数据缺失值预处理
- 创建数据集
- 展示数据集
- 缺失值处理
创建数据集
首先创建一个人工数据集,作为下文对数据缺失值预处理的案例,
import os
os.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:
f.write('NumRooms, Alley, Price\n')
f.write('NA, Pave, 127500\n')
f.write('2,NA, 106000\n')
f.write('4,NA, 178100\n')
f.write('NA,NA, 140000\n')
案例中包含数值缺失值(属性NumRooms)字符串缺失值(属性Alley);
展示数据集
通过 pandas 库 read_csv 函数读取 csv 文件,
import pandas as pd
data = pd.read_csv(data_file)
print(data)
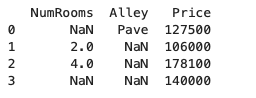
需要注意的是,不是 NaN 而是 NA 的原因,是因为上述创建数据集时 NA 前包含空格;
缺失值处理
对缺失数据的处理,典型方法包括 插值 与 删除,而对于很少的数据集,一般不采用删除的方法。以下展示插值的方法,插值包含 对于数值缺失值的插值 以及 对于字符串缺失值的插值。
首先对数值缺失值做插值处理,插入平均值,
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean(numeric_only=True))
print(inputs)
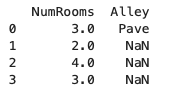
注意加入 numeric_only=True 的原因是为了区分出数值缺失值以及字符串缺失值;
对于字符串的缺失值,可以把所有缺失值做成一个类。列中所有不同的值各自作为一个类,通过 pandas 库的 get_dummies 函数,进行分类操作,
inputs = pd.get_dummies(inputs, dummy_na=True, dtype=int)
print(inputs)

如果不加入 dtype=int 属性,则一般默认为结果值为 True/False 而非 1/0;
将所有的缺失值以及所有的字符串转化为数值后,就可以转换为张量格式的 tensor 了,
import torch
X, y = torch.tensor(inputs.values), torch.tensor(outputs.values)
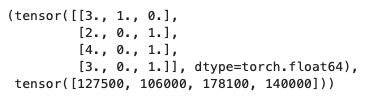
64位浮点数一般计算比较慢,所以深度学习通常会使用32位浮点数;
以上便是一个对于数据缺失值的简单处理,以及最后转化为深度学习的数据结构。