MySQL的联合索引
联合索引的最左匹配原则会一直向右匹配直到遇到范围查询(>、<、between、like) 就会停止匹配。
这个结论并不全对!去掉 「between 和 like 」这个结论就没问题了
经过实验的证明,我得出的结论是这样的:
联合索引的最左匹配原则,在遇到范围查询(如 >、<)的时候,就会停止匹配,也就是范围查询的字段可以用到联合索引,但是在范围查询字段后面的字段无法用到联合索引。但是,对于 >=、<=、BETWEEN、like 前缀匹配这四种范围查询,并不会停止匹配。
用几个实验例子来说明这个结论:
B+Tree 索引
首先,先来认识下 B+Tree 索引。
MySQL 的 InnoDB 存储引擎会为每一张数据库表创建一个「聚簇索引」来保存表的数据,聚簇索引默认使用的是B+Tree 索引。
为了让大家理解 B+Tree 索引的存储和查询的过程,接下来我通过一个简单例子,说明一下 B+Tree 索引在存储数据中的具体实现。
假设有一张商品表,表里有这些数据:
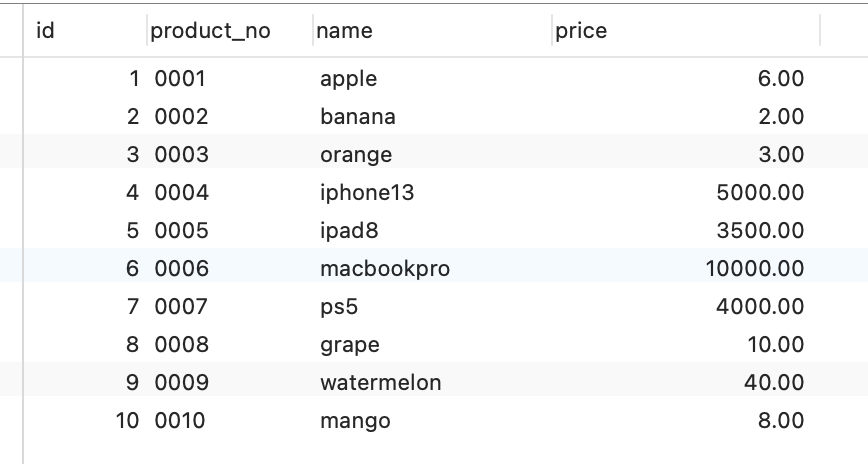
这些数据,存储在 B+Tree 索引时是长什么样子的?
B+Tree 是一种多叉树,叶子节点才存放数据,非叶子节点只存放索引,而且每个节点里的数据是按主键值(id)顺序存放的,每一层父节点的索引值都会出现在下层子节点的索引值中,因此在叶子节点中,包括了所有的索引值信息,并且每一个叶子节点都指向下一个叶子节点,形成一个链表,便于范围查询。
聚簇索引的 B+Tree 如图所示:

假设,执行了 select * from t_product where id = 5查询语句,该查询语句的条件是找到 id(主键)为 5 的这条记录。因为 B+Tree 是一个有序的数据结构,所以可以通过二分查找算法快速定位到这条记录,这也就是我们常说的索引查询,具体过程如下:
- 从根节点开始,将 5 与根节点的索引数据 (1,10,20) 比较,5 在 1 和 10 之间,根据二分查找算法,找到第二层的索引数据 (1,4,7);
