大型语言模型指的是具有数十亿参数(B+)的预训练语言模型(例如:GPT-3, Bloom, LLaMA)。这种模型可以用于各种自然语言处理任务,如文本生成、机器翻译和自然语言理解等。
大语言模型的这些参数是在大量文本数据上训练的。现有的大语言模型主要采用 Transformer 模型架构,并且在很大程度上扩展了模型大小、预训练数据和总计算量。他们可以更好地理解自然语言,并根据给定的上下文(例如 prompt)生成高质量的文本。其中某些能力(例如上下文学习)是不可预测的,只有当模型大小超过某个水平时才能观察到。
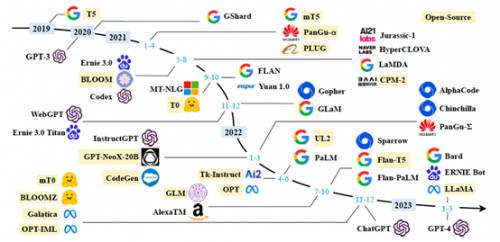
以下是 2019 年以来出现的各种大语言模型(百亿参数以上)时间轴,其中标黄的大语言模型已开源。
在本期文章中,我们将一起探讨大语言模型的发展历史、语料来源、数据预处理流程策略、训练使用的网络架构、最新研究方向分析(LLaMA、PaLM-E 等),以及在亚马逊云科技上进行大语言模型训练的一些最佳落地实践等。
大语言模型的发展历史
我们首先来了解下大语言模型的发展历史和最新研究方向分析。
大语言模型 1.0。过去五年里,自从我们看到最初的Transformer模型 BERT、BLOOM、GPT、GPT-2、GPT-3 等的出现,这一代的大语言模型在 PaLM、Chinchilla 和 LLaMA 中达到了顶峰。第一代 Transformers 的共同点是:它们都是在大型未加标签的文本语料库上进行预训练的。
大语言模型 2.0。过去一年里,我们看到许多经过预训练的大语言模型,正在根据标记的目标数据进行微调。第二代 Transformers 的共同点是:对目标数据的微调,使用带有人工反馈的强化学习(RLHF)或者更经典的监督式学习。第二代大语言模型的热门例子包括:InstructGPT、ChatGPT、Alpaca 和 Bard 等。
大语言模型 3.0。过去的几个月里,这个领域的热门主题是参数高效微调和对特定领域数据进行预训练,这是目前提高大语言模型计算效率和数据效率的最新方法。另外,下一代大语言模型可能以多模态和多任务学习为中心,这将为大语言模型带来更多崭新并突破想象力的众多新功能。
近年来的大语言模型概览
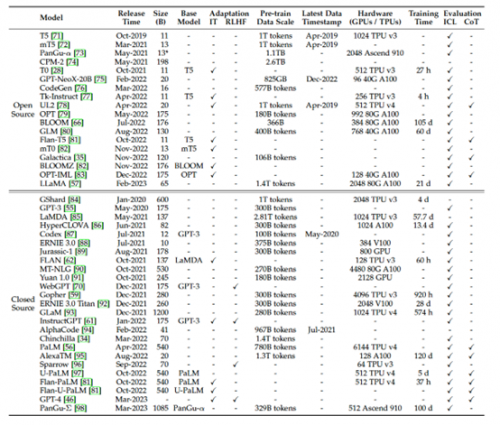
上图展示了近年来大语言模型(大于 10B 的参数)的统计数据,包括容量评估、预训练数据规模(token 数量或存储大小)和硬件资源成本。
图中,“Adaptation” 表示大语言模型是否经过了后续微调:IT 表示指令调整,RLHF 表示通过人工反馈进行强化学习。“Evaluation” 表示大语言模型在原始论文中是否经过了相应能力的评估:ICL 表示上下文学习(in-context learning),CoT 表示思维链(chain-of-thought)。
大语言模型的语料来源
与早期的预训练语言模型(PLMs)相比,包含更多参数的大语言模型需要更大的训练数据量,涵盖了更广泛的内容。为了满足这种需求,已经发布了越来越多的用于研究的训练数据集。根据他们的内容类型,大致可分类为六组:图书、CommonCrawl、Reddit 链接、维基百科、代码和其它。如下表所示:
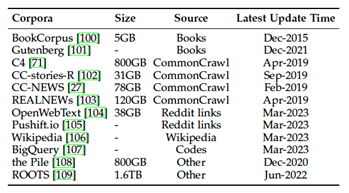

