unordered_map 与 unordred_set 的模拟实现与 map 与 set 的模拟实现差不多。map 与 set 的模拟实现中,底层的数据结构是红黑树。unordered_map 与 unordered_set 的底层数据结构是哈希表。因此,在模拟实现 unordered_map 与 unordred_set 之前你必须确保你已经熟练的掌握哈希表。如果你还对哈希表感到陌生,你可以参考我之前写过的这两篇文章:
哈希表开散列的实现
我们这里实现的unordered_map与unordered_set是以开散列实现的哈希表作为底层数据结构的哦!
修改存储的数据
在 unordered_map 与 unordred_set 的使用部分,我们知道:他俩存储的数据类型是不一样的,为了让哈希表能同时适配出 unordered_map 与 unordered_set 我们就需要对 HashNode 进行一定程度的修改。原理比较简单哈,因为他们俩的数据类型不一样,我们只需要将他俩存储的数据类型模板化即可。通过传入不同的数据类型,实例化出 HashNode 存储不同元素的哈希表。
- 当这个模板参数传入
pair那么是unordered_map。 - 当这个模板参传入的不是一个
pair那么就是一个unordered_set。
template<class T>
struct HashNode
{
T _data;
HashNode<T>* _next;
HashNode(const T& data)
:_data(data)
, _next(nullptr)
{}
};
我们将原本两个模板参数改为了一个,传入什么类型,那么 HashNode 就存储这个类型。
key 的获取
对于 unnordered_set 来说,他的 key 值就是模板参数 T。但是对于 unordered_map 来说,他的 key 值却是:T.first。因为 unordered_map 存储的是一个 pair 嘛。
怎么解决呢?处理思路和模拟实现 map 和 set 是一样的。通过仿函数来实现。
因此在 HashTable 中又要增加一个模板参数,不妨叫做:KeyOfT。在这个仿函数中,我们会根据传入的数据类型获取他的 key 值。
- 对于
unordered_map来说仿函数会返回传入参数 first。因为它存储的是 pair 嘛。key 值就是他的 first。 - 对于
unordered_set来说,仿函数直接将传入参数本身返回。因为他存储的数据就是 key 值本身嘛!
//这是 unordered_set.h 的代码
#pragma once
#include"Hash.h"
template<class K>
class unordered_set
{
public:
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
private:
HashTable<K, K, SetKeyOfT> _ht;
};
在上面的代码中,我们定义了一个结构体 SetOfT 在这个结构体中,我们重载了圆括号运算符。然后将这个类型传入 HashTable 用来获取 unorered_set 的 key 值。你可能会问:为什么还要传入一个 K 值来实例化哈希表呢?不着急等会儿马上为你解答。
//这是 unordered_map.h 中的代码
#pragma once
#include "Hash.h"
template<class K, class V>
class unordered_map
{
public:
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
private:
HashTable<K, pair<K, V>, MapKeyOfT> _ht;
};
同样的,我们定义了一个结构体:MapOfT 在这个结构体结构体中,重载了圆括号运算符,然后将这个结构体类型传入 HashTable 中用来获取 unordered_map 的 key 值。
我们修改了 HashNode 的存储数据, HashTable 的模板参数。那么 HashTable 中的代码也需要做相应的修改。
我们先来看 HashTable 的模板参数:

-
K:有了这个模板参数,
HashTable的函数参数的类型能更加好写:


上面的两个成员函数中,我们都需要用到 key 的类型来定义函数的形参。如果HashTable的模板参数不加上 K,我们就很难获取unordered_map与unoredred_set的 key 值的类型。这便是为啥要在unordered_map.h与unordered_set中实例化哈希表的时候传入 key 值的类型。是不是非常精妙。 -
