本周,有关 OpenAI 宫斗的报道占据了Ai圈版面的主导地位,吃够了奥特曼的大瓜。我们来看看Stability AI刚发布的Stable Video Diffusion,这是一种通过对现有图像进行动画处理来生成视频的 AI 模型。基于 Stability 现有的Stable Diffusion文本到图像模型,Stable Video Diffusion 是开源或商业中为数不多的视频生成模型之一。
项目地址:https://github.com/Stability-AI/generative-models

Stable Video Diffusion是第一个以Stable Diffusion模型作为基础的影片生成模型,官方在其研究论文提到,近来研究人员在原本用于2D图像生成的潜在扩散模型(Latent Diffusion Model,LDM),加入时间层,并且使用小型、高品质的影片资料集加以训练,试图将其改造成影片生成模型。
Stability AI最新研究进一步定义出训练影片LDM的三个阶段,分别是文字到图像的预训练、影片预训练,最后则是高品质影片的微调。研究人员强调,经过良好整理的预训练资料集,对于产生高品质影片非常重要,甚至还提出一套包括标题制作和过滤策略的系统性整理流程。
研究人员也展示了在高品质资料上微调基础模型的影响,并训练出能够和闭源影片生成模型相匹敌的文字转影片模型。Stable Video Diffusion还可用于图像转影片的生成任务,并且展现出强大的动作表示能力,且适用特定相机运动的LoRA模块。主要特性:文本到视频、图像到视频14 或 25 帧,576 x 1024 分辨率、多视图生成、帧插值、支持 3D 场景、通过 LoRA 控制摄像机。
Stable Video Diffusion在以下几个方面展现出显著的优势:
1.高质量输出:模型能生成接近真实的视频内容,细节丰富,色彩逼真。
2.快速响应:相较于其他模型,Stable Video Diffusion在生成视频时更加高效,减少了等待时间。
3.创意自由度:用户可以通过简单的文本描述来指导视频内容的生成,为创意提供了更大的空间。
目前Stability AI 发布两个Stable Video Diffusion版本,SVD 和 SVD-XT,分别是能够生成14帧以及25帧的模型,用户可以自订每秒帧数在3到30之间。虽然高帧数的影片看起来更顺畅,但是在目前的模型限制下,如要产生每秒达30帧数的影片,则两个模型产生的影片长度皆会少于1秒钟。
根据与Stable Video Diffusion 一起发布的白皮书,SVD 和 SVD-XT 最初在数百万个视频的数据集上进行训练,然后在数十万到大约一百万个剪辑的小得多的数据集上进行“微调”。这些视频的来源尚不清楚——该论文暗示许多视频来自公共研究数据集——因此无法判断是否有任何视频受版权保护。如果是的话,它可能会让 Stability 和 Stable Video Diffusion 的用户面临有关使用权的法律和道德挑战。
需要注意的是:目前还不是所有人都可以使用,Stable Video Diffusion 已经开放了用户候补名单注册(https://stability.ai/contact)。
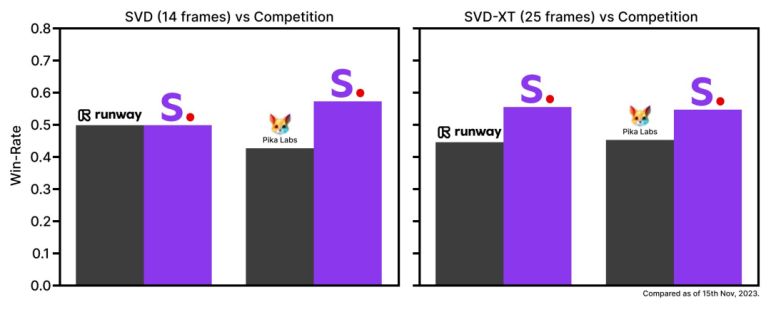
根据外部评估,官方宣称SVD甚至比runway和Pika的影片生成AI更受使用者欢迎。
尽管如此,Stable Video Diffusion 在技术上仍有一定的限制,例如无法生成静态或慢动作影像,不能由文字控制,无法清晰渲染文字,也不能正确生成人脸和人物。同时Stable Video Diffusion 的推出也引发了一些担忧,尤其是关于其可能被滥用的风险。该模型目前似乎没有内置的内容过滤器,这可能会导致其被用于制作不当内容。








![[C/C++]数据结构 循环队列](https://img-blog.csdnimg.cn/6121e6a860064c23b3f913e3555d1994.png)