论文链接:https://arxiv.org/pdf/2311.07919.pdf
开源代码:https://github.com/QwenLM/Qwen-Audio
引言
大型语言模型(LLMs)由于其良好的知识保留能力、复杂的推理和解决问题能力,在通用人工智能(AGI)领域取得了重大进展。然而,语言模型缺乏像人类一样感知非文本模态(如图像和音频)的能力。作为一种重要模态,语音提供了超越文本的多样且复杂的信号,如人声中的情感、语调和意图,自然声音中的火车汽笛、钟声和雷声,以及音乐中的旋律。使LLMs能够感知和理解丰富的音频信号以进行音频交互引起了广泛关注。
以前关于遵循指令的工作主要是通过继承大型(多模态)LLMs的能力,采用轻量级的监督微调来激活模型的能力以与用户意图对齐。然而,由于缺乏能够处理各种音频类型和任务的预训练音频语言模型,大多数工作在音频交互能力上受到限制。现有的代表性音频语言多任务语言模型,如SpeechNet、SpeechT5、VIOLA 、Whisper和Pengi,仅限于处理特定类型的音频,如人声或自然声音。
简介
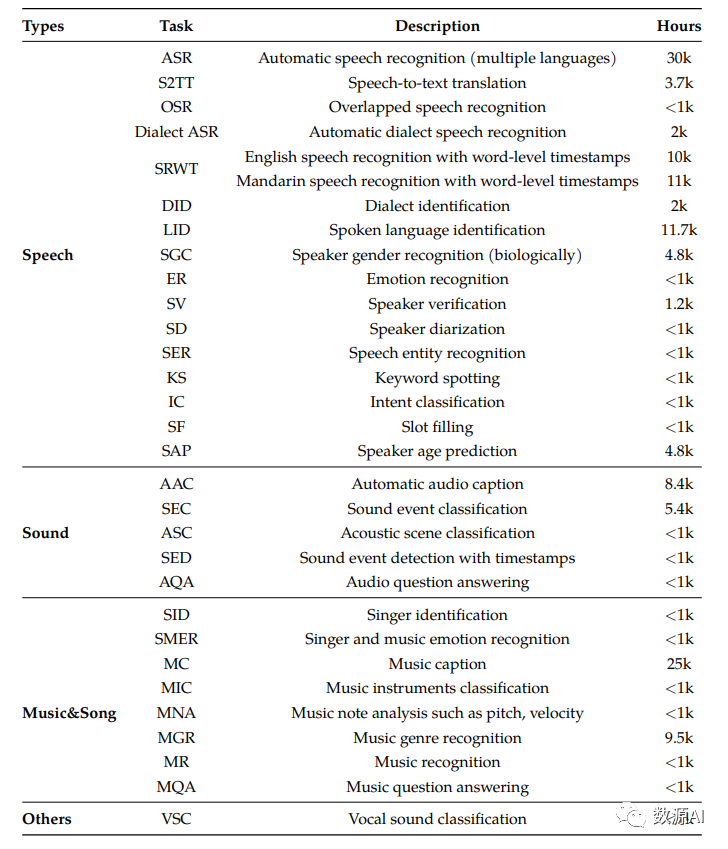
为了促进音频-文本多模态社区的增长和发展,我们引入了Qwen-Audio,一个大规模音频语言模型。Qwen-Audio是一个以音频和文本输入为条件的多任务语言模型,扩展了Qwen-7B语言模型,通过连接单个音频编码器有效地感知音频信号。与以往主要迎合单一类型的音频(如人声)的工作不同,或者专注于特定任务(如语音识别和字幕),或者将模型限制在单一语言上,我们扩大了训练规模,涵盖了超过30个任务、八种语言和各种音频类型,以推进通用音频理解能力的发展。
多任务和多数据集共同训练面临的一个重要挑战是不同数据集关联的文本标签的相当大的变化。这种变化源于任务目标、语言、注释粒度和文本结构(结构化或非结构化)的差异。为了解决这个一对多的挑战,我们精心设计了一个多任务训练框架,将解码器的输出条件为一系列分层标签。这种设计鼓励知识共享,并通过共享和指定标签来减少干扰。此外,我们还将语音识别与基于字级时间戳预测(SRWT)的任务结合起来进行训练,这在以前的多任务学习研究中通常被忽视。我们发现这个任务不仅在超越语音信号的基于语音的问题回答任务(如声音和音乐)方面改进了接地任务,还改善了ASR的性能。
