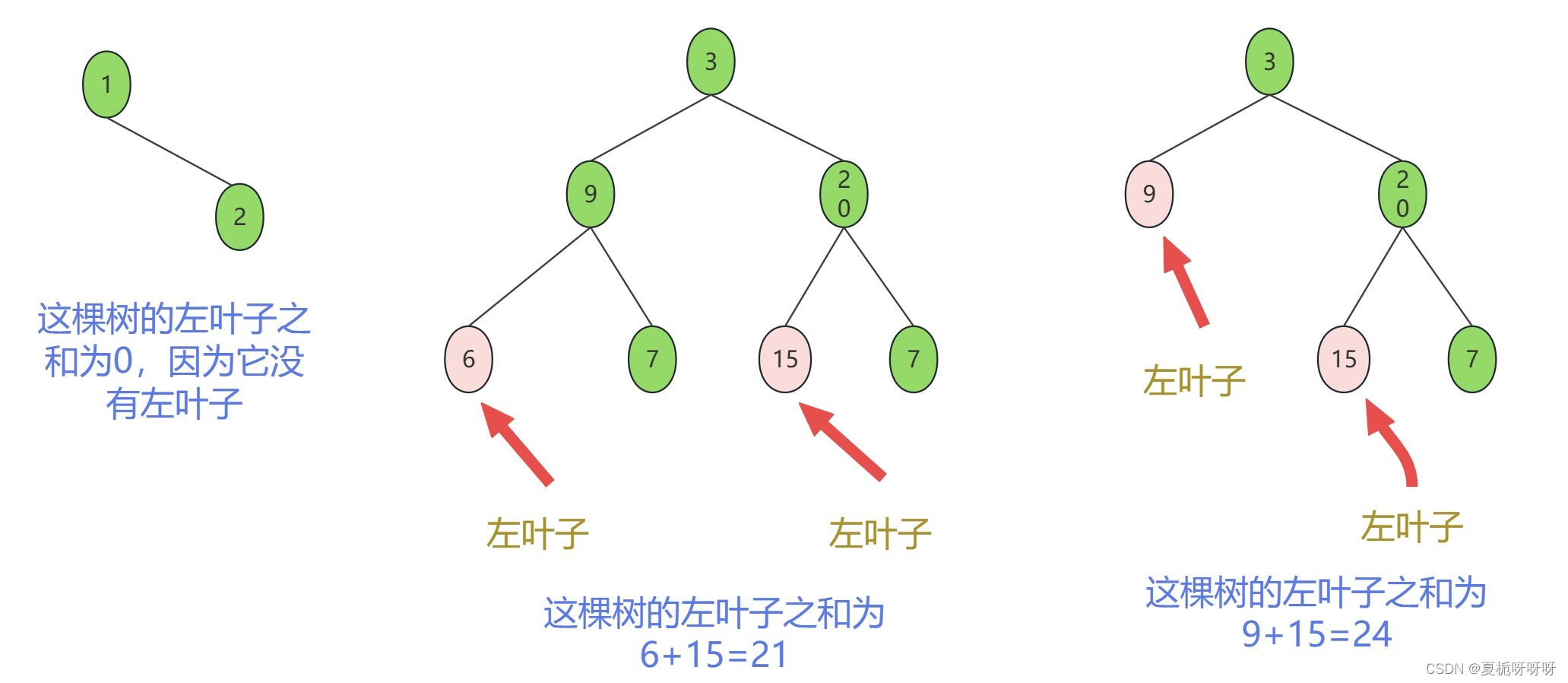
医院运维有多忙?