- 在第二层的索引数据 (1,4,7)中进行查找,因为 5 在 4 和 7 之间,根据二分查找算法,找到第三层的索引数据(4,5,6);
- 在叶子节点的索引数据(4,5,6)中进行查找,然后我们找到了索引值为 5 的这条记录。
聚簇索引只能用于主键字段的快速查询,如果想实现「非主键字段」的快速查询,我们就要针对「非主键字段」创建索引,这种索引称作为「二级索引」。二级索引同样基于 B+Tree 实现的,不过二级索引的叶子节点存放的是主键值,不是实际数据。
我这里将前面的商品表中的 product_no (商品编码)字段设置为二级索引,那么二级索引的 B+Tree 如下图,其中非叶子的索引值是 product_no(图中橙色部分),叶子节点存储的数据是主键值(图中绿色部分)。
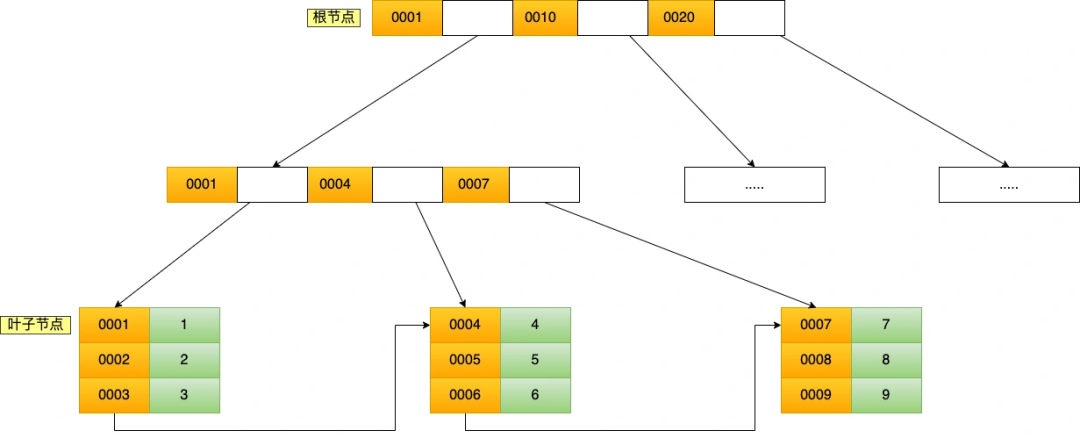
如果我用 product_no 二级索引查询商品,如下查询语句:
select * from product where product_no = '0002';会先在二级索引的 B+Tree 中快速查找到 product_no 为 0002 的二级索引记录,然后获取主键值,然后利用主键值在主键索引的 B+Tree 中快速查询到对应的叶子节点,然后获取完整的记录。这个过程叫「回表」,也就是说要查两个 B+Tree 才能查到数据。如下图:
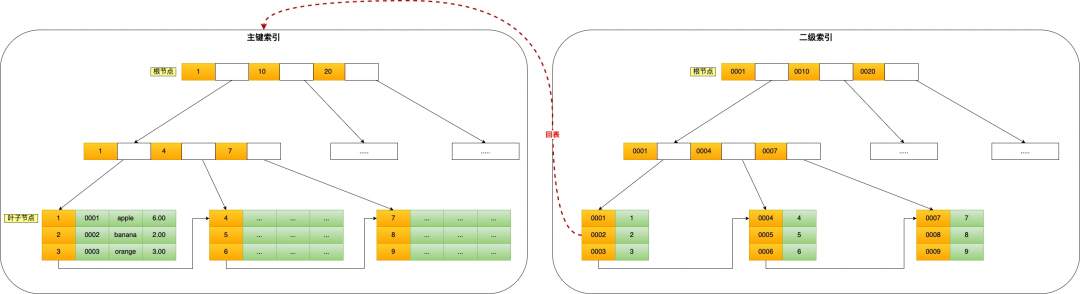
不过,当查询的数据是能在二级索引的 B+Tree 的叶子节点里查询到,这时就不用再查主键索引查,比如下面这条查询语句:
select id from product where product_no = '0002';这种在二级索引的 B+Tree 就能查询到结果的过程就叫作「覆盖索引」,也就是只需要查一个 B+Tree 就能找到数据。
什么是联合索引?
