大家好,我是微学AI,今天给大家介绍一下人工智能基础部分21-神经网络中优化器算法的详细介绍,配套详细公式。本文将介绍几种算法优化器,并展示如何使用PyTorch中的算法优化器,我们将使用MNIST数据集和一个简单的多层感知器(MLP)模型。本文仅用于演示不同优化器的用法,实际应用中可能需要调整超参数以获得最佳性能。
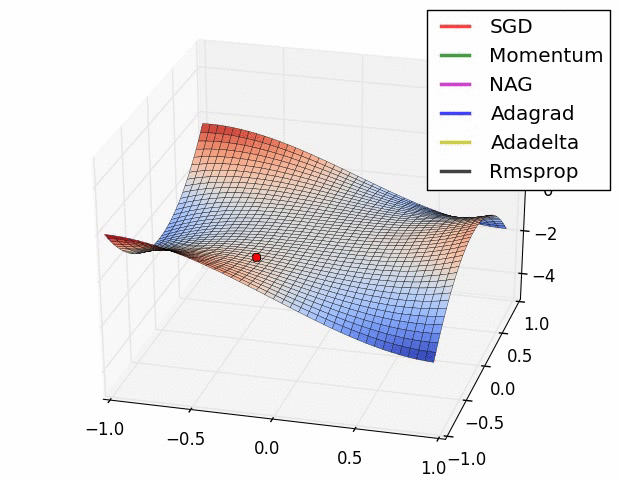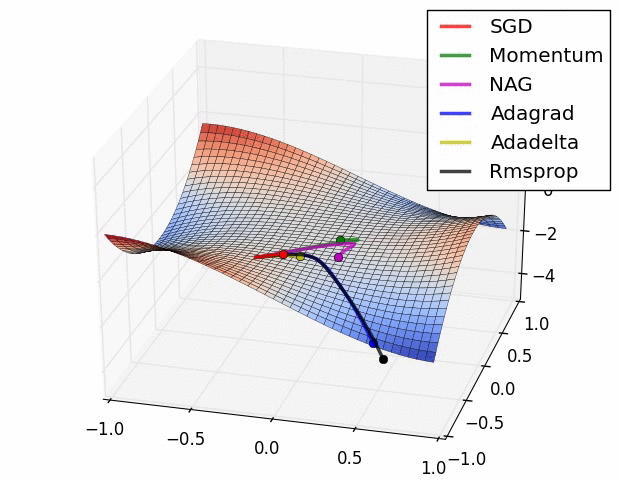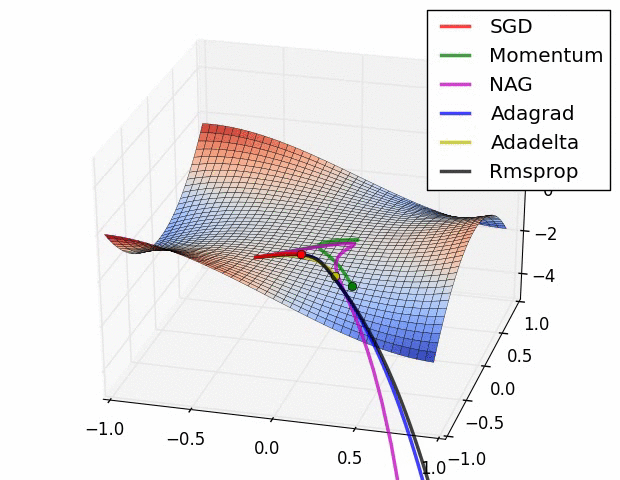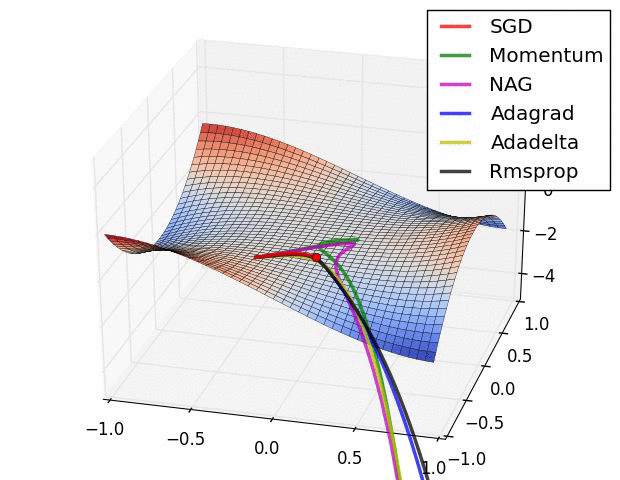
一、几种算法优化器介绍
1. SGD (随机梯度下降)
原理:SGD 是一种简单但有效的优化方法,它通过计算梯度的期望值来更新参数。
数学公式:
θ
t
+
1
=
θ
t
−
η
∇
J
(
θ
t
)
\theta_{t+1} = \theta_t - \eta \nabla J(\theta_t)
θt+1=θt−η∇J(θt)
其中, θ \theta θ 是参数, η \eta η 是学习率, ∇ J ( θ t ) \nabla J(\theta_t) ∇J(θt) 是损失函数 J J J 关于参数 θ \theta θ 的梯度。
2. ASGD (平均随机梯度下降)
原理:ASGD 是 SGD 的一个变种,它在训练过程中计算参数的移动平均值,从而提高优化的稳定性。
数学公式:
θ
t
+
1
=
θ
t
−
η
∇
J
(
θ
t
)
θ
ˉ
t
+
1
=
(
1
−
λ
)
θ
ˉ
t
+
λ
θ
t
+
1
\theta_{t+1} = \theta_t - \eta \nabla J(\theta_t) \\ \bar{\theta}_{t+1} = (1 - \lambda) \bar{\theta}_t + \lambda \theta_{t+1}
θt+1=θt−η∇J(θt)θˉt+1=(1−λ)θˉt+λθt+1
其中, θ ˉ \bar{\theta} θˉ 是参数的移动平均值, λ \lambda λ 是平滑因子。
3. Rprop (弹性反向传播)
原理:Rprop 是一种基于局部梯度信息的优化方法,它根据梯度的符号来更新参数,而不是梯度的大小。
数学公式:
Δ
θ
t
+
1
=
{
Δ
θ
t
⋅
η
+
if
∇
J
(
θ
t
)
⋅
∇
J
(
θ
t
−
1
)
>
0
Δ
θ
t
⋅
η
−
if
∇
J
(
θ
t
)
⋅
∇
J
(
θ
t
−
1
)
<
0
Δ
θ
t
otherwise
θ
t
+
1
=
θ
t
−
sign
(
∇
J
(
θ
t
)
)
⋅
Δ
θ
t
+
1
\Delta \theta_{t+1} = \begin{cases} \Delta \theta_t \cdot \eta^+ & \text{if } \nabla J(\theta_t) \cdot \nabla J(\theta_{t-1}) > 0 \\ \Delta \theta_t \cdot \eta^- & \text{if } \nabla J(\theta_t) \cdot \nabla J(\theta_{t-1}) < 0 \\ \Delta \theta_t & \text{otherwise} \end{cases} \\ \theta_{t+1} = \theta_t - \text{sign}(\nabla J(\theta_t)) \cdot \Delta \theta_{t+1}
Δθt+1=⎩
⎨
⎧Δθt⋅η+Δθt⋅η−Δθtif ∇J(θt)⋅∇J(θt−1)>0if ∇J(θt)⋅∇J(θt−1)<0otherwiseθt+1=θt−sign(∇J(θt))⋅Δθt+1
