当大家面临着复杂的数学建模问题时,你是否曾经感到茫然无措?作为2022年美国大学生数学建模比赛的O奖得主,我为大家提供了一套优秀的解题思路,让你轻松应对各种难题。

问题一
为了分析中国新能源电动汽车发展的主要因素,我们建立一个综合性的数学模型,
多元分析是一种用于研究多个自变量对因变量的联合影响的统计方法。
多元线性回归模型:
多元线性回归模型用于描述多个自变量对一个因变量的联合影响。在这里,我们用该模型来分析影响新能源电动汽车销售量的各个因素:
Y = β 0 + β 1 X 政策 + β 2 X 经济 + β 3 X 技术 + β 4 X 环保 + β 5 X 油价 + ϵ Y = \beta_0 + \beta_1X_{政策} + \beta_2X_{经济} + \beta_3X_{技术} + \beta_4X_{环保} + \beta_5X_{油价} + \epsilon Y=β0+β1X政策+β2X经济+β3X技术+β4X环保+β5X油价+ϵ
- Y Y Y:新能源电动汽车销售量或市场份额。
- β 0 \beta_0 β0:截距。
- β 1 , β 2 , β 3 , β 4 , β 5 \beta_1, \beta_2, \beta_3, \beta_4, \beta_5 β1,β2,β3,β4,β5:各自变量的系数。
- X 政策 , X 经济 , X 技术 , X 环保 , X 油价 X_{政策}, X_{经济}, X_{技术}, X_{环保}, X_{油价} X政策,X经济,X技术,X环保,X油价:官方政策、经济指标、技术创新、环保意识和油价变动。
- ϵ \epsilon ϵ:误差项。
方差分析:
方差分析用于比较多个组之间的平均差异是否显著。在这里,我们可以使用方差分析来确定各个因素是否在统计上显著地影响新能源电动汽车销售量或市场份额。
H
0
:
各组平均值相等
H_0: \text{各组平均值相等}
H0:各组平均值相等
H
1
:
至少有一个组的平均值不同
H_1: \text{至少有一个组的平均值不同}
H1:至少有一个组的平均值不同
主成分分析:
主成分分析用于找到数据中的主要变量,以降低维度。对于新能源电动汽车发展的因素,可以通过主成分分析找到最重要的自变量。
Z i = α 1 X 1 i + α 2 X 2 i + … + α k X k i Z_i = \alpha_1X_{1i} + \alpha_2X_{2i} + \ldots + \alpha_kX_{ki} Zi=α1X1i+α2X2i+…+αkXki
其中, Z i Z_i Zi 是第 i i i 个主成分, X 1 i , X 2 i , … , X k i X_{1i}, X_{2i}, \ldots, X_{ki} X1i,X2i,…,Xki 是原始变量, α 1 , α 2 , … , α k \alpha_1, \alpha_2, \ldots, \alpha_k α1,α2,…,αk 是主成分系数。
判别分析:
判别分析用于确定哪些因素最能有效地区分不同水平的因变量。在这里,我们可以使用判别分析来了解哪些因素对于在市场中脱颖而出是最关键的。
$ D = \beta_0 + \beta_1X_{政策} + \beta_2X_{经济} + \beta_3X_{技术} + \beta_4X_{环保} + \beta_5X_{油价} $
其中, D D D 是判别分数。
路径分析:
路径分析用于理解各个因素之间的直接和间接关系。在这里,我们可以使用路径分析来揭示影响新能源电动汽车销售量的路径。
