最近的一个大屏报表统计的接口查询速度很慢,耗时近一分钟左右,数据量级只是700万左右,但很慢,最后优化到4秒左右,客户还能接受,但其实还可以在优化,先这样吧,简单记录下。这次主要优化的部分数据库和Java代码部分,前端的很少。
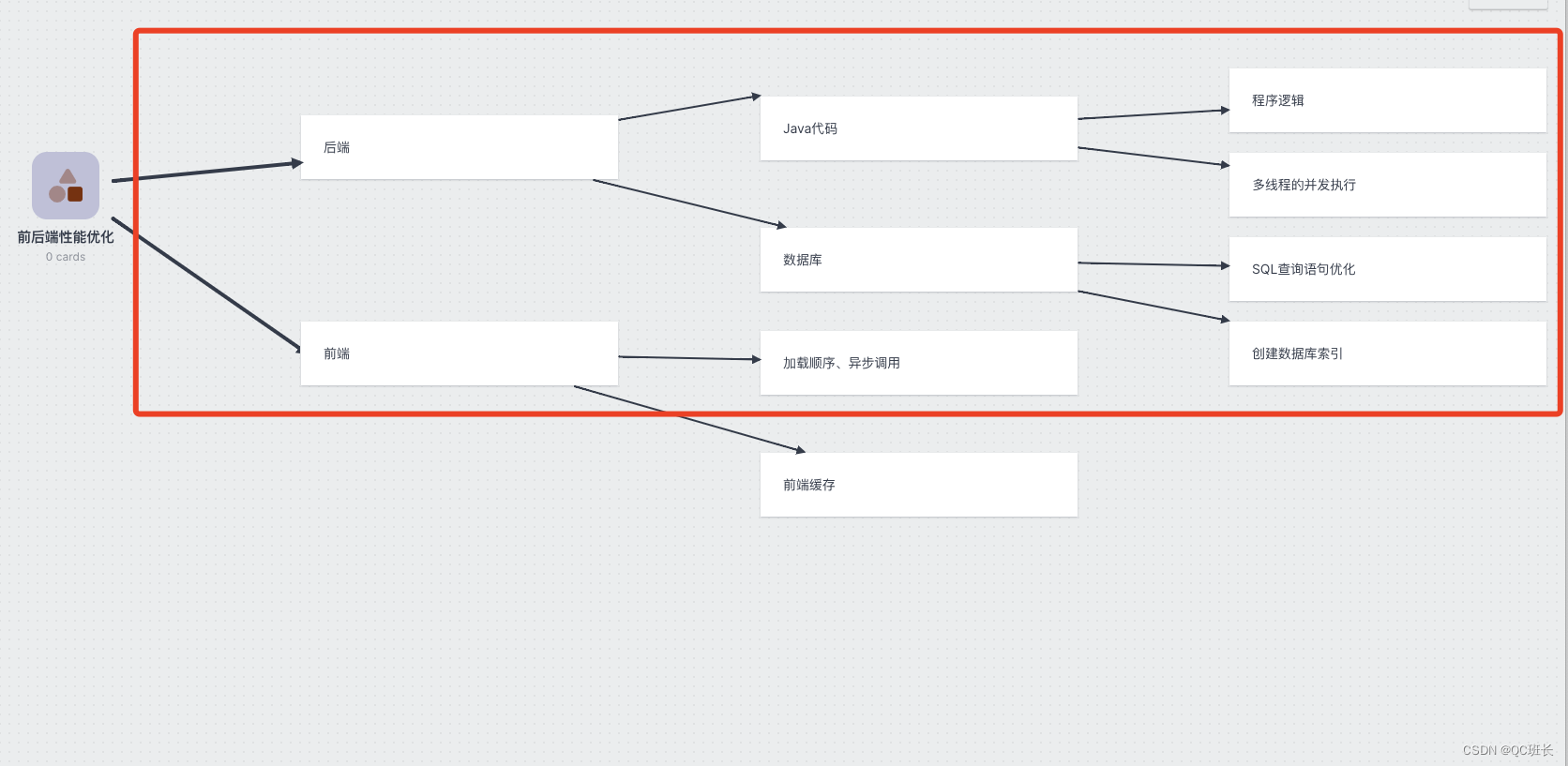
一、数据库
优化先从浏览器的接口调用看,查看到耗时近1分钟,根据接口名称查询对应的Java代码,发现代码中存在两个SQL的调用,顺着引用找到SQL语句,一看是两个都是关联查询的SQL,其中一个还是关联了5张表,复制出来后,到SQL端执行,确实很慢。
数据库优化很好用的两个命令是EXPLAIN和EXPLAIN ANALYZE命令,都是加载查询语句前面,用于分析查询计划和查询实际执行情况的。
然后是使用EXPLAIN命令查看查询计划的的信息,判断是否有需要添加或修改的索引。
使用案例:
---只需将 EXPLAIN 关键字加在查询语句开头就行
EXPLAIN SELECT COUNT(DISTINCT h.id)
FROM test h
JOIN test2 s ON h.id = s.father_id
WHERE s.first_classify = 'QC' ;执行结果示例

EXPLAIN 命令可以用来分析 SQL 查询语句的执行计划,它返回一组字段信息,提供了有关查询的重要性能指标和执行计划的详细信息。下面是 EXPLAIN 命令返回的字段信息的介绍:
id:查询的标识符,用于标识查询中的每个操作步骤。如果查询有多个操作步骤,id 可能会有多个数字,表示操作步骤的执行顺序。
select_type:操作步骤的类型,表示查询的类型。常见的类型有 SIMPLE(简单查询)、PRIMARY(主查询)、SUBQUERY(子查询)、DERIVED(派生表查询)等。
table:操作步骤涉及的表的名称。
partitions:操作步骤使用的分区。
type:访问表的方式,表示查询使用的访问方法。常见的类型有 const(常量表)、eq_ref(唯一索引查找)、ref(非唯一索引查找)、range(范围查找)、index(索引扫描)、all(全表扫描)等。一般来说,访问方法从最好到最差的顺序是:const、eq_ref、ref、range、index、all。
possible_keys:可能应用于该操作步骤的索引列表。