其中, Δ θ \Delta \theta Δθ 是参数更新的大小, η + \eta^+ η+ 和 η − \eta^- η− 是增加和减少更新大小的因子。
4. Adagrad (自适应梯度)
原理:Adagrad 是一种自适应学习率的优化方法,它根据参数的历史梯度来调整学习率。
数学公式:
G
t
=
G
t
−
1
+
∇
J
(
θ
t
)
2
θ
t
+
1
=
θ
t
−
η
G
t
+
ϵ
∇
J
(
θ
t
)
G_t = G_{t-1} + \nabla J(\theta_t)^2 \\ \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{G_t + \epsilon}} \nabla J(\theta_t)
Gt=Gt−1+∇J(θt)2θt+1=θt−Gt+ϵη∇J(θt)
其中, G t G_t Gt 是历史梯度的累积平方和, ϵ \epsilon ϵ 是平滑项。
5. Adadelta (自适应学习率和动量)
原理:Adadelta 是 Adagrad 的一个改进版本,它使用动量项来更新参数,并且不需要设置初始学习率。
数学公式:
E
[
g
2
]
t
=
ρ
E
[
g
2
]
t
−
1
+
(
1
−
ρ
)
∇
J
(
θ
t
)
2
Δ
θ
t
=
−
E
[
Δ
θ
2
]
t
−
1
+
ϵ
E
[
g
2
]
t
+
ϵ
∇
J
(
θ
t
)
E
[
Δ
θ
2
]
t
=
ρ
E
[
Δ
θ
2
]
t
−
1
+
(
1
−
ρ
)
Δ
θ
t
2
θ
t
+
1
=
θ
t
+
Δ
θ
t
E[g^2]_t = \rho E[g^2]_{t-1} + (1 - \rho) \nabla J(\theta_t)^2 \\ \Delta \theta_t = - \frac{\sqrt{E[\Delta \theta^2]_{t-1} + \epsilon}}{\sqrt{E[g^2]_t + \epsilon}} \nabla J(\theta_t) \\ E[\Delta \theta^2]_t = \rho E[\Delta \theta^2]_{t-1} + (1 - \rho) \Delta \theta_t^2 \\ \theta_{t+1} = \theta_t + \Delta \theta_t
E[g2]t=ρE[g2]t−1+(1−ρ)∇J(θt)2Δθt=−E[g2]t+ϵE[Δθ2]t−1+ϵ∇J(θt)E[Δθ2]t=ρE[Δθ2]t−1+(1−ρ)Δθt2θt+1=θt+Δθt
其中, E [ g 2 ] E[g^2] E[g2] 和 E [ Δ θ 2 ] E[\Delta \theta^2] E[Δθ2] 分别是梯度平方和和参数更新平方和的指数移动平均值, ρ \rho ρ 是动量因子。
6. RMSprop (均方根传播)
RMSProp(Root Mean Square Propagation)优化算法是一种自适应学习率的优化算法,主要用于深度学习中。以下是RMSProp优化算法的数学公式:
首先,计算梯度的平方的指数加权移动平均值:
v t = β v t − 1 + ( 1 − β ) g t 2 v_t = \beta v_{t-1} + (1 - \beta) g_t^2 vt=βvt−1+(1−β)gt2
其中, v t v_t vt 是时间步 t 的平方梯度指数加权移动平均值, g t 2 g_t^2 gt2 是当前时间步梯度的元素平方, β \beta β 是梯度的指数衰减率。
然后,更新模型参数:
θ t + 1 = θ t − η v t + ϵ g t \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{v_t} + \epsilon} g_t θt+1=θt−vt+ϵηgt
