目录
- 学习用具
- 张量的定义和运算
- Variable(变量)
- Dataset数据集
之前一直是拿一个个项目来学pytorch,感觉不是很系统,借着假期的机会系统学一下。预计先把入门的知识一周学完吧。
学习用具
《深度学习入门之Pytorch》廖星宇
在Z-library上能搜到。
conda命令一定要会
英伟达官方驱动


先运行下以下代码:
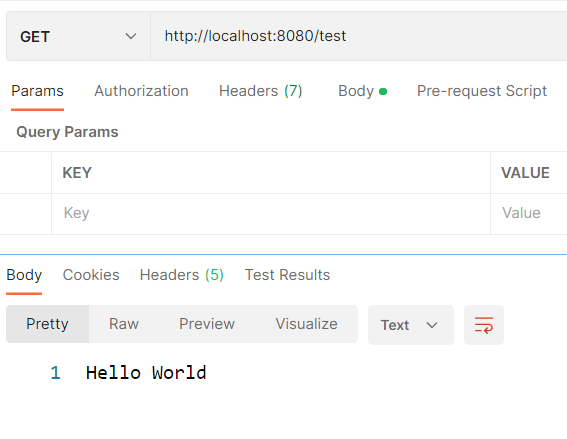
import torch
print(torch.cuda.is_available())
我的返回是False
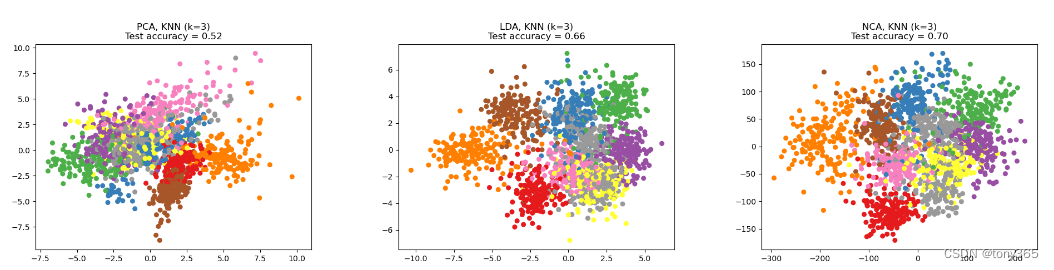
于是我开始了求索之路。打开命令行,输入 nvidia-smi,查看自己的 Driver Version
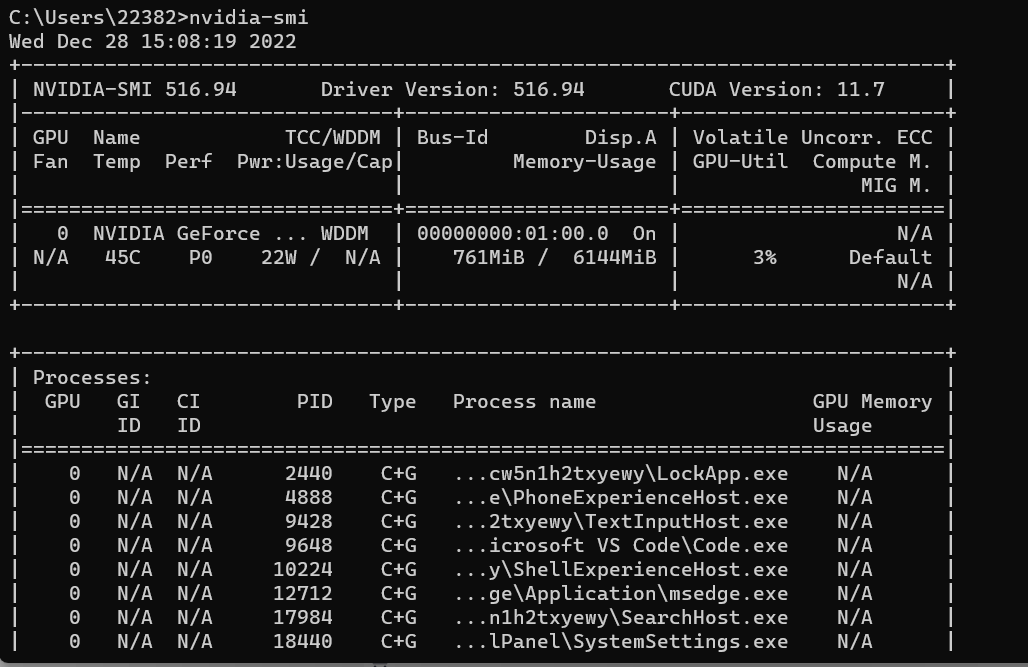
Driver Version: 516.94
CUDA Version: 11.7
然后我又进行了一遍:

