GAN和DCGAN生成随机图像。因此,我们几乎无法控制生成哪些图像。然而,CGAN 可以让我们指定一个条件,以便我们可以告诉它要生成哪些图像。诀窍是使用可学习层将标签值转换为特征向量,以便生成器可以学习要生成什么图像。鉴别器还利用标签条件。现阶段您可能还不清楚,但不用担心。本文将通过简单的代码介绍整个过程的工作原理。
条件作为特征向量
标签到 One-hot 编码标签
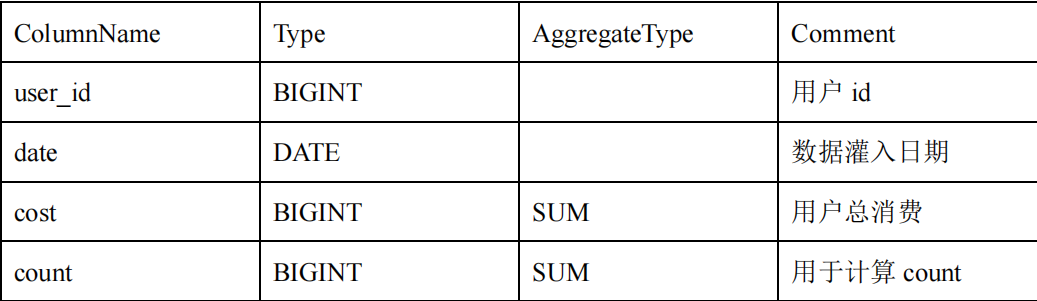
我们将使用包含许多数字图像的 MNIST 数据集。标签是 0 到 9 之间的整数(含 0 和 9)。通过将标签转换为特征向量,我们可以将目标标签(作为条件)输入到生成器和随机值向量中,以便生成的图像具有一些变化。
首先,我们使用 PyTorch F.one_hot 将数字转换为 one-hot 编码。
import torch
from torch.nn import functional as F
# Labels (i.e., 1 and 3)
labels = torch.LongTensor([1, 3])
# Create one-hot encoded labels
encoded = F.one_hot(labels, num_classes=10)
print(encoded)
输出是:
tensor([[0, 1, 0, 0, 0, 0, 0, 0, 0, 0], [0, 0, 0, 1, 0, 0, 0, 0, 0, 0]])
因此,我们将 1 和 3 编码为具有 10 个元素的向量。我们指定num_classes=10标签是从 0 到 9(10 个数字),并且我们需要 10 个元素来唯一标识 one-hot 编码中的每个数字。我们使用 one-hot 编码,因为数字的值没有像等级或顺序这样的含义。它是一个类(分类)值,使用 one-hot 编码来表示分类值是机器学习中的一种行之有效的做法。
特征向量的 One-hot 编码标签
生成器将学习从 one-hot 编码标签中提取特征(条件)。我们将创建一个类,通过全连接层将单热编码标签转换为特征向量。生成器和鉴别器都将使用该类。
# Coverts conditions into feature vectors
class Condition(nn.Module):
def __init__(self, alpha: float):
super().__init__()
# From one-hot encoding to features: 10 => 784
self.fc = nn.Sequential(
nn.Linear(10, 784),
nn.BatchNorm1d(784),
nn.LeakyReLU(alpha))
def forward(self, labels: torch.Tensor):
# One-hot encode labels
x = F.one_hot(labels, num_classes=10)
# From Long to Float
x = x.float()
# To feature vectors
return self.fc(x)
Reshape Helper
我们定义了一个辅助类,用于重塑生成器和鉴别器中的编码条件值。
# Reshape helper
class Reshape(nn.Module):
def __init__(self, *shape):
super().__init__()
self.shape = shape
def forward(self, x):
return x.reshape(-1, *self.shape)
生成器网络定义
该生成器与我们使用的 DCGAN 生成器类似。和之前一样,我们生成随机值向量,并使用全连接层将维度增加到 784。我们还使用条件层将输入标签转换为 784 维度的特征向量。然后,我们对随机向量和标签特征求和。这是一个逐元素的加法运算。我们可以这样做,因为随机值和标签特征向量具有相同数量的元素。
生成器网络处理随机值向量和标签特征向量的总和,以生成指定标签类别的随机图像。让我们看看如何将该Condition类集成到 DCGAN 生成器类中。
# Generator network
class Generator(nn.Module):
def __init__(self, sample_size: int, alpha: float):
super().__init__()
# sample_size => 784
self.fc = nn.Sequential(
nn.Linear(sample_size, 784),
nn.BatchNorm1d(784),
nn.LeakyReLU(alpha))
# 784 => 16 x 7 x 7
self.reshape = Reshape(16, 7, 7)
# 16 x 7 x 7 => 32 x 14 x 14
self.conv1 = nn.Sequential(
nn.ConvTranspose2d(16, 32,
kernel_size=5, stride=2, padding=2,
output_padding=1, bias=False),
nn.BatchNorm2d(32),
nn.LeakyReLU(alpha))
# 32 x 14 x 14 => 1 x 28 x 28
self.conv2 = nn.Sequential(
nn.ConvTranspose2d(32, 1,
kernel_size=5, stride=2, padding=2,
output_padding=1, bias=False),
nn.Sigmoid())
# Random value sample size
self.sample_size = sample_size
# To convert labels into feature vectors
self.cond = Condition(alpha)
def forward(self, labels: torch.Tensor):
# Labels as feature vectors
c = self.cond(labels)