其中, θ t \theta_t θt 是时间步 t 的模型参数, η \eta η 是学习率, ϵ \epsilon ϵ 是为了数值稳定性而添加的小常数。
以上描述了RMSProp优化算法中计算梯度平方指数加权移动平均值和更新模型参数的过程。RMSProp算法通过对梯度进行平方指数加权移动平均来自适应地调整学习率,从而在训练过程中更好地优化模型。
7.Adam
Adam(Adaptive Moment Estimation)是一种自适应学习率的优化算法,它结合了动量梯度下降和RMSprop算法的思想。Adam算法通过计算梯度的一阶矩估计和二阶矩估计来调整每个参数的学习率。
以下是Adam优化算法的数学公式:
首先,计算一阶矩估计(即梯度的指数移动平均值):
m t = β 1 m t − 1 + ( 1 − β 1 ) g t m_t = \beta_1 m_{t-1} + (1 - \beta_1) g_t mt=β1mt−1+(1−β1)gt
其中, m t m_t mt 是时间步 t 的一阶矩估计, g t g_t gt 是当前时间步的梯度, β 1 \beta_1 β1 是动量的指数衰减率。
其次,计算二阶矩估计(即梯度的平方的指数移动平均值):
v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t = \beta_2 v_{t-1} + (1 - \beta_2) g_t^2 vt=β2vt−1+(1−β2)gt2
其中, v t v_t vt 是时间步 t 的二阶矩估计, g t 2 g_t^2 gt2 是当前时间步梯度的元素平方, β 2 \beta_2 β2 是梯度的指数衰减率。
接着,校正一阶矩的偏差:
m ^ t = m t 1 − β 1 t \hat{m}_t = \frac{m_t}{1 - \beta_1^t} m^t=1−β1tmt
v ^ t = v t 1 − β 2 t \hat{v}_t = \frac{v_t}{1 - \beta_2^t} v^t=1−β2tvt
然后,更新模型参数:
θ t + 1 = θ t − η v ^ t + ϵ m ^ t \theta_{t+1} = \theta_t - \frac{\eta}{\sqrt{\hat{v}_t} + \epsilon} \hat{m}_t θt+1=θt−v^t+ϵηm^t
其中, θ t \theta_t θt 是时间步 t 的模型参数, η \eta η 是学习率, ϵ \epsilon ϵ 是为了数值稳定性而添加的小常数。
以上描述了Adam优化算法中用于更新梯度估计、计算动量和RMSProp的过程,并最终利用它们来更新模型参数的方法。
概率论与数理统计中的矩估计介绍
在优化算法中,一阶矩估计和二阶矩估计是指对梯度的统计特征进行估计的过程,涉及了概率论与数理统计的知识。我来详细解释一下:
一阶矩估计通常表示对随机变量的期望值的估计,也可以理解为均值的估计。在优化算法中,一阶矩估计可以用来估计梯度的平均值,在Adam和RMSProp等算法中起到了动量的作用。动量可以帮助优化算法在参数更新时更平稳地前进,避免陷入局部极小值点。一阶矩估计可以通过指数加权移动平均的方式来计算,从而更好地反映梯度的变化趋势。
二阶矩估计则通常表示对随机变量的方差的估计。在优化算法中,二阶矩估计可以用来估计梯度的方差或者标准差,如在RMSProp算法中所使用的。通过估计梯度的方差,我们可以更好地了解梯度的变化范围,并且利用这个信息来自适应地调整学习率,以提高训练的效率和稳定性。
概率论与数理统计为我们提供了对随机变量的期望、方差等统计特征的概念和计算方法,优化算法中的一阶矩估计和二阶矩估计正是借鉴了这些概念和方法,使得优化算法能够更好地利用梯度的统计信息来指导参数更新的过程,从而提高模型的训练效果。
