接前文。
一步一步理解CPU芯片漏洞:Meltdown与Spectre
ARM系列之MMU TLB和ASID基础概念介绍。
一、Meltdown & Spectre 漏洞
Meltdown 和 Spectre 这两个漏洞厉害的地方就在于,利用现代CPU speculative execution (预测执行)的漏洞,在 rax 被清零之前把信息传递出去。Meltdown 的攻击代码(简化版):
mov rax byte[x] // 非法操作
shl rax 0xC // rax * 4096, page alignment
mov rbx qword [rbx + rax] // [rbx] 为用户空间的一个array,合法操作
攻击原理:
- 1、对于第一行mov代码,操作系统会事先标注好内核的内存地址范围,如果 x 在内核的这个地址范围内,并且 CPU 不是以内核模式运行的话,那么该指令会被 CPU 标注为非法,引起异常,异常处理程序会将 rax 清空为0,并且终结此程序,这样后续指令再来读 rax 的时候就只能读到0了。
- 2、理论上讲,在执行第二条指令之前,rax应该已经被清零了。然而在实际的 CPU 运行中,为了达到更好的性能,第二条和第三条指令在异常处理生效之前都会被部分执行,直到异常处理时 rax 和 rbx 被清零。目前看起来也没什么问题,因为rbx 也会被清零,关于 [x] 的任何信息都没有留下。
- 3、但问题的关键就在第三行指令:如果地址 rbx + rax 不在cache中的话,CPU 会自动将这一地址调入cache中,以便之后访问时获得更好的性能,然而异常处理并不会将这个cache flush掉。而这条 cache 的地址是和 rax 直接相关的,这样就相当于在 CPU 硬件中留下了和rax 相关的信息。
- 4、那么如何还原 rbx + rax 这个被cache的地址呢?这时候需要用到的原理就是利用cache的访问延时,即已经被cache的数据访问时间短,没有被cache的数据访问时间长。由于[rbx]这个array是在用户地址空间内的,可以自由操作,首先我们要确保整个 [rbx]这个array 都是没有被cache的,然后执行上述攻击代码,这时候 rbx + rax 这个地址就已经被cache了,接下来遍历整个[rbx] array,来测量访问时间,访问时间最短的那个 page 就可以确定为 rbx + rax。
二、KPTI补丁
KPTI补丁基于KAISER,它是一个用于缓解不太重要问题的早期补丁,当时业界还未了解到Meltdown的存在。
如果没有KPTI,每当执行用户空间代码(应用程序)时,Linux会在其分页表中保留整个内核内存的映射,并保护其访问。这样做的优点是当应用程序向内核发送系统调用或收到中断时,内核页表始终存在,可以避免绝大多数上下文切换相关的开销(TLB刷新、页表交换等)。
KPTI通过完全分离用户空间与内核空间页表来解决页表泄露。支持进程上下文标识符(PCID)特性的x86处理器可以用它来避免TLB刷新,但即便如此,它依然有很高的性能成本。据KAISER原作者称,其开销为0.28%[2];一名Linux开发者称大多数工作负载下测得约为5%,但即便有PCID优化,在某些情况下开销高达30%。[1]
使用内核启动选项“pti=off”可以部分禁用内核页表隔离。依规定也可对已修复漏洞的新款处理器禁用内核页表隔离[16]。

三、KPTI原理
3.1 页表隔离
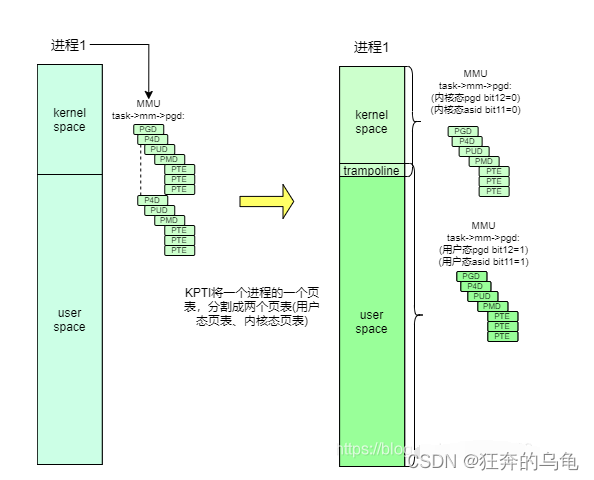
进程页表分割成用户态页表和内核态页表的具体方案是什么样的?