T:存储的数据类型,
unordered_map就是pair<K, V>;unordered_set就是:K。 -
KeyOfT:用该类型实例化出来对象,调用
operator(),仿函数嘛!获取 key 值。 -
HashFunc:这个模板参数可以处理字符串作为 key 值的情况。详细的逻辑在之前的文章:哈希表闭散列实现中讲过。
我们再来看 HashTable 中代码的修改:
- insert 函数的参数不再是
const pair<K, V>& kv,而是const T& data。 - 所有的获取 key 值的地方,都要使用仿函数来获取。
普通迭代器
不用说,哈希表的迭代器肯定不是原生指针。因为每一个哈希表节点数据并不是连续的物理空间。
我们就要思考如何封装哈希表的迭代器:
- 首先,类中肯定包含
HashNode的指针。 - 其次,在对迭代器进行加加或者减减运算时,可能会跨越不同的哈西桶,这个时候就比较难办了!不妨先想想我们应该如何解决。

- 假设我们当前迭代器指向的
HashNode的值为 44,那么当这个迭代器加加之后,我们就要跨越当前的哈希桶,找到下一个有效的HashNode。 - 再假设我们当前迭代器指向的
HashNode的值为 7,那么当这个迭代器减减之后,我们也要跨越当前哈希桶,向前找到一个有效的HashNode。
- 假设我们当前迭代器指向的
- 刚才谈到,我们迭代器加加或者减减之后可能跨越哈希桶。那么是不是要在迭代器中封装当前的哈希桶在数组中的下标呢?仔细一想其实是不需要的,因为我们可以通过当前迭代器,拿到存储数据的 key 值,经过除留余数法获得其在数组中的下标。
但是另外的一个问题就暴露出来了:跨越哈希桶的时候,迭代器中拿不到哈希表的 _table 哇,我们就无法向前或者向后寻找一个有效的HashNode。因此,在迭代器中我们可以封装一个HashTable的指针,在跨越哈希桶的时候就能顺利地向前或者向后查找啦!(当然实现的方法有很多,这取决于你的想象力啦!比如:你可以将 _table 传过来)
template <class K, class T, class KeyOfT, class HashFunc = DefaultHashFunc<K>>
struct __HashIterator
{
typedef HashNode<T> Node;
typedef __HashIterator<K, T, KeyOfT, HashFunc> self;
//构造函数
__HashIterator(Node* node, HashTable<K, T, KeyOfT, HashFunc>* pht)
{
_node = node;
_pht = pht;
}
HashTable<K, T, KeyOfT, HashFunc>* _pht;
Node* _node;
};
operator++()
- 如果当前迭代器的
_node->_next不为nullptr,说明当前节点的_next是一个有效的节点。我们直接修改_node为_node->_next即可。 - 如果当前迭代器的
_node->_next为空,那么,我们就需要寻找下一个位置。- 首先我们需要计算当前迭代器的
_node在HashTable的哪个下标。 - 然后从计算出来的下标的下一个位置开始,查找下一个不为空的哈希桶。
- 如果找不到不为空的哈希桶,说明当前迭代器的节点已经是哈希表的最后一个有效元素了。我们可以令
_node为nullptr充当我们end迭代器。
- 首先我们需要计算当前迭代器的
self operator++()
{
if(_node->_next) //当前的哈希桶还有节点
{
_node = _node->_next;
return *this;
}
else
{
KeyOfT kot;
HashFunc hf;
size_t hashi = hf(kot(_node->_data)) % _pht->_table.size();
++hashi;
while(hashi < _pht->_table.size())
{
if(_pht->_table[hashi])
{
_node = _pht->_table[hashi];
return *this;
}
else
{
++hashi;
}
}
_node = nullptr;
return *this;
}
}
operator!=()
这个函数简单,直接用节点的指针比较就可以啦!
