更多Python学习内容:ipengtao.com
时间序列数据在许多领域中都扮演着关键的角色,从股票价格到气象数据。为了更准确地预测未来趋势,机器学习领域涌现出许多时间序列预测的方法和工具。其中,NeuralProphet库是一个强大的工具,基于神经网络的方法,为时间序列预测提供了高效而灵活的解决方案。
安装与基础用法
首先,通过以下命令安装NeuralProphet库:
pip install neuralprophetNeuralProphet的基础用法非常简单。以下是一个示例,演示如何使用NeuralProphet进行时间序列预测:
from neuralprophet import NeuralProphet
import pandas as pd
# 创建示例数据
df = pd.DataFrame({
'ds': pd.date_range(start='2022-01-01', end='2022-01-10'),
'y': [10, 15, 20, 25, 30, 35, 40, 45, 50, 55]
})
# 初始化模型
model = NeuralProphet()
# 拟合模型
model.fit(df, freq='D')
# 创建未来数据框架
future = model.make_future_dataframe(df, periods=5)
# 预测未来值
forecast = model.predict(future)高级功能与参数解析
NeuralProphet不仅提供了基本的时间序列预测功能,还支持许多高级功能和参数,以满足不同场景的需求。例如,可以调整模型的层数、学习率等超参数,以优化预测性能。
以下是一个演示如何调整超参数的示例:
# 初始化模型,并指定超参数
model = NeuralProphet(
n_changepoints=5,
learning_rate=0.01,
yearly_seasonality=True
)
# 其他操作与基础用法相同实际应用案例
NeuralProphet的强大功能使其在实际项目中得以广泛应用,特别是在需要对多个季节性因素进行精确预测的复杂时间序列数据场景。以下是一个更为详细的实际应用案例,演示如何利用NeuralProphet进行电力需求预测。
场景描述
假设我们是一家电力公司,负责管理电网和满足用户的用电需求。希望通过NeuralProphet预测未来一周的电力需求,以便更有效地规划发电和分配资源。
数据准备
首先,需要有一份包含历史电力需求的数据集。假设有一个包含日期(ds)和电力需求值(y)的数据框。
import pandas as pd
# 创建示例数据
data = {
'ds': pd.date_range(start='2022-01-01', end='2022-01-10'),
'y': [100, 120, 150, 130, 180, 200, 190, 210, 220, 250]
}
df = pd.DataFrame(data)模型训练
接下来,初始化并训练NeuralProphet模型。
from neuralprophet import NeuralProphet
# 初始化模型
model = NeuralProphet()
# 拟合模型
model.fit(df, freq='D')创建未来数据框架
为了进行未来的电力需求预测,创建一个未来数据框架。
# 创建未来数据框架
future = model.make_future_dataframe(df, periods=7)预测未来值
现在,使用训练好的模型进行未来电力需求的预测。
