【Linux系统编程二十】:命名管道/共享内存
- 一.命名管道
- 1.创建管道
- 2.打开管道
- 3.进行通信(server/client)
- 二.共享内存
- 1.实现原理
- 2.申请内存
- 3.挂接
- 4.通信
- 5.去关联
- 6.释放共享内存
- 7.特性:
一.命名管道
上一篇介绍的一个管道是没有名字的
因为你打开那个文件的时候,并没有告诉我们文件名。直接以读的方式方式打开复制子进程,各自拿一个读写单就可以通信了。
好,这有问题吗?没有问题
正是因为它没有名字,那么所以他必须得让我们对应的父子进程继承这才可以看到同一份资源。它采用的是让父子继承的方案看到的。
它只能是具有血缘关系的进程之间进行进程间通信。
那如果没有血缘关系的进程之间想要通信该怎么办呢?这就可以使用我们的命名管道!
如果两个不同的进程。打开同一个文件的时候。在内核中。操作系统会打开几个文件呢?
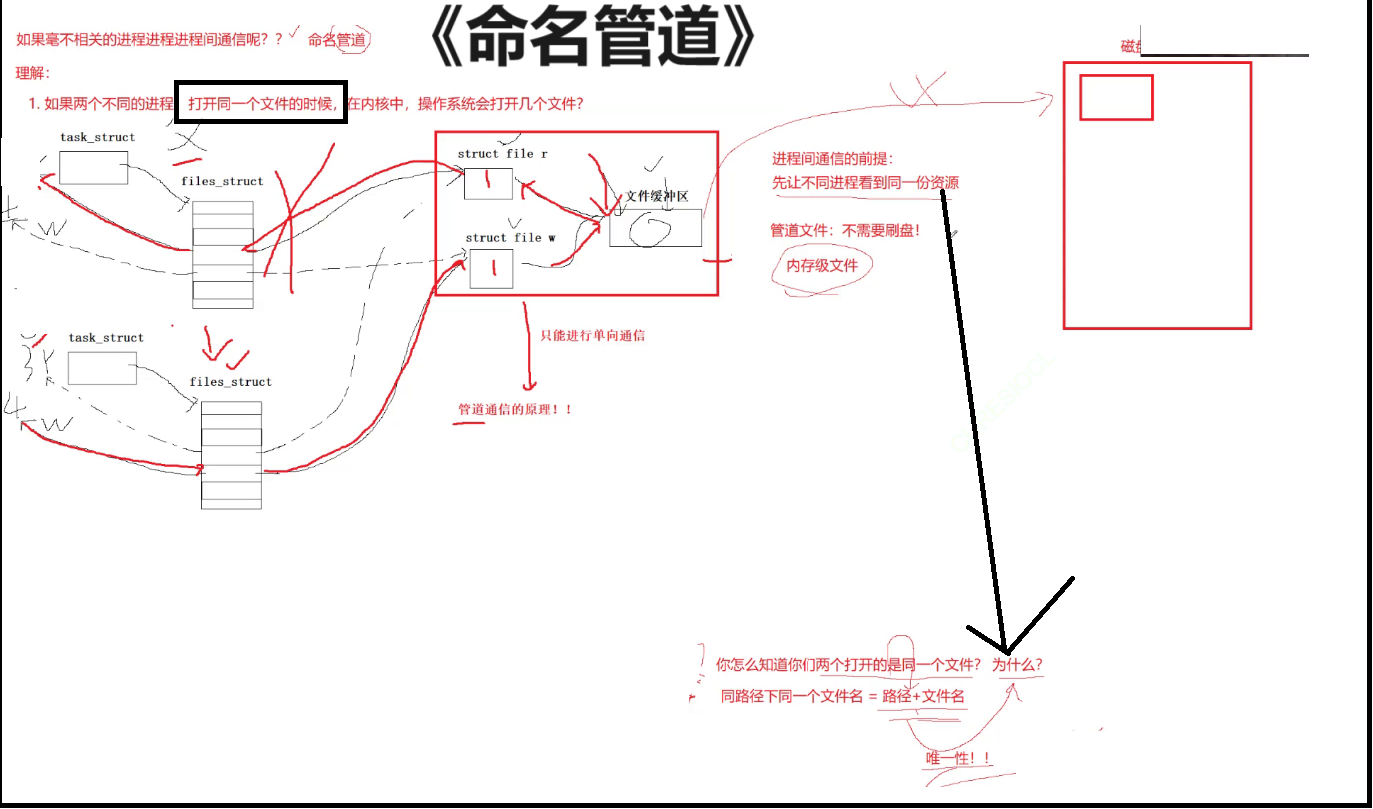
不同的进程打开同一个文件时,在操作系统层面上它还是这种结构。
所以呢两个进程可能有不同的读写文件对象,但是它文件缓冲区还是同一个。还记得进程间通信有个前提吗?这个前提就是应该让我们的不同进程看到。同一份我们对应的资源。
所以这个概念呢,其实和我们匿名管道的原理是一模一样的。
两个不同的进程打开同一个文件时。就要想到这样的问题:
问题1:你怎么知道你们两个打开的是同一个文件?
