写在前面:本博客仅作记录学习之用,部分图片来自网络,如需引用请注明出处,同时如有侵犯您的权益,请联系删除!
文章目录
- 引言
- MobileNets
- MobileNet - V1
- 思想
- 代码实现
- MobileNet - V2
- 思想
- 代码实现
- MobileNet - V3
- 思想
- 代码实现
- 总结
- 致谢
- 参考
引言
卷积神经网络在计算机视觉领域确实变得非常流行,并取得了很多重大突破,但是随着模型变得更加深、更加复杂,也面临着一些挑战。
其中一个主要挑战是模型的规模和速度问题。越深、越复杂的模型需要更多的计算资源,这对于一些计算有限的平台来说可能会导致性能瓶颈。特别是在一些现实世界的应用中,如嵌入式、移动设备等领域,识别任务需要在计算有限的平台上及时执行。
为了解决这个问题,很多轻量级卷积神经网络的设计方法被提出,大致有以下方法:
深度可分离卷积,将标准卷积层拆分为深度卷积层和逐点卷积层,在保持模型性能的同时可极大地减少计算量。
剪枝:通过删除一些不必要的权重或通道来减小模型的大小,在保持模型性能的同时减少参数数量和计算量。
蒸馏: 通过将一个复杂的模型(称为教师模型)的知识转移到一个简单的模型(称为学生模型)上的技术,即在保持学生模型的性能的同时,减少模型的复杂性和计算资源的需求。
量化: 通过对权重和激活值进行量化,将浮点数量化为较低精度的整数表示,从而减小模型的存储空间和内存带宽需求,加快推理速度,可有助于利用特定硬件加速器进行高效计算。
此外降低神经网络计算成本:降低通道,调整输入的分辨率。本文针对基于深度可分离卷积MobileNets的发展,进行叙述。
MobileNets
MobileNet - V1

MobileNets - V1: MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
论文速递: 点击转跳
思想
MobileNet模型基于深度可分离卷积,深度可分离卷积是一种分解卷积的形式,它将标准卷积分解为深度卷积和称为逐点卷积的1×1卷积,具有显著减少计算和模型大小的效果。 需要注意的是,深度卷积和逐点卷积并不是直接相连(结构等效上没问题,网上也有图直接连接的),实际上Mobilenet在两层卷积后都使用了BatchNorm和ReLU激活函数,因此下列图示中添加了BN和ReLU。

传统卷积的参数和计算量:
C
o
n
v
p
a
r
a
.
=
D
×
D
×
m
×
n
Conv_{para.} =D \times D \times m \times n
Convpara.=D×D×m×n
C
o
n
v
C
o
m
p
u
.
=
D
×
D
×
m
×
n
×
M
×
M
Conv_{Compu.} =D \times D \times m \times n \times M \times M
ConvCompu.=D×D×m×n×M×M

- BN的计算量和特征图大小、通道数相关,计算量相对较小,一般不会成为模型训练的瓶颈,在此记作 O ( H × W × C ) O(H×W×C) O(H×W×C)
- ReLU计算量相对较小,ReLU函数的运算只涉及简单的比较和取最大值操作,不需要进行指数等复杂运算,计算量近似表示为 O ( H × W × C ) O(H×W×C) O(H×W×C)。
对于需要进行指数运算和除法运算的激活函数,如Sigmoid、Tanh、Softmax等,其计算量可能会相对较大。幂运算通常需要逐步累乘,具有很高的时间复杂度,除法操作通常需要进行多次乘法和加法运算,进而会导致较大计算量。
深度可卷积的参数和计算量:
D
S
C
o
n
v
p
a
r
a
.
=
D
×
D
×
m
+
1
×
1
×
m
×
n
DSConv_{para.} =D \times D \times m + 1 \times 1 \times m \times n
DSConvpara.=D×D×m+1×1×m×n
D
S
C
o
n
v
C
o
m
p
u
.