医院运维,听起来平平无奇毫不惊艳,但其中的含金量,可不是“维持系统正常运行”就能总结的。毕竟医院对业务连续性的超高要求,让运维面对的问题都是暂时的,下一秒可能就有新问题需要发现解决。

医疗信息化不断提高,各类设备、终端数量呈爆发式增长。IT运行环境日趋复杂,系统间关联逐渐加深,机房管理、系统监控...运维工作加量不加价。在保障信息系统高可用,稳定与安全之间,信息部门选择所有。

当我们试图解决医院棘手的运维问题,就要去做系统性建设。安徽某三甲医院携手LinkSLA智能运维平台,已经走过四个年头,早早完成从传统运维到智能运维的升级,不仅改善对业务系统的支撑,同时帮助运维工作提质增效。
医院运维能力提升主要集中在三个方面:
1、全栈资源统一监控
涵盖多类型、品牌监测,支撑大规模复杂数据的关联分析,一个界面了解医院所有IT资源运行状态。
- IT资源可视化呈现和分析能力
数据呈现更灵活,将网络拓扑、关键性能指标、系统健康状态和警报信息等可视化呈现,提供数据的图形展示,运维人员可快速掌握和分析信息。
- 故障的快速定位与恢复,保障业务连续性。
实时自动巡检,准确定位故障节点,将故障处理时效从小时级降至分钟级。自动识别并分析业务及关联资源的常见故障,变被动响应为主动预防,有效降低故障发生率。
该用户上周罕见的频发告警故障,平台通过及时的告警和服务响应,帮助用户快速解决故障保障业务系统的稳定健康。客户表示虽然告警变多了,但是平台比他更主动,出手更快。很享受这种可控、可靠的服务。

解决nutanix节点内存使用率高问题