我们两个只要看到同一个文件名,那么此时这两个进程就可以打开同一个文件了还有个隐含条件叫做同路径下的我们对应的文件。路径加文件名,我们就能保证打开的是同一个文件。
问题2:我们为什么要打开同一个文件啊?
进程通信必须保证在同一个文件里通信啊,不然怎么通信呢,进程间通信的前提是先让不同的进程看到同一份资源。打开同一个文件不就是看到同一份资源了吗。
这种管道文件它是通过使用路径加文件名的方案,让不同的进程看到同一份文件资源,进而实现不同进程之间通信的。所以它有文件,有路径名,有文件名,所以这种通信我们叫做命名管道。
命名管道唯一和我们匿名管道区别的地方是在哪里呢?
就是我们这里所谓的匿名通信的呢,就是可以用来进行我们不相关进程之间进行进行通信的那它是怎么做到不相关进程之间通信的啊,前提条件是得先让不同进程看到同一份资源。它怎么看到的?
是通过文件名叫路径的方式,让我们看到同一份资源的。
1.创建管道
你要用管道文件进行通信,前提条件你是不是得先把对应要通信的资源,你先准备好,资源你都准备不好,那你玩什么呢?对不对?资源都没有准备好,你就不要玩了。
首先得创建一个管道文件创建,怎么创建呢?
mkfifo(pathname,mode)
第一个参数我们要创建这个管道文件
第二个参数呢就是我们打开这个管道文件对应的一个那么权限。
unlink(path)
unlink是用来删除管道文件的。
我们现在已经能创建一个管道了。下面要做的当然就是不同进程直接通信了。
通信之前你们两个进程决定一下一个从管道里读,一个从管道里写。命名管道也是管道,只支持单向通信的。未来我们俩要通信的话,是不是正常的进行我们管道的读写就可以了。
2.打开管道
现在我们剩下的就是打开管道文件,剩下读写。
那么这打开管道文件怎么打开呢?,linux下一切皆文件,它在设计的时候已经把接口设计成了通用接口。
同学们所以你要打开这个管道文件,怎么打开呢按照文件操作的一系列即可open.打开呀然后呢read write close,这样去读写就可以了,就这么简单。
后我们通信时,客户端和服务双方他们都直接那么叫做通过打开文件的方式那么来进行通信就可以了。
3.进行通信(server/client)
服务端server:
#include "comm.hpp"
// 服务端创建信道,客户端只需要发送信息即可
// 使用命名管道,就像使用文件一样要
using namespace std;
// 管理管道文件
int main()
{
int n = mkfifo(FIFO_FILE, MODE);
if (n == -1) // 创建失败
{
perror("mkfifo");
exit(FIFO_CREATE_ERR); // 创建失败就退出
}
// 使用管道文件--如何使用呢?就跟文件操作一样使用,打开,写入关闭
int fd = open(FIFO_FILE, O_RDONLY);
if (fd < 0)
{
perror("open");
exit(FIFO_OPEN_ERR);
}
while (1)
{
// 读取到一个数组里
char buffer[1024] = {0};
int x = read(fd, buffer, sizeof(buffer));
if (x > 0) // 说明读取成功
{
buffer[x] = 0;
//读取完后,就将客户端发送
