简介
作为数据库管理员(DBA),定期进行数据库的日常巡检是非常重要的。以下是一些原因:
保证系统的稳定性:通过定期巡检,DBA可以发现并及时解决可能导致系统不稳定的问题,如性能瓶颈、资源利用率过高或磁盘空间不足等。
提高数据的安全性:巡检可以帮助DBA发现潜在的安全风险,例如未经授权的访问、数据泄露或其他安全漏洞。及时采取措施,可以防止这些风险演变成实际问题。
避免数据丢失:DBA可以通过检查备份和恢复策略来确保数据的完整性,并确保在发生灾难时能够快速恢复业务运营。
确保合规性:许多行业都有特定的数据管理规定和法规要求。通过巡检,DBA可以确保他们的数据库管理系统符合这些规定和要求。
性能优化:巡检可以帮助DBA识别性能瓶颈,从而优化数据库以提高其效率和响应速度。
资源规划:通过巡检,DBA可以了解当前的资源使用情况,预测未来的资源需求,并根据需要调整资源配置。
综上所述,DBA的日常巡检是保持数据库健康运行的关键环节之一,也是确保业务连续性和高效运行的重要步骤。
28、查看闪回区\快速恢复区空间使用率
select sum(percent_space_used) || '%' "已使用空间比例"
from V$RECOVERY_AREA_USAGE
一、闪回区(Flashback Area):
闪回区是一个由 Oracle 数据库管理的特殊区域,用于存储数据库中的旧数据和相关的元数据。它可以被用于执行闪回查询(Flashback Query)和闪回版本查询(Flashback Version Query),从而可以按时间点恢复数据库对象的旧版本或检索已删除或修改的数据。闪回区是通过配置 DB_FLASHBACK_RETENTION_TARGET 参数来控制保留的时间范围。通常情况下,它的大小是自动管理的,它会根据需要自动增长或缩小。
二、快速恢复区(Fast Recovery Area):
快速恢复区是一个用于存储备份、恢复和日志文件的目录。它是为了简化数据库备份和恢复操作而引入的一个特殊目录。通过配置 DB_RECOVERY_FILE_DEST 参数指定快速恢复区的位置。在数据库运行期间,数据库会自动将备份和归档日志文件保存在快速恢复区中。快速恢复区还会自动管理和清理过期的备份和日志文件,以避免占用过多的磁盘空间。
29、查看僵死进程,分两种
alter system kill session一执行则session即标记为KILLED,但是如果会话产生的数据量大则这个kill可能会比较久,在这个过程中session标记为KILLED但是这个会话还在V$session中,则V$session.paddr还在,所以可以匹配到V$process.addr,所以process进程还在;当kill过程执行完毕,则这个会话即不在V$session中
会话不在的
select * from v$process where addr not in (select paddr from v$session) and pid not in (1,17,18) 会话还在的,但是会话标记为killed