=
D
×
D
×
m
×
M
×
M
+
1
×
1
×
m
×
n
×
M
×
M
+
O
(
H
×
W
×
C
)
DSConv_{Compu.} =D \times D \times m \times M \times M+ 1 \times 1 \times m \times n \times M \times M + O(H×W×C)
DSConvCompu.=D×D×m×M×M+1×1×m×n×M×M+O(H×W×C)
Mobilenet中的深度可分离卷积的参数/传统卷积的参数:
R
a
t
i
o
p
a
r
a
.
=
D
S
C
o
n
v
p
a
r
a
.
C
o
n
v
p
a
r
a
.
Ratio_{para.} = \dfrac {DSConv_{para.}} {Conv_{para.}}
Ratiopara.=Convpara.DSConvpara.=
D
×
D
×
m
+
1
×
1
×
m
×
n
D
×
D
×
m
×
n
\dfrac {D \times D \times m + 1 \times 1 \times m \times n} {D \times D \times m \times n}
D×D×m×nD×D×m+1×1×m×n=
1
n
\dfrac {1} { n}
n1 +
1
D
2
\dfrac {1} {D^2}
D21
在忽略BN、ReLU的计算量的前提下,Mobilenet中的深度可分离卷积的计算量/传统卷积的计算量:
R
a
t
i
o
C
o
m
p
u
.
=
D
S
C
o
n
v
C
o
m
p
u
.
C
o
n
v
C
o
m
p
u
.
Ratio_{Compu.} = \dfrac {DSConv_{Compu.}} {Conv_{Compu.} }
RatioCompu.=ConvCompu.DSConvCompu.=
D
×
D
×
m
×
M
×
M
+
1
×
1
×
m
×
n
×
M
×
M
+
O
(
H
×
W
×
C
)
D
×
D
×
m
×
n
×
M
×
M
≈
\dfrac {D \times D \times m \times M \times M+ 1 \times 1 \times m \times n \times M \times M + O(H×W×C)} {D \times D \times m \times n\times M \times M} \approx
D×D×m×n×M×MD×D×m×M×M+1×1×m×n×M×M+O(H×W×C)≈
1
n
\dfrac {1} { n}
n1 +
1
D
2
\dfrac {1} {D^2}
D21
此外MobileNet运算快的原因与矩阵乘法也有关系,模型结构将几乎所有的计算都放在密集的1 × 1卷积中,可通过高度优化的一般矩阵乘法(GEMM)函数来实现。1×1卷积不需要在内存中重新排序,可以直接使用GEMM实现,GEMM是最优化的数值线性代数算法之一。
卷积的展开是一种众所周知的技术,以便将卷积转换为矩阵乘法,卷积通常由GEMM实现,但需要在内存中进行初始的重新排序,以便将其映射到GEMM。由于卷积核的大小只有1×1,它不需要在输入数据上进行滑动窗口的移动,也不需要考虑步长的设置。因此,在计算1×1卷积时,可以将输入数据和卷积核都看作是一个向量,直接进行矩阵乘法运算。

代码实现
class Depthwise_Separable_Conv(nn.Module):
def __init__(self, ch_in, ch_out, kernel_size=3):
super(Depthwise_Separable_Conv, self).__init__()
self.depth_conv = nn.Conv2d(ch_in, ch_in, kernel_size=kernel_size, padding=kernel_size//2, groups=ch_in)
self.bn_depth_conv = nn.BatchNorm2d(ch_in) # 添加Batch Normalization层
self.point_conv = nn.Conv2d(ch_in, ch_out, kernel_size=1)
self.relu = nn.ReLU(inplace=True) # 添加ReLU激活函数
def forward(self, x):
x = self.depth_conv(x)
