经常会遇到一些需要预测的场景,比如预测品牌销售额,预测产品销量。
时间序列
今天分享一波使用 LSTM 进行端到端时间序列预测的完整代码和详细解释。
我们先来了解两个主题:
-
什么是时间序列分析?
-
什么是 LSTM?
时间序列分析:时间序列表示基于时间顺序的一系列数据。它可以是秒、分钟、小时、天、周、月、年。未来的数据将取决于它以前的值。
在现实世界的案例中,我们主要有两种类型的时间序列分析:
-
单变量时间序列(只有一列,因此即将到来的未来值将仅取决于它之前的值。如:仅依据历史销量数据预测未来数据)
-
多元时间序列(不同类型的特征值并且目标数据将依赖于这些特征。如:除历史销量数据外,还有促销活动、节假日等特征)
对于单变量时间序列数据,我们将使用单列进行预测。
LSTM
其他前置:LSTM:LSTM基本上是一个循环神经网络,能够处理长期依赖关系。
假设你在看一部电影。所以当电影中发生任何情况时,你都已经知道之前发生了什么,并且可以理解因为过去发生的事情所以才会有新的情况发生。RNN也是以同样的方式工作,它们记住过去的信息并使用它来处理当前的输入。RNN的问题是,由于渐变消失,它们不能记住长期依赖关系。因此为了避免长期依赖问题设计了lstm。
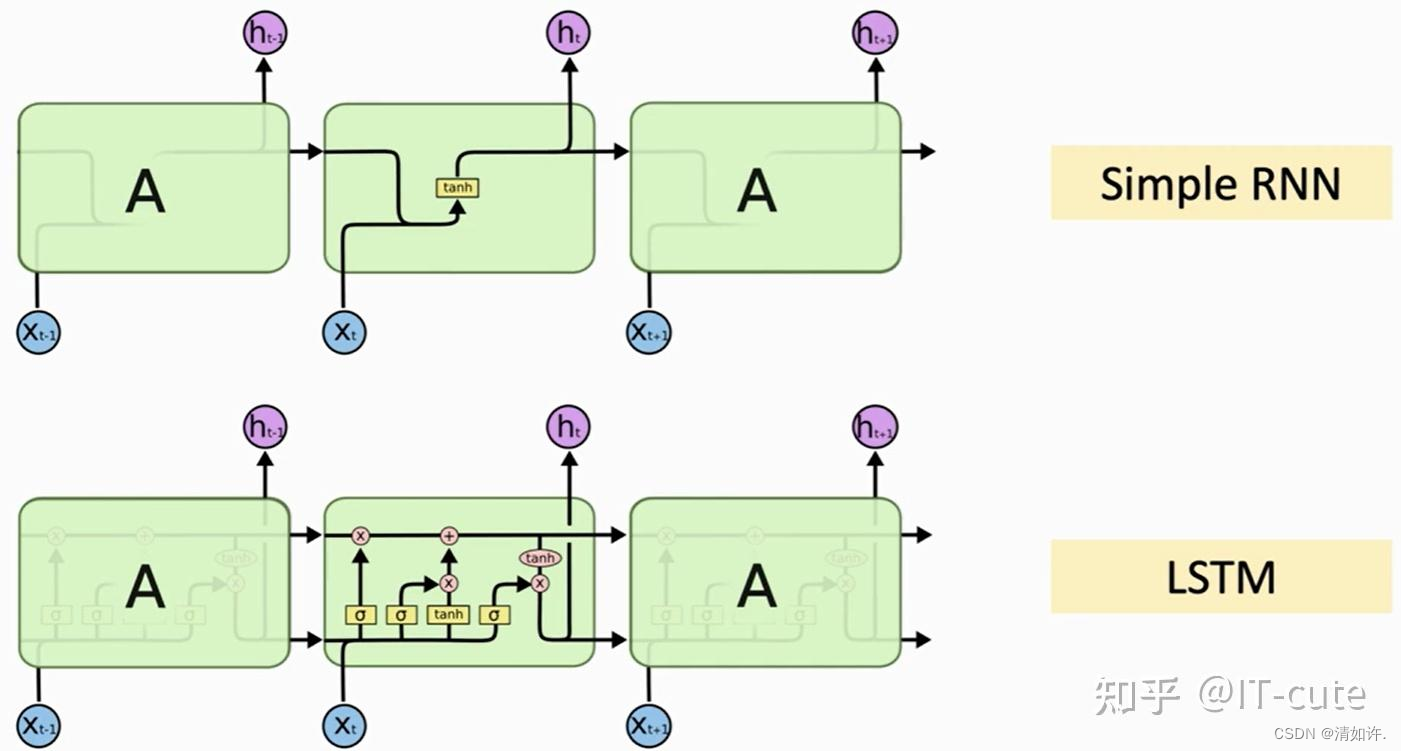
- LSTM 是一个神经网络,更具体是RNN (Recurrent ),所以我们需要用keras 基于tensorflow库
- LSTM 相比于一般的神经网络(NN),增加了长时记忆与短时记忆。
LSTM 相比于一般的RNN,有效解决了梯度消失的问题。梯度消失通俗的影响就是“长期记忆的丢失”。 - LSTM 相比于一般的RNN,从设计的角度来看,核心是多了一个cell。次核心是因为多了一个cell,每一步的迭代中重新设计了遗忘门,输入门和输出门,以及cell状态的更新。
下面开始编码实现
代码实现
数据集格式调整
为了便于方便,取出所需要的列,格式如下图所示,Date表示日期列,Product表示产品列,nums表示销售数量列。下面开始训练模型进行预测。

- 1、导入需要用到的库
请确保你已经安装了所需的库,可以使用以下命令进行安装:
pip install pandas numpy scikit-learn tensorflow
导入模型训练所需要的库:
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
- 读取CSV文件
df = pd.read_csv('weekly_product.csv')
- 将日期转换为Datetime对象
df['Date'] = pd.to_datetime(df['Date'], format='%Y/%m/%d')
- 按照日期升序排序
df.sort_values(by='Date', inplace=True)
- 确保数据按日期升序排列
df.reset_index(drop=True, inplace=True)
- 提取唯一的商品名称
products = df['Product'].unique()
- 创建一个空的DataFrame,用于存储预测结果
predicted_df = pd.DataFrame(columns=['Date', 'Product', 'nums'])
针对每种商品进行预测
for product in products:
product_df = df[df['Product'] == product].copy()
# 提取销售数量并进行归一化
sales = product_df['nums'].values.reshape(-1, 1)
scaler = MinMaxScaler(feature_range=(0, 1))
sales_scaled = scaler.fit_transform(sales)
# 将数据拆分为输入序列和目标值
X, y = [], []
for i in range(len(sales_scaled) - 10):
X.append(sales_scaled[i:i+10, 0])
y.append(sales_scaled[i+10, 0])
X, y = np.array(X), np.array(y)
# 将数据重塑为LSTM模型所需的形状 (samples, time steps, features)
X = np.reshape(X, (X.shape[0], X.shape[1], 1))
# 构建LSTM模型
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(X.shape[1], 1)))
model.add(LSTM(units=50))
model.add(Dense(units=1))
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
model.fit(X, y, epochs=50, batch_size=32)
# 预测未来10周的销售数据
future_dates = pd.date_range(start='2023-10-02', periods=10, freq='W')
future_sales = []
for i in range(10):
input_data = sales_scaled[-10:].reshape(1, 10, 1)
