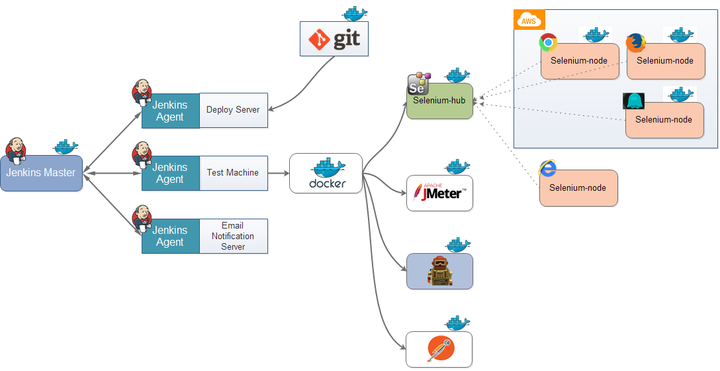
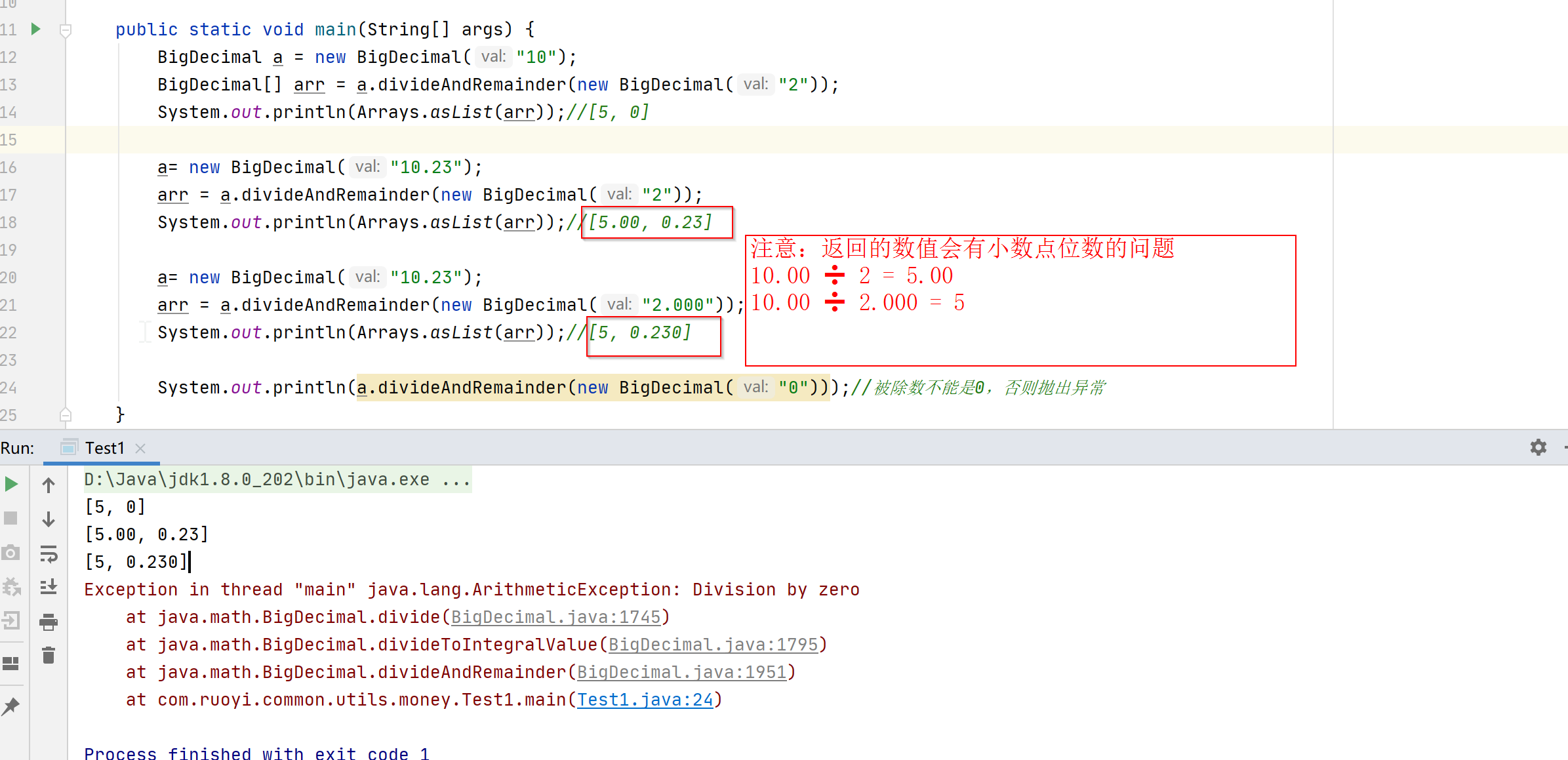
有文本串aabaabaaf,模式串aabaaf问文本串中是否出现过模式串
暴力解法
最不用动脑子的,直接两层for循环,逐个匹配,匹配到不相等的值时把文本串后移一位,再重新比较。这种方法的复杂度是O(m×n),该方法低效的原因在于重复比较次数过多,比如当比较到aabaa时发现此时的f与b不相符,又从头开始比较,但ff和b前有相同的aa,如果我们能直接从b开始比较是不是高效多了呢?由此产生了KMP算法。
KMP算法概述
KMP算法就是当模式串与文本串字符不等时,不移动至头部进行比较,比如f与b不匹配,跳至b进行比较,节约了前面相同aa的比较次数,尝试将比较过程直观展示如下:
逐个比较到f发现不匹配
a a b a a b a a f
| | | | | !=
a a b a a f
此时再从之前已知匹配的aa后面的b开始比较即可
a a b a a b a a f
| | | | | |
a a b a a f
那我们如何得知之前匹配的内容呢?这时就要引入前缀表的概念。
前缀表
a a b a a f
0 1 0 1 2 0
形如上表这样,比较到当前字符发现不匹配时,可由前一位对应的字符找到此时应跳转的位置,这样的表为前缀表,具体如何找到对应字符应跳转的位置,要先引入前后缀的概念。