key:实际应用于该操作步骤的索引。
key_len:索引字段的长度。
ref:操作步骤使用的索引字段或常量与表之间的关联。
rows:操作步骤扫描的行数估计。
filtered:操作步骤的行过滤百分比。
Extra:附加信息,提供了关于操作步骤的其他信息,例如是否使用了临时表、是否使用了文件排序等。
这些字段信息可以了解查询的执行计划和性能瓶颈,从而进行性能优化和调整。通过分析这些信息,可以确定是否需要添加索引、优化查询条件、重构查询语句等来提高查询性能。
不同的数据库管理系统(如MySQL、PostgreSQL等)可能会略有不同的字段信息和含义。
关键信息是type类型,尽量少用全表扫描。possible_keys,在适合的字段上加上索引。索引的是使用是用空间换时间。
下面是使用EXPLAIN ANALYZE 命令执行查询结果分析
---只需将 EXPLAIN ANALYZE 关键字加在查询语句开头就行
EXPLAIN ANALYZE SELECT COUNT(DISTINCT h.id)
FROM test h
JOIN test2 s ON h.id = s.father_id
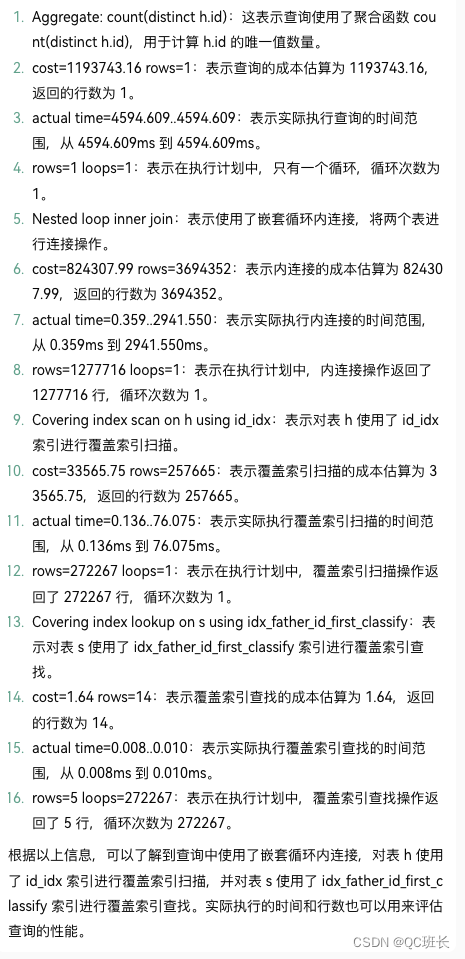
WHERE s.first_classify = 'QC' ;执行结果,如果你看不懂,可以直接把查询结果丢给ChatGPT让它给你分析,并逐行注释。

-> Aggregate: count(distinct h.id) (cost=1193743.16 rows=1) (actual time=4594.609..4594.609 rows=1 loops=1)
-> Nested loop inner join (cost=824307.99 rows=3694352) (actual time=0.359..2941.550 rows=1277716 loops=1)
-> Covering index scan on h using id_idx (cost=33565.75 rows=257665) (actual time=0.136..76.075 rows=272267 loops=1)
-> Covering index lookup on s using idx_father_id_first_classify (father_id=h.id, first_classify='F41A01') (cost=1.64 rows=14) (actual time=0.008..0.010 rows=5 loops=272267)
