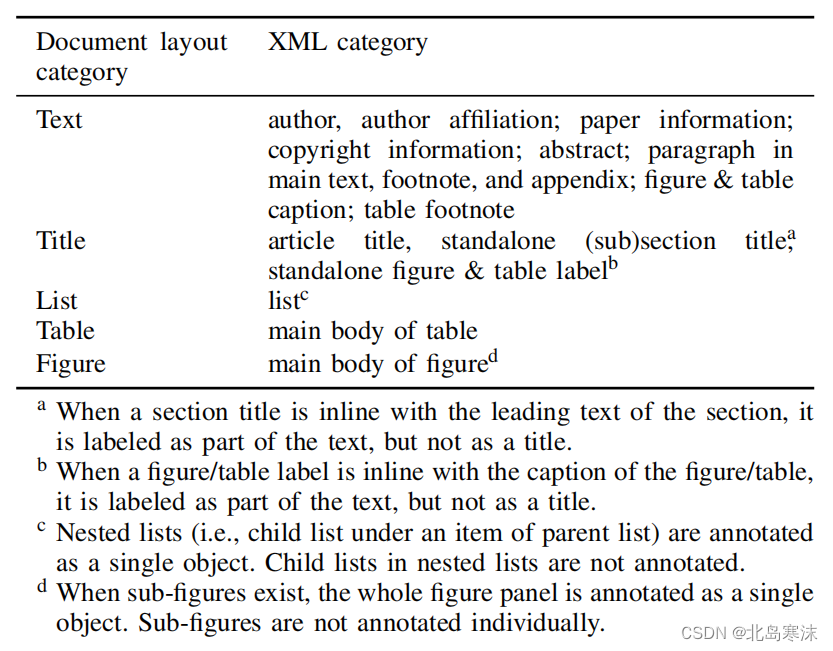
以下案例由浅到深,逐步深入,通过实例介绍了序列化器的使用方法,和遇到的常见问题的解决方法。
一、序列化器serializers.Serializer
1、urls.py
urlpatterns = [
path("api/<str:version>/depart/",views.DepartView.as_view(),name="depart")
]2、models.py
class Depart(models.Model):
title = models.CharField(verbose_name="部门",max_length=32)
order = models.IntegerField(verbose_name="顺序")
count = models.IntegerField(verbose_name="人数")3、views.py
from rest_framework import serializers
# 自定义模型序列化器1:Serializer
class DepartSerializer(serializers.Serializer):
# 字段名要与模型中的字段一致,需要哪个字段写哪个;
title = serializers.CharField()
count = serializers.IntegerField()
class DepartView(APIView):
def get(self,request,*args,**kwargs):
# 1.数据库中获取数据
queryset = models.Depart.objects.all()
# 2.转换成JSON格式,mang=True表示有多个值,默认为False,有一个值;
ser = DepartSerializer(instance=queryset,many=True)
# 3.返回给用户,这里对数据进行了在包装,返回了一个状态值:status
context = {"status":True,"data":ser.data}
return Response(context)4、自定义模型序列化器时,可以继承ModeSerializer,操作起来就更方便;
# 自定义模型序列化器2:ModelSerializer
class DepartSerializer(serializers.ModelSerializer):
class Meta:
model = models.Depart
# 模型中所有的字段都会拿过来,
fields = "__all__"二、模型中特殊字段序列化方法,如模型中的choices、ForeignKey、Datetime
1、urls.py
path("api/<str:version>/user/", views.UserView.as_view(), name="user")2、models.py,这个表中模拟了常见的各种数据类型字段
class User(models.Model):
name = models.CharField(verbose_name="姓名",max_length=32)
age = models.IntegerField(verbose_name="年龄")
gender = models.SmallIntegerField(verbose_name="性别",choices=((1,'男'),(2,'女')))
depart = models.ForeignKey(verbose_name='部门',to='Depart',on_delete=models.CASCADE)
ctime = models.DateTimeField(verbose_name="时间",auto_now_add=True)
3、views.py
