1、常见的搜索结构
| 种类 | 数据格式 | 时间复杂度 |
| 顺序查找 | 无要求 | O(N) |
| 二分查找 | 有序 | O(log_2 N) |
| 二叉搜索树 | 无要求 | O(log_2 N) |
| 二叉平衡树 | 无要求 | O(log_2 N) |
| 哈希 | 无要求 | O(1) |
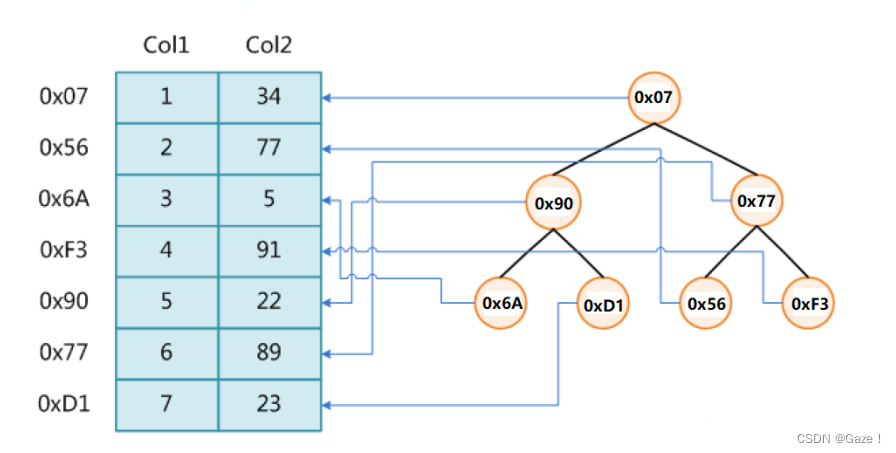
如果数据量很大,比如有100G数据,无法一次放进内存中,那就只能放在磁盘上了,上述搜索结构就不能发挥作用。如果放在磁盘上,如何处理数据?
在内存中只保存数据项需要查找的部分(key),以及指向该数据在磁盘中位置的指针。那么要访问数据时,先取这个地址去磁盘访问数据。
2、B树的概念
1970年,R.Bayer和E.mccreight提出了一种适合外查找的树,它是一种平衡的多叉树,称为B树。
一棵m阶(m>2)的B树,是一棵平衡的M路平衡搜索树,可以是空树。
满足以下性质:
- 根节点至少有两个孩子