# 预测未来值
forecast = model.predict(future)结果展示与评估
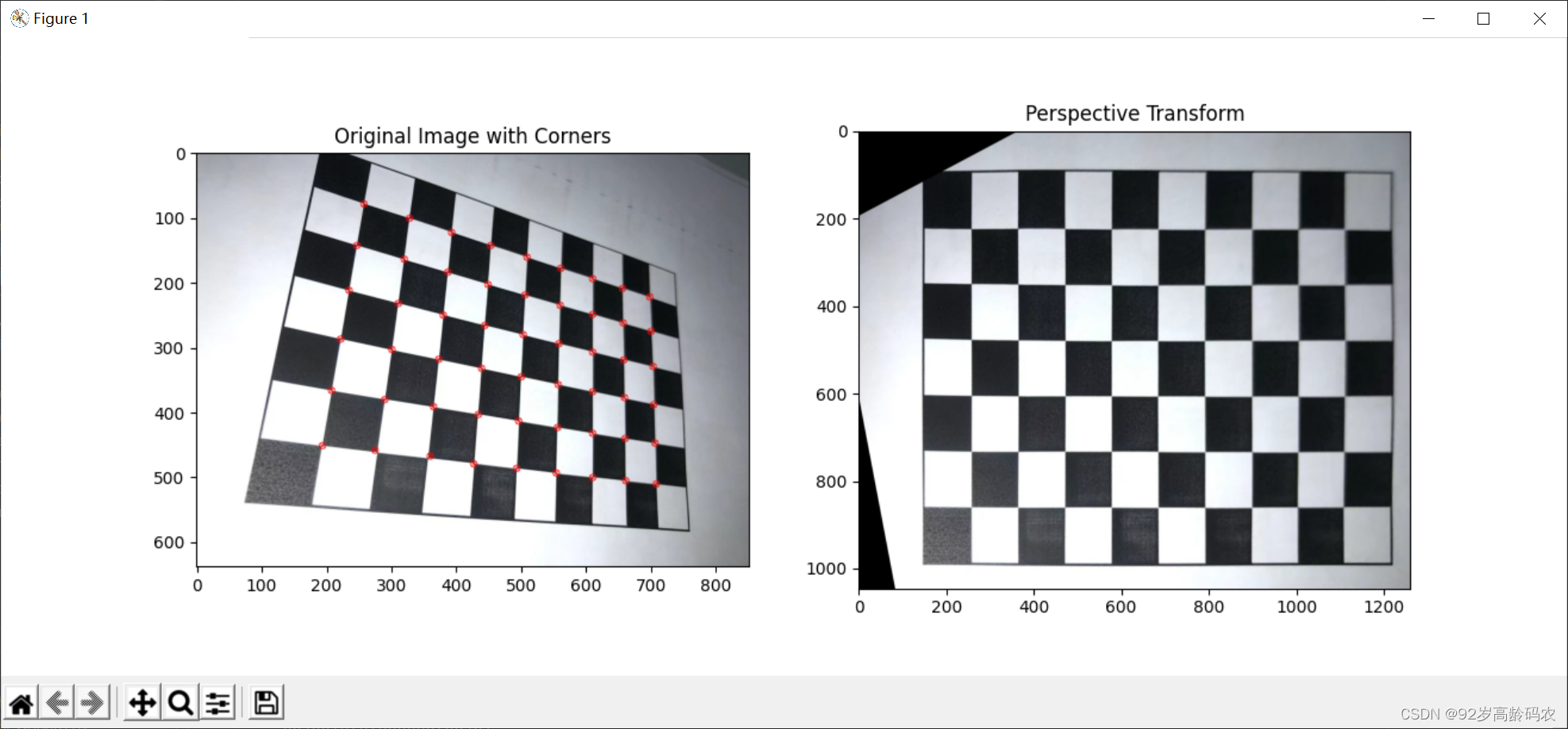
最后,可以通过可视化工具(如Matplotlib)展示预测结果,并进行模型性能的评估。
import matplotlib.pyplot as plt
# 绘制原始数据
plt.plot(df['ds'], df['y'], label='Actual')
# 绘制预测结果
plt.plot(forecast['ds'], forecast['yhat1'], label='Forecast', linestyle='dashed')
plt.xlabel('Date')
plt.ylabel('Power Demand')
plt.legend()
plt.show()注意事项与最佳实践
在使用NeuralProphet进行时间序列预测时,有一些注意事项和最佳实践可以帮助您更好地应用模型并获得准确的预测结果。
1. 数据质量
确保输入的时间序列数据质量良好,包括但不限于:
-
缺失值处理: 处理时间序列中的缺失值,可以通过插值或其他方法进行填充。
-
异常值处理: 处理异常值,以避免对模型训练产生负面影响。
# 处理缺失值和异常值的示例
df = df.dropna() # 删除缺失值
df = df[(df['y'] > 0) & (df['y'] < 500)] # 过滤异常值2. 节假日和特殊事件
如果时间序列中包含与业务相关的特殊事件或节假日,NeuralProphet允许用户通过holidays参数进行配置。确保正确标记这些事件,以提高模型的预测准确性。
# 节假日和特殊事件的配置示例
holidays = pd.DataFrame({
'holiday': 'special_event',
'ds': pd.to_datetime(['2022-01-01', '2022-02-14']),
'lower_window': 0,
'upper_window': 1,
})
model = NeuralProphet(holidays=holidays)3. 模型参数调整
NeuralProphet具有许多可调整的参数,如learning_rate、epochs等。通过调整这些参数,可以根据实际数据的特性优化模型的性能。
# 模型参数调整示例
model = NeuralProphet(learning_rate=0.01, epochs=100)
model.fit(df)4. 多季节性设置
对于包含多个季节性因素的时间序列,使用seasonality参数配置NeuralProphet,以更好地捕捉这些季节性变化。
# 多季节性设置示例
model = NeuralProphet(seasonality={'daily': {'fourier_order': 5}, 'yearly': {'order': 10}})5. 交叉验证
使用交叉验证评估模型在不同时间段的性能,以确保模型的泛化能力。
# 交叉验证示例
from neuralprophet import NeuralProphetCV
cv_model = NeuralProphetCV()
cv_model.fit(df, freq='D', valid_p=0.2, epochs=50)性能比较与优化
NeuralProphet在时间序列预测中表现出色,但在处理大规模数据时,性能优化仍然是一个重要的考虑因素。以下是一些性能比较和优化的建议:
1. 数据批处理