# Batch size is the number of labels
batch_size = len(labels)
# Generate random inputs
z = torch.randn(batch_size, self.sample_size)
# Inputs are the sum of random inputs and label features
x = self.fc(z) # => 784
x = self.reshape(x+c) # => 16 x 7 x 7
x = self.conv1(x) # => 32 x 14 x 14
x = self.conv2(x) # => 1 x 28 x 28
return x
正如您所看到的,代码将标签转换为与随机值向量相同维度的特征向量,并执行逐元素加法操作(x+c)。换句话说,随机值和标签特征向量表达在同一空间中生成图像所需的信息。
我们来详细看看这部分代码。
# Label feature vectors (784)
c = self.cond(labels)
# Random value vectors (784)
z = torch.randn(batch_size, self.sample_size)
x = self.fc(z)
# Element-wise addition and reshape from 784 into 16x7x7
x = self.reshape(x+c)
如果我们没有随机值向量并且仅使用标签特征向量来训练生成器,它将学习为每个标签输入生成一张图像。拥有随机值向量对于向生成的图像添加变化至关重要。
在上面的代码中,我们使用了逐元素加法运算,但这并不是组合随机值向量和标签特征向量的唯一方法。我们可以将两个向量连接成一个。在这种情况下,我们不需要使两个向量具有相同数量的元素。或者,我们可以连接单热编码标签和随机值向量,并通过全连接层将它们提供给生成输入特征。我们需要调整全连接层中的参数数量以适应不同的输入向量大小。
在本文中,我们使用逐元素加法操作,因为它实现起来很简单,但您可能想尝试其他方法来看看它是如何工作的。
鉴别器网络定义
我们使用Condition鉴别器网络内的类来根据给定条件预测输入图像是真实的还是虚假的。例如,当条件指示图像是数字3时,鉴别器分类该图像是否是数字“3”的真实图像。与生成器一样,鉴别器也有条件层,可以通过训练学习为每个标签生成特征。
# Discriminator network
class Discriminator(nn.Module):
def __init__(self, alpha: float):
super().__init__()
# 1 x 28 x 28 => 32 x 14 x 14
self.conv1 = nn.Sequential(
nn.Conv2d(1, 32,
kernel_size=5, stride=2, padding=2, bias=False),
nn.LeakyReLU(alpha))
# 32 x 14 x 14 => 16 x 7 x 7
self.conv2 = nn.Sequential(
nn.Conv2d(32, 16,
kernel_size=5, stride=2, padding=2, bias=False),
nn.BatchNorm2d(16),
nn.LeakyReLU(alpha))
# 16 x 7 x 7 => 784
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 784),
nn.BatchNorm1d(784),
nn.LeakyReLU(alpha),
nn.Linear(784, 1))
# Reshape label features: 784 => 16 x 7 x 7
self.cond = nn.Sequential(
Condition(alpha),
Reshape(16, 7, 7))
def forward(self, images: torch.Tensor,
labels: torch.Tensor,
targets: torch.Tensor):
# Label features
c = self.cond(labels)
# Image features + Label features => real or fake?
x = self.conv1(images) # => 32 x 14 x 14
x = self.conv2(x) # => 16 x 7 x 7
prediction = self.fc(x+c) # => 1
loss = F.binary_cross_entropy_with_logits(prediction, targets)
return loss
CGAN训练
在训练时,我们将标签提供给鉴别器和生成器。每个网络都会为给定的标签生成对其目标有用的特征。CGAN 训练循环轮流训练鉴别器和生成器。
鉴别器训练
它与 DCGAN 判别器训练相同,只是我们提供标签。
# Train loop
for epoch in range(100):
d_losses = []
g_losses = []
for images, labels in tqdm(dataloader):
#===============================
# Disciminator Network Training
#===============================
# Images from MNIST are considered as real
d_loss = discriminator(images, labels, real_targets)
# Images from Generator are considered as fake
d_loss += discriminator(generator(labels), labels, fake_targets)
# Discriminator paramter update
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
...