bool operator!=(const self& s)
{
return _node != s._node;
}
operator*() 与 operator->()
这两个函数我们也写了很多遍了。分别返回数据域和数据域的指针就行。
T& operator*()
{
return _node->_data;
}
T* operator->()
{
return &_node->_data;
}
begin() 和 end()
这两个函数是在 HashTable 的类中写,千万不敢写迷糊了。
- begin():我们只需要遍历 _table 找到第一个不为空的哈希桶。返回这个哈希桶的第一个节点就行。如果找不到,就用
nullptr作为迭代器构造函数的第一个参数返回。 - end():直接用
nullptr作为迭代器的第一个参数即可。
在__HashIterator中,构造函数的第二个参数是哈希表的指针,begin 与 end 返回时第二个参数应该怎么传递呢?是不是就是this指针哇!这就是为什么我们将哈希表的指针作为迭代器成员的原因,因为简单嘛!如果是_table也行,总归要麻烦点。
iterator begin()
{
for(size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
if(cur) return iterator(cur, this);
}
return iterator(nullptr, this);
}
iterator end()
{
return iterator(nullptr, this);
}
你编译一下代码,发现编译不通过:原因就是在迭代器中你要用哈希表,在哈希表中你又要用迭代器。无论将哪一个类放在前面都行不通。因此需要加前置声明。
template <class K, class T, class KeyOfT, class HashFunc>
class HashTable;
为 unorered_map 与 unordered_set 添加 begin() 与 end()
这两个函数都比较简单哈!我们已经在 HashTable 中实现了 begin 与 end 函数。因此只需要在这两个容器中分别调用 begin 与 end 函数即可。
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
上面的代码在 unordred_map 与 unordered_set 中都搞一份就行啦!
代码写到这里我们就可以使用范围 for 遍历我们自己实现的
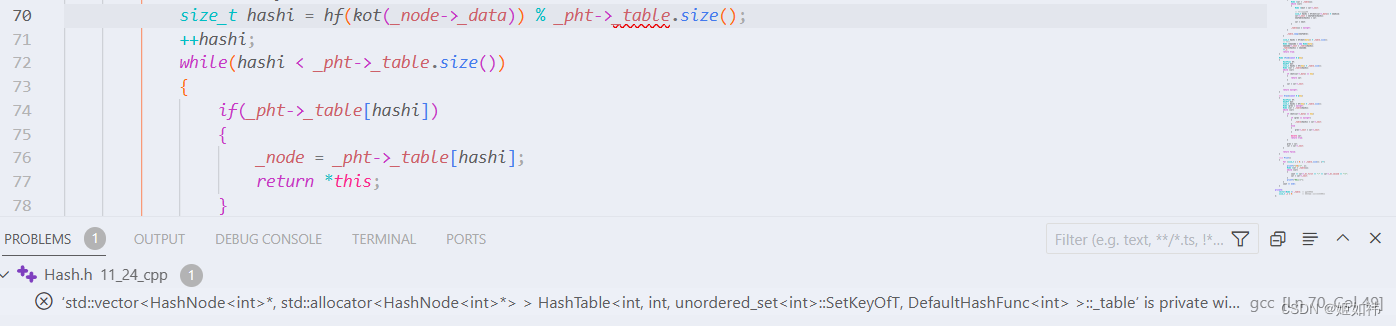
unordred_map和unordered_set了。但是我们运行代码之后又报了一个错误。说是:_table 不可访问。在迭代器中我们封转了哈希表的指针。但是因为 _table 是哈希表中的私有成员,外部当然不能访问啦!
这里就有两种比较靠谱的解决方式:
- 写一个函数,返回
HashTable的 _table 成员。- 用友元,谁是谁的友元呢?当然是
__HashIterator是HashTable的友元啦!
template <class K, class T, class KeyOfT, class HashFunc>
friend struct __HashIterator;
上面的代码在 visual studio 中运行是没有问题的,但是在 vscode 中就不能运行。报错的提示是:嵌套作用域不能使用相同的模板参数。如果你遇到了这样的报错提示,那么随便改一下模板参数的名称即可!
const 迭代器
首先我们要明确普通迭代器与 const 迭代器的区别,在之前封转 list,map,set 我们就已经知道,其实就是 begin 与 end 的返回值类型不一样嘛!处理方式都是一样的:将不一样的地方参数化即可!因此我们又要向 __HashIterator 中加入模板参数啦!
template <class K, class T, class Ref, class Ptr, class KeyOfT, class HashFunc>
struct __HashIterator
- Ref:表示返回引用,如果是普通迭代器传入的 Ref 就是 T&,返回的也就是 T& 啦!如果是 const 迭代器,传入的 Ref 就是 const T&,返回的自然也是 const T& 啦!