- 1、在运行userapplication 的时候,将kernel mapping 减少到最少,只保留必须的user到kernel的exception entry mapping. 其他的kernel mapping 在运行user application时都去掉,变成无效mapping,这样的话,如果user访问kernel data, 在MMU地址转换的时候就会被挡掉(因为无效mapping).
- 2、设计一个trampoline 的kernel PGD给运行user时用。Trampoline kernel mapping PGD只包含exception entry必需的mapping.
- 3、当user通过系统调用,或是timer或其他异常进入kernel是首先用trampoline的mapping,接下来tramponline的vector处理会将kernel mapping 换成正常的kernel mapping(SWAPPER_PGD_DIR), 并直接跳转到kernel原来的vector entry, 继续正常处理。我们把上述过程称之为map kernel mapping.
- 4、当从kernel返回到user时,正常的kernel_exit会调用trampoline的exit,tramp_exit会重新将kernel mapping 换成是trampoline. 这个过程叫unmap kernel mapping.
3.2 TLB刷新策略
TLB是页表的高速缓存,虚拟地址到物理地址转换都要经过TLB。
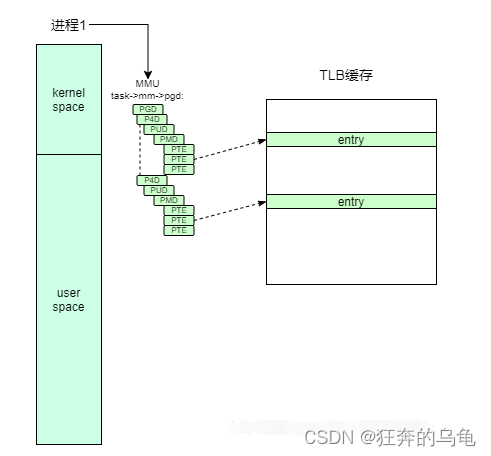
TLB刷新策略的发展史是这样的:
- 1、初始状态。操作系统中存在多个进程,每个进程都由自己虚拟地址空间。进程的虚拟地址空间时重叠的,如果存在多-份地址转换将出现混乱。那么在进程切换的时候,会进行TLB刷新,将旧进程的页表缓存无效。
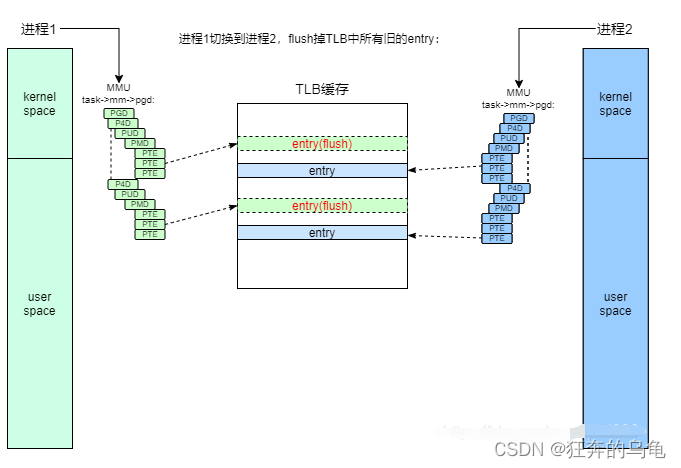