生成器训练
它与 DCGAN 生成器训练相同,只是我们提供标签。
# Training Loop
for epoch in range(100):
for images, labels in tqdm(dataloader):
...
#===============================
# Generator Network Training
#===============================
# Images from Generator should be as real as ones from MNIST
g_loss = discriminator(generator(labels), labels, true_targets)
...
完整的源代码可在本文末尾找到。现在,让我们看看训练的结果。
训练结果
测试图像生成
在每个epoch之后,我们使用以下代码为从 0 到 9 的每个数字生成八张图像。
# 0 to 9 in a list
labels = list(range(10))
# Convert to long tensor
labels = torch.LongTensor(labels)
# Repeat each digit eight times
labels = labels.repeat(8)
# Flatten (10x8 => 80)
labels = labels.flatten()
# Generate 80 images
generated_images = generator(labels)
# Save the results in a grid layout
save_image_grid(epoch, generated_images, ncol=10)
第 1 epoch
在第一个epoch之后,生成的图像看起来像根据条件的数字。在我看来,添加条件使网络更容易学习。

第 50 epoch
我想说,输出看起来已经令人满意了。

第 100 epoch
与 Epoch 50 相比没有太大区别。它可能会稍微好看一些。很难说。无论如何,训练成功了,因为生成器可以根据给定条件生成各种图像。

CGAN 在生成针对特定图像的合成训练数据方面非常有用。
CGAN 为何有效
因此,CGAN 与 DCGAN 相同,只是将标签特征添加到输入向量中。仅此而已,但它会根据给定的标签条件生成。为什么它会这么有效?
生成器和鉴别器不共享其Condition层,因此每个网络都独立且对抗地学习。生成器尝试生成尽可能真实的图像,使得判别器计算的损失变得更小。在此过程中,该Condition层必须学会尽可能区分不同的标签特征,因为知道生成什么以实现更低的损失取决于预测它应该生成什么数字。鉴别器Condition层还学习区分不同的数字,使二元分类(真或假)决策变得更容易。因此,区分生成器和鉴别器的标签输入至关重要。
例如,当标签为数字 1 时,生成器必须生成尽可能真实的 1 图像(尽可能像 MNIST 图像),如果生成的图像不符合,则判别器需要给生成器带来显着的损失。看起来根本就像数字“1”。从生成器的角度来看,鉴别器是一个也从输入中学习的损失函数。
因此,只要我们对所有 0 到 9 位数字的生成器和鉴别器进行同样的训练,生成器就可以理解为给定标签生成真实(类似 MNIST)图像的条件。
源代码
源代码与DCGAN几乎相同,只是我们现在有了条件处理代码。
import numpy as np
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.nn import functional as F
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from torchvision.utils import make_grid
from tqdm import tqdm
# Common config
batch_size = 64
# Generator config
sample_size = 100 # Random sample size
g_alpha = 0.01 # LeakyReLU alpha
g_lr = 1.0e-4 # Learning rate
# Discriminator config
d_alpha = 0.01 # LeakyReLU alpha
d_lr = 1.0e-4 # Learning rate
# Data Loader for MNIST
transform = transforms.ToTensor()
dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
dataloader = DataLoader(dataset, batch_size=batch_size, drop_last=True)
# Coverts conditions into feature vectors
class Condition(nn.Module):
def __init__(self, alpha: float):
super().__init__()
# From one-hot encoding to features: 10 => 784
self.fc = nn.Sequential(
nn.Linear(10, 784),
nn.BatchNorm1d(784),
nn.LeakyReLU(alpha))
def forward(self, labels: torch.Tensor):
# One-hot encode labels
x = F.one_hot(labels, num_classes=10)
# From Long to Float
x = x.float()
# To feature vectors
return self.fc(x)
# Reshape helper
class Reshape(nn.Module):
def __init__(self, *shape):
super().__init__()
self.shape = shape
def forward(self, x):
return x.reshape(-1, *self.shape)
# Generator network
class Generator(nn.Module):
def __init__(self, sample_size: int, alpha: float):
super().__init__()
# sample_size => 784
self.fc = nn.Sequential(
nn.Linear(sample_size, 784),
nn.BatchNorm1d(784),
nn.LeakyReLU(alpha))
# 784 => 16 x 7 x 7
self.reshape = Reshape(16, 7, 7)
# 16 x 7 x 7 => 32 x 14 x 14
self.conv1 = nn.Sequential(
nn.ConvTranspose2d(16, 32,
kernel_size=5, stride=2, padding=2,
output_padding=1, bias=False),
nn.BatchNorm2d(32),
nn.LeakyReLU(alpha))
# 32 x 14 x 14 => 1 x 28 x 28
self.conv2 = nn.Sequential(
nn.ConvTranspose2d(32, 1,
kernel_size=5, stride=2, padding=2,
output_padding=1, bias=False),
nn.Sigmoid())
# Random value sample size
self.sample_size = sample_size
# To convert labels into feature vectors
self.cond = Condition(alpha)