EXPLAIN ANALYZE 命令是一种用于分析 SQL 查询语句执行计划和实际执行时间的命令。它返回的字段信息包括 EXPLAIN 命令的字段信息,同时还包括以下字段:
QUERY PLAN:查询执行计划的详细信息,包括操作步骤、访问方法、索引使用等。
Planning Time:查询规划阶段的时间,表示生成查询执行计划所花费的时间。
Execution Time:查询执行阶段的时间,表示实际执行查询所花费的时间。
Actual Rows:实际扫描的行数,表示查询实际扫描的行数。
Actual Loops:实际循环次数,表示查询实际执行的循环次数。
Actual Startup Time:实际开始执行查询的时间。
Actual Total Time:实际执行查询的总时间。
Actual Time:实际执行查询的时间,以毫秒为单位。
EXPLAIN ANALYZE 命令返回的字段信息可以帮助您更全面地了解查询的执行计划和实际执行情况。通过分析这些信息,可以确定查询的性能瓶颈、优化查询计划、减少查询执行时间等。同时,还可以比较不同查询语句的执行效果,选择性能最佳的查询方式。
最后通过ANALYZE TABLE 命令来优化下对应的表,
---只需将 EXPLAIN TABLE 关键字加在表名开头就行
ANALYZE TABLE test;ANALYZE TABLE 命令是用于分析和收集数据库表统计信息的命令。它的主要作用是帮助优化查询性能和执行计划。
ANALYZE TABLE 命令会完成以下任务:
优化查询计划:通过分析表的统计信息,数据库管理系统可以更准确地估计查询的成本和选择最优的执行计划。
选择合适的索引:通过分析表的索引长度和数据分布情况,可以判断是否需要创建或删除索引,以及选择合适的索引类型和列顺序。
优化存储空间:通过分析表的行数和平均行长度,可以估计表的总大小,并根据需要进行存储空间的调整。
检测表的完整性:通过分析更新时间和自增值,可以检测表的数据是否完整,并及时发现可能存在的问题。
数据库的查询,通过加索引大部分都能解决,在这个过程中善于用ChatGPT来帮助解决很重要。
二、Java程序代码