select * from v$process where addr in (select paddr from v$session where status='KILLED')再根据上述结果中的SPID通过如下命令可以查看到process的启动时间
ps auxw|head -1;ps auxw|grep SPID
这些进程的 PID(Process ID)通常是固定的:
- PID 1 通常是 PMON(Process Monitor)进程,它负责清理失败的用户进程,释放它们占用的资源。
- PID 17 通常是 QMN0(Queue Monitor)进程,它负责处理 Oracle 的队列消息。
- PID 18 通常是 LCK0(Lock)进程,它负责处理分布式锁。
这些背景进程是 Oracle 数据库正常运行所必需的,它们不会关联到任何用户会话,所以在 v$session 视图中没有对应的行。
30、查看行迁移或行链接的表
select * From dba_tables where nvl(chain_cnt,0)<>0chain_cnt:表中从一个数据块链接到另一个数据块或已迁移到新块的行数,需要链接以保留旧的 rowid。此列仅在分析表后更新。
31、数据缓冲区命中率
一、
SELECT a.VALUE+b.VALUE logical_reads, c.VALUE phys_reads,
round(100*(1-c.value/(a.value+b.value)),2)||'%' hit_ratio
FROM v$sysstat a,v$sysstat b,v$sysstat c
WHERE a.NAME='db block gets'
AND b.NAME='consistent gets'
AND c.NAME='physical reads';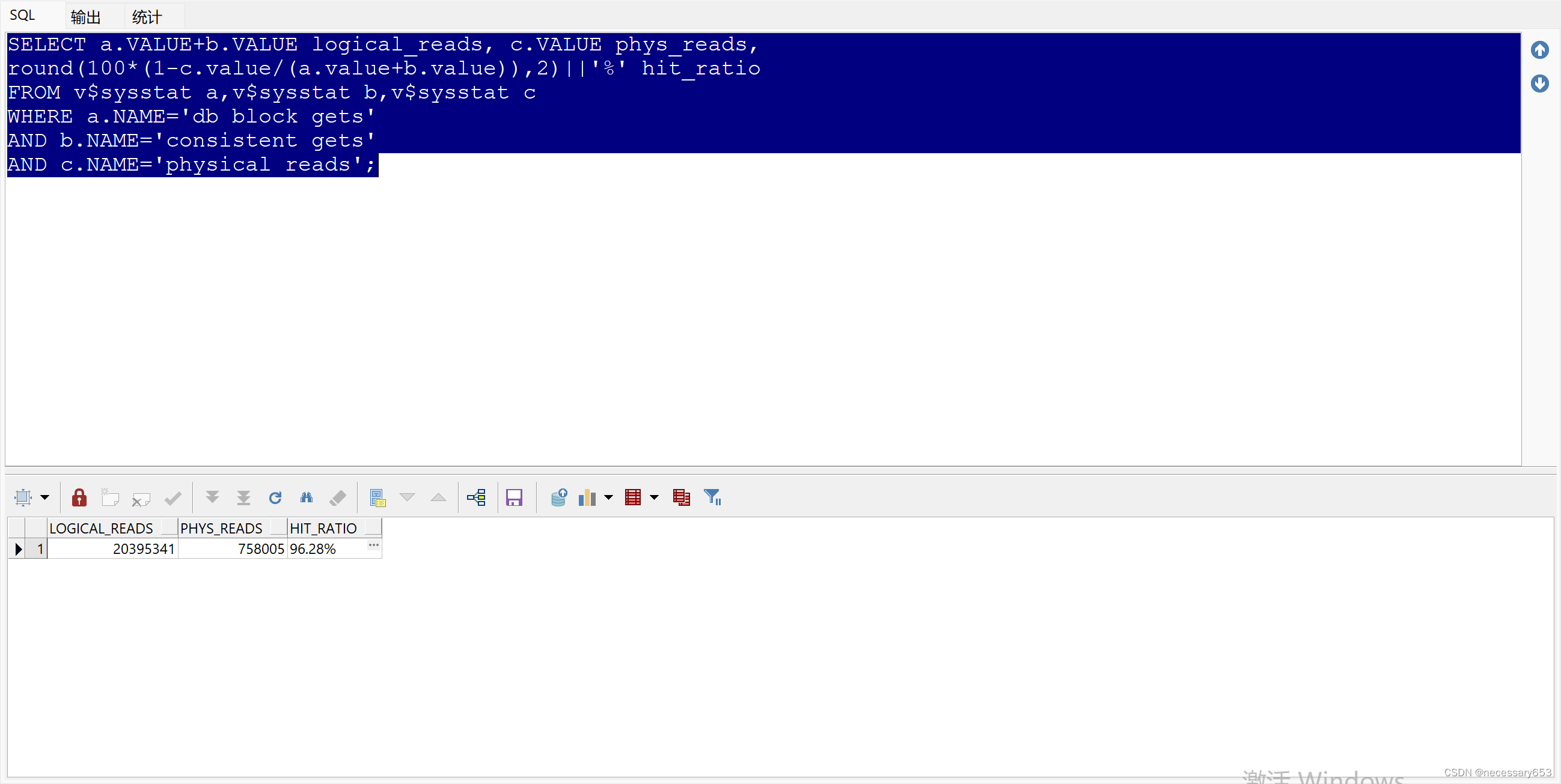
用于获取数据库中逻辑读和物理读的统计信息,并计算命中率
a.VALUE+b.VALUE logical_reads: 这一部分从v$sysstat表中选择a.VALUE和b.VALUE,并将它们相加,表示逻辑读的总数。逻辑读是指数据库在处理查询时,从内存中的数据块获取信息,而不是从磁盘读取。
c.VALUE phys_reads: 这一部分从v$sysstat表中选择c.VALUE,表示物理读的总数。物理读是指数据库在处理查询时,从磁盘读取数据块。
round(100*(1-c.value/(a.value+b.value)),2)||'%' hit_ratio: 这一部分计算了命中率,并将其四舍五入到小数点后两位。命中率是衡量数据库查询在内存中成功找到所需数据块的比例。公式为:命中率 = (1 - (物理读数 / (逻辑读数 + 物理读数))) * 100%。
