walking[end_val:]
Skforecast采用了类似于Sickit-Learn的结构,这是一个很多人都熟悉的框架。所以对五个模型进行超参数调优和选择滞后是一个简单的过程。
RandomForestRegressor、GradientBoostingRegressor、Ridge、LGBMRegressor和XGBRegressor都可以用于预测连续数值的回归模型。所以我们可以确定每个模型的最佳参数,使均方误差最小化。然后这些改进的参数将被整合到模型中来预测步行活动。
滞后决定了过去的滞后值(时间步长)的最大数量,这些滞后值将被用作预测未来的特征。它表示有多少过去的观测将被视为预测下一个观测的输入特征。
步长指定进入未来进行预测的步数。它表示预测范围或模型应该预测的时间步数。
# Models to compare
models = [RandomForestRegressor(random_state=42),
GradientBoostingRegressor(random_state=42),
Ridge(random_state=42),
LGBMRegressor(random_state=42),
XGBRegressor(random_state=42)]
# Hyperparameter to search for each model
param_grids = {'RandomForestRegressor': {'n_estimators': [10, 50, 100], 'max_depth': [5, 15, 30, 45, 60]},
'GradientBoostingRegressor': {'n_estimators': [10, 50, 100], 'max_depth': [5, 15, 30, 45, 60]},
'Ridge': {'alpha': [0.01, 0.1, 1]},
'LGBMRegressor': {'n_estimators': [10, 50, 100], 'max_depth': [5, 15, 30, 45, 60]},
'XGBRegressor': {'n_estimators': [10, 50, 100], 'max_depth': [5, 15, 30, 45, 60]}}
# Lags used as predictors
lags_grid = [2, 5, 7]
df_results = pd.DataFrame()
for i, model in enumerate(models):
print(f"Grid search for regressor: {model}")
print(f"-------------------------")
forecaster = ForecasterAutoreg(
regressor = model,
lags = 2
)
# Regressor hyperparameters
param_grid = param_grids[list(param_grids)[i]]
results = grid_search_forecaster(
forecaster = forecaster,
y = data_train,
param_grid = param_grid,
lags_grid = lags_grid,
steps = 250,
refit = False,
metric = 'mean_squared_error',
initial_train_size = 50,
fixed_train_size = True,
return_best = False,
n_jobs = 'auto',
verbose = False,
show_progress = True
)
# Create a column with model name
results['model'] = list(param_grids)[i]
df_results = pd.concat([df_results, results])
df_results = df_results.sort_values(by='mean_squared_error')
df_results.head(10)
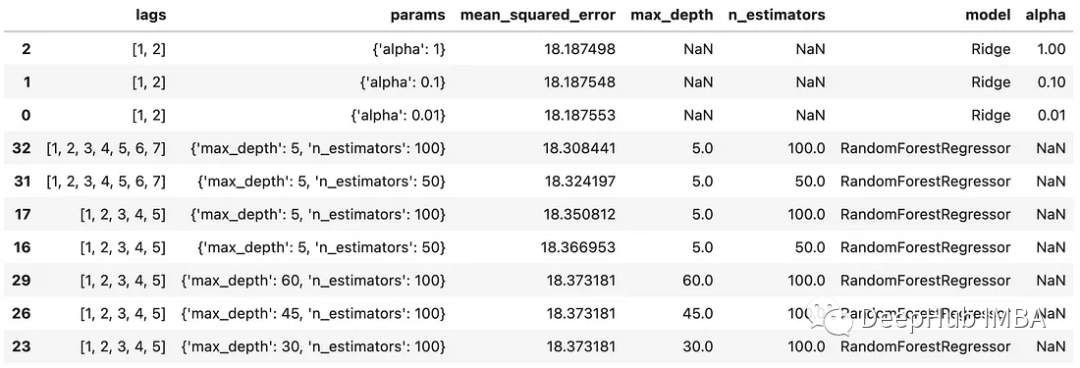
超参数调整过程的结果是一个DF,表示所使用的模型及其各自的均方误差和各种参数,如下所示。
通过超参数整定,得到的模型最优参数为:
GradientBoostingRegressor
- max_depth=30
- n_estimators=10
- lags = 2
Ridge
- alpha=1