前缀为包含首字母,不包含尾字母的所有字串;后缀为包含尾字母,不包含首字母的所有字串,以该模式串为例,其所有前缀和后缀为:
前缀:a aa aab aaba aabaa
后缀:f af aaf baaf abaaf
模式串不同字串对应的最长相等前后缀表格如下:
a aa aab aaba aabaa aabaaf
0 1 0 1 2 0
a a b a a f
当不匹配时找前一个字符最长相等前后缀即可,在编程中我们将其命名为next数组。
next数组代码示例
a a b a a f
j i
0
void getNext(next,s)//s为模式串{
j=0;next[0]=0;//初始化,i,j表示后前缀末尾指向位置
for(i=1;i<s.size();i++){//后缀指向1,第一个字符无后缀,故其最长相等前后缀为0
while(j>0&&s[i]!=s[j])//当前后缀不等时,j等于前一个字符对应的next数组位置
j=next[j-1];
if(s[i]==s[j]//前后缀相等时,j后移一位,i的后移在循环中实现
j++;
next[i]=j;}保存next数组
}
}
该代码实现了next数组即解决了如果当下不满足时该从何处比较的问题,也就是求出不同字符串下最长相等前后缀,方式是比较前后缀的最后一位来判定,那我想比较前后缀相同不是还要通过两个for循环来实现吗,为什么比较前后缀的最后一位就能判定两个不同的字符串最大相等前后缀长度呢?