cout << "client say@ " << buffer << endl;
}
else if (x == 0) // 说明读取结束,读到末尾
{
break;
}
else
break;
}
close(fd);
// 最后不用了,就删除管道文件
int m = unlink(FIFO_FILE);
if (m == -1)
{
perror("unlink");
exit(FIFO_DELETE_ERR);
}
return 0;
}
客户端client:
#include "comm.hpp"
using namespace std;
//客户端这里只需要写入信息
int main()
{
int fd=open(FIFO_FILE,O_WRONLY);
if(fd<0)
{
perror("open");
exit(FIFO_OPEN_ERR);
}
//打开成功后就可以进行通信
cout<<"client opne file done"<<endl;
string line;
while(1)
{
cout<<"Please Enter@: "<<endl;
getline(cin,line);
write(fd,line.c_str(),line.size());
}
close(fd);
return 0;
}
共同访问区:
#pragma once
#include <iostream>
#include <cerrno>
#include <sys/types.h>
#include <sys/stat.h>
#include <unistd.h>
#include <fcntl.h>
#include <cstring>
#include <cstdlib>
#define FIFO_FILE "./myfifo" // 在当前目录下创建命名管道myfifo
#define MODE 0664
enum
{
FIFO_CREATE_ERR = 1,
FIFO_OPEN_ERR,
FIFO_DELETE_ERR
};
//可以这样封装创建管道和销毁管道,定义一个Init对象即可。
class Init
{
Init()
{
int n = mkfifo(FIFO_FILE, MODE);
if (n == -1) // 创建失败
{
perror("mkfifo");
exit(FIFO_CREATE_ERR); // 创建失败就退出
}
}
~Init()
{
// 最后不用了,就删除管道文件
int m = unlink(FIFO_FILE);
if (m == -1)
{
perror("unlink");
exit(FIFO_DELETE_ERR);
}
}
};
以上就是基于文件部分的通信,包括匿名管道和命名管道。
二.共享内存
1.实现原理
在介绍之前再强调一遍:通信的前提:让不同的进程先看到同一份资源。
sister v的共享内存呢,它是一个那么单独设计的内核模块,用来进行进程间通信的。
让进程看到同一份资源,什么资源不是资源,谁提供资源都行。
上面讲的那些都叫做基于文件的。
现在讲的这个共享内存,它是专门由操作系统去给我们提供的一种通信方案。
假设我们有a b两个进程呢,那么不管是哪两个进程呢,那么我们以a进程为例,它自己有自己的代码区有自己的数据区,那么就可以有自己的页表,然后经过页表呢将对地址空间当中的内容进行映射到物理地址当中。(当然前提肯定是你这个进程的代码数据各种全全部都有了)。