方法与模型
本文介绍了Qwen-Audio和Qwen-Audio-Chat的详细信息,这两个系统旨在实现基于人类指令的通用音频理解和灵活交互。我们的模型训练过程包括两个阶段:多任务预训练和监督微调。
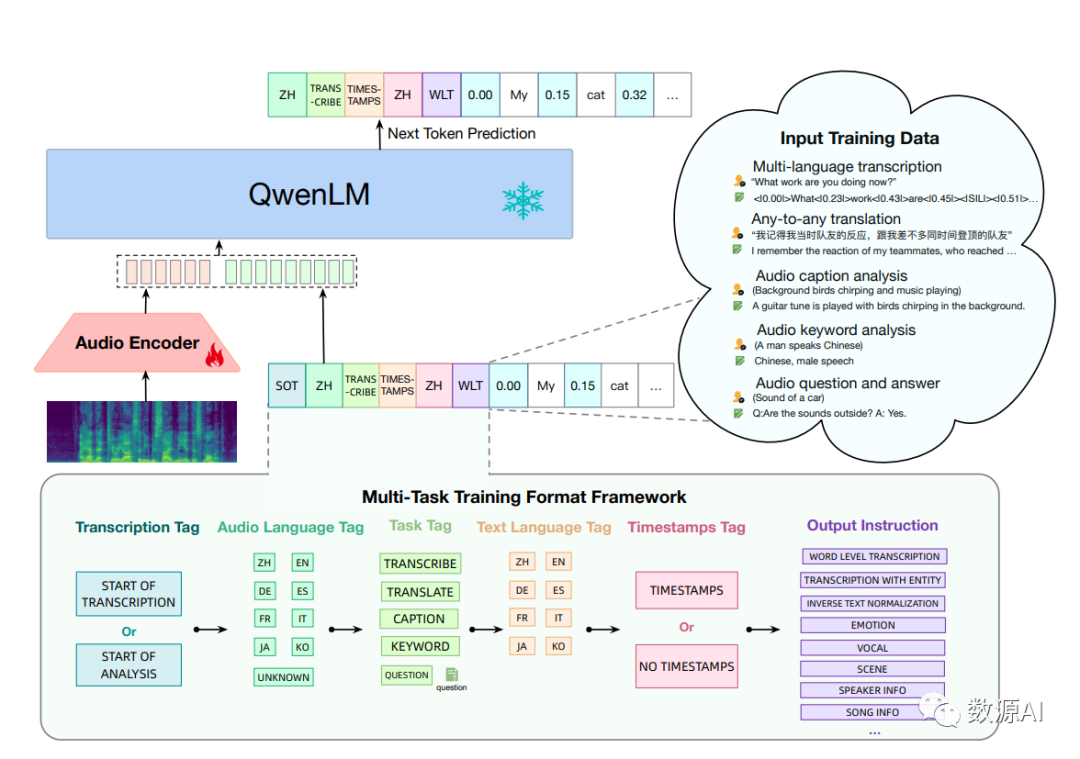
Qwen-Audio模型的结构如图所示。Qwen-Audio包含一个音频编码器和一个大型语言模型。给定成对数据(a, x),其中a和x表示音频序列和文本序列,训练目标是最大化下一个文本标记的概率。
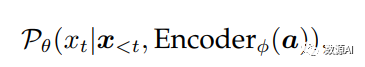
在给定音频表示和之前的文本序列x<t的条件下,θ和ϕ分别表示llm(large language model,大语言模型)和音频编码器的可训练参数。
1 音频编码器
Qwen-Audio采用单个音频编码器来处理各种类型的音频。音频编码器的初始化基于Whisper-large-v2模型 ,这是一个包含两个卷积下采样层作为起始层的32层Transformer模型。音频编码器由640M个参数组成。虽然Whisper是针对语音识别和翻译进行监督训练的,但它的编码表示仍然包含丰富的信息,如背景噪音,甚至可以用于恢复原始语音。为了预处理音频数据,Whisper将其重新采样为16kHz的频率,并使用25ms的窗口大小和10ms的跳跃大小将原始波形转换为80通道的Mel频谱图。此外,还加入了一个步幅为2的池化层以减少音频表示的长度。因此,编码器输出的每一帧大约对应于原始音频信号的40ms片段。在训练时应用了SpecAugment作为数据增强方法。
2 大语言模型
Qwen-Audio采用了一个大语言模型作为其基础组件。该模型使用从Qwen-7B导出的预训练权重进行初始化。Qwen-7B是一个32层Transformer解码模型,隐藏大小为4096,总共有77亿个参数。
3 多任务预训练
受Whisper的启发 ,为了将不同类型的音频结合起来,我们提出了一个多任务训练格式框架,如下所示:
• 转录标签:使用转录标签表示预测的开始。<|startoftranscripts|>用于指示任务涉及对口语的准确转录和捕获语音记录的语言内容,例如语音识别和语音翻译任务。对于其他任务,使用<|startofanalysis|>标签。