x = self.bn_depth_conv(x) # BN层作用在depthwise卷积结果上
x = self.relu(x) # ReLU激活函数作用在BN层输出结果上
x = self.point_conv(x)
return x
MobileNet - V2

MobileNet - V2: Inverted Residuals and Linear Bottlenecks
论文速递:点击转跳
MobileNetV1提出的深度可分离卷积,通过分解传统卷积为深度卷积和逐点卷积,在减少参数和计算量的同时保留其性能,实现了移动应用程序的任务。但是,在网络设计中多使用深度可分离卷积就能实现性能和速度的有效均衡吗?其实还有上升的空间。
思想
众所周知: 神经网络中的流形可以嵌入到低维子空间中。即在深度卷积层的所有单独的 d d d 通道像素中,其编码的信息实际上存在于一些流形中,并可嵌入到低维子空间中。
下图是嵌入高维空间的低维流形的ReLU变换的例子。初始螺旋被嵌入到N维空间中,使用随机矩阵
T
T
T,然后是
R
e
L
U
ReLU
ReLU,然后使用
T
−
1
T ^{- 1}
T−1投影回二维空间。在
n
=
2
,
3
n = 2,3
n=2,3,会导致流形的某些点相互坍缩而导致信息丢失,对于n = 15到30的变换是高度非凸的。

直观感觉: 输入中的有效信息可以映射到 N N N 维空间。然而激活函数的特性,如ReLU激活函数能够产生稀疏激活性,使得在输入值小于零时神经元会失效。N较小,激活函数会导致丢失较多关于输入的有效信息而难以映射回低维空间;N较大时,即使会导致丢失部分关于输入的有效信息也可以映射回低维空间而不产生太大的差异。类似 N N N通道的特征之间是可以互补,N较大具有更好的互补效果。
因此在进行ReLU前,特征具有更多的通道将有利于网络更好的学习,这同样适用于深度可分离卷积。 对于一些较深的网络,残差的出现让网络可以更深,残差通常具有下列特点:
- 解决梯度消失问题: 在深层神经网络中,随着信号通过多个层传播,梯度可能会逐渐变小并消失,导致网络难以训练。利用残差连接,可以将输入信号直接跳过一部分层级并与输出信号相加,使得梯度能够更容易地回传到较早的层级,有效减轻梯度消失问题,使得网络更容易训练。
- 加速模型收敛: 残差连接能够提供一条更短的路径,使得信息能够更快速地从输入传递到输出。这种跨层的直接连接有助于信息的快速传播和流动,加速了模型的收敛速度。相比于没有残差连接的网络,具有残差连接的网络通常能够更快地达到较好的性能。
- 提高模型的表达能力: 残差连接允许网络学习残差函数,即学习输入与输出之间的差异可以提高网络的表达能力,使得网络能够更好地适应复杂的数据分布和模式。
因此 MobileNet - V2 提出了关于倒残差的结构。传统的残差为减少计算量和参数,通常会压缩通道后再进行较大尺度卷积核提取特征,最后再调整通道和输入通道一致保证能相加。倒残差则是为充分利用ReLU的特性,首先扩充通道,将特征映射到更高的维度的空间,经由深度可分离卷积提取特征,最后在调整通道保证能与残差相加。通道变化和传统残差的通道变化相反,故称倒残差,残差的引入就可以将深度可分离应用到更深的网络中。

传统残差的参数,中间卷积核大小假设为
D
D
D,图示中设置为3:
R
e
s
p
a
r
a
.
=
1
×
1
×
m
×
n
+
D
×
D
×
n
×
n
+
1
×
1
×
m
×
n
Res_{para.} =1 \times 1 \times m \times n + D \times D \times n \times n + 1 \times 1 \times m \times n
Respara.=1×1×m×n+D×D×n×n+1×1×m×n =
2
m
n
+
n
2
D
2
2 m n + n^2 D^2
2mn+n2D2
倒残差的参数,中间卷积核大小假设为
D
D
D:
I
n
R
e
s
p
a
r
a
.
=
1
×
1
×
m
×
k
+
D
×
D
×
k
+
1
×
1
×
m
×
k
InRes_{para.} =1 \times 1 \times m \times k + D \times D \times k +1 \times 1 \times m \times k
InRespara.=1×1×m×k+D×D×k+1×1×m×k =
2
m
k
+
k
D
2
2 m k + kD^2
2mk+kD2
倒残差的参数与残差的参数比较:
R
a
t
i
o
p
a
r
a
.