上图展示了现有大语言模型预训练数据中,各种不同的数据来源占比比率的信息。
大语言模型的数据预处理策略
在收集了大量数据后,对其进行预处理对于构建预训练语料库至关重要,尤其是要删除嘈杂、冗余、不相关和潜在的有毒数据,这可能会在很大程度上影响大语言模型的容量和性能。该论文中,研究者们用一个章节专门阐述了其研究团队的数据预处理策略,以及如何通过各种方法来提高所收集数据质量。

上图为该论文阐述大语言模型的预训练数据处理的典型策略概览图。
大语言模型的网络结构
大语言模型在训练阶段的网络结构设计参数,也是影响大语言模型性能的重要指标之一。下表列举了一些大语言模型的主要网络结构参数,包括:token 大小、归一化方式、位置嵌入方式、激活函数、是否使用 Bias、层数、注意力头的数量、隐藏状态大小、最大上下文长度等参数。如下表所示:
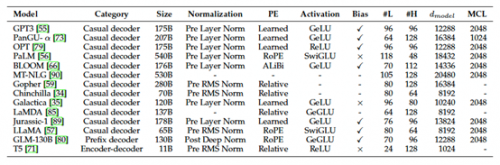
上表概述了包含详细配置信息的多个大语言模型的型号卡(Model cards):
PE 表示位置嵌入
#L 表示层数
#H 表示注意力头的数量
dmodel 表示隐藏状态的大小
MCL 表示最大上下文长度
大语言模型的涌现能力
LLM 的涌现能力被正式定义为「在小模型中不存在但在大语言模型中出现的能力」,这是 LLM 与以前的 PLM 区分开来的最显著特征之一。当出现这种新的能力时,它还引入了一个显著的特征:当规模达到一定水平时,性能显著高于随机的状态。以此类推,这种新模式与物理学中的相变现象密切相关。原则上,这种能力也可以与一些复杂的任务有关,而人们更关心可以应用于解决多个任务的通用能力。
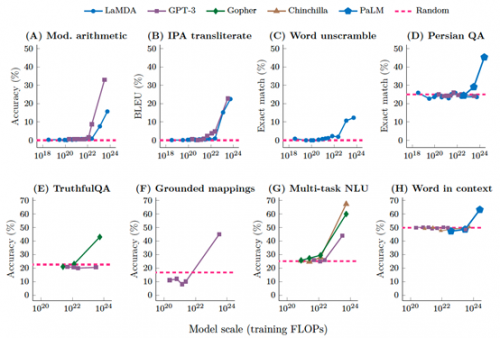
在少量提示(few-shot prompting)方法下测试了以下八个不同场景的大语言模型性能:
算术运算(Mod. arithmetic)
语音翻译(IPA transliterate)
单词解读(Word unscramble)
Persian QA
TruthfulQA 基准
概念映射(Grounded mappings)
多任务语言理解(Multi-task NLU)
上下文理解基准
每个点都是一个单独的大语言模型。当大语言模型实现随机时,就会出现通过少量提示(few-shot prompting)方法执行任务的能力性能,在模型大小达到一定规模之后,性能会显著提高到远高于随机水平。
目前大语言模型主要有三种代表性的涌现能力,分别是:
上下文学习
指令遵循
循序渐进的推理
上下文学习。GPT-3 正式引入了上下文学习能力:假设大语言模型已经提供了自然语言指令和多个任务描述,它可以通过完成输入文本的词序列来生成测试实例的预期输出,而无需额外的训练或梯度更新。
指令遵循。通过对自然语言描述(即指令)格式化的多任务数据集的混合进行微调,LLM 在微小的任务上表现良好,这些任务也以指令的形式所描述。这种能力下,指令调优使 LLM 能够在不使用显式样本的情况下通过理解任务指令来执行新任务,这可以大大提高泛化能力。
循序渐进的推理。对于小语言模型,通常很难解决涉及多个推理步骤的复杂任务,例如数学学科单词问题。同时,通过思维链推理策略,LLM 可以通过利用涉及中间推理步骤的 prompt 机制来解决此类任务得出最终答案。据推测,这种能力可能是通过代码训练获得的。