- 每个分支节点都包含k-1个关键字和k个孩子,其中 m/2 ≤ k ≤ m,(孩子永远比关键字多一个)
- 每个叶子节点都包含k-1个关键字,其中 ceil(m/2) ≤ k ≤ m
- 所有的叶子节点都在同一层
- 每个节点中的关键字从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域划分
- 每个结点的结构为:(n,A0,K1,A1,K2,A2,… ,Kn,An(n为结点中关键字的个数,满足ceil(m/2)-1≤n≤m-1)
3、B树的插入分析
以M=3为例,具体表现为

我们这里多存储一个只是为了当B树已经有两个数据(已满)时,先插入进数据,然后好进行分裂操作。
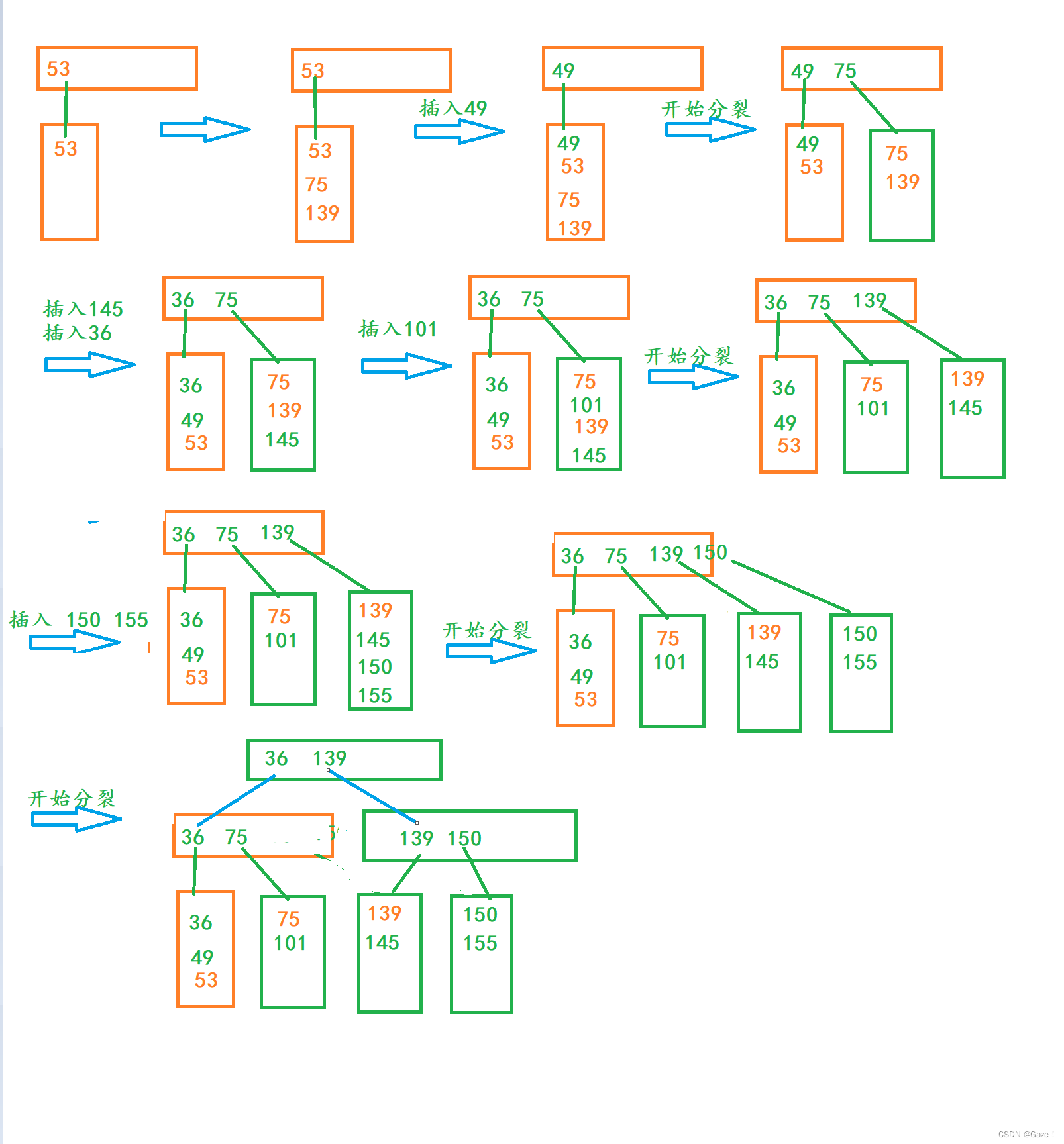
用序列{53, 139, 75, 49, 145, 36, 101}构建B树:
(1)插入 53 139
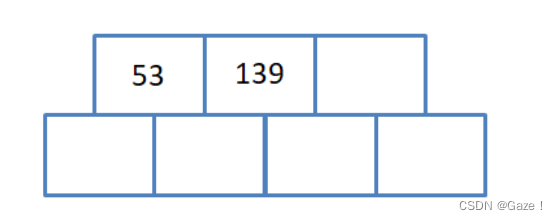