前文我将 product_no 字段设置为了索引,这种二级索引只有一个字段。如果将多个字段组合成一个索引,那么这种二级索引就被称为联合索引。
比如,将商品表中的 product_no 和 name 字段组合成联合索引`(product_no, name)``,创建联合索引的方式如下:
CREATE INDEX index_product_no_name ON product(product_no, name);联合索引 ``(product_no, name)` 的 B+Tree 示意图如下:
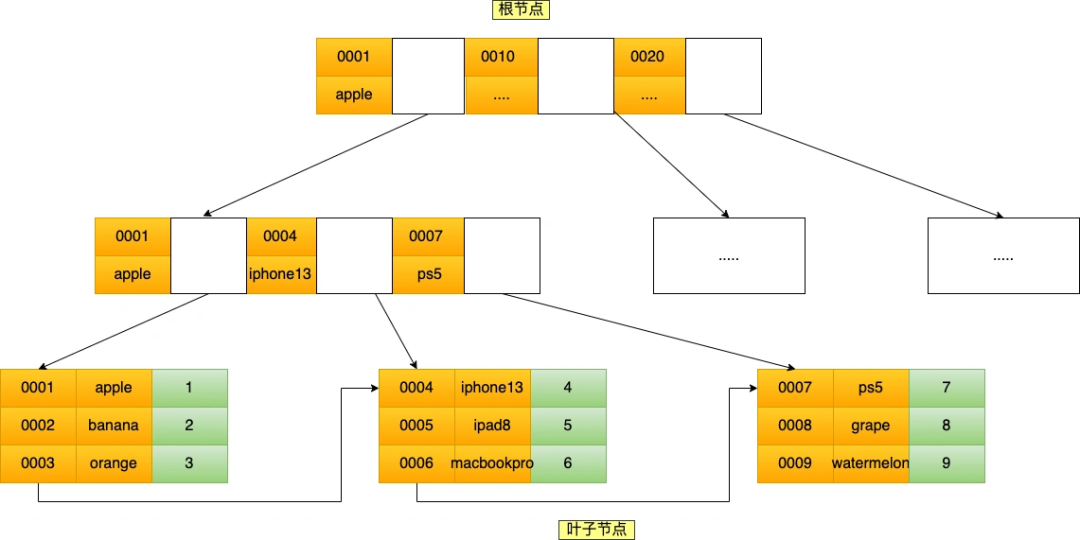
可以看到,联合索引的非叶子节点用两个字段的值作为 B+Tree 的索引值。
联合索引的 B+Tree 是先按 product_no 进行排序,然后再 product_no 相同的情况再按 name 字段排序。记住这句话,很重要!
最左匹配原则
使用联合索引时,存在最左匹配原则,也就是按照最左优先的方式进行索引的匹配。
在使用联合索引进行查询的时候,如果不遵循「最左匹配原则」,联合索引会失效,这样就无法利用到索引快速查询的特性了。
比如,如果创建了一个 (a, b, c) 联合索引,如果查询条件是以下这几种,就可以利用联合索引:
- where a=1;
- where a=1 and b=2 and c=3;
- where a=1 and b=2;
需要注意的是,因为有查询优化器,所以 a 字段在 where 子句的顺序并不重要。但是,如果查询条件是以下这几种,因为不符合最左匹配原则,所以就无法匹配上联合索引,联合索引就会失效:
- where b=2;
- where c=3;
- where b=2 and c=3;
上面这些查询条件之所以会失效,是因为(a, b, c) 联合索引,是先按 a 排序,在 a 相同的情况再按 b 排序,在 b 相同的情况再按 c 排序。所以,b 和 c 是全局无序,局部相对有序的,这样在没有遵循最左匹配原则的情况下,是无法利用到索引的。
我这里举联合索引(a,b)的例子,该联合索引的 B+ Tree 如下:
可以看到,a 是全局有序的(1, 2, 2, 3, 4, 5, 6, 7 ,8),而 b 是全局是无序的(12,7,8,2,3,8,10,5,2)。因此,直接执行 where b = 2 这种查询条件没有办法利用联合索引的,利用索引的前提是索引里的 key 是有序的。
只有在 a 相同的情况才,b 才是有序的,比如 a 等于 2 的时候,b 的值为(7,8),这时就是有序的,这个有序状态是局部的,因此,执行 where a = 2 and b = 7 这种查询条件时, a 和 b 字段能用到联合索引的,也就是联合索引生效了。
联合索引范围查询
联合索引有一些特殊情况,并不是查询过程使用了联合索引查询,就代表联合索引中的所有字段都用到了联合索引进行索引查询,也就是可能存在部分字段用到联合索引的 B+Tree,部分字段没有用到联合索引的 B+Tree 的情况。
这种特殊情况就发生在范围查询。也就是文章开头的那句话:联合索引的最左匹配原则会一直向右匹配直到遇到「范围查询」就会停止匹配。也就是范围查询的字段可以用到联合索引,但是范围查询字段的后面的字段无法用到联合索引。
范围查询有很多种,那到底是哪些范围查询会导致联合索引的最左匹配原则会停止匹配呢?
接下来,举例几个范围查询的例子,下面的实验案例是基于 MySQL 8.0 做的。
例子一
Q1: select * from t_table where a > 1 and b = 2,联合索引(a, b)哪一个字段用到了联合索引的 B+Tree?
