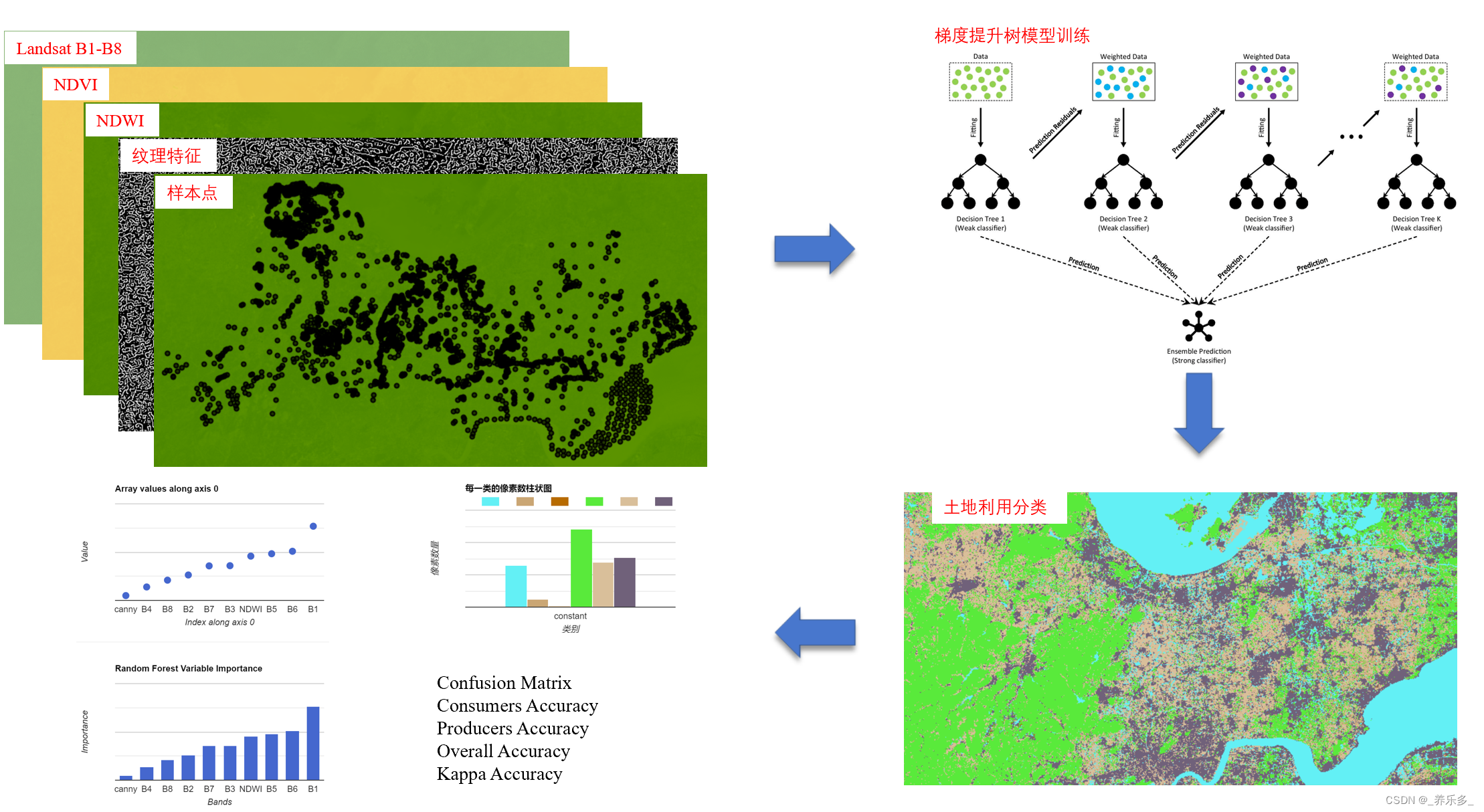
1 状态TTL机制
1.1 API简介
TTL常用API如下:
| API | 注解 |
|---|---|
| setTtl(Time.seconds(…)) | 配置过期时长,当状态中的数据到达这个时长则判定为过期数据,在new StateTtlConfig.Builder(Time.seconds(...))也可以配置,如果同时调用setTtl()方法则进行覆盖 |
| updateTtlOnCreateAndWrite() | 当该条数据在State中插入或者更新的时候,刷新计时,可用于冷热数据分离 |
| updateTtlOnReadAndWrite() | 读或写都刷新该数据的TTL计时,可用于冷热数据分离 |
| setStateVisibility(…) | 用于控制状态中过期数据的可见性,当方法中设置StateTtlConfig.StateVisibility.NeverReturnExpired)时则不可见过期未被清理的数据,如果设置StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp则可见过期未被清理的数据.setStateVisibility(...)由异步线程执行,默认是NeverReturnExpired. |
| setTtlTimeCharacteristic(…) | 指定TTL的时间语义,默认是event time,可以配置process time,将StateTtlConfig.TtlTimeCharacteristic.ProcessingTime填入方法的参数即可. |
| disableCleanupInBackground() | 禁用后台清理过期数据,使用后则不会清理过期数据 |
| cleanupIncrementally(… , …) | 针对本地状态后端,即HashMapStateBackend. 增量清理, 每当访问状态数据时都会驱动一次过期检查,清除其中部分数据, 这也是HashMapBackend状态后端唯一能真正清理过期数据的方法,cleanupIncrementally(... , ...)方法中需要传入两个参数int cleanupSize和boolean runCleanupForEveryRecord,cleanupSize是指key的数据量,runCleanupForEveryRecord是指是否清理所有过期数据,如果runCleanupForEveryRecord设置的值为true此时cleanupSize就会失效,但是状态数据较多时会严重影响时效性. |
| cleanupFullSnapshot() | 针对快照数据,即checkpoint快照. 全量清理, 在做快照时将所有的过期数据进行清理保证快照中没有过期数据,但是状态后端中的过期数据没有进行清理. |
| cleanupInRocksdbCompactFilter(xxx) | 针对于RocksdbStateBackend. 只生效于RocksDB状态后端,通过Flink将CompactFilter传给RocksDB,在RocksDB在Compact过程中根据过滤条件将过期数据删除,传入的参数为过期时间. |
1.2 代码模板
-
代码
class StateMapFunc2 implements MapFunction<String, String>, CheckpointedFunction { private ListState<String> listState; @Override public String map(String s) throws Exception { // 将数据添加到状态存储器中,split[0]为用户ID listState.add(s); // 获取状态存储器中的数据 Iterable<String> iter = listState.get(); StringBuffer buffer = new StringBuffer(); for (String str : iter) { buffer.append(str); } // 将数据添加到状态存储中 return buffer.toString(); } @Override public void snapshotState(FunctionSnapshotContext ctx) throws Exception { } @Override public void initializeState(FunctionInitializationContext ctx) throws Exception { OperatorStateStore operatorStateStore = ctx.getOperatorStateStore(); // 配置State TTL StateTtlConfig ttlConfig = new StateTtlConfig.Builder(Time.seconds(10)) // 设置数据存活时长,当该数据在State中存活时间超过10s时删除该数据 // 这个方法也是设置数据存活时长,和StateTtlConfig.Builder(Time.seconds(10))的作用一样,可以不用这个方法,如果用了会覆盖上面设置的时长 .setTtl(Time.seconds(10)) /** * updateTtlOnCreateAndWrite和updateTtlOnReadAndWrite二选一即可, 这两个方法的主要作用就是配合setTtl方法将冷热数据进行分离 **/ // 当该条数据在State中插入或者更新的时候,刷新计时 .updateTtlOnCreateAndWrite() // 读或写都刷新该数据的TTL计时 .updateTtlOnReadAndWrite() /** * setStateVisibility就是设置状态的可见性,前面setTtl方法是设置删除过期数据,删除过期数据实际上是由另一个异步线程周期性(定时器)的完成,也就是说超过10s的数据不一定会马上被删除,但是 * 获取数据的时候底层会将超过存活时间的数据进行判断过滤,setStateVisibility就是可以设置是否可以查询到这些过期的数据,NeverReturnExpired和ReturnExpiredIfNotCleanedUp二选一. **/ // 不返回过期数据,这个也是默认策略 .setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired) // 返回还没有被清除的过期数据 .setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp) // 指定TTL计时时间语义(默认处理时间) .setTtlTimeCharacteristic(StateTtlConfig.TtlTimeCharacteristic.ProcessingTime) // 禁用后台清理过期数据 .disableCleanupInBackground() /** * 针对本地状态后端,即HashMapStateBackend * 增量清理, 每当获取状态数据时,迭代器都会向前推进。对遍历的状态数据进行检查,并清理过期的数据 * 参数1: 设置每次清理的key的数据量(copyOnWriteStateMap中的key的条目数量) * 参数2: 设置是否清理所有条目也就是key对应的数据,如果设置为true则参数1失效,在状态数据较多时不建议设置为true,会严重影响时效性 **/ .cleanupIncrementally(10, false) /** * 针对快照数据,即checkpoint快照 * 全量清理, 在做快照时将所有的过期数据进行清理保证快照中没有过期数据,但是不会清状态后端中的过期数据 **/ .cleanupFullSnapshot() /** * 针对于RocksdbStateBackend * 只生效于RocksDB状态后端,通过Flink将CompactFilter传给RocksDB,在RocksDB在Compact过程中根据过滤条件将过期数据删除,传入的参数为过期时间(也就是发生Compact时的过滤条件) **/ .cleanupInRocksdbCompactFilter(10000) .build(); // 配置状态描述,在ListStateDescriptor构造器中声明数据类型,简单类型可以使用xxx.class,符合类型需要使用到TypeInformation.of() ListStateDescriptor descriptor = new ListStateDescriptor("MapState", String.class); // 状态描述器加载TTL配置 descriptor.enableTimeToLive(ttlConfig); listState = operatorStateStore.getListState(descriptor); } }代码中是以
Operator State为例,如果是Keyed State则在open方法中配置TTL.
1.3 TTL机制详解
在代码模板中有API的使用方式,但是TTL机制不同的方法之间存在互斥或者互不影响的关系.
1.3.1 过期时间设置策略
- new StateTtlConfig.Builder(Time.seconds(10))
- setTtl(Time.seconds(10))
这两种方式都是设置过期时间使用的,但是只需要选用其中一种即可,如果在创建StateTtlConfig对象时就设置了过期时间,又在setTtl方法中设置了过期时间,则会对过期时间进行覆盖,本质上二者都是对同一个变量进行赋值.
-
源码
new StateTtlConfig.Builder(Time.seconds(10))public static class Builder { private UpdateType updateType = OnCreateAndWrite; private StateVisibility stateVisibility = NeverReturnExpired; private TtlTimeCharacteristic ttlTimeCharacteristic = ProcessingTime; private Time ttl; private boolean isCleanupInBackground = true; // ... // 调用Builder时对ttl变量进行了赋值 public Builder(@Nonnull Time ttl) { this.ttl = ttl; } // ... }setTtl(Time.seconds(10))public static class Builder { private UpdateType updateType = OnCreateAndWrite; private StateVisibility stateVisibility = NeverReturnExpired; private TtlTimeCharacteristic ttlTimeCharacteristic = ProcessingTime; private Time ttl; private boolean isCleanupInBackground = true; // ... // 这里同样是对ttl进行了赋值 @Nonnull public Builder setTtl(@Nonnull Time ttl) { this.ttl = ttl; return this; } // ... }通过源码可以看出,使用此
API时在创建StateTtlConfig对象时给一个过期时间即可,不需要再调用setTtl方法
1.3.2 过期时间刷新策略
- updateTtlOnCreateAndWrite()
- updateTtlOnReadAndWrite()
这两方法就是互斥的,只能生效一个,同样是因为二者都是对同一个变量进行赋值,就是说在二者同时调用的情况下,谁在后面调用谁就生效,如代码模板中线调用的updateTtlOnCreateAndWrite()后调用的updateTtlOnReadAndWrite()那么生效的就是updateTtlOnReadAndWrite()策略.