逻辑读和物理读的次数。
命中率,这是一个重要的性能指标,可以衡量数据库在内存中成功找到所需数据块的比例。如果命中率接近100%,则说明数据库查询大部分时间在内存中查找所需数据,而不是从磁盘读取。这通常是一个积极的迹象,表明数据库的性能良好。如果命中率较低,则可能需要分析原因并进行优化,例如增加内存、优化数据库结构或查询语句等。
二、
SELECT DB_BLOCK_GETS + CONSISTENT_GETS Logical_reads,
PHYSICAL_READS phys_reads,
round(100 *
(1 - (PHYSICAL_READS / (DB_BLOCK_GETS + CONSISTENT_GETS))),
2) || '%' "Hit Ratio"
FROM V$BUFFER_POOL_STATISTICS
WHERE NAME = 'DEFAULT';
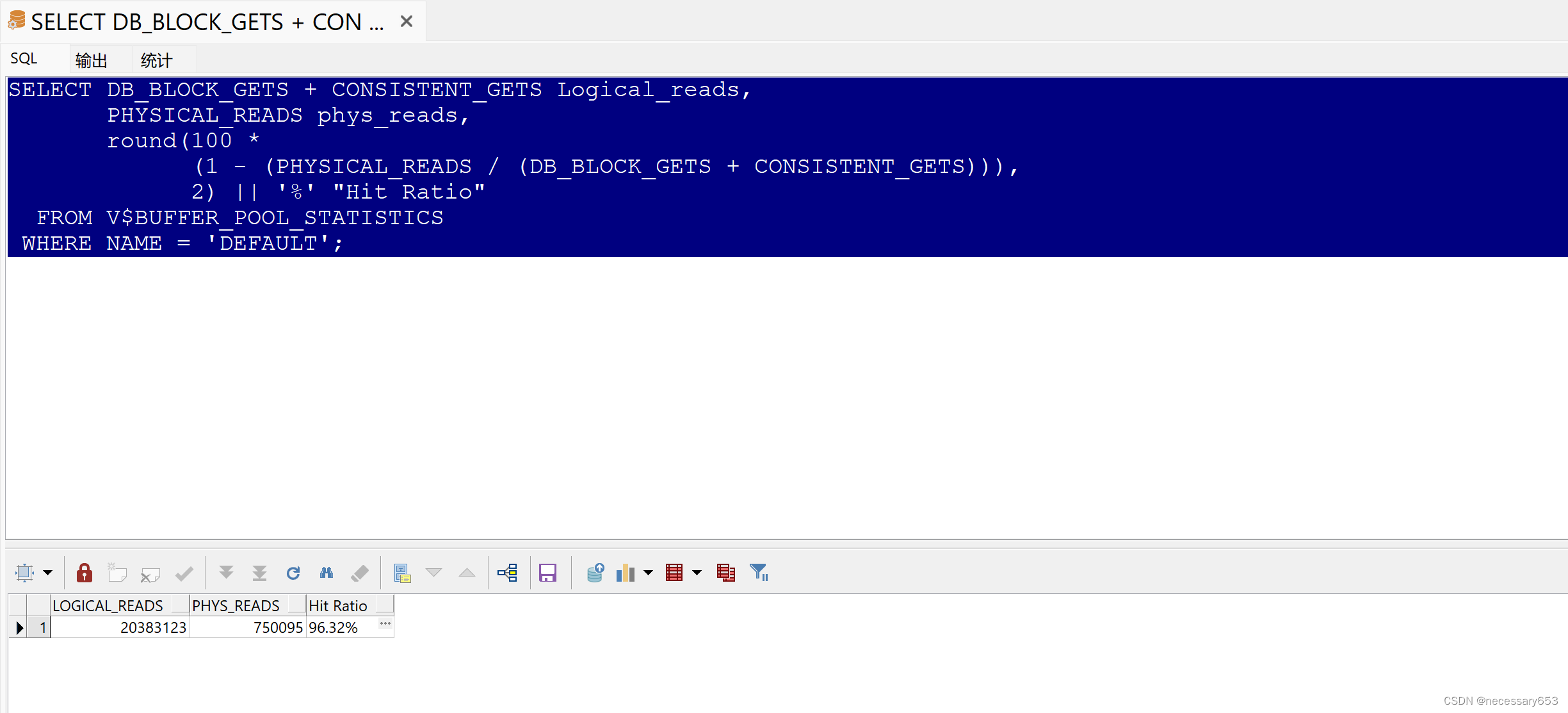
在Oracle数据库中查询关于缓冲池的统计信息。缓冲池是数据库中存储数据块的地方,这些数据块包含数据库中的数据和相关的索引。这个查询返回了关于缓冲池的三个主要信息:逻辑读、物理读以及命中率。
DB_BLOCK_GETS:这是从数据库缓冲池获取数据块的逻辑操作。当数据库需要访问某个数据块,但该数据块不在缓冲池中时,就会发生这种操作。
CONSISTENT_GETS:这是一致性读获取的次数。一致性读是当数据库需要读取一个数据块,但该数据块在内存中已被其他会话修改过,此时就需要从磁盘读取这个数据块,并把这个操作称为一致性读。
LOGICAL_READS:这是上述两个操作的累加和,表示从数据库缓冲池获取数据块的逻辑操作的总数。
PHYSICAL_READS:这是从磁盘读取数据块的物理操作的总数。当数据块在内存中找不到,需要从磁盘读取时,就会发生这种操作。
Hit Ratio:这是命中率,它表示了内存(缓冲池)中访问数据块的效率。命中率越高,表示大部分数据访问都在内存中完成,不需要从磁盘读取,这通常是数据库性能良好的标志。
如果逻辑读和物理读的次数非常高,那么可能需要对数据库进行优化,比如增加内存、调整数据库的参数等。同时,命中率的计算也可以帮助了解内存的使用效率,如果命中率很低,那么可能需要增加内存或者调整数据库的结构和查询语句等来提高性能。
32、共享池命中率
select sum(pinhits)/sum(pins)*100 from v$librarycache;
--两者语句均可实现
select sum(pinhits-reloads)/sum(pins)*100 from v$librarycache;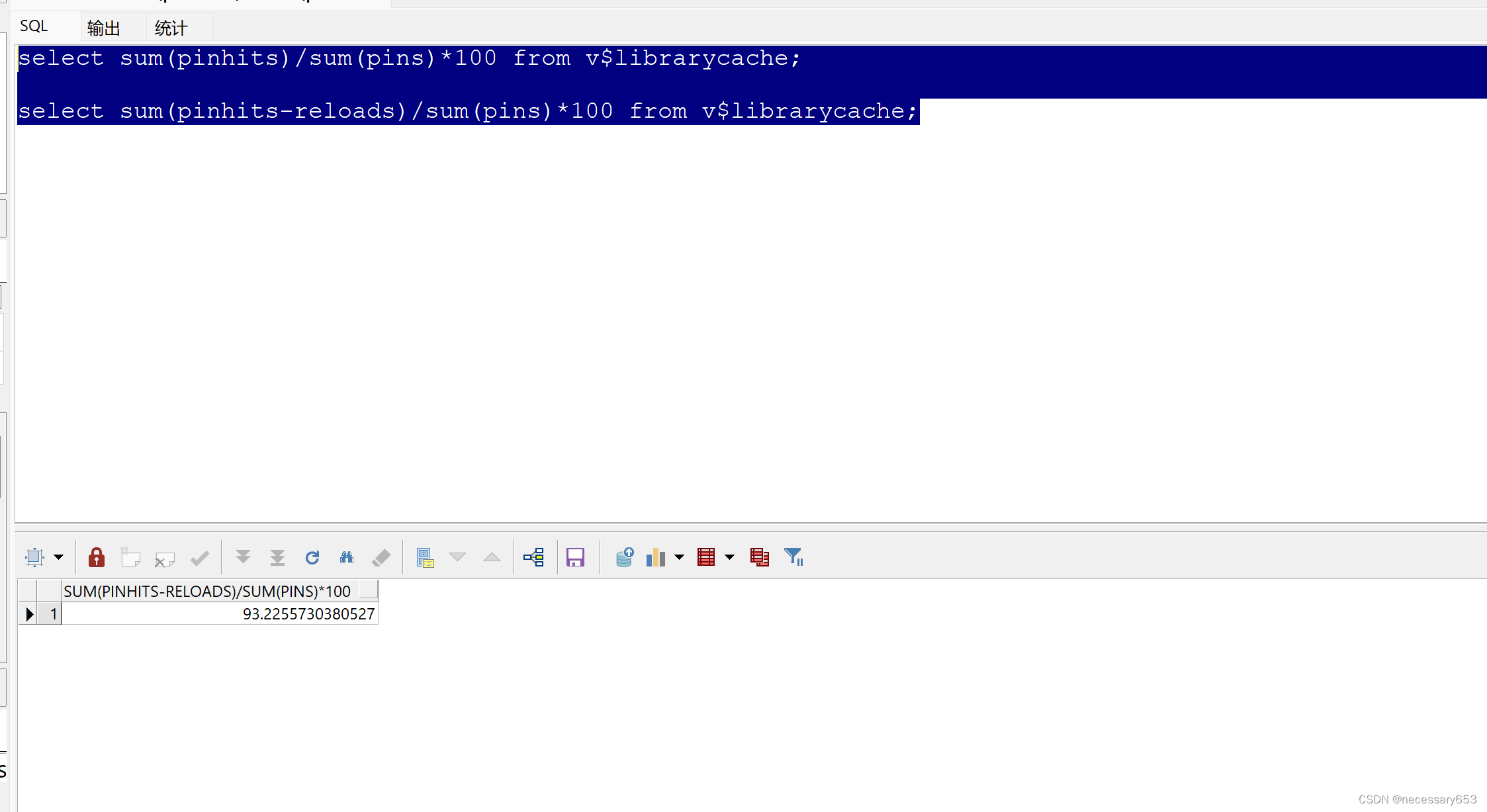
33、查询归档日志切换频率
一、
select sequence#,