二、PyTorch实现算法优化器的代码
import torch
import torch.nn as nn
import torch.optim as optim
from torchvision import datasets, transforms
from torch.utils.data import DataLoader
# 定义一个简单的多层感知器
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
x = x.view(-1, 28 * 28)
x = torch.relu(self.fc1(x))
x = torch.relu(self.fc2(x))
x = self.fc3(x)
return x
# 准备数据
transform = transforms.Compose([transforms.ToTensor(), transforms.Normalize((0.1307,), (0.3081,))])
train_dataset = datasets.MNIST(root='./data', train=True, download=True, transform=transform)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 定义损失函数
criterion = nn.CrossEntropyLoss()
# 定义优化器列表
optimizers = [
optim.SGD,
optim.ASGD,
optim.Rprop,
optim.Adagrad,
optim.Adadelta,
optim.RMSprop,
optim.Adam
]
# 训练函数
def train(optimizer_class, model, dataloader, criterion, epochs=3):
optimizer = optimizer_class(model.parameters(), lr=0.01)
model.train()
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
for batch_idx, (data, target) in enumerate(dataloader):
optimizer.zero_grad()
output = model(data)
loss = criterion(output, target)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(output.data, 1)
total += target.size(0)
correct += (predicted == target).sum().item()
print(f'Optimizer: {optimizer_class.__name__}, Epoch: {epoch + 1}, Loss: {running_loss / len(dataloader)}, Accuracy: {correct / total * 100}%')
# 使用不同的优化器训练模型
for optimizer_class in optimizers:
model = MLP()
train(optimizer_class, model, train_loader, criterion)
运行结果:
Optimizer: SGD, Epoch: 1, Loss: 0.8009015738265093, Accuracy: 79.87333333333333%
Optimizer: SGD, Epoch: 2, Loss: 0.31090657713253106, Accuracy: 91.07333333333332%