=
I
n
R
e
s
p
a
r
a
.
R
e
s
p
a
r
a
.
Ratio_{para.} = \dfrac {InRes_{para.} } {Res_{para.}}
Ratiopara.=Respara.InRespara.=
2
m
k
+
k
D
2
2
m
n
+
D
2
n
2
\dfrac {2 m k + kD^2} {2 m n + D^2 n^2}
2mn+D2n22mk+kD2
当 n = m / 2 , k = 2 m , D = 3 n = m/2,k = 2m,D=3 n=m/2,k=2m,D=3 时,即传统残差通道压缩一半,深度可分离卷积通道扩展一倍
R a t i o p a r a . Ratio_{para.} Ratiopara.= 2 m k + k D 2 2 m n + D 2 n 2 \dfrac {2 m k + kD^2} {2 m n + D^2 n^2} 2mn+D2n22mk+kD2= 4 m 2 + 18 m 3.25 m 2 \dfrac {4m^2+ 18m} { 3.25m^2} 3.25m24m2+18m = 1.23 + 1 5.54 m 1.23+\dfrac {1} {5.54m} 1.23+5.54m1
当 n = m , k = 2 m , D = 3 n = m,k = 2m,D=3 n=m,k=2m,D=3 时,即传统残差通道不压缩,深度可分离卷积通道扩展一倍
R a t i o p a r a . Ratio_{para.} Ratiopara.= 2 m k + k D 2 2 m n + D 2 n 2 \dfrac {2 m k + kD^2} {2 m n + D^2 n^2} 2mn+D2n22mk+kD2= 4 m 2 + 18 m 11 m 2 \dfrac {4m^2+ 18m} { 11m^2} 11m24m2+18m = 4 11 + 18 11 m \dfrac {4} {11}+\dfrac {18} {11m} 114+11m18
可以发现,传统残差通道压缩一半,两者的参数在相近的数量,传统残差通道不压缩的时候,倒残差少一半的参数。相同的,ReLU等的计算量忽略的前提下,计算量也和上述结果差不多。
代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class InvertedResidualBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride, expansion):
super(InvertedResidualBlock, self).__init__()
self.stride = stride
hidden_dim = in_channels * expansion
self.conv = nn.Sequential(
# 逐点卷积扩张通道
nn.Conv2d(in_channels, hidden_dim, 1, 1, 0, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# 深度可分离卷积
nn.Conv2d(hidden_dim, hidden_dim, 3, stride, 1, groups=hidden_dim, bias=False),
nn.BatchNorm2d(hidden_dim),
nn.ReLU6(inplace=True),
# 逐点卷积压缩通道
nn.Conv2d(hidden_dim, out_channels, 1, 1, 0, bias=False),
nn.BatchNorm2d(out_channels)
)
# 步长为1需要残差,否则是以卷积实现下采样
self.use_res_connect = self.stride == 1 and in_channels == out_channels
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)
MobileNet - V3

MobileNet - V3: Searching for MobileNetV3
论文速递:点击转跳