- Ptr:表示返回指针。如果是普通迭代器传入的 Ptr就是 T*,返回的也就是 T* 啦!如果是 const 迭代器,传入的 Ptr就是 const T*,返回的自然也是 const T* 啦!
因此:在 HashTable 中就要传入不同的参数类型,来定义出普通迭代器和 const 迭代器。
typedef __HashIterator<K, T, T&, T*, KeyOfT, HashFunc> iterator;
typedef __HashIterator<K, T, const T&, const T*, KeyOfT, HashFunc> const_iterator;
实现了 cosnt_iterator 之后呢?我们就需要为 HashTable 添加 const 迭代器的版本,也是非常简单呢!添加完成了之后,我们再为 unordred_map 与 unordered_set 添加 cosnt 迭代器。其中 unordered_set 的 key 值不允许修改,因此 unordered_set 的 iterator 与 const_iterator都是 const_iterator。
map 解决 key 不能被修改的方法就是:在 pair 中为 K 加上 const。
但是这么修改之后报错:

invalid conversion from ‘const HashTable<int, int, unordered_set::SetKeyOfT, DefaultHashFunc >’ to ‘HashTable<int, int, unordered_set::SetKeyOfT, DefaultHashFunc >’ [-fpermissive]
这是什么原因呢?begin() const 中的 const 修饰的是 this 指向的内容。因此,这里的 this 的完整类型为:const HashTable<K, T, KeyOfT, HashFunc> * 但是呢?迭代器的构造函数的第二个参数是:HashTable<K, T, KeyOfT, HashFunc>* pht
非 const 是无法转化为 const 类型的,因此会报错,解决办法就是在构造函数的参数加上 cosnt 就行。并且将 __HashIterator 的哈希表指针的成员改为 const。因为迭代器中不会通过哈希表的指针修改哈希表的内容。因此这么写完全没有问题呢!
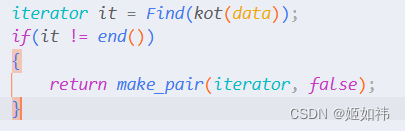
修改 Find 返回值
在库函数中 find 的返回值是 iterator。因此我们也需要修改。修改的方法很简单,只需在返回的地方处理一下就可以啦!
在返回的地方调用构造函数就可以啦!
iterator Find(const K &key)
{
HashFunc hf;
KeyOfT kot;
size_t hashi = hf(key) % _table.size();
Node *cur = _table[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur, this);
}
cur = cur->_next;
}
return iterator(nullptr, this);
}
修改 insert 函数的返回值
首先我们得知道库函数中 Insert 的返回值:pair<iterator, bool>
- 在判断哈希表中是否已经存在这个元素的时候,需要用 iterator 接收 Find 函数的返回值。通过这个返回值与 end 做比较,如果不等于 end 说明哈希表中已经存在这个元素了,我们返回这个迭代器,和 false 构造出来的 pair 即可。
- 如果是新插入,就用新插入的节点构造一个迭代器对象和 true 一起打包成 pair 返回即可。

好的,我们现在已经修改完成了HashTable中的 Insert 函数。之后呢,我们顺利的修改了unordered_map与unordered_set中的 insert 函数,但是修改之后编译,发现又出问题了!

