上期介绍了大语言模型的定义和发展历史,本期将分析基于亚马逊云科技的大语言模型相关研究方向,以及大语言模型的训练和构建优化。
大语言模型研究方向分析
Amazon Titan
2023 年 4 月,亚马逊云科技宣布推出 Amazon Titan 大语言模型。根据其以下官方网站和博客的信息(如下图所示):一些亚马逊云科技的客户已经预览了亚马逊全新的 Titan 基础模型。目前发布的 Amazon Titan 大语言模型主要包括两个基础模型:
针对总结、文本生成、分类、开放式问答和信息提取等任务的生成式大语言模型;
文本嵌入(embeddings)大语言模型,能够将文本输入(字词、短语甚至是大篇幅文章)翻译成包含语义的数字表达(jiembeddings 嵌入编码)。

虽然这种大语言模型不生成文本,但对个性化推荐和搜索等应用程序却大有裨益,因为相对于匹配文字,对比编码可以帮助模型反馈更相关、更符合情境的结果。实际上,Amazon.com 的产品搜索能力就是采用了类似的文本嵌入模型,能够帮助客户更好地查找所需的商品。为了持续推动使用负责任AI的最佳实践,Titan 基础模型可以识别和删除客户提交给定制大语言模型的数据中的有害内容,拒绝用户输入不当内容,过滤模型中包含不当内容的输出结果,如仇恨言论、脏话和语言暴力。
Alpaca: LLM Training LLM
2023 年 3 月 Meta 的 LLaMA 大语言模型发布,该大语言模型对标 GPT-3。已经有许多项目建立在 LLaMA 大语言模型的基础之上,其中一个著名的项目是 Stanford 的羊驼(Alpaca)大语言模型。Alpaca 基于 LLaMA 大语言模型,是有 70 亿参数指令微调的语言 Transformer。Alpaca 没有使用人工反馈的强化学习(RLHF),而是使用监督学习的方法,其使用了 52k 的指令-输出对(instruction-output pairs)。
LLaMA 大语言模型:

研究人员没有使用人类生成的指令-输出对,而是通过查询基于 GPT-3 的 text-davinci-003 模型来检索数据。因此,Alpaca 本质上使用的是一种弱监督(weakly supervised)或以知识蒸馏(knowledge-distillation-flavored)为主的微调。
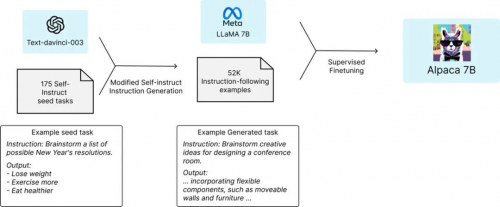
这里值得关注的是羊驼(Alpaca)大语言模型的训练数据,是通过查询 GPT-3 大语言模型获得的。通俗地来说,这是“用 LLM 来训练 LLM”,或者称之为“用 AI 来训练 AI”。我觉得大多数人可能低估了这件事情对人类社会影响的意义,我觉得其意义非凡。这意味着:AI 之间的相互学习成长这件事,已经开始了。很多年后,当我们回望 AI 世代的演进史,这件事也许会是一个重要的时间节点。
PaLM-E: Multimodality
在 2023 年 3 月,PaLM-E 大语言模型发布,展示了在大语言模型和多模态数据模式(multimodality)融合的一些最新进展。这是大语言模型的另一个重要趋势:通过视觉、多模态和多任务训练来扩展能力。

如以上论文中的图示,PaLM-E 大语言模型是一种用于具体推理任务、视觉语言任务和语言任务的单一通用多模态大语言模型。PaLM-E 大语言模型对多模态句子进行操作,即一系列标记,其中来自任意模式(例如图像、神经三维表示或状态,绿色和蓝色)的输入与文本标记(橙色)一起插入,作为 LLM 的输入,经过端到端训练。

该论文展示了 PaLM-E 在三个不同的机器人领域做迁移学习的测试结果对比图。使用 PaLM-E 、ViT 预训练、机器人和视觉语言的混合数据组合,与仅对相应的域内数据进行训练相比,有显著的性能提升。
值得注意的是,PaLM-E 继续被训练为一个完全基于解码器的 LLM,它根据给定的前缀或提示自回归生成文本补全。那么,它们如何启用状态表征或者图像的输入呢?他们对网络进行了预训练以将其编码为 embeddings。对于图像,他们使用 4B 和 22B 参数的视觉 Transformer (ViT) 来生成嵌入向量;然后对这些嵌入向量进行线性投影,以匹配单词令牌嵌入的嵌入维度。
在训练过程中,为了形成多模态的句子,他们首先使用特殊标记 Tokens,例如:<img1>、<img2> 等,然后将其与嵌入的图像交换(类似于通过嵌入层嵌入单词标记的方式)。