然后映射过来,此时我们的进程就能看到,就能访问了。
本质原理:
①这里第一步就先在这个物理内存先创建出来一块空间。
②第二步再把这个共享空空间再经过页表啊映射到我们对应的一个进程的共享区当中。
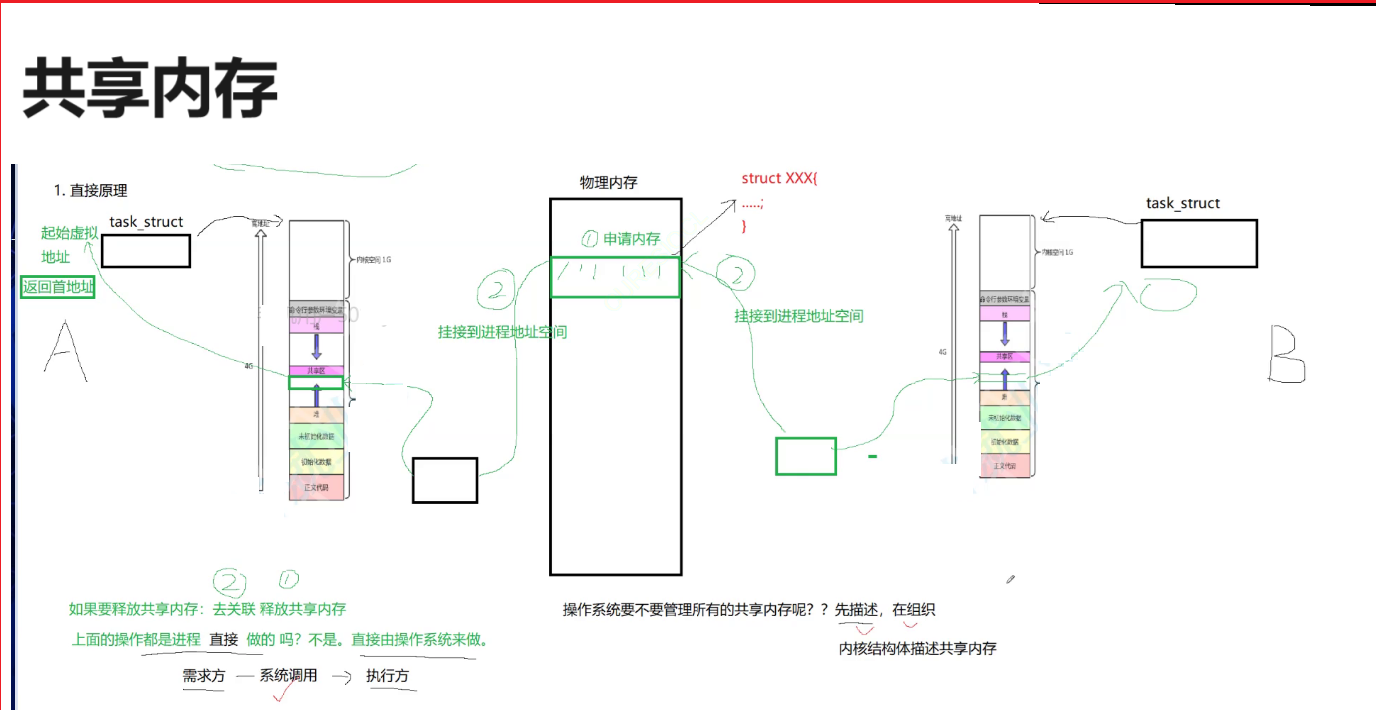
那么映射到我们的共享区当中呢,然后给应用层返回一个对应的连续的内存空间的起始地址啊,所以这里呢我们就有一个起始的虚拟地址。
那么首先这一点在操作系统层面上,他想做是完全可以做到的那么这时我们就完成了一个叫做共享内存的创建。
这个共享内存是建立在我们进程地址空间的共享区的,那么进程这个时候就能直接访问了。既然操作系统能把你对应的申请的这块内存给你这个进程a去进行建立映射。要通信其他进程,其他进程你也可以来进行映射啊,经过页表映射到你自己的地址空间里面。
然后呢建立好之后,给这应用层也返回虚拟地址啊,所以从此往后呢,我们两个进程就可以通过各自的页表访问同一块物理内存了。
那么此时这就叫做先让不同的进程看到同样的一份资源。这个原理就叫做共享内存。
这要做的第一步无非就是要先申请内存啊,二步就是要把申请好的这块内存分别挂接到我们两个进程它的地址空间。然后返回我们对应的首地址啊。返回了我们对应的地址之后呢,就有了一段我们对应的起始对应的内存了。
所以我们未来访问时可以经过列表访问这个内存,一个进程向我们的共享内存里进行写,如果你愿意,你也可以写啊,共享内存是双向通信的,但一般我们都是一个写一个读。
【问题1】系统调用
进城需要通信。操作系统来帮我们来做这个建立通信的信道。
也就是说,我们的进程呢,说我要通信,那么操作系统说行,那我帮你执行。
进程自己不能在系统里直接访问内核数据结构,它也不能直接搞它的页表,然后建立映射。需要操作系统来搞。如果进程自己做了这个东西,那么这个内存就属于你自己的。我们想要的是一个共享的空间。
所以我们的需求是要让操作系统去执行,它解决的是我们为什么要要建立共享内存,它解决的是我们如何建立的问题。
所以我们必须得由操作系统来给我们的进程操作,这样就一定要存在一个东西叫做系统调用。
所以共享内存这玩意儿呢,它将来的建立,挂接,最终是由操作系统必须得给我提供一批系统调用。然后我进程呢调你的系统调用,我什么时候调是由我进程说了算。但一旦我调系统调用了,就跟我的进程没关系,是由操作系统帮我去做的,创建出来的共享内存,那么其中就不属于我这个进程私有的。
【问题2】共享内存在内核方面的理解
所以这个共享内存是要由操作系统管理的,当很多进程都要进行通信,操作系统就要创建多个共享内存,操作系统就需要对这些共享内存进行管理:
在操作系统当中,你对应的要管理这个共享内存。要管理这个管理层,必须得把管理层先得描述起来。比如说啊我们就得有一个struct结构体描述你申请的共享内存多大呀,谁申请的呀?那么当前有多少个进程和我是关联的呀,那么我们当前进程呃共享内存啊我们使用了多少了等它的诸多属性。我们是不是一定要有内核结构体来描述共享内存。再把所有的这些被共享内存的结构体,用链表了、数组了,或者你各种数据结构管理起来。
所以在操作系统层面上管理共享内存的行为就变成了对某种数据结构的增删查改。
【问题3】删除共享内存
共享内存申好了,那么如何删除共享内存呢???