如上图,在unordered_set中,insert 的返回值虽然看上去是:pair<iterator, bool> 但是因为unordered_set的 iterator 与 const_iterator 都是 const_iterator 。因此,unordered_set的 insert 函数返回值的实际类型是:pair<const_iterator, bool> 自然会出现类型不兼容,无法转换的问题。
解决办法在map与set的模拟实现部分已经讲解过了。
我们可以为__HashIterator加上一个非常像构造函数的函数:
typedef __HashIterator<K, T, T*, T&, KeyOfT, HashFunc> Iterator;
__HashIterator(const Iterator& it)
:_node(it._node)
,_pht(it._pht)
{}
Iterator 是用 T*,T&定义的,而不是 Ref 和 Ptr,因此当这个迭代器是普通迭代器的时候,就是拷贝构造函数。当这个迭代器是 const 迭代器的时候,就是一个类型转换。非常巧妙。
unordered_map 的 opertor[]
原理比较简单,就是调用 insert 函数。无论插入成功还是失败,都将 insert 返回值对应的 iterator 的数据中的 second 返回即可。
V& operator[](const K& key)
{
pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));
return ret.first->second;
}
完整代码
Hash.h
#pragma once
#include <vector>
template <class K>
struct DefaultHashFunc
{
size_t operator()(const K &key)
{
return (size_t)key;
}
};
// 12:00
template <>
struct DefaultHashFunc<string>
{
size_t operator()(const string &str)
{
// BKDR
size_t hash = 0;
for (auto ch : str)
{
hash *= 131;
hash += ch;
}
return hash;
}
};
template <class T>
struct HashNode
{
T _data;
HashNode<T> *_next;
HashNode(const T &data)
: _data(data), _next(nullptr)
{
}
};
template <class K, class T, class KeyOfT, class HashFunc>
class HashTable;
template <class K, class T, class Ref, class Ptr, class KeyOfT, class HashFunc>
struct __HashIterator
{
typedef HashNode<T> Node;
typedef __HashIterator<K, T, Ref, Ptr, KeyOfT, HashFunc> self;
typedef __HashIterator<K, T, T&, T*, KeyOfT, HashFunc> Iterator;
//构造函数
__HashIterator(Node* node, const HashTable<K, T, KeyOfT, HashFunc>* pht)
{
_node = node;
_pht = pht;
}
__HashIterator(const Iterator& it)
:_node(it._node)
,_pht(it._pht)
{}
self operator++()
{
if(_node->_next) //当前的哈希桶还有节点
{
_node = _node->_next;
return *this;
}
else
{
KeyOfT kot;
HashFunc hf;
size_t hashi = hf(kot(_node->_data)) % _pht->_table.size();
++hashi;
while(hashi < _pht->_table.size())
{
if(_pht->_table[hashi])
{
_node = _pht->_table[hashi];
return *this;
}
else
{
++hashi;
}
}
_node = nullptr;
return *this;
}
}
bool operator!=(const self& s)
{
return _node != s._node;
}
Ref operator*()
{
return _node->_data;
}
Ptr operator->()
{
return &_node->_data;
}
const HashTable<K, T, KeyOfT, HashFunc>* _pht;
Node* _node;
};
template <class K, class T, class KeyOfT, class HashFunc = DefaultHashFunc<K>>
class HashTable
{
public:
typedef HashNode<T> Node;
typedef __HashIterator<K, T, T&, T*, KeyOfT, HashFunc> iterator;
typedef __HashIterator<K, T, const T&, const T*, KeyOfT, HashFunc> const_iterator;
private:
template <class U, class Q, class W, class E, class Y, class I>
friend struct __HashIterator;
public:
iterator begin()
{
for(size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
if(cur) return iterator(cur, this);
}
return iterator(nullptr, this);
}
iterator end()
{
return iterator(nullptr, this);
}
const_iterator begin() const
{
for(size_t i = 0; i < _table.size(); i++)
{
Node* cur = _table[i];
if(cur) return const_iterator(cur, this);
}
return const_iterator(nullptr, this);
}
const_iterator end() const
{
return const_iterator(nullptr, this);
}
HashTable()
{
_table.resize(10, nullptr);
}
~HashTable()
{