-
源码
public static class Builder { private UpdateType updateType = OnCreateAndWrite; private StateVisibility stateVisibility = NeverReturnExpired; private TtlTimeCharacteristic ttlTimeCharacteristic = ProcessingTime; private Time ttl; private boolean isCleanupInBackground = true; // ... // 此方法给updateType进行赋值 @Nonnull public Builder setUpdateType(UpdateType updateType) { this.updateType = updateType; return this; } /* * 二者方法体中调用的都是同一个方法setUpdateType */ @Nonnull public Builder updateTtlOnCreateAndWrite() { return setUpdateType(UpdateType.OnCreateAndWrite); } @Nonnull public Builder updateTtlOnReadAndWrite() { return setUpdateType(UpdateType.OnReadAndWrite); } // ... }源码可以看出二者调用同一个方法
setUpdateType,而setUpdateType方法又是给updateType赋值的一个方法,所以再使用时要根据实际的业务场景选择updateTtlOnCreateAndWrite()和updateTtlOnReadAndWrite()中的一个.
1.3.3 返回过期数据策略
- setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
- setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)
-
源码
public static class Builder { private UpdateType updateType = OnCreateAndWrite; private StateVisibility stateVisibility = NeverReturnExpired; private TtlTimeCharacteristic ttlTimeCharacteristic = ProcessingTime; private Time ttl; private boolean isCleanupInBackground = true; // ... // 此方法给stateVisibility进行赋值 @Nonnull public Builder setStateVisibility(@Nonnull StateVisibility stateVisibility) { this.stateVisibility = stateVisibility; return this; } // 下面两个方法体中都是调用setStateVisibility方法 @Nonnull public Builder returnExpiredIfNotCleanedUp() { return setStateVisibility(StateVisibility.ReturnExpiredIfNotCleanedUp); } @Nonnull public Builder neverReturnExpired() { return setStateVisibility(StateVisibility.NeverReturnExpired); } // ... }这二者同样是互斥的原则,使用选其一即可,即使都调用也是后被调用者生效.
1.3.4 过期数据清除策略
- cleanupIncrementally(10, false)
- cleanupFullSnapshot()
- cleanupInRocksdbCompactFilter(10000)
这三种过期数据清除策略针对的是不同的场景(本地状态后端、快照、RocksDB状态后端),所以三者是可以同时使用的,不会存在同时调用后者会对前者进行覆盖的问题,在API简介章节介绍了这种三策略的作用,这里着重介绍cleanupIncrementally策略.
HashMapStateBackend使用的存储结构是Flink团队自己开发的一种数据存储结构copyOnWriteStateMap,说这个存储结构是因为cleanupIncrementally策略删除过期数据的操作和这种结构息息相关.
关于copyOnWriteStateMap的结构可以简单的理解为K,V形式存储的结构,其中的Key就是使用keyBy时指定的key,如果没有使用keyBy那么所有数据key都会给一个相同的默认值,其中的Value是指ListState、MapState等,也就是在构建状态存储器时候选择存储形式,如下图:

在本地状态后端(HashMapStateBackend)中默认使用的就是cleanupIncrementally清除策略,默认值为cleanupIncrementally(5, false),也就是说只要设置了TTL的过期时间,HashMapStateBackend就会使用cleanupIncrementally策略来清理过期数据,只不过cleanupIncrementally对用户提供了选择方式,这里将结合图解说明cleanupIncrementally如何清除过期数据的.