MobileNetV2在MobileNetV1的基础上进一步优化深度可分离卷积的结构,针对ReLU的特性设计了倒残差模块,使得该模块可以应用于各种深度的网络。但MobileNetV2在网络结构上其实不是最佳的,MobileNetV3通过对网络架构搜索去探索网络获取更好的性能,并在倒残差模块上进一步的添加SE注意力机制去提升网络,并针对swish做了进一步的优化。
思想
深度神经网络的精度和效率之间寻找最优平衡点是近年来研究热点。新颖的手工结构和算法神经结构搜索在这一领域的发展中发挥了重要作用。
回顾: MobileNetV1引入了深度可分离卷积替代传统卷积层,通过将空间滤波与特征生成机制分离,有效地分解了传统卷积。MobileNetV2引入了线性瓶颈和倒残差结构,以便通过利用问题的低秩性来构建更有效的层结构。
MobileNetV3:将基于挤压和激励的轻量级注意力模块引入瓶颈结构,以构建最有效的模型,并优化激活函数swish,并使用网络架构搜索(NetAdapt)去获取最佳的网络结构。
下列为SE倒残差,其原理很简单,将倒残差的中间特征生成一个等通道数的一维向量对其中的特征进行一个加权或者说特征选择。

在一些研究中,使用swish的非线性激活函数来替代ReLU,显着提高了神经网络的准确性。但swish在嵌入式环境中的代价不容忽视,因为
σ
(
x
)
=
1
1
+
e
−
x
\sigma(x) = \frac{1}{1 + e^{-x}}
σ(x)=1+e−x1,其归一下依赖于除法和幂运算,因此对移动设备并不友好(这就是为什么在MobileNet - V1中比较计算量时能忽略ReLU、BN的计算量)。针对这个问题,MobileNet - V3提出了如下改变:
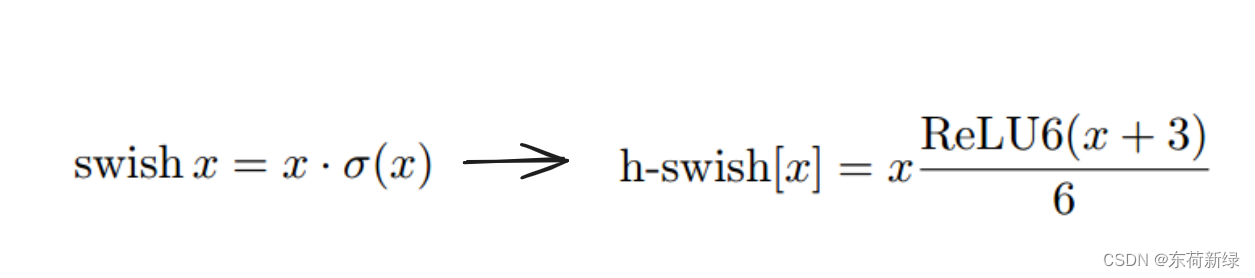
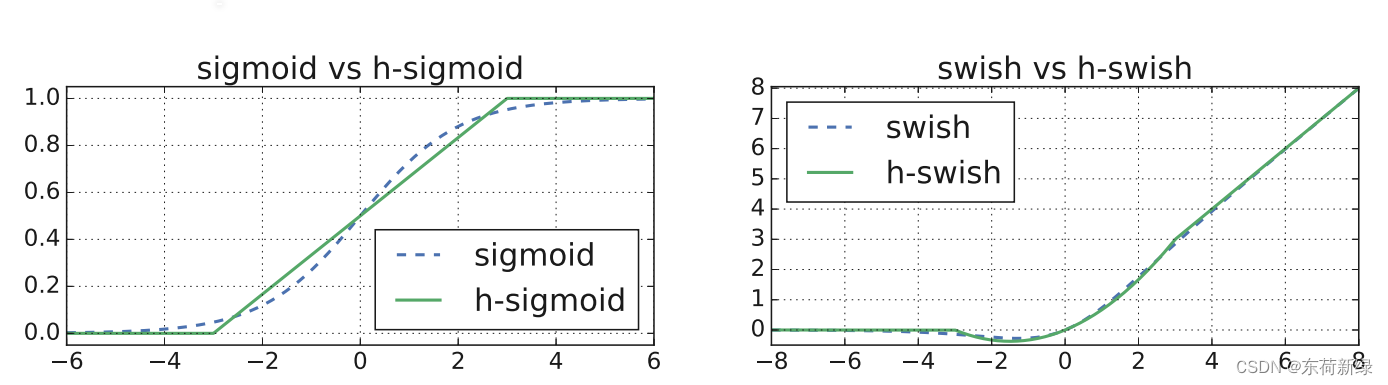
在上述的结构下结合下,MobileNetV3较好的平衡了精度和效率。
代码实现
import torch
import torch.nn as nn
import torch.nn.functional as F
class InvertedResidualBlock(nn.Module):
def __init__(self, input_dim, expand_ratio, output_dim, stride):
super(InvertedResidualBlock, self).__init__()
# 计算隐藏层的维度
hidden_dim = int(input_dim * expand_ratio)
# 定义卷积和批归一化层
self.conv1 = nn.Conv2d(input_dim, hidden_dim, kernel_size=1, stride=1, padding=0, bias=False)
self.bn1 = nn.BatchNorm2d(hidden_dim)
# 定义深度可分离卷积和批归一化层
self.conv2 = nn.Conv2d(hidden_dim, hidden_dim, kernel_size=3, stride=stride, padding=1, groups=hidden_dim, bias=False)
self.bn2 = nn.BatchNorm2d(hidden_dim)
# 定义输出卷积和批归一化层
self.conv3 = nn.Conv2d(hidden_dim, output_dim, kernel_size=1, stride=1, padding=0, bias=False)
self.bn3 = nn.BatchNorm2d(output_dim)
# 定义SE模块
self.se = SELayer(output_dim)
# 保存步长和输入输出维度
self.stride = stride
self.input_dim = input_dim
self.output_dim = output_dim
def forward(self, x):
# 保存输入特征图
identity = x
# 第一个1x1卷积,通道数扩张
x = self.conv1(x)
x = self.bn1(x)
x = F.relu6(x, inplace=True)
# 深度可分离卷积
x = self.conv2(x)
x = self.bn2(x)