for (size_t i = 0; i < _table.size(); i++)
{
Node *cur = _table[i];
while (cur)
{
Node *next = cur->_next;
delete cur;
cur = next;
}
_table[i] = nullptr;
}
}
pair<iterator, bool> Insert(const T &data)
{
KeyOfT kot;
iterator it = Find(kot(data));
if(it != end())
{
return make_pair(it, false);
}
HashFunc hf;
// 负载因子到1就扩容
if (_n == _table.size())
{
// 16:03继续
size_t newSize = _table.size() * 2;
vector<Node *> newTable;
newTable.resize(newSize, nullptr);
// 遍历旧表,顺手牵羊,把节点牵下来挂到新表
for (size_t i = 0; i < _table.size(); i++)
{
Node *cur = _table[i];
while (cur)
{
Node *next = cur->_next;
// 头插到新表
size_t hashi = hf(kot(cur->_data)) % newSize;
cur->_next = newTable[hashi];
newTable[hashi] = cur;
cur = next;
}
_table[i] = nullptr;
}
_table.swap(newTable);
}
size_t hashi = hf(kot(data)) % _table.size();
// 头插
Node *newnode = new Node(data);
newnode->_next = _table[hashi];
_table[hashi] = newnode;
++_n;
return make_pair(iterator(newnode, this), true);
}
iterator Find(const K &key)
{
HashFunc hf;
KeyOfT kot;
size_t hashi = hf(key) % _table.size();
Node *cur = _table[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
return iterator(cur, this);
}
cur = cur->_next;
}
return iterator(nullptr, this);
}
bool Erase(const K &key)
{
HashFunc hf;
KeyOfT kot;
size_t hashi = hf(key) % _table.size();
Node *prev = nullptr;
Node *cur = _table[hashi];
while (cur)
{
if (kot(cur->_data) == key)
{
if (prev == nullptr)
{
_table[hashi] = cur->_next;
}
else
{
prev->_next = cur->_next;
}
delete cur;
return true;
}
prev = cur;
cur = cur->_next;
}
return false;
}
void Print()
{
for (size_t i = 0; i < _table.size(); i++)
{
printf("[%d]->", i);
Node *cur = _table[i];
while (cur)
{
cout << cur->_kv.first << ":" << cur->_kv.second << "->";
cur = cur->_next;
}
printf("NULL\n");
}
cout << endl;
}
private:
vector<Node *> _table; // 指针数组
size_t _n = 0; // 存储了多少个有效数据
};
unodered_map.h
#pragma once
#include "Hash.h"
template<class K, class V>
class unordered_map
{
public:
struct MapKeyOfT
{
const K& operator()(const pair<K, V>& kv)
{
return kv.first;
}
};
typedef typename HashTable<K, pair<const K, V>, MapKeyOfT>::iterator iterator;
typedef typename HashTable<K, pair<const K, V>, MapKeyOfT>::const_iterator const_iterator;
pair<iterator, bool> insert(const pair<K, V>& kv)
{
return _ht.Insert(kv);
}
iterator begin()
{
return _ht.begin();
}
iterator end()
{
return _ht.end();
}
V& operator[](const K& key)
{
pair<iterator, bool> ret = _ht.Insert(make_pair(key, V()));
return ret.first->second;
}
private:
HashTable<K, pair<const K, V>, MapKeyOfT> _ht;
};
unordered_set.h
#pragma once
#include"Hash.h"
template<class K>
class unordered_set
{
public:
struct SetKeyOfT
{
const K& operator()(const K& key)
{
return key;
}
};
typedef typename HashTable<K, K, SetKeyOfT>::const_iterator iterator;
typedef typename HashTable<K, K, SetKeyOfT>::const_iterator const_iterator;
pair<iterator, bool> insert(const K& key)
{
pair<typename HashTable<K, K, SetKeyOfT>::iterator, bool> ret = _ht.Insert(key);
return pair<iterator, bool>(ret.first, ret.second);
}
iterator begin() const
{
return _ht.begin();
}
iterator end() const
{
return _ht.end();
}
private:
HashTable<K, K, SetKeyOfT> _ht;
};