to_char(first_time, 'yyyymmdd_hh24:mi:ss') firsttime,
round((first_time - lag(first_time) over(order by first_time)) * 24 * 60,
2) minutes
from v$log_history
where first_time > sysdate - 3
order by first_time, minutes;
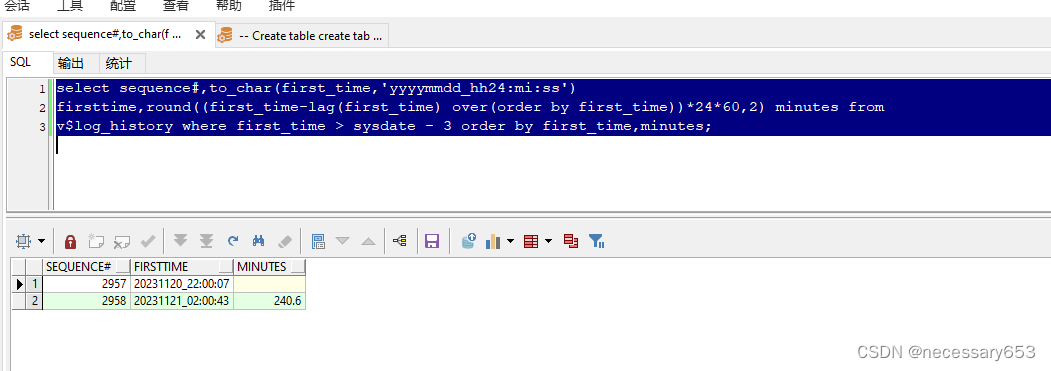
sequence#:这是该记录在 v$log_history 中的序列号。
to_char(first_time, 'yyyymmdd_hh24:mi:ss') firsttime:这将 first_time 字段转换为字符串,格式为 '年月日_时:分:秒',并将其命名为 firsttime。
round((first_time - lag(first_time) over(order by first_time)) * 24 * 60, 2) minutes:这部分比较复杂。它首先使用 lag() 函数获取前一条记录的 first_time 值,然后计算当前记录的 first_time 与前一条记录的 first_time 的时间差(以分钟为单位),并将这个时间差乘以 24(因为每小时有 24 分钟)再乘以 60(因为每小时有 60 分钟),从而得到时间差(以小时为单位),最后四舍五入到小数点后两位,并将结果命名为 minutes。
这个查询从 v$log_history 视图中获取了过去三天内的记录,并显示了每条记录的序列号、时间戳以及与前一条记录的时间差(以小时为单位)。这样的信息可以用来分析数据库的重做日志活动,例如找出何时进行了大量的重做操作或者何时日志活动最为频繁等。
二、
select sequence#,
to_char(first_time, 'yyyy-mm-dd hh24:mi:ss') First_time,
First_change#,
switch_change#
from v$loghist
where first_time > sysdate - 3
order by 1;
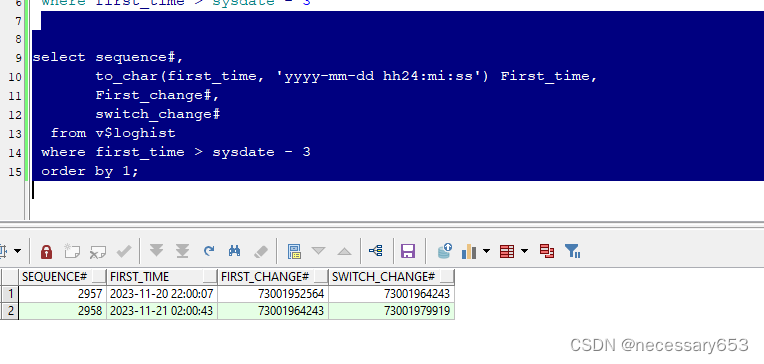
从Oracle数据库的v$loghist视图中查询数据。下面我会解释每个字段的含义:
sequence#: 这是在v$loghist中的记录序列号,可以看作是每条记录的唯一标识。
to_char(first_time, 'yyyy-mm-dd hh24:mi:ss') First_time: 这条是将first_time字段转换为字符串格式,显示为'年-月-日 时:分:秒',并将这个列命名为First_time。
First_change#: 这个字段的含义可能会因数据库的上下文而异,一般来说,可能表示首次更改的序号或ID。