def forward(self, labels: torch.Tensor):
# Labels as feature vectors
c = self.cond(labels)
# Batch size is the number of labels
batch_size = len(labels)
# Generate random inputs
z = torch.randn(batch_size, self.sample_size)
# Inputs are the sum of random inputs and label features
x = self.fc(z) # => 784
x = self.reshape(x+c) # => 16 x 7 x 7
x = self.conv1(x) # => 32 x 14 x 14
x = self.conv2(x) # => 1 x 28 x 28
return x
# Discriminator network
class Discriminator(nn.Module):
def __init__(self, alpha: float):
super().__init__()
# 1 x 28 x 28 => 32 x 14 x 14
self.conv1 = nn.Sequential(
nn.Conv2d(1, 32,
kernel_size=5, stride=2, padding=2, bias=False),
nn.LeakyReLU(alpha))
# 32 x 14 x 14 => 16 x 7 x 7
self.conv2 = nn.Sequential(
nn.Conv2d(32, 16,
kernel_size=5, stride=2, padding=2, bias=False),
nn.BatchNorm2d(16),
nn.LeakyReLU(alpha))
# 16 x 7 x 7 => 784
self.fc = nn.Sequential(
nn.Flatten(),
nn.Linear(784, 784),
nn.BatchNorm1d(784),
nn.LeakyReLU(alpha),
nn.Linear(784, 1))
# Reshape label features: 784 => 16 x 7 x 7
self.cond = nn.Sequential(
Condition(alpha),
Reshape(16, 7, 7))
def forward(self, images: torch.Tensor,
labels: torch.Tensor,
targets: torch.Tensor):
# Label features
c = self.cond(labels)
# Image features + Label features => real or fake?
x = self.conv1(images) # => 32 x 14 x 14
x = self.conv2(x) # => 16 x 7 x 7
prediction = self.fc(x+c) # => 1
loss = F.binary_cross_entropy_with_logits(prediction, targets)
return loss
# To save grid images
def save_image_grid(epoch: int, images: torch.Tensor, ncol: int):
image_grid = make_grid(images, ncol) # Into a grid
image_grid = image_grid.permute(1, 2, 0) # Channel to last
image_grid = image_grid.cpu().numpy() # Into Numpy
plt.imshow(image_grid)
plt.xticks([])
plt.yticks([])
plt.savefig(f'generated_{epoch:03d}.jpg')
plt.close()
# Real / Fake targets
real_targets = torch.ones(batch_size, 1)
fake_targets = torch.zeros(batch_size, 1)
# Generator and discriminator
generator = Generator(sample_size, g_alpha)
discriminator = Discriminator(d_alpha)
# Optimizers
d_optimizer = torch.optim.Adam(discriminator.parameters(), lr=d_lr)
g_optimizer = torch.optim.Adam(generator.parameters(), lr=g_lr)
# Train loop
for epoch in range(100):
d_losses = []
g_losses = []
for images, labels in tqdm(dataloader):
#===============================
# Disciminator Network Training
#===============================
# Images from MNIST are considered as real
d_loss = discriminator(images, labels, real_targets)
# Images from Generator are considered as fake
d_loss += discriminator(generator(labels), labels, fake_targets)
# Discriminator paramter update
d_optimizer.zero_grad()
d_loss.backward()
d_optimizer.step()
#===============================
# Generator Network Training
#===============================
# Images from Generator should be as real as ones from MNIST
g_loss = discriminator(generator(labels), labels, real_targets)
# Generator parameter update
g_optimizer.zero_grad()
g_loss.backward()
g_optimizer.step()
# Keep losses for logging
d_losses.append(d_loss.item())
g_losses.append(g_loss.item())
# Print loss
print(epoch, np.mean(d_losses), np.mean(g_losses))
# Save generated images
labels = torch.LongTensor(list(range(10))).repeat(8).flatten()
save_image_grid(epoch, generator(labels), ncol=10)
参考文献
条件生成对抗网络, 2014年。
本文译自KikabeN博文


![[论文笔记] Scaling Laws for Neural Language Models](https://img-blog.csdnimg.cn/2674d8d5c6c84d59b73491ca58184c91.png)