那么你肯定是要先去关联啊,不难理解,就是你曾经不是把共享内存挂接到你地址空间了吗?那要释放共享内存,那么首先得做的是让当前进程和共享内存去掉关联,也就是把页表曾经映射的那些条目直接去掉。那么去关联之后,然后才能进行释放共享内存。
可是最最尴尬的是,我们的共享内存,它怎么知道有几个进程跟他是关联的呢?
好,共享内存,它怎么知道有几个进行关联呢?所以它在内部是存在着引用计数,计算有多少个进程和它关联起来的。那么删除共享内存时,去关联后,并不能直接删除共享内存,还需要看引用计数是否为0,只有当最后一个进程去关联的时候,减到零的时候才可以真正的删除共享内存。
2.申请内存
首先得能够在系统里创建一个共享内存。在linux系统里创建一个共享内存,我们所要采用的接口叫shmget(),它的作用呢是申请一个系统的共享内存啊
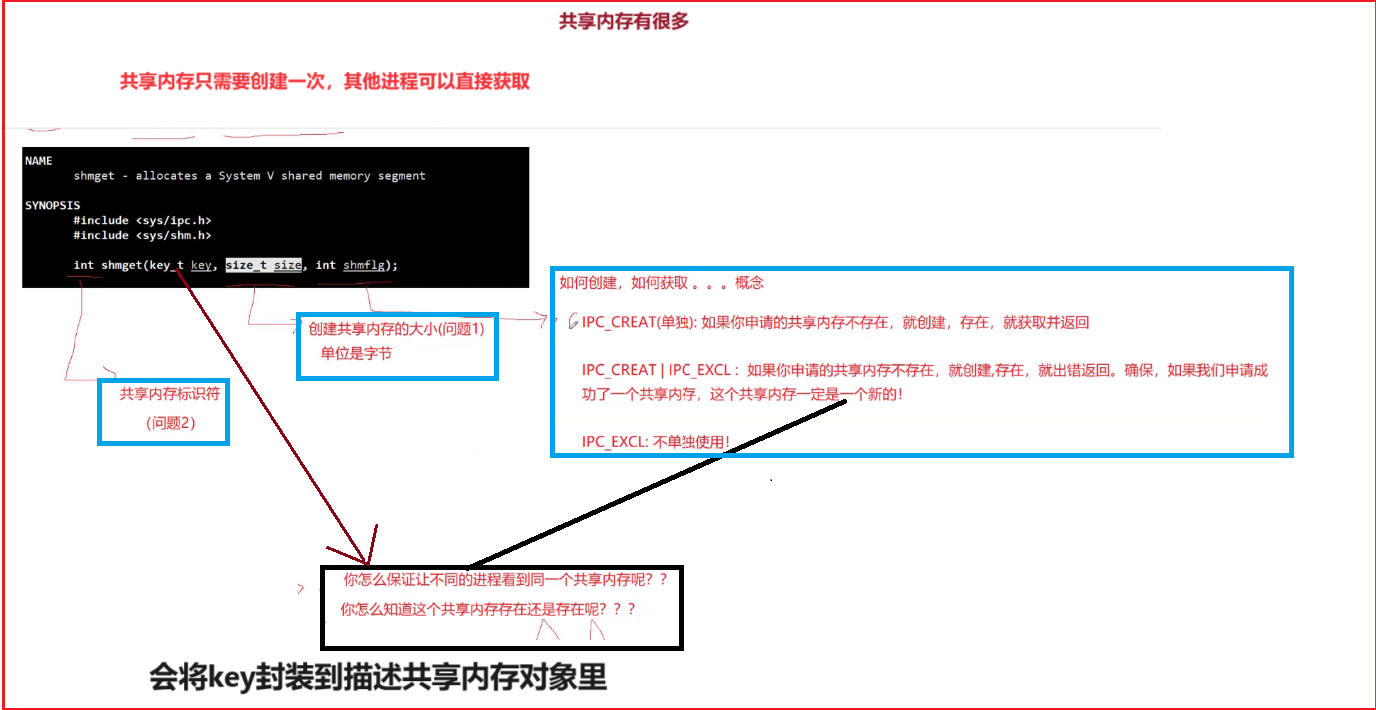
shmget系统调用三个参数分别代表的意义:
1.第一个参数:key
不管我将来是想创建共享内存,还是想获取共享内存。我们两个j进程必须拿到同一个key。
因为只有拿到了同一个king,我们此时才能证明我们两个访问的是同一个共享内存。因为系统里可同时会存在非常多的共享内存哦,那有很多的话,你怎么保证你的就是通信双方的进程看到的是同一个共享内存呢?