x = F.relu6(x, inplace=True)
# 第二个1x1卷积,通道数减少
x = self.conv3(x)
x = self.bn3(x)
# 使用SE模块增强特征重要性
x = self.se(x)
# 如果步长大于1或者输入输出维度不一致,使用残差连接
if self.stride == 1 and self.input_dim == self.output_dim:
x += identity
return x
class SELayer(nn.Module):
def __init__(self, input_dim, reduction_ratio=16):
super(SELayer, self).__init__()
# 定义全局平均池化层和两个全连接层
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Linear(input_dim, input_dim // reduction_ratio)
self.fc2 = nn.Linear(input_dim // reduction_ratio, input_dim)
def forward(self, x):
b, c, _, _ = x.size()
# 计算特征的squeeze值
squeeze = self.avg_pool(x).view(b, c)
# 计算特征的excitation值
excitation = F.relu(self.fc1(squeeze))
excitation = torch.sigmoid(self.fc2(excitation)).view(b, c, 1, 1)
# 将特征与excitation值相乘
return x * excitation
总结
MobileNet是一种轻量级的深度卷积神经网络(CNN),旨在计算资源有限的移动设备上实现高效的推理。其设计出发点是通过减少模型参数和计算量来提高模型的速度和效率,同时尽可能保持模型的准确性。
MobileNet首先引入了深度可分离卷积(Depthwise Separable Convolution)结构。随后MobileNet由一系列的倒残差模块(Inverted Residual Blocks)组成。每个倒残差模块包含了一系列的卷积层和批归一化层,并且在适当的位置添加了SE模块进行通道注意力机制的增强。倒残差模块的核心思想是通过倒残差连接将输入和输出特征图相加,以避免信息的丢失,并且使用扩张因子(expand ratio)来控制通道数的变化,使得MobileNet在计算资源有限的设备上具有较低的内存占用和更快的推理速度,并具有较好的性能。
致谢
欲尽善本文,因所视短浅,怎奈所书皆是瞽言蒭议。行文至此,诚向予助与余者致以谢意。
参考
[1]. Howard A G, Zhu M, Chen B, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications[J]. arv preprint arv:1704.04861, 2017.
[2].Chellapilla K, Puri S, Simard P. High performance convolutional neural networks for document processing[C]//Tenth international workshop on frontiers in handwriting recognition. Suvisoft, 2006.
[3]. Sandler M, Howard A, Zhu M, et al. Mobilenetv2: Inverted residuals and linear bottlenecks[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 4510-4520.
[4]. Howard A, Sandler M, Chu G, et al. Searching for mobilenetv3[C]//Proceedings of the IEEE/CVF international conference on computer vision. 2019: 1314-1324.