predicted_sales = model.predict(input_data)
future_sales.append(predicted_sales[0, 0])
# 更新输入数据,加入新的预测值
sales_scaled = np.concatenate([sales_scaled, predicted_sales], axis=0)
# 反归一化
future_sales = scaler.inverse_transform(np.array(future_sales).reshape(-1, 1))
# 计算模型的性能指标
true_sales = product_df['nums'].values[-10:]
mse = mean_squared_error(true_sales, future_sales)
mae = mean_absolute_error(true_sales, future_sales)
print(f"Product: {product}")
print(f"Mean Squared Error: {mse}")
print(f"Mean Absolute Error: {mae}")
# 创建预测数据的DataFrame
future_df = pd.DataFrame({'Date': future_dates, 'Product': product, 'nums': future_sales.flatten()})
# 将预测数据追加到原始数据框中
predicted_df = pd.concat([predicted_df, future_df], ignore_index=True)
最后,保存最终的预测数据框到CSV文件
predicted_df.to_csv('predicted_sales_MAE.csv', index=False)
模型的性能指标
在时间序列预测任务中,精确率(precision)和召回率(recall)等常用的分类模型评价指标通常不直接适用。取而代之的是,可以使用回归模型的评价指标,例如均方根误差(RMSE)或平均绝对误差(MAE)来评估模型的性能。
在回归任务中,常用的评价指标包括均方根误差(Root Mean Squared Error,RMSE)和平均绝对误差(Mean Absolute Error,MAE)。这些指标用于衡量模型的预测值与实际值之间的差异。

这些指标的解释如下:
-
RMSE解释: 如果RMSE等于0,表示模型的预测完全准确,没有任何误差。RMSE的值越小越好,因为它表示预测值与实际值之间的差异越小。
-
MAE解释: MAE的值越小越好,它表示模型的平均预测误差有多大。与RMSE不同,MAE不会受到异常值的影响,因为它使用的是绝对值。
在使用这些指标时,通常会选择适合问题特点的一个或多个指标进行评估。
完整代码
为了使模型更加复用性,将上面代码拆分成两个文件,一个用于模型的训练和保存,另一个用于加载模型并进行预测。请确保你有 pandas, numpy, scikit-learn, 和 tensorflow 安装在你的环境中。
File 1: train_and_save_model.py
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import LSTM, Dense
from sklearn.metrics import mean_squared_error, mean_absolute_error
# Read the CSV file
df = pd.read_csv('weekly_product.csv')
# Convert the 'Date' column to datetime
df['Date'] = pd.to_datetime(df['Date'], format='%Y/%m/%d')
# Sort the dataframe by date
df.sort_values(by='Date', inplace=True)
df.reset_index(drop=True, inplace=True)
# Extract unique product names
products = df['Product'].unique()
# Train and save a model for each product
for product in products:
product_df = df[df['Product'] == product].copy()
# Extract and normalize sales data
sales = product_df['nums'].values.reshape(-1, 1)
scaler = MinMaxScaler(feature_range=(0, 1))
sales_scaled = scaler.fit_transform(sales)
# Prepare the input sequences and target values
X, y = [], []
for i in range(len(sales_scaled) - 10):
X.append(sales_scaled[i:i + 10, 0])
y.append(sales_scaled[i + 10, 0])