switch_change#: 这个字段的含义也可能因数据库的上下文而异,可能表示切换更改的序号或ID。
主要用于分析在过去的三天内数据库的重做日志历史记录。
34、查询lgwr进程写日志时每执行一次lgwr需要多少秒,
在state是waiting的情况下,某个等待编号seq#下,seconds_in_wait达多少秒,就是lgwr进程写一次IO需要多少秒
select event, state, seq#, seconds_in_wait, program
from v$session
where program like '%LGWR%'
and state = 'WAITING'
event: 这个字段表示会话当前正在等待的事件。例如,它可能正在等待一个锁,或者正在等待数据库响应等。
state: 这个字段表示会话的状态。在这个查询中,我们只选取了状态为'WAITING'的会话,也就是正在等待的会话。
seq#: 这个字段表示会话在Oracle实例中的序列号。
seconds_in_wait: 这个字段表示会话在等待中已经等待的秒数。
program: 这个字段表示会话正在运行的程序。在这个查询中,我们只选取了程序名包含'LGWR'的会话,也就是正在运行的程序包含'LGWR'的会话。
这个查询的结果集将包含所有满足以下条件的会话的信息:程序名包含'LGWR',并且正在等待。这些信息可以帮助确定哪些会话正在等待,以及它们等待了多长时间等。
35、查询没有索引的表
Select *
from user_tables
where table_name not in (select table_name from user_indexes);
--或者使用以下
Select table_name
from user_tables
where table_name not in (select table_name from user_ind_columns);
USER_INDEXES视图提供了有关当前用户所创建的索引的整体信息,而USER_IND_COLUMNS视图提供了更详细的索引列信息。这两个视图都是用于监视和管理数据库对象的工具,
36、查询7天的db time
--37、查询7天的db time
WITH sysstat AS
(select sn.begin_interval_time begin_interval_time,
sn.end_interval_time end_interval_time,
ss.stat_name stat_name,
ss.value e_value,
lag(ss.value, 1) over(order by ss.snap_id) b_value
from dba_hist_sysstat ss, dba_hist_snapshot sn
where trunc(sn.begin_interval_time) >= sysdate - 7