所以key是让我们的不同进程进行唯一性标识。我们呢才能保证我们在共享内存里判断一个共享内存存在。
因为我要创建过共享内存,我也得有个key。这样在系统里去创建共享内存的时候,你存在还是不存在,我就可以拿着我的k和系统里进行对比就可以了。那么正是因为我们有了key,所以啊第一个进程可以通过我们对应的k创建共享内存。
那么第二个进程他们只要拿着同一个key值获得已经创建的共享内存。
所以两个进程只要拿着同一个key就可以看到同一个叫做我们的共享内存了。
第一个进程通过king创建。第二个他只要拿着同样的key,他就可以和第一个进程看到同共享内存了。
因为我们这个king是唯一的,而且呢我们两个呢那么就可以通过key来标定为一个共享内存了。
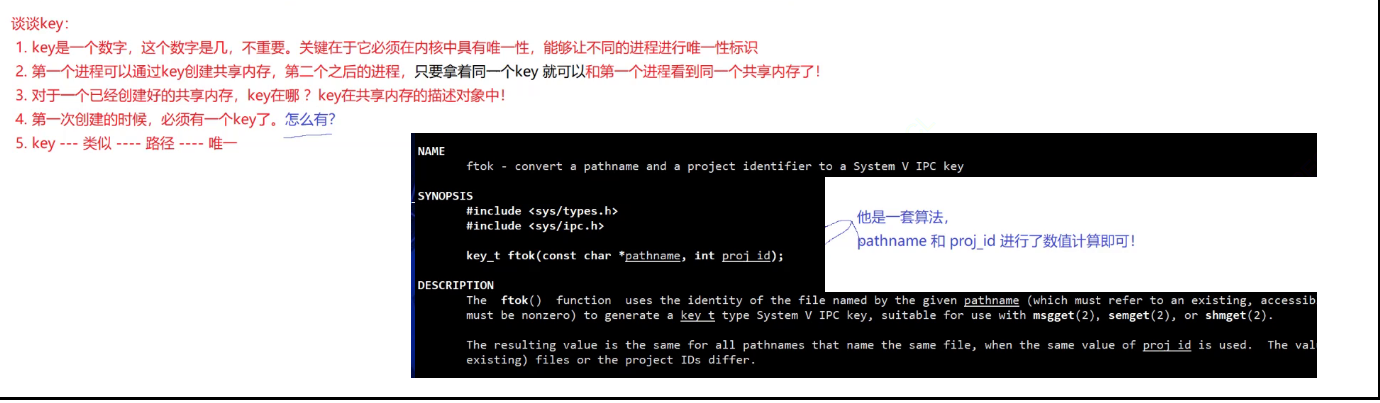
通过ftok(pathname,processid)接口就可以创建一个key值。
【问题1】为什么要自己创建key,而不是让操作系统创建呢?
如果操作系统给你形成了一个key,你怎么把这个key交给另一个和你通信的进程呢?