下面是程序代码的部分,原本的程序代码并不是我写的,打开看了之后,有两个执行查询的代码段是可以同时执行的,所以改成并发执行。
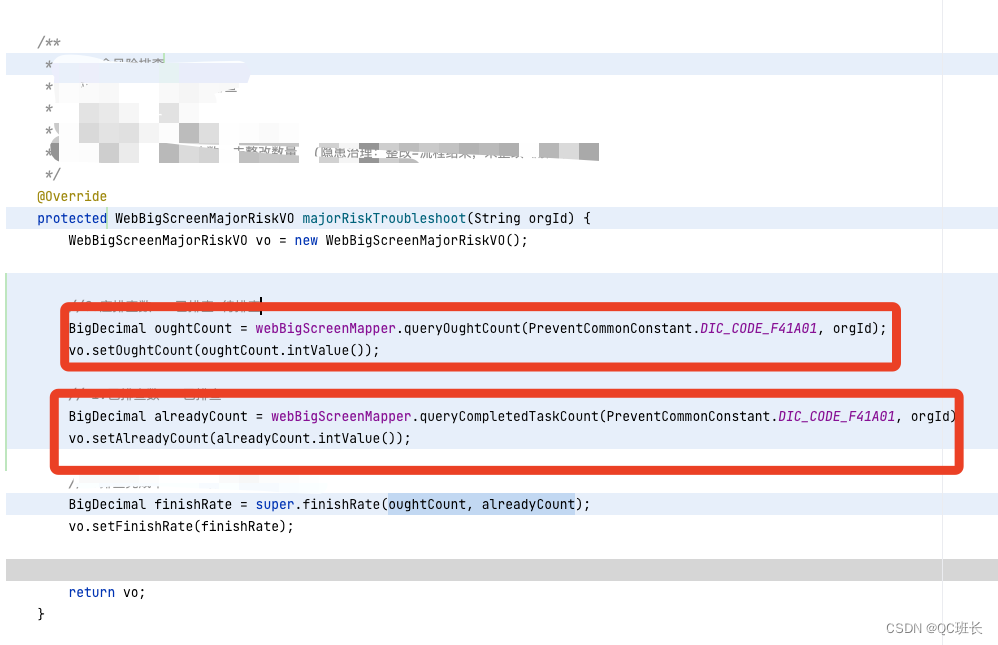
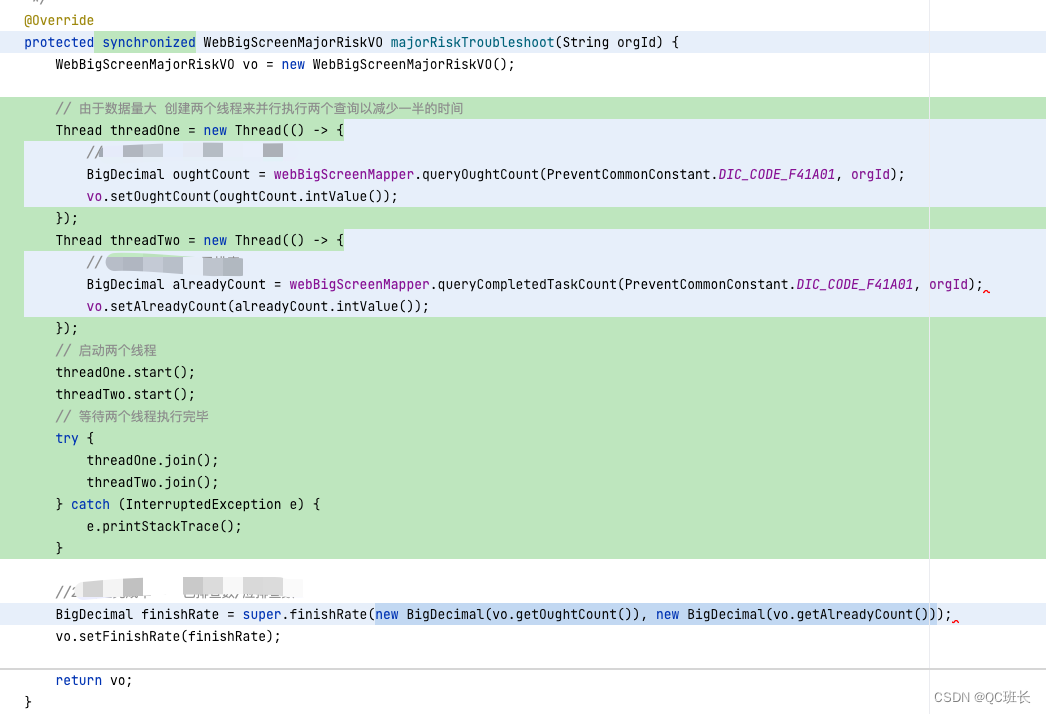 程序上改后,接口时间就减少一半了,接口时间来到了4.5秒左右,但其实还是慢。
程序上改后,接口时间就减少一半了,接口时间来到了4.5秒左右,但其实还是慢。
三、前端React代码
在改改前端,前端的话,可以把这个接口的查询放在最开始执行,以减少用户使用的等待延迟感受。前段端代码就省略了。下次有机会在写吧。
四、总结拓展
性能优化某种意义上是对资源取舍利用的问题。通常是就是空间和时间的互换与取舍。
以下是我收集到的常见的6种互换手段。
1、索引
索引的原理是拿额外的存储空间换取查询时间,增加了写入数据的开销,但使读取数据的时间复杂度一般从O(n)降低到O(logn)甚至O(1)。
在数据集比较大时,不用索引就像从一本没有目录而且内容乱序的新华字典查一个字,得一页一页全翻一遍才能找到;用索引之后,就像用拼音先在目录中先找到要查到字在哪一页,直接翻过去就行了。书籍的目录是典型的树状结构。
2、缓存
缓存优化性能的原理和索引一样,是拿额外的存储空间换取查询时间。Phil Karlton 曾说过:计算机科学中只有两件困难的事情:缓存失效和命名规范。缓存的使用除了带来额外的复杂度以外,还面临如何处理缓存失效的问题。
3、压缩
压缩的原理消耗计算的时间,换一种更紧凑的编码方式来表示数据。对数据的压缩虽然消耗了时间来换取更小的空间存储,但更小的存储空间会在另一个维度带来更大的时间收益。
能减少的就减少:
-
JS打包过程“摇树”,去掉没有使用的文件、函数、变量;
-
开启HTTP/2和高版本的TLS,减少了Round Trip,节省了TCP连接,自带大量性能优化;
-
减少不必要的信息,比如Cookie的数量,去掉不必要的HTTP请求头;
-
更新采用增量更新,比如HTTP的PATCH,只传输变化的属性而不是整条数据;
-
缩短单行日志的长度、缩短URL、在具有可读性情况下用短的属性名等等;
-
使用位图和位操作,用风骚的位操作最小化存取的数据。典型的例子有:用Redis的位图来记录统计海量用户登录状态;布隆过滤器用位图排除不可能存在的数据;大量开关型的设置的存储等等。
能删除的就删除:
-
删掉不用的数据;
-