X, y = np.array(X), np.array(y)
# Reshape the data for LSTM model
X = np.reshape(X, (X.shape[0], X.shape[1], 1))
# Build the LSTM model
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(X.shape[1], 1)))
model.add(LSTM(units=50))
model.add(Dense(units=1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(X, y, epochs=50, batch_size=32)
# Save the model
model.save(f'model_{product}.h5')
# Evaluate the model on the training data
train_predictions = model.predict(X)
train_predictions = scaler.inverse_transform(train_predictions)
true_sales = product_df['nums'].values[10:]
mse = mean_squared_error(true_sales, train_predictions)
mae = mean_absolute_error(true_sales, train_predictions)
print(f"Product: {product}")
print(f"Mean Squared Error on Training Data: {mse}")
print(f"Mean Absolute Error on Training Data: {mae}")
File 2: load_and_predict_model.py
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler
from tensorflow.keras.models import load_model
import datetime
# Function to load the trained model and make predictions
def predict_sales(product, date_str):
# Load the saved model
model = load_model(f'model_{product}.h5')
# Read the CSV file
df = pd.read_csv('weekly_product.csv')
# Convert the input date string to datetime
input_date = datetime.datetime.strptime(date_str, '%Y/%m/%d')
# Filter data for the given product and date
product_df = df[(df['Product'] == product) & (df['Date'] <= input_date)].copy()
# Extract and normalize sales data
sales = product_df['nums'].values.reshape(-1, 1)
scaler = MinMaxScaler(feature_range=(0, 1))
sales_scaled = scaler.fit_transform(sales)
# Prepare the input sequence for prediction
input_sequence = sales_scaled[-10:].reshape(1, 10, 1)
# Make predictions
predicted_sales_scaled = model.predict(input_sequence)
# Inverse transform to get the actual sales values
predicted_sales = scaler.inverse_transform(predicted_sales_scaled)
return predicted_sales[0, 0]
# Example usage
product_name = 'example_product'
prediction_date = '2023/11/20'
predicted_sales = predict_sales(product_name, prediction_date)
print(f"Predicted Sales for {product_name} on {prediction_date}: {predicted_sales}")
在上述代码中,train_and_save_model.py 文件用于训练模型并保存,而 load_and_predict_model.py 文件用于加载保存的模型并进行预测。在 load_and_predict_model.py 中,可以通过调用 predict_sales 函数来得到指定商品在指定日期的销售预测。