and ss.snap_id = sn.snap_id
and ss.dbid = sn.dbid
and ss.instance_number = sn.instance_number
and ss.dbid = (select dbid from v$database)
and ss.instance_number = (select instance_number from v$instance)
and ss.stat_name = 'DB time')
select to_char(BEGIN_INTERVAL_TIME, 'mm-dd hh24:mi') ||
to_char(END_INTERVAL_TIME, ' hh24:mi') date_time,
stat_name,
round((e_value - nvl(b_value, 0)) /
(extract(day from(end_interval_time - begin_interval_time)) * 24 * 60 * 60 +
extract(hour from(end_interval_time - begin_interval_time)) * 60 * 60 +
extract(minute from(end_interval_time - begin_interval_time)) * 60 +
extract(second from(end_interval_time - begin_interval_time))),
0) per_sec
from sysstat
where (e_value - nvl(b_value, 0)) > 0
and nvl(b_value, 0) > 0
Oracle 的性能视图 dba_hist_sysstat 和 dba_hist_snapshot 中查询数据库的 "DB time" 统计信息。"DB time" 是 Oracle 数据库中一个非常重要的性能指标,它表示在某个时间段内,所有活动的会话在数据库中消耗的总时间。
- date_time:这是一个时间段,表示 "DB time" 的统计信息是在这个时间段内收集的。它由 BEGIN_INTERVAL_TIME 和 END_INTERVAL_TIME 两个字段拼接而成,BEGIN_INTERVAL_TIME 是时间段的开始时间,END_INTERVAL_TIME 是时间段的结束时间。
- stat_name:这是统计信息的名称,在这个查询中,它的值总是 "DB time"。
- per_sec:这是每秒的 "DB time"。它是在指定的时间段内,"DB time" 的增量除以时间段的长度(以秒为单位)得到的。如果 "DB time" 在这个时间段内没有增加,那么 per_sec 的值就是 0。