删掉不用的索引;
-
删掉不该打的日志;
-
删掉不必要的通信代码,不去发不必要的HTTP、RPC请求或调用,轮询改发布订阅;
-
终极方案:砍掉整个功能。
4、预取
预取通常搭配缓存一起用,其原理是在缓存空间换时间基础上更进一步,再加上一次“时间换时间”,也就是:用事先预取的耗时,换取第一次加载的时间。
当可以猜测出以后的某个时间很有可能会用到某种数据时,把数据预先取到需要用的地方,能大幅度提升用户体验或服务端响应速度。
5、削峰填谷
削峰填谷的原理也是“时间换时间”,谷时换峰时。
削峰填谷与预取是反过来的:预取是事先花时间做,削峰填谷是事后花时间做。就像三峡大坝可以抗住短期巨量洪水,事后雨停再慢慢开闸防水。软件世界的“削峰填谷”是类似的,只是不是用三峡大坝实现,而是用消息队列、异步化等方式。
6、批量处理
批量处理同样可以看成“时间换时间”,其原理是减少了重复的事情,是一种对执行流程的压缩。以个别批量操作更长的耗时为代价,在整体上换取了更多的时间。
-
前端把所有文件打包成单个JS,大部分时候并不是最优解。Webpack提供了很多分块的机制,CSS和JS分开、JS按业务分更小的Chunk结合懒加载、一些体积大又不用在首屏用的第三方库设置external或单独分块,可能整体性能更高。不一定要一批搞定所有事情,分几个小批次反而用户体验的性能更好。
-
Redis的MGET、MSET来批量存取数据时,每批大小不宜过大,因为Redis主线程只有一个,如果一批太大执行期间会让其他命令无法响应。经验上一批50-100个Key性能是不错的,但最好在真实环境下用真实大小的数据量化度量一下,做Benchmark测试才能确定一批大小的最优值。
-
MySQL、Oracle这类RDBMS,最优的批量Insert的大小也视数据行的特性而定。我之前在2U8G的Oracle上用一些普遍的业务数据做过测试,批量插入时每批5000-10000条数据性能是最高的,每批过大会导致DML的解析耗时过长,甚至单个SQL语句体积超限,单批太多反而得不偿失。
-
消息队列的发布订阅,每批的消息长度尽量控制在1MB以内,有些云服务商提供的消息队列限制了最大长度,那这个长度可能就是性能拐点,比如AWS的SQS服务对单条消息的限制是256KB。
还有与提升并行能力有点关的4中方式:
- 榨干计算资源
- 水平扩容
- 分片
- 无锁
参考文献
性能优化的 10 个技巧!(文末送书)