????什么鬼
最后应该是CUDA版本和pytorch不匹配吧。算了,能用就行,回头再说……
编程熟练才是王道。
张量的定义和运算
import torch
a=torch.Tensor([[2,3],[4,8],[7,9]]) # 三行两列的矩阵
print('a is {}'.format(a))
print('a size is {}'.format(a.size()))
我费了好大劲,不知道为啥我的VScode运行不了pytorch,老是显示有错误。我放到jupyter notebook上之后就好了……
运行结果:
a is tensor([[2., 3.],
[4., 8.],
[7., 9.]])
a size is torch.Size([3, 2])
上面的代码内容牵扯到的语法教程
torch.rand_like 就是和第一个参数的shape是一样的。也是随机数。
接下来就是把书中的例子都练一遍。
import torch
b=torch.LongTensor([[2,3],[4,8],[7,9]])
print(b)
print()
c = torch.zeros((3, 2))
print('zero tensor: {}'.format(c))
运行结果:
tensor([[2, 3],
[4, 8],
[7, 9]])
zero tensor: tensor([[0., 0.],
[0., 0.],
[0., 0.]])
Variable(变量)


from torch.autograd import Variable # torch 中 Variable 模块
# Create Variable
x = Variable(torch.Tensor([1]), requires_grad=True) #True表示对这个变量求梯度,本来默认的False
w = Variable(torch.Tensor([2]), requires_grad=True)
b = Variable(torch.Tensor([3]), requires_grad=True)
# Build a computational graph. 创建一个计算图
y=w*x+b # y=2*x+3
# Compute gradients 下面这一行就是自动求导
y.backward() # same as y .backward(torch.FloatTensor([1]))
# Print out the gradients.
print(x.grad)# x.grad = 2
print(w.grad)# w.grad = 1
print(b.grad)# b.grad = 1
又TM报错了
NameError: name ‘Variable’ is not defined
我¥……¥(&%…………*…………&¥%
吆西,得导入from torch.autograd import Variable # torch 中 Variable 模块
运行成功!
tensor([2.])
tensor([1.])
tensor([1.])
不过,对于标量求导,里面的参数就可以不写了,自动求导不需要你再去明确地写明哪个函数对哪个函数求导,直接通过这行代码就能对所有的需要梯度的变量进行求导,得到它们的梯度,然后
通过x. grad可以得到x的梯度。注意,这里没有括号。
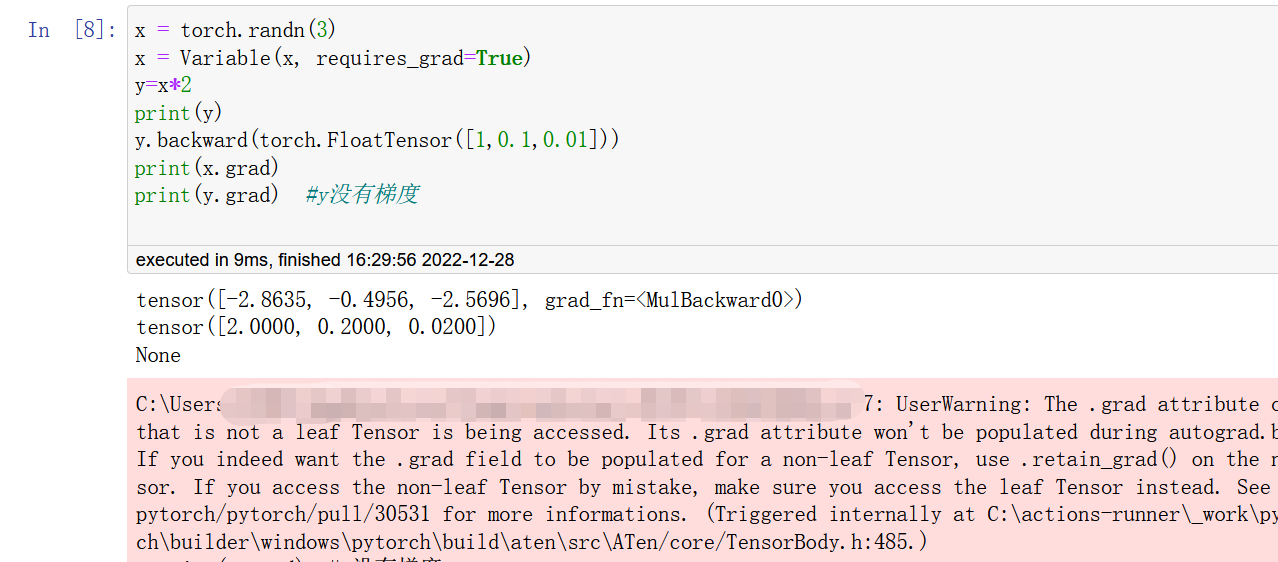
做矩阵求导
x = torch.randn(3)
x = Variable(x, requires_grad=True)
y=x*2
print(y)
y.backward(torch.FloatTensor([1,0.1,0.01]))
print(x.grad)
# print(y.grad) y没有梯度
运行结果:
tensor([-0.8490, -1.3609, 2.9927], grad_fn=<MulBackward0>)
tensor([2.0000, 0.2000, 0.0200])