• 音频语言标签:然后,我们引入了一个语言标签,用于指示音频中的口语语言。该标签使用一个唯一的令牌来表示训练集中存在的每种语言,总共有八种语言。在音频片段不包含任何语音的情况下,例如自然声音和音乐,模型被训练来预测一个 <|unknown|> 令牌。
• 任务标签:接下来的标记指定了任务类型。我们将收集到的音频任务分为五种类别:<|transcribe|>(转录)、<|translate|>(翻译)、<|caption|>(字幕)、<|analysis|>(分析)和 <|question-answer|>(问答)任务。对于问答(QA)任务,我们在标签后添加相应的问题。
• 文本语言标签:标签令牌指定输出文本序列的语言。
• 时间戳标记:存在一个<|timestamps|>或<|notimestamps|>的标记决定模型是否需要预测时间戳。与Whisper中使用的句级时间戳不同,<|timestamps|>标记的包含需要模型进行细粒度的词级时间戳预测,简称为SRWT(带有词级时间戳的语音识别)。这些时间戳的预测与转录单词交叉进行:每个转录单词之前预测开始时间标记,而每个转录单词之后预测结束时间标记。根据我们的实验,SRWT提高了模型对音频信号与时间戳对齐的能力。这种改进的对齐有助于模型对语音信号进行全面理解,从而在诸多任务中取得显著进展,如语音识别和音频问答任务。
• 最后,我们提供输出说明,以进一步明确不同子任务的任务和所需格式,然后文本输出开始。我们框架的指导原则是通过共享标签来最大化类似任务之间的知识共享,从而提高它们的性能。同时,我们确保可以区分不同的任务和输出格式,以避免模型中的一对多映射问题。
4 监督微调
多任务模型的广泛预训练使其具备了广泛的音频理解能力。在此基础上,我们采用基于指示的微调技术来提高模型与人类意图的对齐能力,从而得到一个交互式聊天模型,命名为Qwen-Audio-Chat。
为了实现这一目标,我们为每个任务手动创建演示。这些演示包括原始文本标签、问题和答案。然后,我们利用GPT-3.5 根据提供的原始文本标签生成更多的问题和答案。此外,我们还通过手动注释、模型生成和策略串联的方式创建了一个音频对话数据集。这个数据集帮助我们将推理、故事生成和多图像理解能力融入到我们的模型中。