(2)已满 再插入75(关键字数量等于M)开始分裂
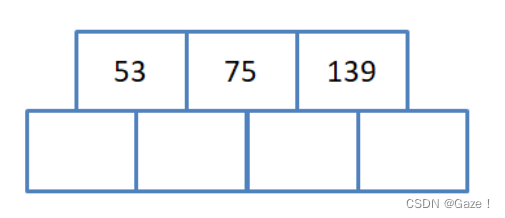
分裂规则:
分裂出一半(M/2)的值和孩子给兄弟
需要分裂的节点有M个关键字,找到中位数(75),右边M/2(139)给兄弟,中位数给父亲,没有父亲就创建一个父亲。
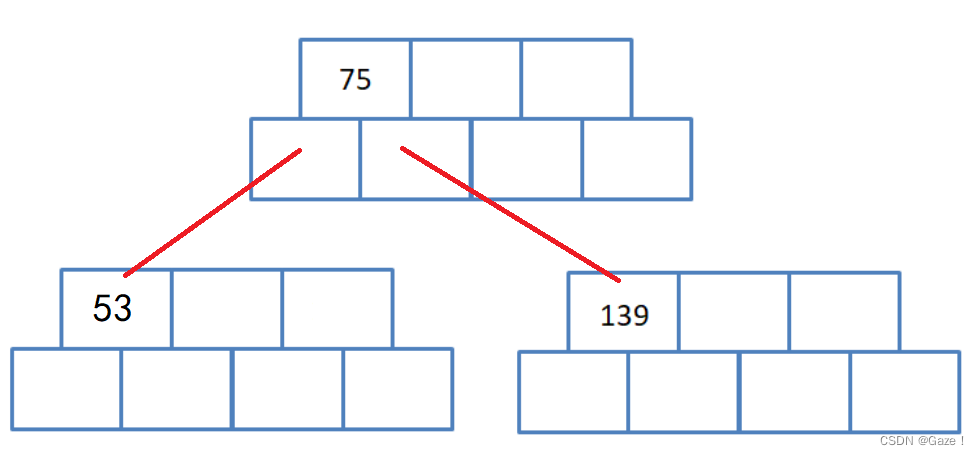
(3)插入49 145 36
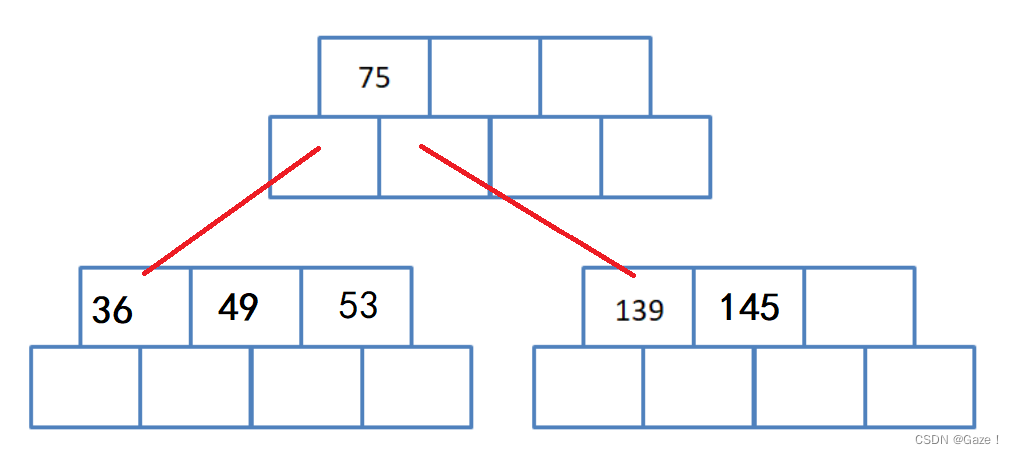
(4) 开始分裂
中位数(49) 右边M/2 (53)给分裂出来的兄弟节点 中位数给父亲节点
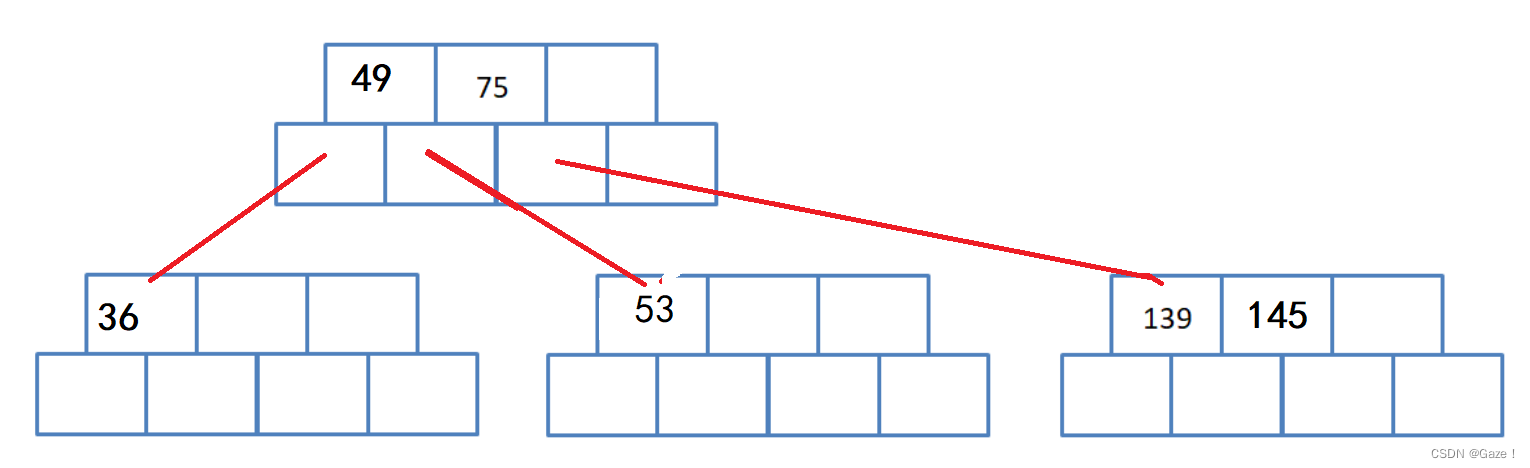
(5)插入101
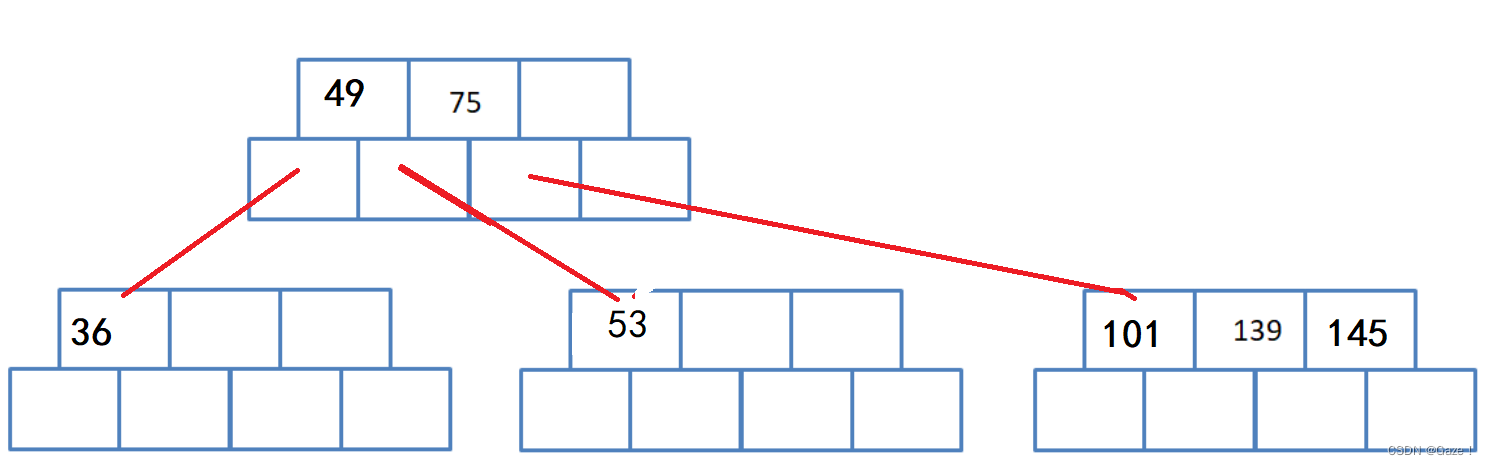
(6)开始分裂
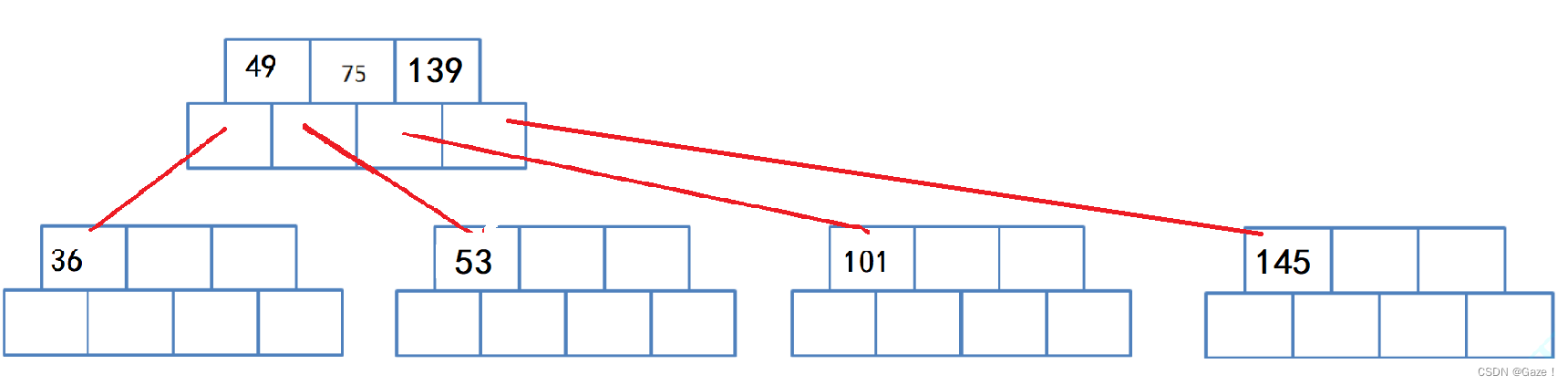
(7) 父亲满了 继续分裂

3.2插入过程的总结