- lags = 2
RandomForestRegressor
- max_depth=5
- n_estimators=100
- lags = 7
LGBMRegressor
- max_depth=15
- n_estimators=10
- lags = 5
XGBRegressor
- max_depth=5
- n_estimators=10
- lags = 2
预测
我们现在知道了应用于模型的最佳参数,可以开始训练了。将数据分成训练集和测试集。我们在上面分成验证机和测试集的原因是,测试集没有参与超参数调优过程的,所提它对于模型仍然是完全未知的。
# Split train-test
step_size = 250
data_train = acc_x_walking[:-step_size]
data_test = acc_x_walking[-step_size:]

下一步是创建和拟合预测模型。
# Create and fit forecaster
# GradientBoostingRegressor
gb_forecaster = ForecasterAutoreg(
regressor = GradientBoostingRegressor(random_state=42, max_depth=30, n_estimators=10),
lags = 2
)
# Ridge
r_forecaster = ForecasterAutoreg(
regressor = Ridge(random_state=42, alpha=1),
lags = 2
)
# RandomForestRegressor
rf_forecaster = ForecasterAutoreg(
regressor = RandomForestRegressor(random_state=42, max_depth=5, n_estimators=100),
lags = 7
)
# LGBMRegressor
lgbm_forecaster = ForecasterAutoreg(
regressor = LGBMRegressor(random_state=42, max_depth=15, n_estimators=10),
lags = 5,
)
# XGBRegressor
xgb_forecaster = ForecasterAutoreg(
regressor = XGBRegressor(random_state=42, max_depth=5, n_estimators=10),
lags = 2,
)
# Fit
gb_forecaster.fit(y=data_train)
r_forecaster.fit(y=data_train)
rf_forecaster.fit(y=data_train)
lgbm_forecaster.fit(y=data_train)
xgb_forecaster.fit(y=data_train)
# Predict
gb_predictions = gb_forecaster.predict(steps=step_size)
r_predictions = r_forecaster.predict(steps=step_size)
rf_predictions = rf_forecaster.predict(steps=step_size)
lgbm_predictions = lgbm_forecaster.predict(steps=step_size)
xgb_predictions = xgb_forecaster.predict(steps=step_size)
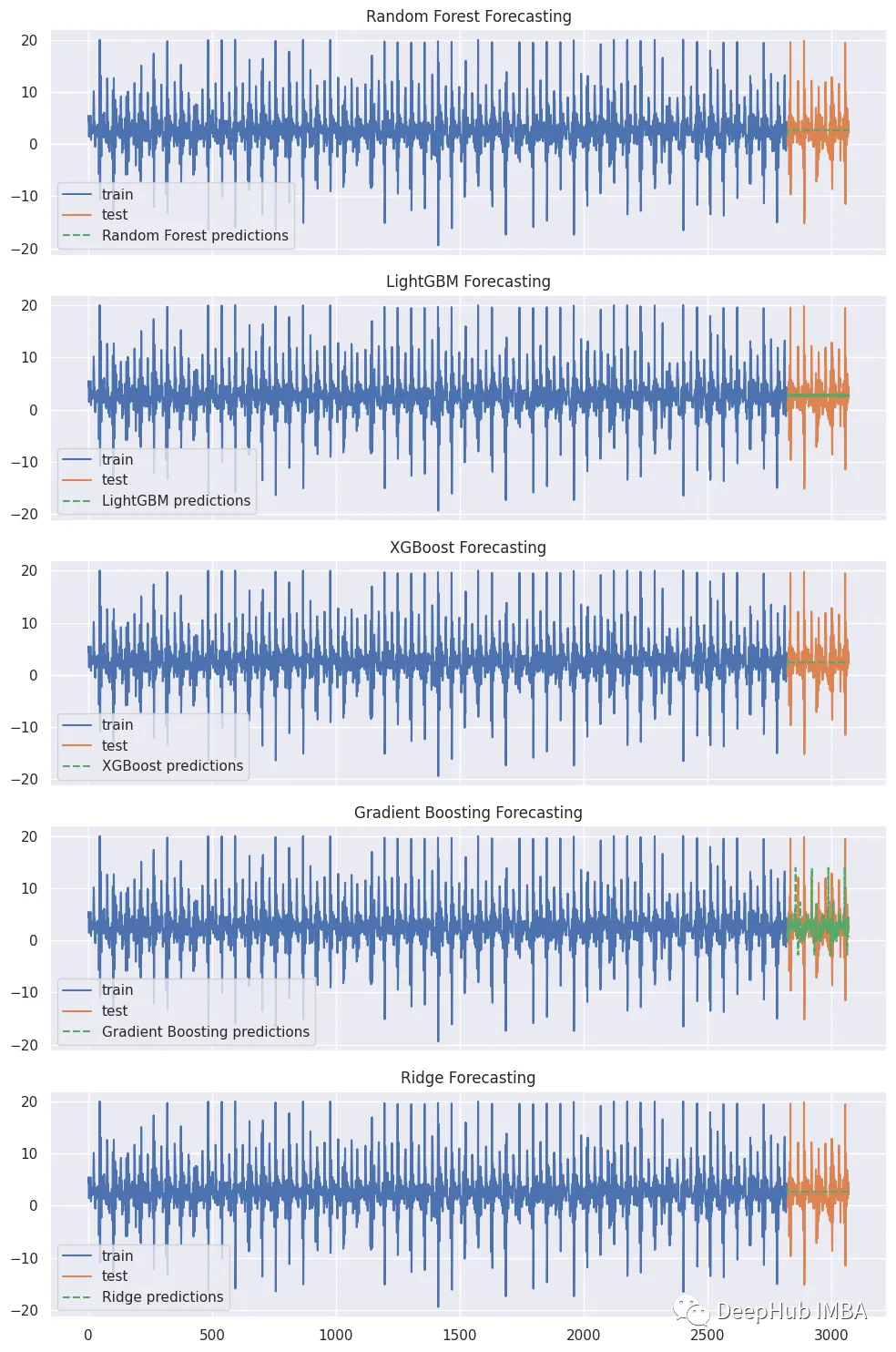
下图展示了五种模型的预测结果很明显,除梯度增强外,所有模型都产生了平线的预测。这里的原因有很多,比如说对于其他几个模型,因为我们是介绍skforecast,所以没有设置全部的超参数,导致可能还没有拟合,这个可以再进行调整。
结论
skforecast是在Python中掌握时间序列预测的一个非常好的选择。它简单易用,是根据历史数据预测未来价值的好工具。
在本文的整个探索过程中,使用skforecast的特征来调整超参数,并为基本回归模型(如RandomForestRegressor, GradientBoostingRegressor, Ridge, LGBMRegressor和XGBRegressor)选择滞后。
skforecast的一个显著优势是用户友好的文档,它清楚地解释了模型的功能和参数。如果您正在寻找一种轻松有效的方法来探索时间序列预测,skforecast是一个非常好的选择。