# 自定义模型序列化器
class UserSerializer(serializers.ModelSerializer):
# gender字段显示出来是整型,要想显示对应的string类型,需要自定义字段,字段名可以自己定义;
# 这里主要是介绍 source的用法;用来解决模型中choices的问题;
gender_text = serializers.CharField(source='get_gender_display')
# 解决ForeignKey显示对应字段的问题;
depart = serializers.CharField(source='depart.title')
# 解决Datatime字段显示时间的问题,不设定格式显示的带毫秒
ctime = serializers.DateTimeField(format='%Y-%m-%d')
class Meta:
model = models.User
# fields = "__all__" # 显示所有字段
fields = ['name','age','gender','gender_text','depart','ctime'] # 指定显示字段
class UserView(APIView):
def get(self,request,*args,**kwargs):
# 1.获取数据;
queryset = models.User.objects.all()
# 2.序列化;
ser = UserSerializer(instance=queryset,many=True)
# 3.返回数据;
context = {'status':True,'data':ser.data}
return Response(context)4、通过postman测试返回数据
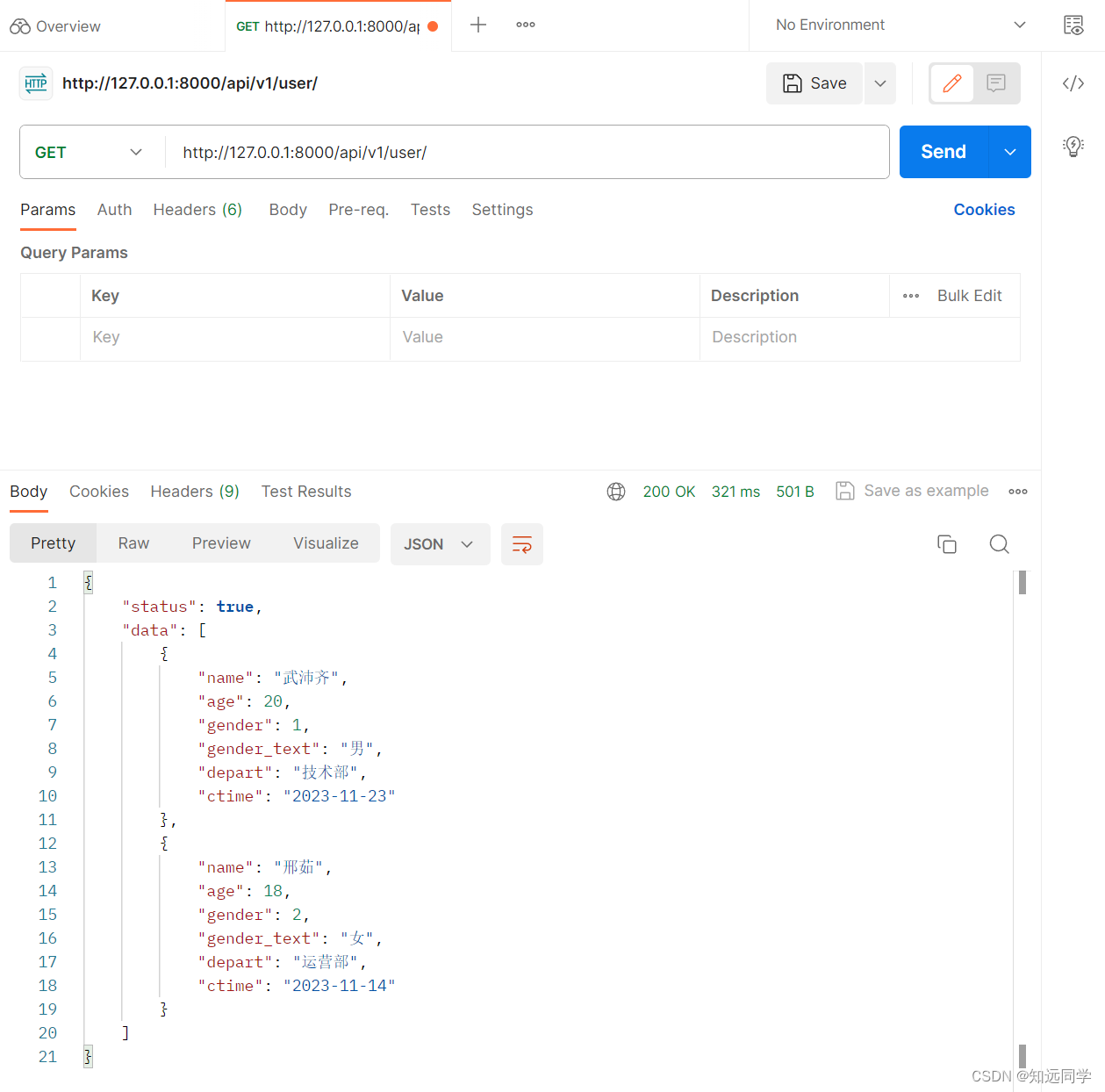
三、在自定义模型序列化器中,通过自定义方法实现定制的返回值,get_xxx方法中return返回什么,xxx字段就会显示什么,后期开发中使用的还是比较多。
注:model.py、urls.py和上例相同,这里不再重复。
1、views.py
# 自定义模型序列化器
class UserSerializer(serializers.ModelSerializer):
# gender字段显示出来是整型,要想显示对应的string类型,需要自定义字段,字段名可以自己定义;
# 这里主要是介绍 source的用法;用来解决模型中choices的问题;
gender_text = serializers.CharField(source='get_gender_display')
# 解决ForeignKey显示对应字段的问题;
depart = serializers.CharField(source='depart.title')
# 解决Datatime字段显示时间的问题,不设定格式显示的带毫秒
ctime = serializers.DateTimeField(format='%Y-%m-%d')
# 自定义方法
xxx = serializers.SerializerMethodField()
class Meta:
model = models.User
# fields = "__all__" # 显示所有字段
fields = ['name','age','gender','gender_text','depart','ctime','xxx'] # 指定显示字段
def get_xxx(self,obj):
return '{}-{}-{}'.format(obj.name,obj.age,obj.gender)
class UserView(APIView):
def get(self,request,*args,**kwargs):