Optimizer: SGD, Epoch: 3, Loss: 0.2509216960471894, Accuracy: 92.69833333333334%
Optimizer: ASGD, Epoch: 1, Loss: 0.8227703367659787, Accuracy: 79.11333333333333%
Optimizer: ASGD, Epoch: 2, Loss: 0.3227304352451362, Accuracy: 90.68833333333333%
Optimizer: ASGD, Epoch: 3, Loss: 0.2698148043155035, Accuracy: 92.145%
Optimizer: Rprop, Epoch: 1, Loss: 8.706047950292637, Accuracy: 85.69333333333333%
Optimizer: Rprop, Epoch: 2, Loss: 16.184261398441567, Accuracy: 85.75166666666667%
Optimizer: Rprop, Epoch: 3, Loss: 15.855906286521126, Accuracy: 85.99166666666666%
Optimizer: Adagrad, Epoch: 1, Loss: 0.24328371752172645, Accuracy: 92.56166666666667%
Optimizer: Adagrad, Epoch: 2, Loss: 0.12497247865737311, Accuracy: 96.25333333333333%
Optimizer: Adagrad, Epoch: 3, Loss: 0.09774033319570426, Accuracy: 97.06666666666666%
Optimizer: Adadelta, Epoch: 1, Loss: 1.3385312659526938, Accuracy: 69.485%
Optimizer: Adadelta, Epoch: 2, Loss: 0.5202090000229349, Accuracy: 86.955%
Optimizer: Adadelta, Epoch: 3, Loss: 0.39094064729427225, Accuracy: 89.41666666666667%
Optimizer: RMSprop, Epoch: 1, Loss: 0.6654755138456504, Accuracy: 88.81666666666666%
Optimizer: RMSprop, Epoch: 2, Loss: 0.23642293871569037, Accuracy: 93.51833333333333%
Optimizer: RMSprop, Epoch: 3, Loss: 0.20657251488222783, Accuracy: 94.41833333333334%
Optimizer: Adam, Epoch: 1, Loss: 0.2741849403957457, Accuracy: 91.88833333333334%
Optimizer: Adam, Epoch: 2, Loss: 0.18909314711804567, Accuracy: 94.86833333333334%
Optimizer: Adam, Epoch: 3, Loss: 0.1710762643500535, Accuracy: 95.42166666666667%
以上代码将为每个优化器运行3个训练周期,并打印损失值和准确率。我们可以看到针对这个任务Adagrad优化器表现较好,在实际应用中,我们可能需要运行更多的训练周期并调整学习率等超参数以获得最佳性能。