2.第二个参数
共享内存的大小
3.第三个参数
设置共享内存创建时,设置一些配置和权限
IPC_CREAT:创建共享内存,如果不存在,就创建。如果存在就返回存在的共享内存。
IPC_CREAT|IPC_EXCL.创建共享,如果不存在就创建,如果存在就报错。
4.返回值
shmid返回的是用来标识唯一的共享内存标识符。
key是给操作系统用的,让操作系统去拿着它去申请共享内存,这里所谓的shmid最后是不是就是它的返回值啊?它的返回值叫做共享内存标识符,它只在你的进程内。
一个是给我们对应的操作系统内标定唯一性的。
一个是让我们在自己的编码当中用这个共享内存,用它来进行控制共享内存的。所以只有创建共享内存是用这个key从此往后再也不用这个key了。创建完后,再对这个共享内存操作都是通过shmdi来找到共享内存操作的。
3.挂接
共享内存申请完了,第二步骤就是我们要把这个外部内存和我的进程挂接起来。那么怎么挂接呢?首先肯定不能你自己挂,肯定是由操作性的给你提供接口的,所以我们叫做shmat。
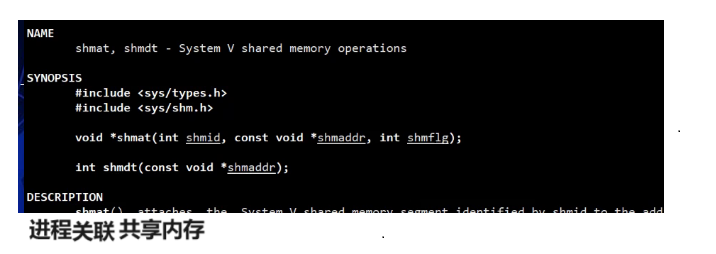
返回值这里的代表的含义就是你想让你当前对应的共享内存挂接到地址空间的什么位置。共享内存最终挂接的时候是在我们对应的共享区,但具体你想让它挂载到我们共享区的什么位置?void*就是我们最终得到的那个虚拟的起始地址。第三个参数我们也是默认啊,默认的话就按照我们的这个呃叫做我们共享内存它默认的权限来就行了。所以这里设为零就可以。
第二个参数设为nullptr,它给我们得到的是一块连续堆空间的起始地址,说白了就是一块虚拟地址。
4.通信
将共享内存挂接到不同进程的地址空间后,这些进程之间就可以进行通信了。
公共资源comm.hpp。它们之间的通信非常简单直接,就是各种朝自己的内存里输出和输入即可。

#include <iostream>
using namespace std;
#include <string>
#include <cstdlib>
#include <cstring>
#include <sys/ipc.h>
#include <sys/shm.h>
#include <errno.h>
#include <sys/types.h>
#include <sys/types.h>
#include <sys/stat.h>
//key值的获取根据系统调用ftok(pathname,pro_id)
const string pathname="/home/tao";
const int pro_id=0x6666;
int size= 4096;
//这是用户自己决定的
//Log log;
key_t GetKey()
{
key_t k=ftok(pathname.c_str(),pro_id);
if(k<0)
{
// log(Fatal,"ftok error:%s",strerror(errno));//致命错误
exit(1);
}
//普通日志:成功
//log(Info,"ftok success key is %d",k);
return k;
}
int GetMEm(int flag=IPC_CREAT|IPC_EXCL|0666)//默认是创建,权限是0666
{
int key=GetKey();
int shmid=shmget(key,size,flag);//确保每次创建的都是新的共享内存
if(shmid<0)
{
// log(Fatal,"Creat shmget error:%s",strerror(errno));
exit(2);
}
//log(Info,"Creat shmget success shmid is%d",shmid);
return shmid;
}
//进程a是创建共享内存的,而进程b是要获取共享内存的,我们可以通过传不同的参数
//调用同一个GetMem来完成,因为获取共享内存,我们就不加上IPC_EXCL就可以实现