这个结果集在 Oracle 数据库中是用来监控数据库的性能。通过查看 "DB time" 的变化,你可以了解数据库的负载是否在增加或减少,这对于数据库的性能调优和故障排查是非常有用的。
37、查询产生热块较多的对象
x$bh .tch表示访问次数越高,热点快竞争问题就存在
SELECT e.owner, e.segment_name, e.segment_type
FROM dba_extents e,
(SELECT *
FROM (SELECT addr,ts#,file#,dbarfil,dbablk,tch
FROM x$bh
ORDER BY tch DESC)
WHERE ROWNUM < 11) b
WHERE e.relative_fno = b.dbarfil
AND e.block_id <= b.dbablk
AND e.block_id + e.blocks > b.dbablk; Oracle 的 dba_extents 视图和 x$bh 内部表中查询信息。dba_extents 视图提供了数据库中所有段的扩展信息,x$bh 内部表提供了数据库的缓冲池中的块信息。
- e.owner:这是段的所有者,也就是拥有这个段的用户的名称。
- e.segment_name:这是段的名称。
- e.segment_type:这是段的类型,例如 "TABLE", "INDEX" 等。
这个查询的目的是找出数据库缓冲池中最热的(被访问次数最多的)10个块所属的段。这对于了解数据库的访问模式和优化数据库的性能是非常有用的。如果一个表或索引的块被频繁地访问,那么可能需要考虑对这个表或索引进行优化,例如重新组织表,重建索引,或者调整缓冲池的大小。
38、导出AWR报告的SQL语句
--根据以下语句查询DBID, INSTANCE_NUMBER, startsnapid,endsnapid, DBID, INSTANCE_NUMBER, startsnapid,endsnapid字段需要指定的对应的值
select * from dba_hist_snapshot;
select * from table(dbms_workload_repository.awr_report_html(DBID, INSTANCE_NUMBER, startsnapid,endsnapid))
select * from TABLE(DBMS_WORKLOAD_REPOSITORY.awr_diff_report_html(DBID, INSTANCE_NUMBER, startsnapid,endsnapid, DBID, INSTANCE_NUMBER, startsnapid,endsnapid));AWR(Automatic Workload Repository)报告在Oracle数据库中非常重要,它是一个自动负载信息库,是Oracle 10g以后版本提供的一种性能收集和分析工具。AWR报告能提供一个时间段内整个系统资源使用情况的报告,通过报告可以了解一个系统的整个运行情况。