1.如果树为空,直接插入新节点中,该节点为树的根节点
2.树非空,找待插入元素在树中的插入位置(注意:找到的插入节点位置一定在叶子节点中)
3.检测是否找到插入位置(假设树中的key唯一,即该元素已经存在时则不插入)
4.按照插入排序的思想将该元素插入到找到的节点中
4.检测该节点是否满足B树的性质:即该节点中的元素个数是否等于M,如果小于则满足
6.如果插入后节点不满足B树的性质,需要对该节点进行分裂。
(a)申请新节点找到该节点的中间位置
(b)将该节点中间位置右侧的元素以及其孩子搬移到新节点中
(c)将中间位置元素以及新节点往该节点的双亲节点中插入,即继续4
7. 如果向上已经分裂到根节点的位置,插入结束。
由于该插入规则,B树天然平衡向右和向上增长。
4.B树的性能分析
如果M=1024,B树共有四层,那么:

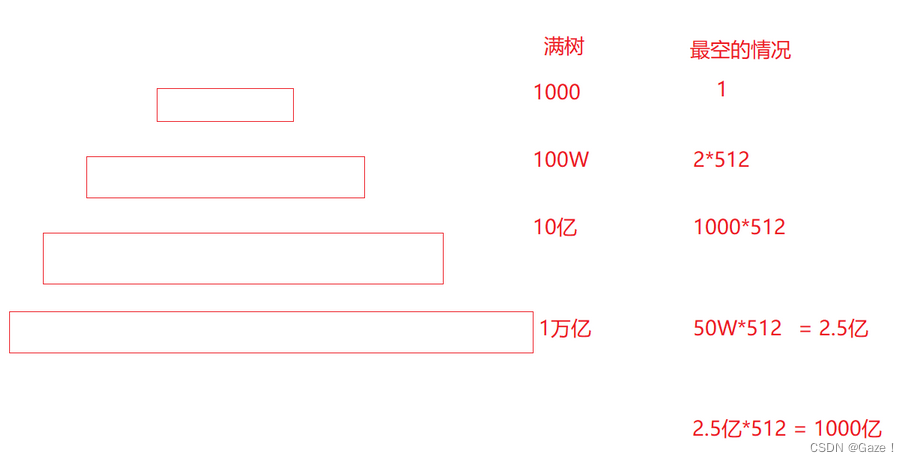
在620亿个元素中,如果这棵树的度为1024,则需要小于4次即可定位到该节点,然后利用