一些第三方领域学者对其论文和展示的性能提升也做了分析,如上图所示。使用 PaLM-E 、ViT 预训练、机器人和视觉语言的混合数据组合进行联合训练,与针对单个任务的训练模型相比,可以实现两倍以上的性能提升。
大语言模型的训练和构建优化
训练大语言模型的挑战
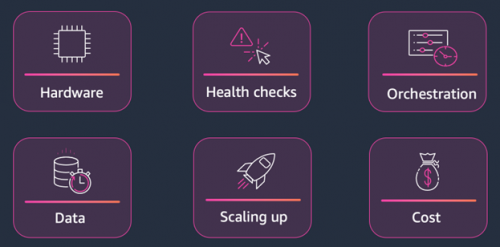
训练大语言模型涉及许多挑战。这些挑战概括来说,大致来自于六个方面,如下图示:
硬件(Hardware)
健康检查(Health Checks)
编排(Orchestration)
数据(Data)
规模扩展(Scaling up)
成本考虑(Cost)
首先是硬件。你想使用最新的硬件。最新的硬件通常可以让你在各种基准测试中获得更好的性能,因此,如果这些大语言模型需要数周或数月的时间来训练,而你没有利用最新硬件的性能优势,那么你将无法训练大语言模型以获得最适合你的用例的结果。
第二个是健康检查。您需要确保硬件运行良好,以便最大限度地减少大语言模型训练期间的干扰。
我们还需要考虑编排,启动集群,关闭集群,确保网络和安全配置运行良好,机器学习团队在运行各种工作负载时不会相互干扰。
我们需要考虑的其他事情是大数据集。存储、处理和加载它们以进行机器学习训练并不是一件容易的事,并且可能需要大量的开发工作才能高效完成。
我们扩大基础设施的规模并设计算法以绕过基础设施的局限性是另一个挑战。我们今天谈论的大语言模型通常不适用于单个 GPU,因此你必须考虑如何将该大语言模型拆分到 GPU 上。
最后,我们必须考虑成本。这些大语言模型的训练成本可能高达数十万甚至数百万美元。所以,你想很好地利用机器学习团队的时间。与其让他们在基础架构上工作,他们可以专注于尝试新的大语言模型创意,这样您的企业就可以利用该大语言模型取得最佳结果。
大语言模型的构建优化
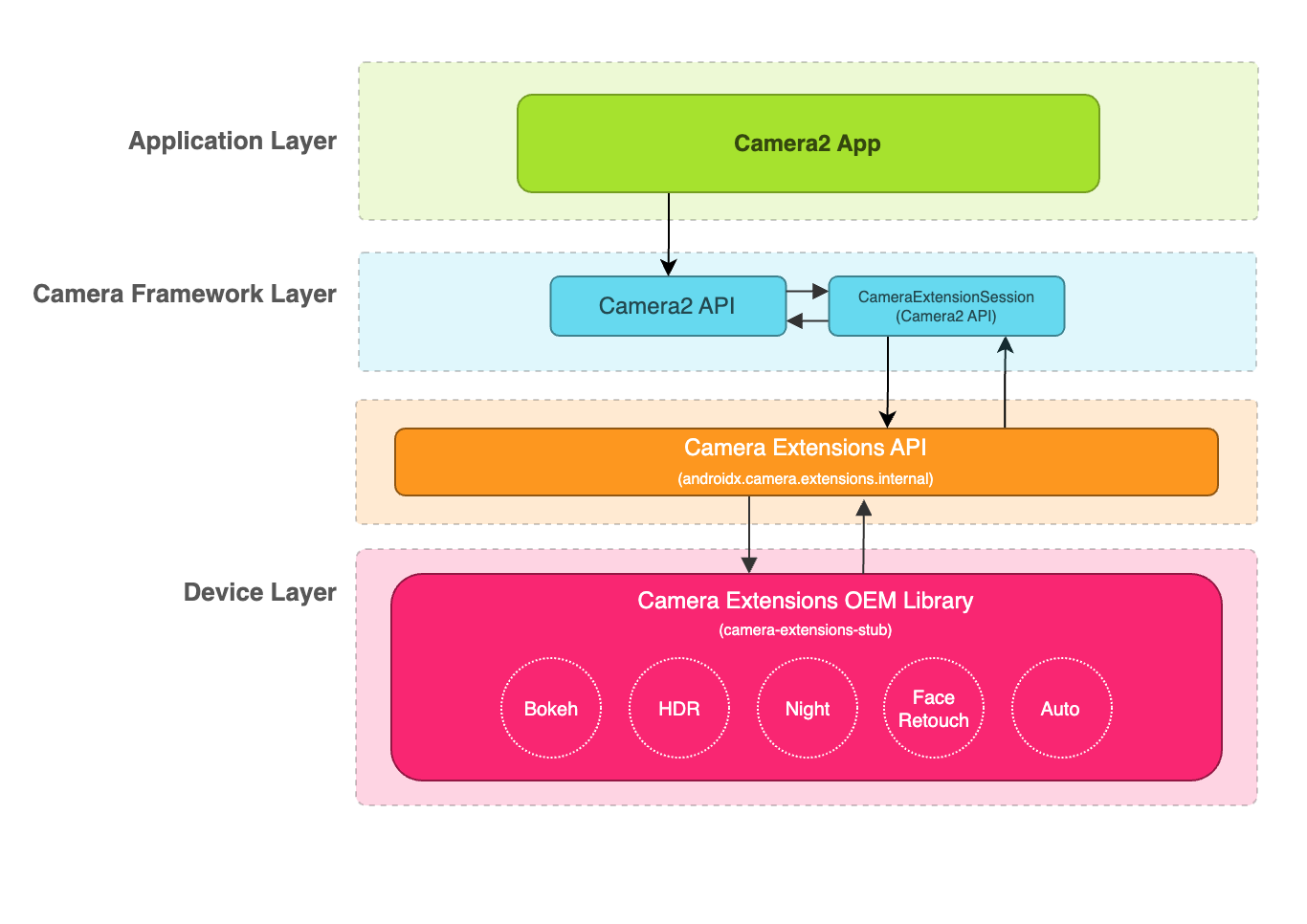
幸运的是,Amazon SageMaker 可以帮助你应对所有这些挑战,从而加速大语言模型的训练。现在,Amazon SageMaker 可帮助您使用托管基础设施、工具和工作流程为任何用例构建、训练和部署机器学习模型。如下图所示。
下图中黄色的部分,例如:Amazon SageMaker 分布式训练库、Amazon SageMaker 训练编译优化等,我们还会在下一篇的动手实验部分,用完整的代码来演绎实现,让你有更身临其境的感受。