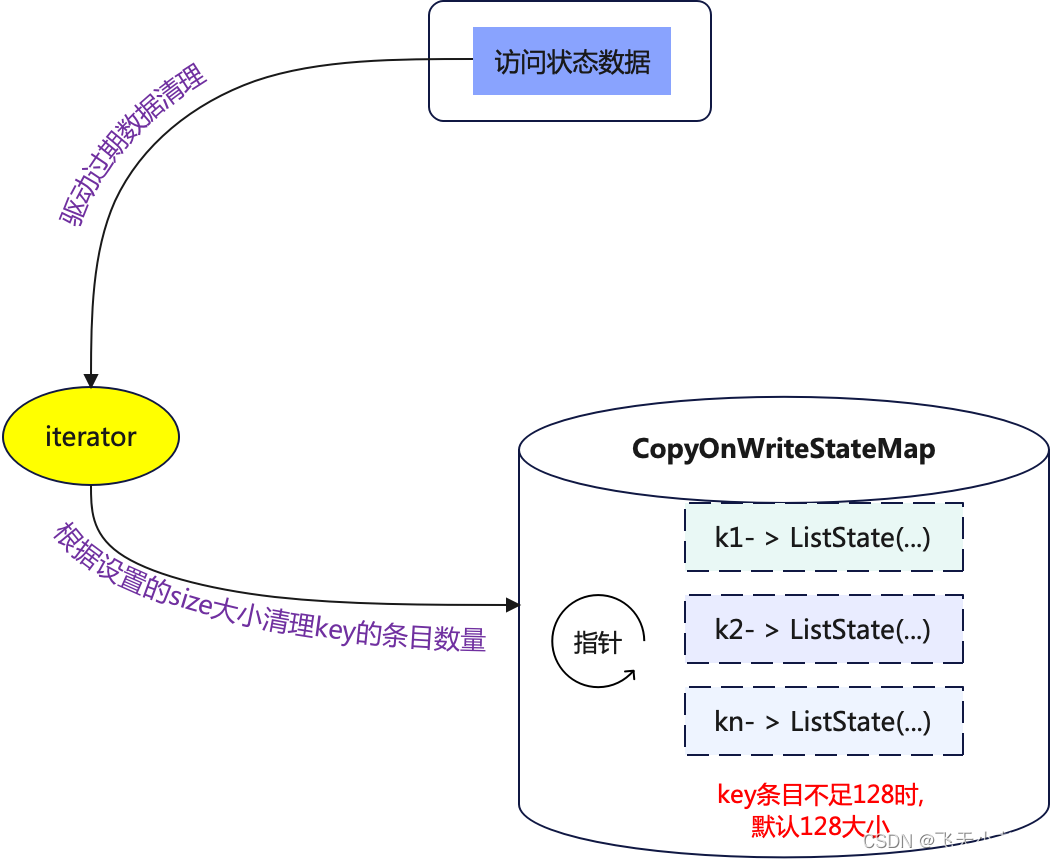
- 只要访问状态数据就会触发
cleanupIncrementally执行. - 如果用户没有设置
cleanupIncrementally,TTL会根据cleanupIncrementally(5, false)来删除过期数据,如果用户指定了参数则按照用户定义的参数删除数据. - 比如现在是
cleanupIncrementally(10, false),迭代器会从k1开始,到k10结束,将这10个条目的key中的ListState中的过期数据进行清理. CopyOnWriteStateMap中的数据存放是无序的,而且Flink在创建CopyOnWriteStateMap时候给的默认大小是128,也就说处理数据中key的数量超过128,否则就算只有一个key,CopyOnWriteStateMap的大小也是128,迭代器最少也要迭代128次.- 当设置
cleanupIncrementally(10, false)时,假如数据中只有一个key,那么这个k -> ListState(...)在CopyOnWriteStateMap中的存放位置是任意的,假设在CopyOnWriteStateMap中存放的位置是22,就会出现当第一次访问状态数据时,并不会删除这个key对应的ListState中的数据,访问状态数据时同样还是不会删除过期数据,只有第三次访问时,才会删除过期数据,因为cleanupSize设置的大小为10,迭代器每次只会迭代10个条目的key,每当访问状态数据时,迭代器都会从最后一次迭代的指针位置开始继续推进. - 当迭代器的指针推进位置到
128时,又会从0的位置从新开始推进(这里是指CopyOnWriteStateMap的大小是128),以此类推. - 如果
cleanupIncrementally(10, true)中的runCleanupForEveryRecord为true时,那就是说每次访问状态数据迭代器都会把CopyOnWriteStateMap中的所有条目都清理一遍,所以说为true时第一个参数(cleanupSize)会失效.
cleanupIncrementally的执行机制就很好的解释了,为什么在使用本地状态后端(HashMapStateBackend)时经常会出现明明已经来了7,8条数据,数据过期数据还没有清理到,或者距离上一次访问状态数据过了1h甚至更久都没有清理过期数据的情况.