如果取消上段代码的注释,会有以下效果。
Dataset数据集
官方API文档:https://pytorch.org/vision/stable/datasets.html
torch.utils.data.Dataset是代表这一数据的抽象类,你可以自己定义你的数
据类继承和重写这个抽象类,非常简单,只需要定义_len_ 和_getitem_ 这两个函数(长下面这样):
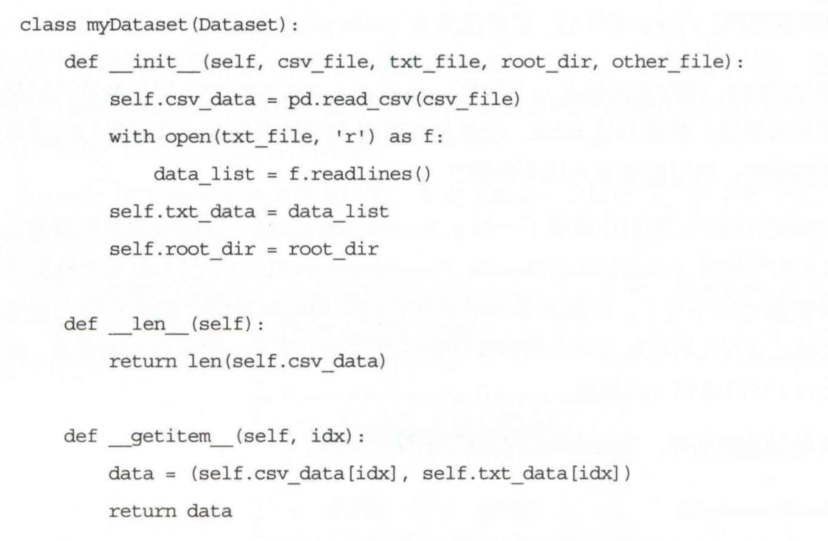
通过上面的方式,可以定义我们需要的数据类,可以通过迭代的方式来取得每一个数据,但是这样很难实现取batch, shuffle 或者是多线程去读取数据,所以PyTorch中提供了一个简单的办法来做这个事情,通过torch. utils. data. DataLoader来定义一个新的迭代器,如下:(以后基本都用这个,上面的那个有些项目中也用,看懂就行)
dataiter = DataLoader (myDataset, batch size=32,shuffle=True,collate_fn=default_collate)
collate_fn表示如何获取样本。
但是!!!我看的书中对于这个类的操作逻辑并没有讲明白,反而给身为读者的我一种只要在这两种方法里选择一种的方法就行,但是不是的。看下面的文章你就明白了。
两步走
具体的操作逻辑
ImageFolder

其中的root需要是根目录,在这个目录下有几个文件夹,每个文件夹表示一个类别: transform 和target_transform 是图片增强;
loader 是图片读取的办法,因为我们读取的是图片的名字,然后通过loader将图片转换成我们需要的图片类型进人神经网络。
加载数据集的基础运用部分到此就算结束了。