由于联合索引(二级索引)是先按照 a 字段的值排序的,所以符合 a > 1 条件的二级索引记录肯定是相邻的,于是在进行索引扫描的时候,可以定位到符合 a > 1 条件的第一条记录,然后沿着记录所在的链表向后扫描,直到某条记录不符合 a > 1 条件位置。所以 a 字段可以在联合索引的 B+Tree 中进行索引查询。
但是在符合 a > 1 条件的二级索引记录的范围里,b 字段的值是无序的。
比如,下图的联合索引的 B+ Tree 里:
下面这三条记录的 a 字段的值都符合 a > 1 查询条件,而 b 字段的值是无序的:
- a 字段值为 5 的记录,该记录的 b 字段值为 8;
- a 字段值为 6 的记录,该记录的 b 字段值为 10;
- a 字段值为 7 的记录,该记录的 b 字段值为 5;
因此,我们不能根据查询条件 b = 2 来进一步减少需要扫描的记录数量(b 字段无法利用联合索引进行索引查询的意思)。
所以在执行 Q1 这条查询语句的时候,对应的扫描区间是 (2, + ∞),形成该扫描区间的边界条件是 a > 1,与 b = 2 无关。
因此,Q1 这条查询语句只有 a 字段用到了联合索引进行索引查询,而 b 字段并没有使用到联合索引。
我们也可以在执行计划中的 key_len 知道这一点,在使用联合索引进行查询的时候,通过 key_len 我们可以知道优化器具体使用了多少个字段的查询条件来形成扫描区间的边界条件。
举例个例子 ,a 和 b 都是 int 类型且不为 NULL 的字段,那么 Q1 这条查询语句执行计划如下:
可以看到 key_len 为 4 字节(如果字段允许为 NULL,就在字段类型占用的字节数上加 1,也就是 5 字节),说明只有 a 字段用到了联合索引进行索引查询,而且可以看到,即使 b 字段没用到联合索引,key 为 idx_a_b,说明 Q1 查询语句使用了 idx_a_b 联合索引。
通过 Q1 查询语句我们可以知道,a 字段使用了 > 进行范围查询,联合索引的最左匹配原则在遇到 a 字段的范围查询( >)后就停止匹配了,因此 b 字段并没有使用到联合索引。
例子二
Q2: select * from t_table where a >= 1 and b = 2,联合索引(a, b)哪一个字段用到了联合索引的 B+Tree?
Q2 和 Q1 的查询语句很像,唯一的区别就是 a 字段的查询条件「大于等于」。
由于联合索引(二级索引)是先按照 a 字段的值排序的,所以符合 >= 1 条件的二级索引记录肯定是相邻,于是在进行索引扫描的时候,可以定位到符合 >= 1 条件的第一条记录,然后沿着记录所在的链表向后扫描,直到某条记录不符合 a>= 1 条件位置。所以 a 字段可以在联合索引的 B+Tree 中进行索引查询。
虽然在符合 a>= 1 条件的二级索引记录的范围里,b 字段的值是「无序」的,但是对于符合 a = 1 的二级索引记录的范围里,b 字段的值是「有序」的(因为对于联合索引,是先按照 a 字段的值排序,然后在 a 字段的值相同的情况下,再按照 b 字段的值进行排序)。
于是,在确定需要扫描的二级索引的范围时,当二级索引记录的 a 字段值为 1 时,可以通过 b = 2 条件减少需要扫描的二级索引记录范围(b 字段可以利用联合索引进行索引查询的意思)。也就是说,从符合 a = 1 and b = 2 条件的第一条记录开始扫描,而不需要从第一个 a 字段值为 1 的记录开始扫描。
所以,Q2 这条查询语句 a 和 b 字段都用到了联合索引进行索引查询。
我们也可以在执行计划中的 key_len 知道这一点。执行计划如下:
可以看到 key_len 为 8 字节,说明优化器使用了 2 个字段的查询条件来形成扫描区间的边界条件,也就是 a 和 b 字段都用到了联合索引进行索引查询。
通过 Q2 查询语句我们可以知道,虽然 a 字段使用了 >= 进行范围查询,但是联合索引的最左匹配原则并没有在遇到 a 字段的范围查询( >=)后就停止匹配了,b 字段还是可以用到了联合索引的。
例子三
Q3: SELECT * FROM t_table WHERE a BETWEEN 2 AND 8 AND b = 2,联合索引(a, b)哪一个字段用到了联合索引的 B+Tree?