当前后缀相等时我们很好理解,因为前面的相等已经判断过了,所以如果当下判定位置仍相等时,只需在上一次结果上+1即可;主要是当下判定位置不等时如何理解,执行步骤是向前遍历,直至找到与后缀字符相等的字符,并将前缀末尾指向之,想了半天又看了几遍实在不明白咋回事,贴两张图看看能不能理解吧,好像用到了动态规划的思想?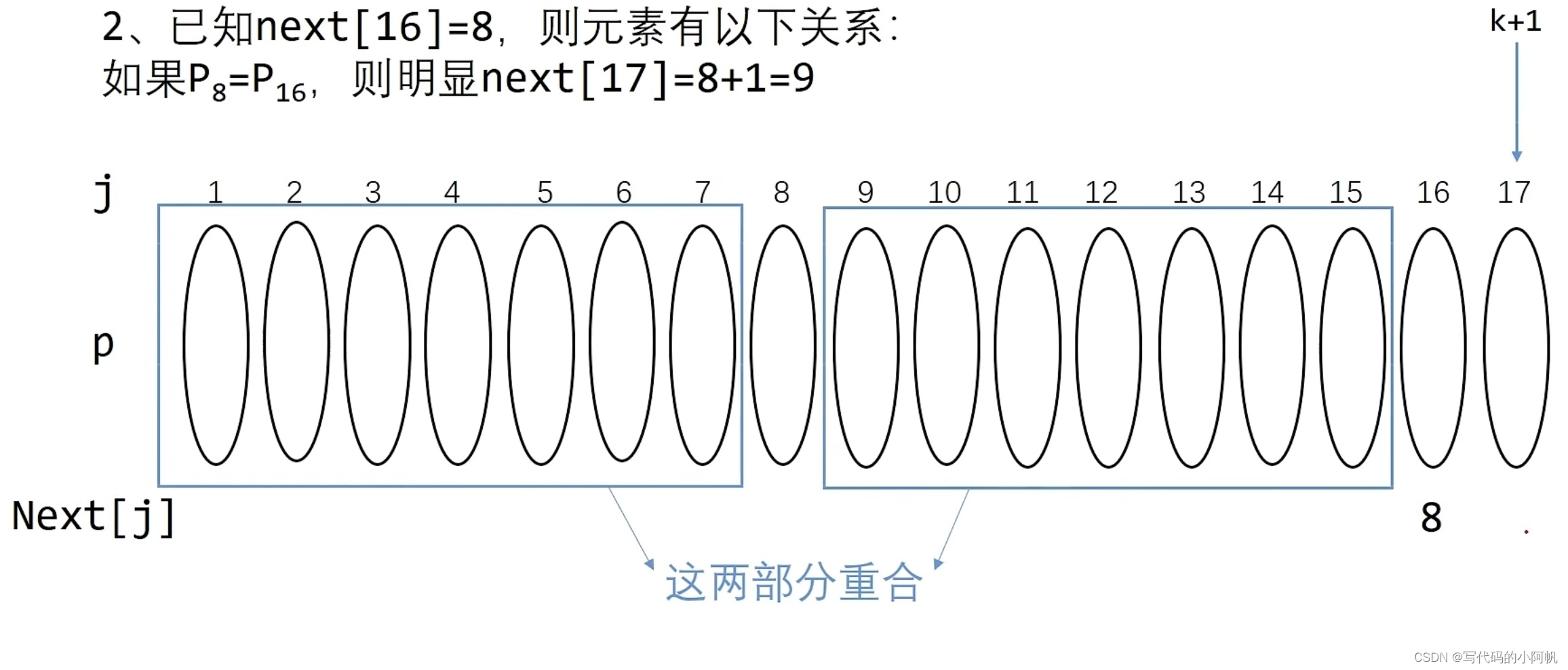

总结
KMP算法是用于比较字符串的一种高效算法,特点在于字符串只向前,模式串节约了重复部分的比较次数,实现通过next数组,但涉及next数组的求解人家有很巧妙的办法,五行代码就给搞定了,比我手算还简单,没有明白,暂时就到此为止吧。