//如果共享内存以及存在,就直接返回该共享内存。
int CreatSM()
{
return GetMEm();//默认是创建
}
int GetSM()
{
return GetMEm(IPC_CREAT);//只传入IPC_CREAT就是获取原先存在的共享内存
}
进程a.cc
#include "comm.hpp"
//两个进程想通过共享内存通信
//1.首先进程a根据key值让操作系统申请共享内存
//通过唯一的key值来让操作系统申请一块唯一的共享内存,所以第一步首先需要约定以一个key值
//本质就是操作系统会拿这个key值去构造一个结构体对象,该结构体对象是用来管理共享内存的
//2.进程a的地址空间需要挂接到共享内存
//3.不用了就去挂接
//4.共享内存是没有同步互斥的,我们可以利用管道的方式,来进行同步,在进行通信之前,创建
//命名管道,并将命名管道打开。开始接受信息,一旦接受到一个信息才可以进行输出,如果没有收到就在等待
int main()
{
//1.创建共享内存
int shmid=CreatSM();
//2.挂接到共享内存--挂接到地址空间的哪里呢?挂接到shmadder地方
char*shmaddr=(char*)shmat(shmid,nullptr,0);
//3.通信
while(true)
{
cout<<"client say@ "<<shmaddr<<endl;
}
//4.不用了去关联
shmdt(shmaddr);
//5.最后如果没有进程要用共享内存了,共享内存是不会自动销毁的,需要用户手动销毁
shmctl(shmid,IPC_RMID,nullptr);
}
进程b.cc
#include "comm.hpp"
//进程b如果想和进行a通过共享内存通信,需要用自己的key来和共享内存进行匹配
//因为共享内存被进程a创建完了,进程b只需匹配
//进程b匹配完也需要将自己的地址空间挂接到共享内存上。
//实现同步---在通信之前创建命名管道,并打开命名管道,往命名管道里输入固定信息,才能往
//共享内存里输入。
int main()
{
//1.获取到共享内存
int shmid=GetSM();
//2.挂接到地址空间
char* shmaddr=(char*)shmat(shmid,nullptr,0);
//3.开始通信
while(true)
{
cout<<"Please enter:";
cin>>shmaddr;
}
//4.不用了,去关联
shmdt(shmaddr);
}
5.去关联
如果想去掉你自己对某一个共享内存的关联,那么你只需要使用shmdt

那么这个参数什么意思呢?这个参数就是曾经这个shmat所得到的虚拟地址的起始地址。
6.释放共享内存
自己不主动的把共享内存给我关掉,操作系统我也不给你关。你不主动关闭,那么共享内存会一直存在。所以共享内存一旦创建,还要放在那儿。
你用户你想进行几个进程通信,你就随时挂机,你想用你就创建啊,你想用你就挂机,不用你把它直接去关联,除非你主动关闭好,否则固态内存一直存在。生命周期随内核啊
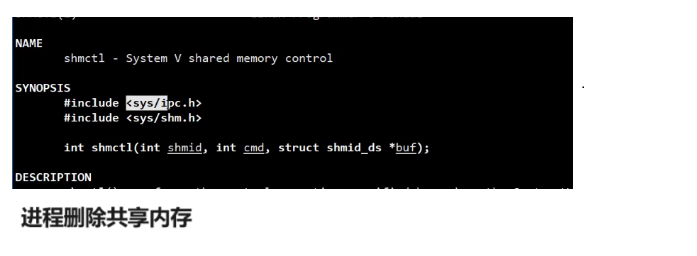
shamctl可以用来删除共享内存,也可以用来获取共享内存的属性。它这个接口第一个参数啊,就是我们共享内存的id,也就是共享内存标识符。第二个参数用来删除共享内存的。第三个参数就是用来获取共享内存的各种属性的,各种属性都存在struct shmid_ds这个结构体对象里。
7.特性:
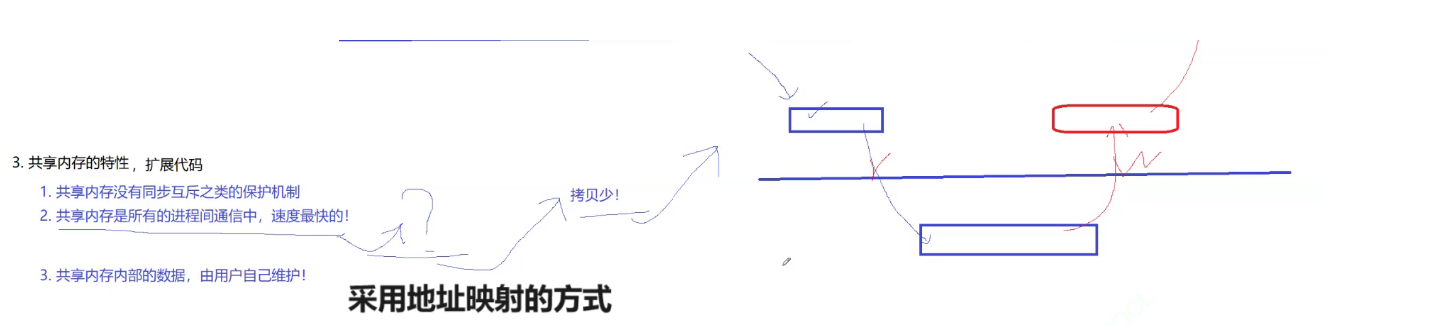
共享内存这块,我们发现它没有同步机制,需要我们自己设置一些同步加锁来保护它,它是通信方式中最快的一种,因为通信的过程中,拷贝次数很少。

![[译]JavaScript中Base64编码字符串的细节](https://img-blog.csdnimg.cn/img_convert/6b5509e5e1847bcb8bca4f12625b25f4.png)