Q3 查询条件中 a BETWEEN 2 AND 8 的意思是查询 a 字段的值在 2 和 8 之间的记录。
不同的数据库对 BETWEEN ... AND 处理方式是有差异的。在 MySQL 中,BETWEEN 包含了 value1 和 value2 边界值,类似于 >= and =<。而有的数据库则不包含 value1 和 value2 边界值(类似于 > and <)。
这里我们只讨论 MySQL。由于 MySQL 的 BETWEEN 包含 value1 和 value2 边界值,所以类似于 Q2 查询语句,因此Q3 这条查询语句 a 和 b 字段都用到了联合索引进行索引查询。
我们也可以在执行计划中的 key_len 知道这一点。执行计划如下:
可以看到 key_len 为 8 字节,说明优化器使用了 2 个字段的查询条件来形成扫描区间的边界条件,也就是 a 和 b 字段都用到了联合索引进行索引查询。
通过 Q3 查询语句我们可以知道,虽然 a 字段使用了 BETWEEN 进行范围查询,但是联合索引的最左匹配原则并没有在遇到 a 字段的范围查询( BETWEEN)后就停止匹配了,b 字段还是可以用到了联合索引的。
例子四
Q4: SELECT * FROM t_user WHERE name like 'j%' and age = 22,联合索引(name, age)哪一个字段用到了联合索引的 B+Tree?
由于联合索引(二级索引)是先按照 name 字段的值排序的,所以前缀为 ‘j’ 的 name 字段的二级索引记录都是相邻的, 于是在进行索引扫描的时候,可以定位到符合前缀为 ‘j’ 的 name 字段的第一条记录,然后沿着记录所在的链表向后扫描,直到某条记录的 name 前缀不为 ‘j’ 为止。
所以 a 字段可以在联合索引的 B+Tree 中进行索引查询,形成的扫描区间是['j','k')。注意, j 是闭区间。如下图:
虽然在符合前缀为 ‘j’ 的 name 字段的二级索引记录的范围里,age 字段的值是「无序」的,但是对于符合 name = j 的二级索引记录的范围里,age字段的值是「有序」的(因为对于联合索引,是先按照 name 字段的值排序,然后在 name 字段的值相同的情况下,再按照 age 字段的值进行排序)。
于是,在确定需要扫描的二级索引的范围时,当二级索引记录的 name 字段值为 ‘j’ 时,可以通过 age = 22 条件减少需要扫描的二级索引记录范围(age 字段可以利用联合索引进行索引查询的意思)。也就是说,从符合 name = 'j' and age = 22 条件的第一条记录时开始扫描,而不需要从第一个 name 为 j 的记录开始扫描 。如下图的右边:
所以,Q4 这条查询语句 a 和 b 字段都用到了联合索引进行索引查询。
我们也可以在执行计划中的 key_len 知道这一点。本次例子中:
name 字段的类型是 varchar(30) 且不为 NULL,数据库表使用了 utf8mb4 字符集,一个字符集为 utf8mb4 的字符是 4 个字节,因此 name 字段的实际数据最多占用的存储空间长度是 120 字节(30 x 4),然后因为 name 是变长类型的字段,需要再加 2,也就是 name 的 key_len 为 122。
age 字段的类型是 int 且不为 NULL,key_len 为 4。
Q4 查询语句的执行计划如下:
可以看到 key_len 为 126 字节,name 的 key_len 为 122,age 的 key_len 为 4,说明优化器使用了 2 个字段的查询条件来形成扫描区间的边界条件,也就是 name 和 age 字段都用到了联合索引进行索引查询。
通过 Q4 查询语句我们可以知道,虽然 name 字段使用了 like 前缀匹配进行范围查询,但是联合索引的最左匹配原则并没有在遇到 name 字段的范围查询( like 'j%')后就停止匹配了,age 字段还是可以用到了联合索引的。
小结
网上传来穿去这句话:「联合索引的最左匹配原则会一直向右匹配直到遇到范围查询(>、<、between、like) 就会停止匹配」并不是对的。
经过实验的证明,我得出的结论是这样的:
联合索引的最左匹配原则,在遇到范围查询(如 >、<)的时候,就会停止匹配,也就是范围查询的字段可以用到联合索引,但是在范围查询字段后面的字段无法用到联合索引。注意,对于 >=、<=、BETWEEN、like 前缀匹配的范围查询,并不会停止匹配。




![实现极坐标图表QPolarChart的角度轴范围是[0,360]时,0度在水平右侧](https://img-blog.csdnimg.cn/5aadcf4575cd4b3db243934e48e2f7d2.png)


![[Linux] shell脚本之循环](https://img-blog.csdnimg.cn/5acc1a6822b9428b9c880c2090fe03ee.png)