AWR每小时对v$active v$session v$history视图(内存中的ASH采集信息,理论为1小时)进行采样一次,并将信息保存到磁盘中,并且保留7天,7天后旧的记录才会被覆盖。这些采样信息被保存在wrh_active_session_history视图(写入AWR库中的ASH信息,理论为1小时以上)中。
AWR报告可以提供关于数据库性能的各种详细信息,包括CPU使用情况、内存使用情况、磁盘I/O、网络I/O等。这些信息可以帮助数据库管理员更好地理解数据库的性能表现,发现性能瓶颈,并采取适当的措施来优化和提升数据库的性能。
另外,AWR报告还可以在问题发生后进行故障排查和问题解决。如果数据库性能出现下降或其他问题,可以通过查看AWR报告来了解问题发生时系统的运行情况,从而更好地定位问题的原因。
40、查询某个SQL的执行计划
--通过以下查询语句,获取对应sql的hash_value
select a.hash_value,a.* from v$sql a where sql_id='&指定的SQL_id'
--讲以上查询语句的对应hash_value,填入到下列语句中,'advanced'代表高级信息
select * from table(dbms_xplan.display_cursor(v$sql.hash_value,0,'advanced'));
select * from table(xplan.display_cursor('v$sql.sql_id',0,'advanced'));
--不过要先创建xplan包,再执行
SQL> CREATE PUBLIC SYNONYM XPLAN FOR SYS.XPLAN;
SQL> grant execute on sys.xplan to public;DBMS_XPLAN.DISPLAY_CURSOR 是一个函数,它返回一个表,表中的每一行都是执行计划的一部分。这个函数有三个参数:
- 第一个参数是 SQL 语句的哈希值或 SQL ID。在第一段代码中,它是 v$sql.hash_value,在第二段代码中,它是 'v$sql.sql_id'。
- 第二个参数是子游标的编号。在这两段代码中,它都是 0,表示主游标。
- 第三个参数是格式选项。在这两段代码中,它都是 'advanced',表示显示高级信息,包括优化器的成本、字节、基数等。
结果集中的每一行都是执行计划的一部分,包括操作的类型(例如 "TABLE ACCESS FULL", "INDEX RANGE SCAN" 等)、操作的对象(例如表名或索引名)、操作的成本和基数等信息。
这个结果集在 Oracle 数据库中的作用是用来优化 SQL 语句的性能。通过查看执行计划,你可以了解 Oracle 数据库是如何执行 SQL 语句的,从而找出性能瓶颈,优化 SQL 语句或数据库结构。