# 1.获取数据;
queryset = models.User.objects.all()
# 2.序列化;
ser = UserSerializer(instance=queryset,many=True)
# 3.返回数据;
context = {'status':True,'data':ser.data}
return Response(context)2、返回数据展示

四、序列化中的嵌套,一般用来解决模型中ManyToMany和ForeignKey的处理
1、urls.py
path("api/<str:version>/depart/",views.DepartView.as_view(),name="depart"),
path("api/<str:version>/user/", views.UserView.as_view(), name="user")2、models.py
class Depart(models.Model):
title = models.CharField(verbose_name="部门",max_length=32)
order = models.IntegerField(verbose_name="顺序")
count = models.IntegerField(verbose_name="人数")
class Tag(models.Model):
caption = models.CharField(verbose_name='标签',max_length=32)
class User(models.Model):
name = models.CharField(verbose_name="姓名",max_length=32)
age = models.IntegerField(verbose_name="年龄")
gender = models.SmallIntegerField(verbose_name="性别",choices=((1,'男'),(2,'女')))
depart = models.ForeignKey(verbose_name='部门',to='Depart',on_delete=models.CASCADE)
ctime = models.DateTimeField(verbose_name="时间",auto_now_add=True)
# 创建多对多的关系
tags = models.ManyToManyField(verbose_name='标签',to='Tag')
3、views.py
# 序列化器的嵌套,主要针对ForeignKey和ManyToMany
# 自定义序列化器,序列化Depart表
class D1(serializers.ModelSerializer):
class Meta:
model = models.Depart
fields = ['id','title']
# 自定义序列化器,序列化Tag表
class D2(serializers.ModelSerializer):
class Meta:
model = models.Tag
fields = ['caption']
class UserSerializer(serializers.ModelSerializer):
depart = D1()
# 标签这里是多对多的关系,所以还是要加上mangy=True
tags = D2(many=True)
class Meta:
model = models.User
# fields = "__all__" # 显示所有字段
fields = ['name','age','depart','tags']
class UserView(APIView):
def get(self,request,*args,**kwargs):