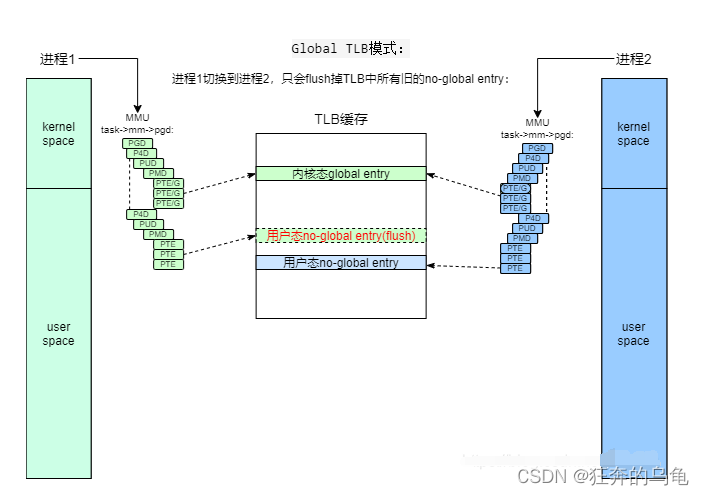
2、Global TLB和non-Global TLB。现代OS都将地址空间分为内核空间和用户空间,进程间的用户空间独立,内核空间一样。
为了性能,可以把内核态空间的页表设置G标志:
 这样这类页表被加载进TLB以后会变成Global TLB。这样在进程切换刷新TLB时,只会清理旧进程用户态的non-Global TLB,而不会清理旧进程内核态的Global TLB。这样新的进程会开始一个半新的TLB,效能提高不少:
这样这类页表被加载进TLB以后会变成Global TLB。这样在进程切换刷新TLB时,只会清理旧进程用户态的non-Global TLB,而不会清理旧进程内核态的Global TLB。这样新的进程会开始一个半新的TLB,效能提高不少:
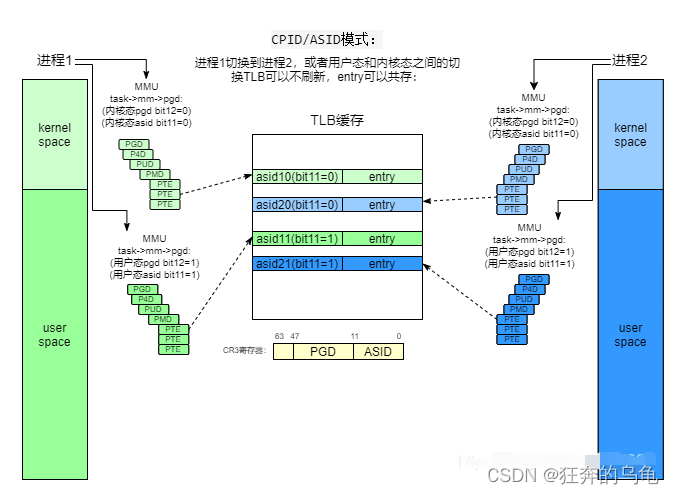
- 3、PCID(Process-Context Identifiers)和ASID(Address-Space Identifier)。
在kpti出现以后对TLB有了两个新的需求:
1、内核空间不能设置成全局,因为这样就没有隔离的效果了。
2、内核态和用户态的切换就会引起页表切换,这种场景下要求TLB不要刷新,因为如果刷新就会带来非常大的性能开销,但是不刷新又怎么做到页表隔离呢?
针对上述的需求,诞生了新的TLB机制PCID/ASID。每一个进程在运行时,都会动态分配一个pcid/asid,如果进程切换到本进程开始运行,把对应的pcid/asid配置到cr3中:
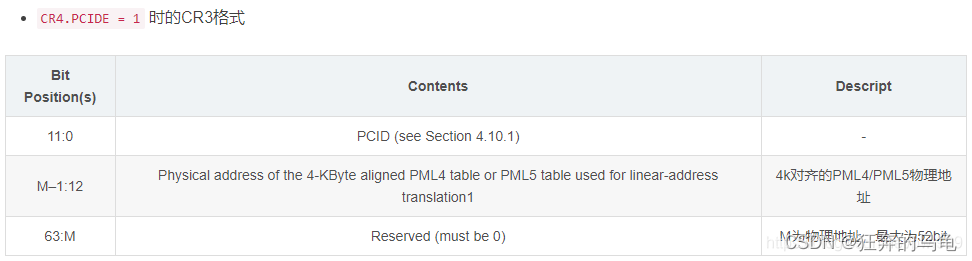
在进程运行过程中,根据本进程的pgd产生的页表转换关系会缓存到TLB中,所有产生的TLB条目会根据当前cr3中的pcid/asid打上标签。TLB条目有了标签以后,页表切换就不需要去刷新旧的条目了,因为当前cpu只会认和当前cr3中asid相同的TLB条目,这样TLB就不用频繁的去刷新,且相互之间也是隔离的。