Y = γ 0 + γ 1 X 政策 + γ 2 X 经济 + γ 3 X 技术 + γ 4 X 环保 + γ 5 X 油价 + ϵ Y = \gamma_0 + \gamma_1X_{政策} + \gamma_2X_{经济} + \gamma_3X_{技术} + \gamma_4X_{环保} + \gamma_5X_{油价} + \epsilon Y=γ0+γ1X政策+γ2X经济+γ3X技术+γ4X环保+γ5X油价+ϵ
X 政策 = α 0 + α 1 X 经济 + α 2 X 技术 + α 3 X 环保 + α 4 X 油价 + ϵ 1 X_{政策} = \alpha_0 + \alpha_1X_{经济} + \alpha_2X_{技术} + \alpha_3X_{环保} + \alpha_4X_{油价} + \epsilon_1 X政策=α0+α1X经济+α2X技术+α3X环保+α4X油价+ϵ1
X 经济 = β 0 + β 1 X 技术 + β 2 X 环保 + β 3 X 油价 + ϵ 2 X_{经济} = \beta_0 + \beta_1X_{技术} + \beta_2X_{环保} + \beta_3X_{油价} + \epsilon_2 X经济=β0+β1X技术+β2X环保+β3X油价+ϵ2
⋮ \vdots ⋮
其中, γ 0 , γ 1 , … , γ 5 \gamma_0, \gamma_1, \ldots, \gamma_5 γ0,γ1,…,γ5、 α 0 , α 1 , … , α 4 \alpha_0, \alpha_1, \ldots, \alpha_4 α0,α1,…,α4、 β 0 , β 1 , … , β 3 \beta_0, \beta_1, \ldots, \beta_3 β0,β1,…,β3 是路径系数。
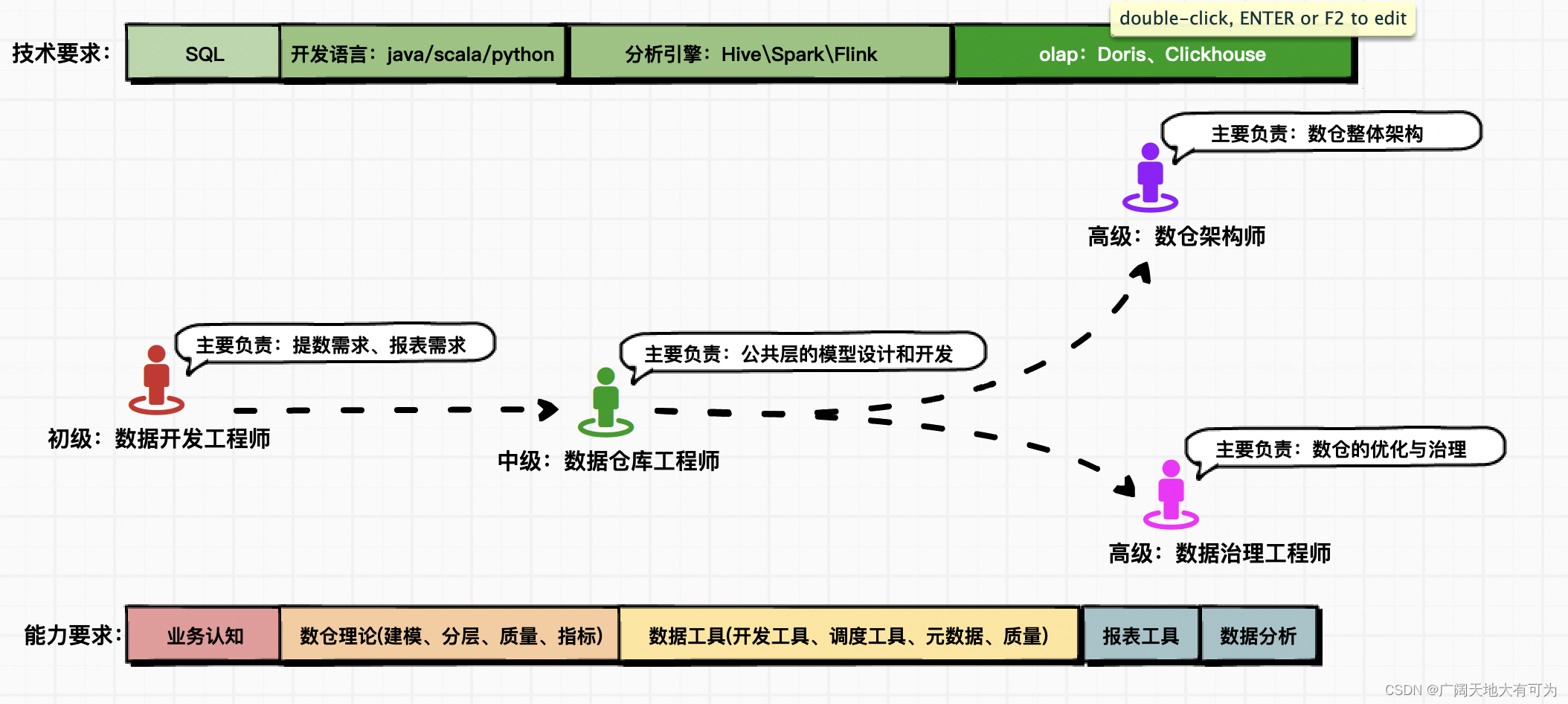
这个模型提供了一个系统的框架,能够帮助官方、产业界和研究机构更深入地理解和评估各种因素对中国新能源电动汽车发展的影响。
问题2
数据收集:
- 历史数据: 收集过去10年的新能源电动汽车销售量、市场份额、官方政策变化、经济指标、技术进步等数据。
- 行业报告: 查阅行业报告,了解当前市场趋势、技术创新和竞争格局。
- 官方发布的数据: 官方机构通常会发布有关新能源汽车销售和产业发展的数据。另外一些大企业也同样会提供相应的数据信息
- 环保和能源政策: 收集有关环保和能源政策的信息,包括可能影响新能源汽车市场的政策。
模型建立:
建立一个时间序列分析模型,以预测未来10年新能源电动汽车的发展,使用以下数学模型:
Y t = β 0 + β 1 X 1 t + β 2 X 2 t + … + β k X k t + ϵ t Y_t = \beta_0 + \beta_1X_{1t} + \beta_2X_{2t} + \ldots + \beta_kX_{kt} + \epsilon_t Yt=β0+β1X1t+β2X2t+…+βkXkt+ϵt
其中:
- Y t Y_t Yt 是第 t t t 年的新能源电动汽车销售量或市场份额。
- X 1 t , X 2 t , … , X k t X_{1t}, X_{2t}, \ldots, X_{kt} X1t,X2t,…,Xkt 是影响新能源电动汽车发展的各个因素,如官方政策、经济指标、技术进步等。
- β 0 , β 1 , … , β k \beta_0, \beta_1, \ldots, \beta_k β0,β1,…,βk 是模型参数。
- ϵ t \epsilon_t ϵt 是误差项,代表未被模型考虑的其他因素的影响。