# 1.获取数据;
queryset = models.User.objects.all()
# 2.序列化;
ser = UserSerializer(instance=queryset,many=True)
# 3.返回数据;
context = {'status':True,'data':ser.data}
return Response(context)
4、返回数据展示

五、序列化器的继承
1、urls.py
path("api/<str:version>/depart/",views.DepartView.as_view(),name="depart"),
path("api/<str:version>/user/", views.UserView.as_view(), name="user")2、models.py
class Depart(models.Model):
title = models.CharField(verbose_name="部门",max_length=32)
order = models.IntegerField(verbose_name="顺序")
count = models.IntegerField(verbose_name="人数")
class Tag(models.Model):
caption = models.CharField(verbose_name='标签',max_length=32)
class User(models.Model):
name = models.CharField(verbose_name="姓名",max_length=32)
age = models.IntegerField(verbose_name="年龄")
gender = models.SmallIntegerField(verbose_name="性别",choices=((1,'男'),(2,'女')))
depart = models.ForeignKey(verbose_name='部门',to='Depart',on_delete=models.CASCADE)
ctime = models.DateTimeField(verbose_name="时间",auto_now_add=True)
# 创建多对多的关系
tags = models.ManyToManyField(verbose_name='标签',to='Tag')
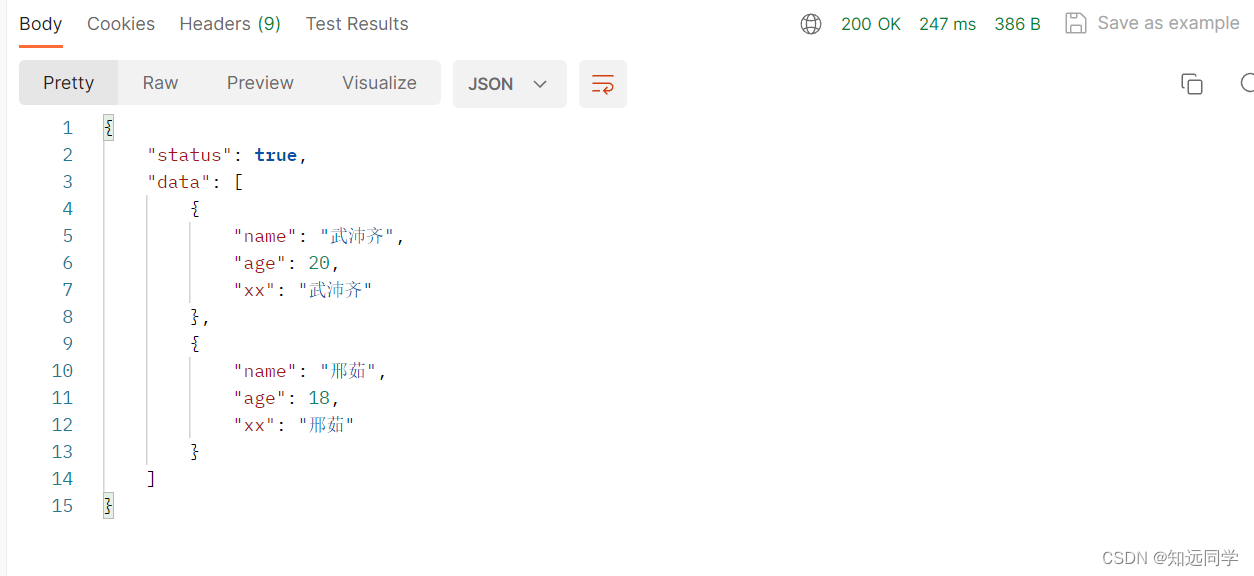
3、views.py,Base是自定义的一个类,里面有一个字段是XX,source=‘name’,当UserSerializer继承了Base类的时候,可以直接使用XX字段。
class Base(serializers.Serializer):
xx = serializers.CharField(source='name')
class UserSerializer(serializers.ModelSerializer,Base):
class Meta:
model = models.User
# fields = "__all__" # 显示所有字段
fields = ['name','age','xx']
class UserView(APIView):
def get(self,request,*args,**kwargs):
# 1.获取数据;
queryset = models.User.objects.all()
# 2.序列化;
ser = UserSerializer(instance=queryset,many=True)
# 3.返回数据;
context = {'status':True,'data':ser.data}
return Response(context)4、返回数据展示