为了有效处理多音频对话和多个音频输入,我们引入了使用 "Audio id:" 标记不同音频的约定,其中 id对应音频输入对话的顺序。在对话格式方面,我们使用ChatML (Openai)格式构建我们的指示微调数据集。在这个格式中,每个交互的陈述都用两个特殊标记(和)标注,以便促进对话的终止。
为了在多轮对话中实现对音频和纯文本模态的灵活输入,我们在训练过程中使用了上述提到的音频为中心的指令数据和纯文本指令数据的组合。这种方法使模型能够无缝处理多种形式的输入。指令调整数据的总量为20k。

实验与结果
对于多任务预训练,我们冻结LLM的权重,只优化音频编码器。我们将训练得到的模型称为Qwen-Audio。在随后的监督微调阶段,我们固定音频编码器的权重,只优化LLM。得到的模型被标记为Qwen-Audio-Chat。
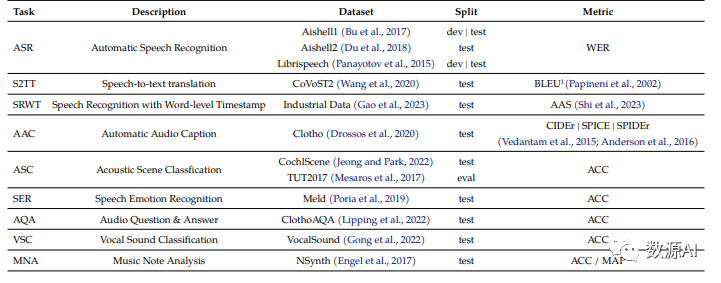
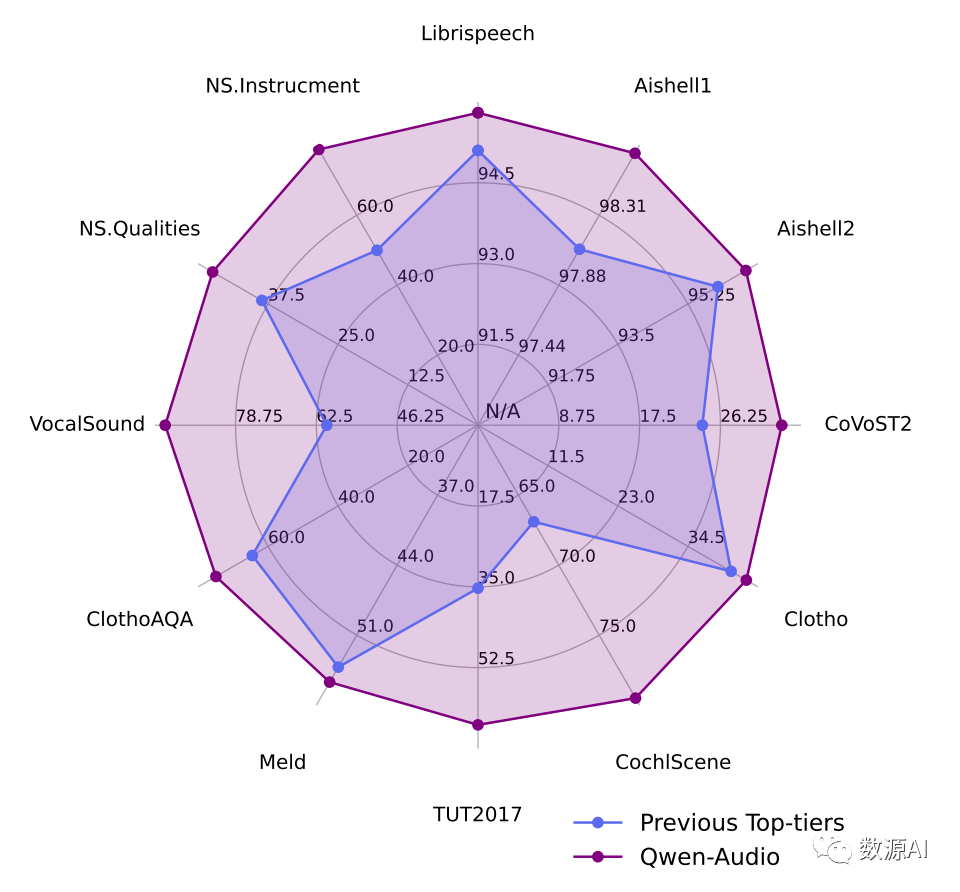
为了评估Qwen-Audio的普适理解能力,我们进行了全面评估,包括自动语音识别(ASR)、语音到文本翻译(S2TT)、自动音频字幕生成(AAC)、声场分类(ASC)、语音情绪识别(SER)、音频问答(AQA)、声音分类(VSC)和音符分析(MNA)等多个任务。该评估在12个数据集上进行,为避免数据泄露,评估数据集严格排除训练数据。
12个数据集测评结果
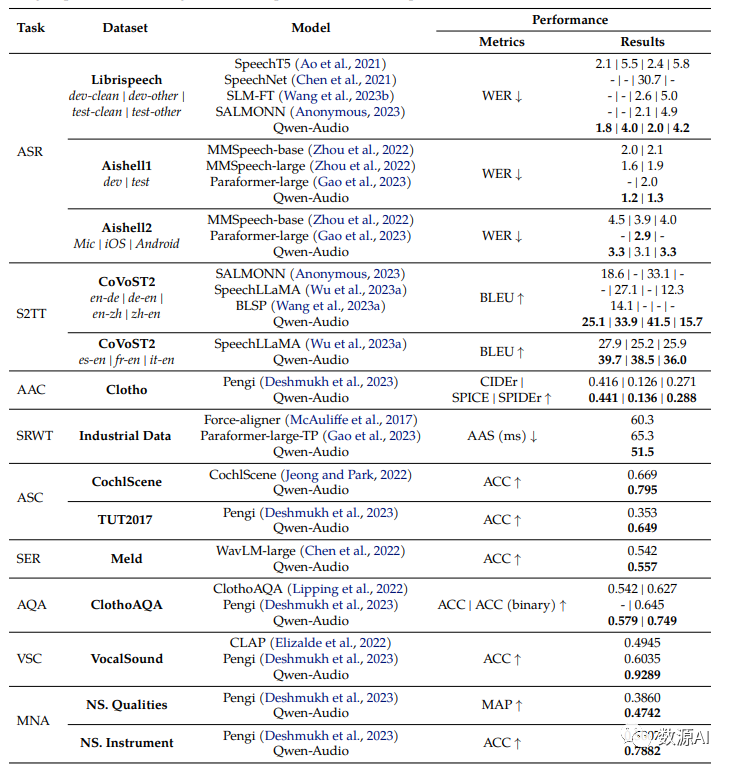
我们首先检查其英文自动语音识别(ASR)结果,其中Qwen-Audio在与前期多任务学习模型相比表现出更好的性能。具体而言,它在librispeech测试集的test-clean和test-other数据集上分别实现了2.0%和4.2%的词错误率(WER)。类似地,中文普通话ASR的结果显示Qwen-Audio在与之前的方法相比具备竞争力的性能。据我们所知,Qwen-Audio在Aishell1 dev和test数据集上取得了最先进的结果。此外,我们评估了Qwen-Audio在CoVoST2数据集上的语音翻译性能。
Qwen-Audio-Chat 的对话示例