宿主机的内存使用率看似微不足道,实际检查起来费时费力,很多用户会过滤掉,不愿为这种小事每天做例行检查。但是小问题也会引发大事件,严重可导致非计划停机,大面积的业务中断。
上周一16:55分,平台收到该客户Nutanix-Hypervisor内存使用率超出阈值告警。
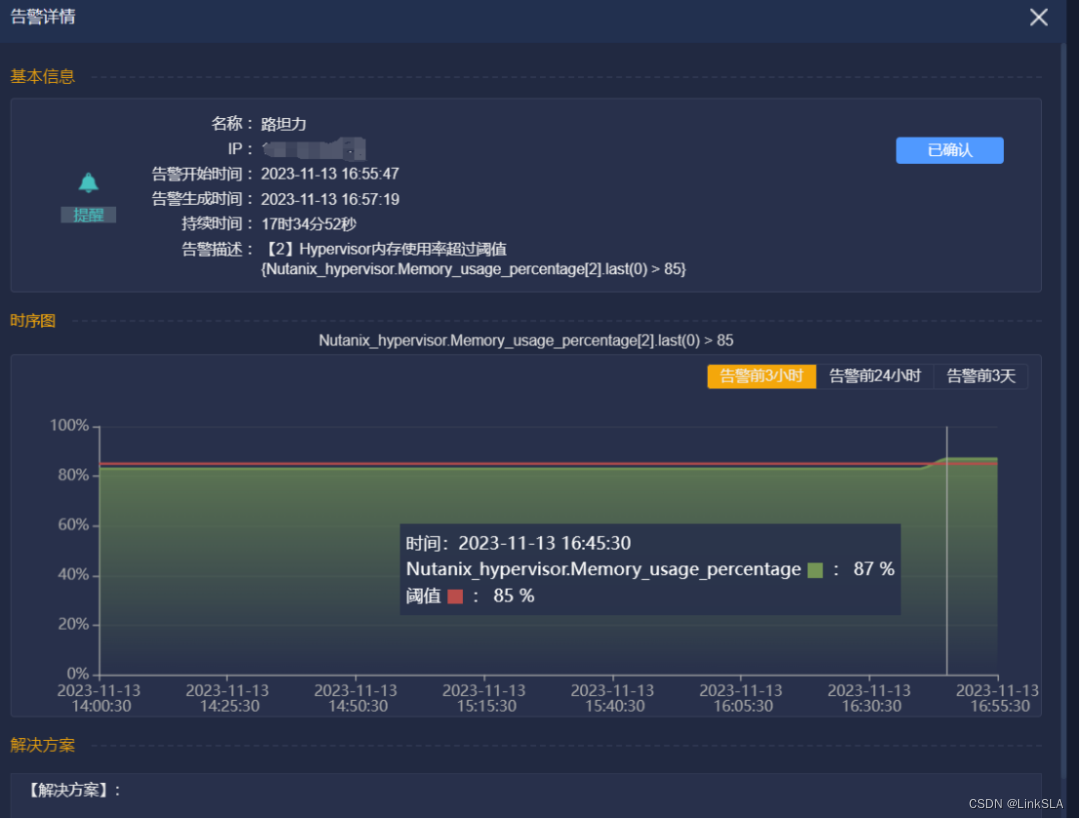
MOC工程师通知现场工程师处理,提醒内存使用过高,建议将部分虚拟机迁移,从02节点迁移至01节点。

虚拟机迁移后,告警问题得以解除。平台通过moc7*24在线值守,帮助客户更轻松高效运维,提前告知客户,做好空间规划与清理,有效避免小事情造成大麻烦。
解决HIS数据库日志空间满问题
周二14:22,平台收到HIS数据库日志文件空间使用率过高告警,THIS4的日志文件增高,接近100。
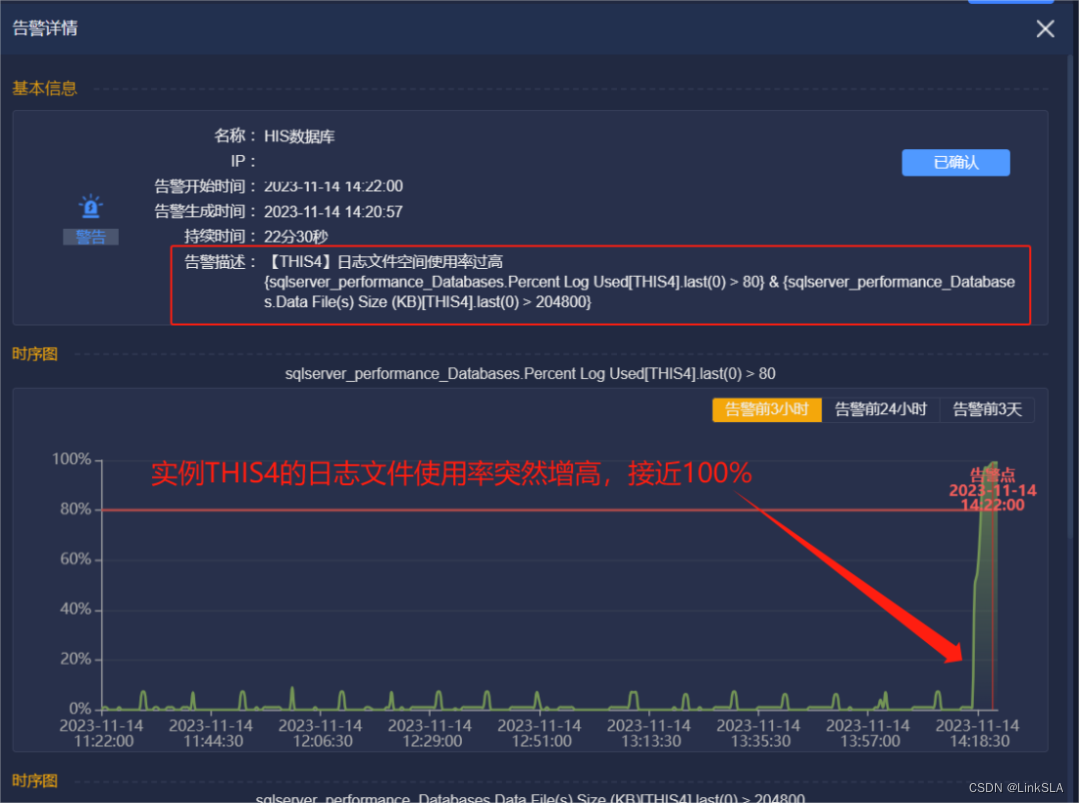
日志文件使用率阈值设为80%,过去一段时间使用率在10%左右平稳运行,根据当天时序图显示,从14:20开始,短短5分钟THIS实例的日志文件就从2.74G火速上升到28.86G,日志文件异常暴增,背后到底发生啥?让moc带我们走进现场。
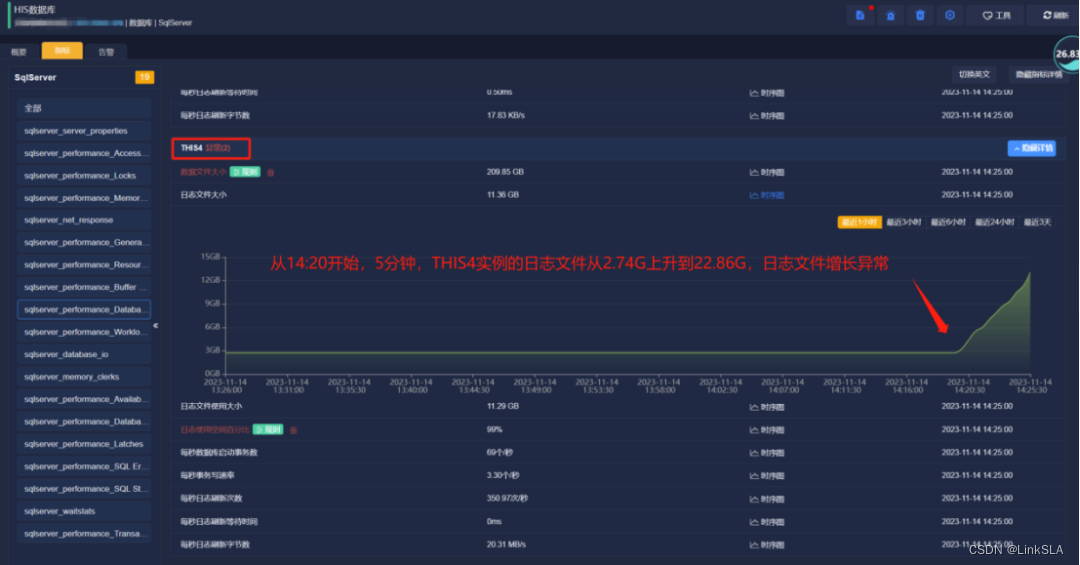
MOC工程师第一时间沟通现场工程师,检查故障确定因数据库差异化备份导致,数据库: COMMON、HRP_HB、MZHSZ、 NIS_MOBILE、THIS4备份完成后,磁盘空间使用率恢复正常, 告警得以解除。
分钟级的告警响应,源自于平台对每个业务组件的指标、日志进行实时监控检测,一旦触发告警moc工程师会第一时间响应,通知现场工程师直到问题解决。将隐患扼杀在萌芽状态,大大降低系统宕机风险。