在下层,我们有基础设施,Amazon SageMaker 可让你访问最新的硬件,包括 GPU 和 Trainium,以及实例之间的快速网络互连,这对于分发训练至关重要。
在中间层,有托管基础设施和工具的能力。
Amazon SageMaker 会为你处理大规模集群编排,它加速了集群,最后它会向下旋转。它有助于完成所有这些安全和网络配置,因此你可以轻松保护客户数据和 IP 的安全。
在训练工作开始时还会进行健康检查,以确保硬件有效运行,减少对训练工作的干扰。编排还意味着你只需为所用的计算资源付费。你只需要在集群启动时付费,为你训练大语言模型,这样你就不必全天候为所有昂贵的硬件付费。
还有用于分析、调试和监控实验的工具,以及使用各种策略进行超参数优化的工具,以确保获得尽可能好的大语言模型。
在顶层,有针对云端进行了优化的框架和库,例如在 Amazon SageMaker 上非常易于使用的 PyTorch、TensorFlow 和 Hugging Face,以及可帮助你处理超大型数据集或超大语言模型的 Amazon SageMaker 分布式训练库。
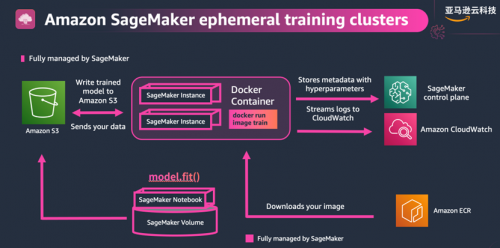
我已经谈了很多使用 Amazon SageMaker 进行训练的能力和好处,让我们来谈谈它是如何运作的。训练大语言模型,我们需要一些计算资源,然后在某些数据集上运行我们编写的训练代码。Amazon SageMaker 做到这一点的方法是:通过启动短暂的训练集群来完成任务。
当提交训练作业时,Amazon SageMaker 将根据你选择的集群配置启动集群。它将从 ECR 加载训练代码,从 S3 加载数据,然后开始训练。训练过程中,它会将日志和指标输出到 CloudWatch,将大语言模型检查点(checkpoint)同步到 S3,并在任务结束时关闭集群。如果你编写的代码考虑了具有弹性,编写成能够从检查点自动恢复,则你的训练作业将无需手动干预即可自动重启。
以下是用于开始训练作业的核心代码,即 estimator API:
from sagemaker.pytorch import PyTorch
estimator = PyTorch(entry_point = ‘./cifar10.py’,
role = role,
framework_version = ‘1.13’,
py_version = ‘py38’,
instance_count = 1,
instance_type = ‘ml.g5.xlarge’,
hyperparameters = {‘epochs’: 50, ‘batch_size’: 32},
metric_definitions = [{‘Name’: ‘train:loss’, ‘Regex’: ‘loss: (.*)’}]
estimator.fit(“s3://bucket/path/to/training/data”)
这里选择了 PyTorch 估算器,并定义了入口点的函数文件:cifar10.py。这与我们在自己的本地电脑上运行用于训练大语言模型的脚本非常相似,我们称之为脚本模式。使用 Amazon SageMaker 训练作业的方法有很多,灵活性更强,你可以提供自己的 docker 容器或一些内置算法。
然后定义想要使用的框架和 Python 版本,以及训练作业的实例类型、实例数量和超参数。你现在可以随时轻松更改这些内容,启动其他训练任务来尝试不同的实例类型,看看哪种硬件最适合你的用例。
接下来将给出指标定义。这将告诉 Amazon SageMaker 如何解析从脚本中输出的日志,Amazon SageMaker 会将这些指标发送到 CloudWatch,供你稍后查看。
最后调用 estimator.fit(),其中包含训练数据的路径。