二分查找可以快速定位到该元素,大大减少了读取磁盘的次数。
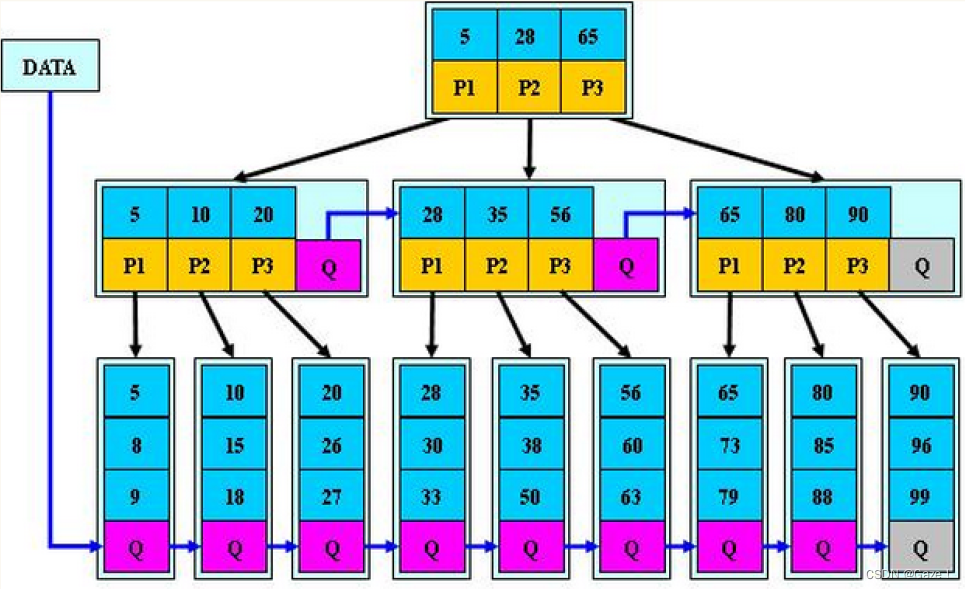
5.B+树和B*树
B+树是B树的变形,B+树的规则跟B树基本类似。
几点改进优化:
- 分支节点的子树指针与关键字个数相同
- 分支节点的子树指针p[i]指向关键字值大小在[k[i],k[i+1])区间之间。(相当于取消了最左边的那个子树)
- 所有叶子节点增加一个链接指针链接在一起
- 所有关键字及其映射数据都在叶子节点出现(分支节点和叶子节点有重复的值,分支节点存的是叶子节点的索引。父亲中存的是孩子节点中最小的值做索引)
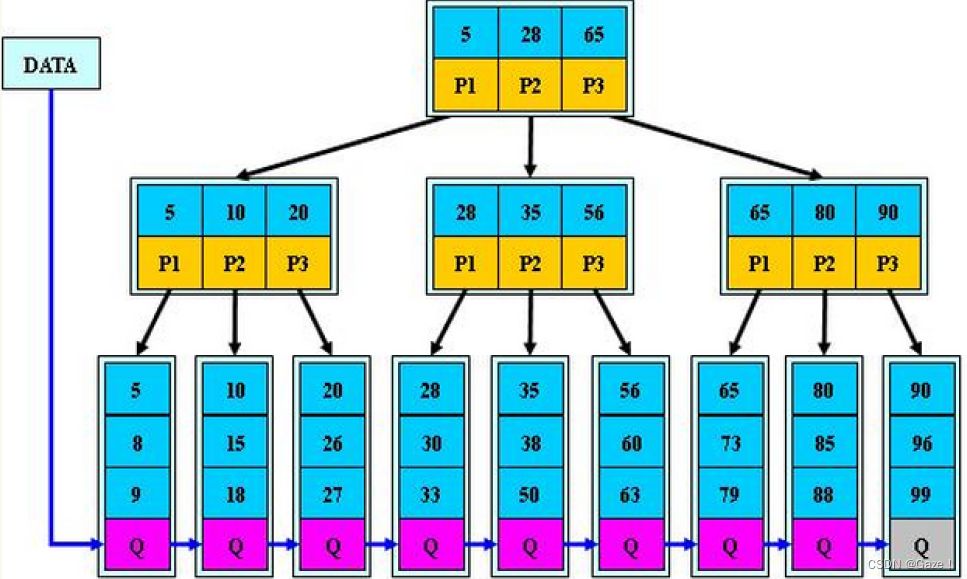
总结:
简化B树孩子比关键字多一个的规则,变成相等。
所有关键字都出现在叶子节点的链表中,且链表中的节点都是有序的,方便遍历查找所有值。
不可能在分支节点中命中,叶子节点才是存储数据的数据层。
5.2 图解B+树的插入
M等于3的B+树分裂过程 {53,139,75,49,145,36,101,150,155}
B+树的插入过程和跟B树基本是类似的,区别在于,第一次插入两层节点,一层做分支,一层做根。
B+树的分裂:
当一个结点满时,分配一个新的结点,并将原结点中1/2的数据复制到新结点,最后在父结点中增
加新结点的指针;B+树的分裂只影响原结点和父结点,而不会影响兄弟结点,所以它不需要指向
兄弟的指针。
5.3 B*树
B*树是B+树的变形,在B+树的非根和非叶子结点再增加指向兄弟节点的指针
B*树的分裂
当一个结点满时,如果它的下一个兄弟结点未满,那么将一部分数据移到兄弟结点中,再在原结
点插入关键字,最后修改父结点中兄弟结点的关键字(因为兄弟结点的关键字范围改变了);如
果兄弟也满了,则在原结点与兄弟结点之间增加新结点,并各复制1/3的数据到新结点,最后在父
结点增加新结点的指针。
B*树分配新结点的概率比B+树要低,空间使用率更高;
5.4 总结
B树:有序数组+平衡多叉树;
B+树:有序数组链表+平衡多叉树;
B*树:一棵更丰满的,空间利用率更高的B+树。