解决C盘IO繁忙率高问题
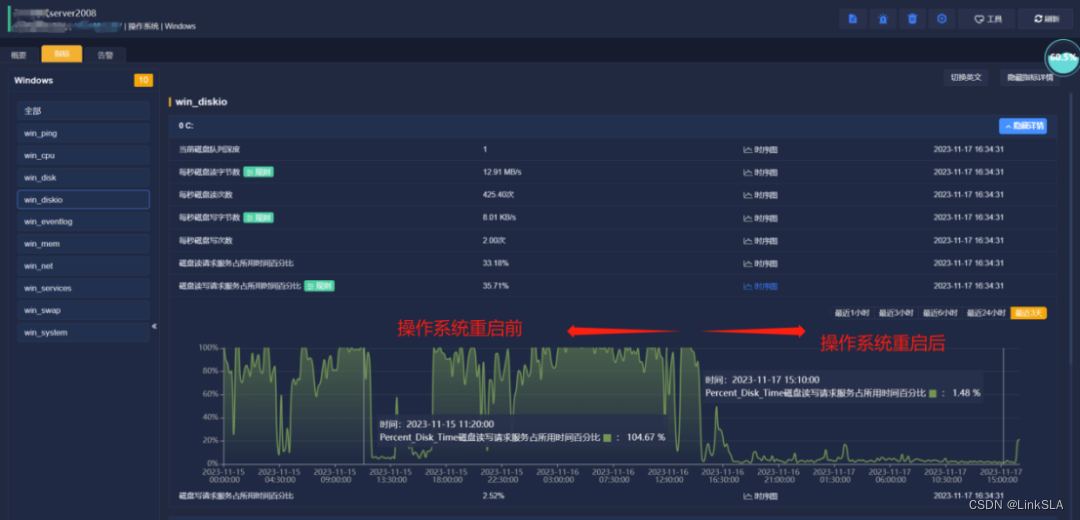
周三7:18,【OC】磁盘繁忙率超过阈值,C盘读写请求服务占所用时间百分比"Percent_Disk_Time"大于90%,逼近100%。

moc工程师初步判断两种可能。其一,C盘负载过重,导致磁盘无法及时处理所有的读写请求,其二,磁盘驱动器出现了故障或其他问题。

MOC工程师与现场工程师沟通,建议进行系统性能分析和磁盘故障排除,检查系统中的磁盘活动情况,查看进程或应用程序是否过多占用磁盘资源,尝试清理磁盘碎片,释放磁盘空间。进行病毒扫描,确保系统没有受到恶意软件的影响。如果是硬件故障,可能需要更换磁盘或进行维修。
通过现场工程师排查,最终得出由于部署服务反复停止和重启导致C占用率过高导致,重启服务器后恢复正常
LinkSLA改变传统人工排查故障的方式,通过实时自动巡检,一站式的数据管理分析,快速定位响应告警,效率大幅提升。传统需要供应商多次沟通才能完成故障定位修复,甚至耗时1个月以上时间,基于平台的监控数据以及专家支持,故障发现定位恢复时间缩短至小时级。
此外,通过MOC工程师,客户可以轻松使用平台,无需时刻紧盯监控,也能掌握平台运行状态,遇到突发问题,moc会第一时间通知,协助故障定位和提供解决方案,真正做到事前有御防,事中有保障,事后有总结。LinkSLA智能运维改善信息部门对业务系统的支撑能力,同时大幅降低运维人员的工作强度,使其将更多精力用于运维管理,未来医院发力智慧医疗,也将受益智能运维的高效工作,收获长期价值。