NeuralProphet支持通过batch_size参数进行数据批处理,以减少内存占用和提高训练速度。根据机器配置和数据集大小,调整batch_size可以显著影响训练性能。
# 数据批处理示例
model = NeuralProphet(batch_size=64)
model.fit(df)2. 多线程训练
NeuralProphet提供了num_workers参数,允许使用多线程进行数据加载和训练。通过增加num_workers,可以更充分地利用多核处理器,提高训练效率。
# 多线程训练示例
model = NeuralProphet(num_workers=4)
model.fit(df)3. GPU加速
NeuralProphet支持通过cuda参数启用GPU加速,适用于支持CUDA的NVIDIA GPU。使用GPU可以显著加速模型的训练过程。
# GPU加速示例
model = NeuralProphet(cuda=True)
model.fit(df)4. 模型预测批处理
在进行模型预测时,通过设置forecast_periods参数来指定预测的时间范围,以批处理的方式进行预测,提高预测性能。
# 模型预测批处理示例
future = model.make_future_dataframe(df, periods=365)
forecast = model.predict(future, forecast_periods=30)5. 模型保存与加载
为避免重复训练模型,建议将已训练好的模型保存到文件,并在需要时加载。这样可以节省训练时间,特别是对于大型模型和大规模数据集。
# 模型保存与加载示例
model.save_model('my_model')
loaded_model = NeuralProphet()
loaded_model.load_model('my_model')总结
NeuralProphet是一个功能强大的时间序列预测库,具有广泛的实际应用价值。通过实际应用案例,深入了解了NeuralProphet在电力需求预测等领域的应用,展示了其在处理多季节性因素的复杂时间序列数据时的卓越性能。在注意事项与最佳实践方面,强调了合理的数据批处理、多线程训练、GPU加速等策略,以及通过模型保存与加载提高效率的方法。此外,通过性能比较与优化,提供了一系列实用建议,包括调整批处理大小、使用多线程、启用GPU加速以及模型预测批处理等,以优化NeuralProphet在大规模数据上的处理效率。
总体而言,NeuralProphet以其灵活性和高度可定制的特性脱颖而出,使其成为处理实际项目中复杂时间序列的理想选择。无论是通过性能优化提高训练速度,还是通过多样性的模型配置应对不同的时间序列情景,NeuralProphet都展现了其强大的应用潜力。对于数据科学家和时间序列分析师来说,深入了解NeuralProphet的实际应用和性能优化策略将为他们在实际项目中取得更好的结果提供有力支持。
如果你觉得文章还不错,请大家 点赞、分享、留言 下,因为这将是我持续输出更多优质文章的最强动力!
更多Python学习内容:ipengtao.com
干货笔记整理
100个爬虫常见问题.pdf ,太全了!
Python 自动化运维 100个常见问题.pdf
Python Web 开发常见的100个问题.pdf
124个Python案例,完整源代码!
PYTHON 3.10中文版官方文档
耗时三个月整理的《Python之路2.0.pdf》开放下载
最经典的编程教材《Think Python》开源中文版.PDF下载

点击“阅读原文”,获取更多学习内容