模型参数估计:
使用历史数据,通过最小二乘法等方法估计模型参数 β \beta β。
未来10年的预测:
使用模型和已知的未来数据(政策、技术创新计划等),预测未来10年的新能源电动汽车销售量或市场份额。
情景分析:
考虑不同的发展路径,例如政策变化、经济波动等对预测的可能影响。
我们搜集了行业发展数据表格为:Develop.xlsx,含有10年内行业发展的销售额,市场占有率,售卖比例等参数,相应的时间预测代码:
import pandas as pd
import statsmodels.api as sm
import matplotlib.pyplot as plt
# 读取Excel文件
file_path = 'Develop.xlsx'
df = pd.read_excel(file_path, sheet_name='Sheet1')
# 将时间列设为索引
df.set_index('Year', inplace=True)
# 假设销售额是因变量,其他列是自变量
y = df['Sales']
X = df[['MarketShare', 'SellRatio', 'OtherFactors']] # 自变量列
# 添加截距项
X = sm.add_constant(X)
# 拟合多元线性回归模型
model = sm.OLS(y, X).fit()
# 打印回归结果
print(model.summary())
# 预测未来10年的销售额
future_years = pd.Series(range(df.index[-1] + 1, df.index[-1] + 11))
future_X = sm.add_constant(df[['MarketShare', 'SellRatio', 'OtherFactors']]) # 使用历史数据的平均值作为未来数据
future_predictions = model.predict(future_X.append(pd.DataFrame(data={0: future_years, 'MarketShare': df['MarketShare'].mean(), 'SellRatio': df['SellRatio'].mean(), 'OtherFactors': df['OtherFactors'].mean()}).set_index(0)))
# 将预测结果添加到DataFrame
future_df = pd.DataFrame({'Sales Prediction': future_predictions}, index=future_years)
# 打印未来10年的销售额预测
print(future_df)
# 可视化历史销售额和预测销售额
plt.figure(figsize=(10, 6))
plt.plot(df.index, y, label='Actual Sales')
plt.plot(future_df.index, future_predictions, label='Sales Prediction', linestyle='dashed')
plt.title('Sales Prediction Over Time')
plt.xlabel('Year')
plt.ylabel('Sales')
plt.legend()
plt.show()
更多内容具体可以看看我的下方的名片!里面包含有亚太赛一手资料与分析!
另外在赛中,我们也会陪大家一起解析亚太赛APMCM的一些方向
关注 CS数模 团队,数模不迷路~