云布道师
本文根据 2023 云栖大会演讲实录整理而成,演讲信息如下:
演讲人:姜伟华 | 阿里云计算平台事业部资深技术专家、阿里云实时数仓 Hologres 研发负责人
演讲主题:Hologres Serverless 之路——揭秘弹性计算组
实时化成为了大数据平台的核心演进趋势,而其中 Serverless 技术可以让企业在实时场景取的性能、成本、高可用之间的平衡。2023 年云栖大会上,阿里云实时数仓Hologres 研发负责人姜伟华介绍了一站式实时数仓 Hologres 在 6 年研发期间的Serverless 演进之路,让客户实时数仓成本降低 70%-120%,开发效率提升 100%,性能提升 100-200%。
一站式实时数仓 Hologres
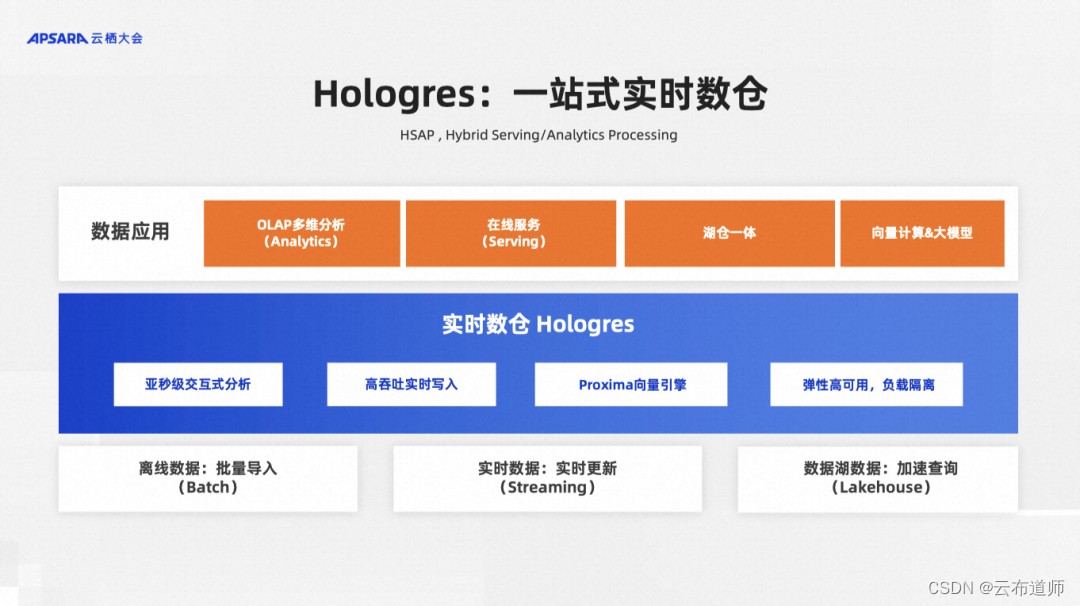
首先向大家简单介绍下 Hologres。Hologres 是阿里云自研一站式实时数仓,以分析服务一体化架构,统一数据平台架构,实现一份数据,同时支持支持多维分析、在线服务、湖仓一体、向量计算多个场景,其中包含了:
- 多维分析(实现同 CK、Doris 等查询场景) 数据高性能实时写入、更新与查询,实现写入即可查,支持列存、内置索引加速
- 在线服务(实现同 Hbase、Redis 等点查场景) 超高 QPS 下 KV 与 SQL 点查、非主键点查,支持行存、具备高可用能力
- 湖仓分析(实现同 Presto 等交互式分析场景) 无需数据搬迁,对 MaxCompute、数据湖中的表进行秒级交互式查询,元数据自动发现
- 向量计算(实现同 Faiss 等向量查询场景) 内置达摩院 Proxima 向量引擎,QPS
Serverless 实时数仓的挑战与关键技术
在一个 All in one 的一站式实时数仓架构下,像我们刚才提到的,希望一份数据,同时能支持以上四种场景,那各个业务部门、各种业务需求便随之而来,例如:
- 稳定性需求
在进行资源的扩缩容、启停时候,如何不影响实时在线的业务?
如何保证业务/任务之间的隔离?例如读写隔离、写写隔离、读隔离、任务隔离。并且是比起资源组或者资源队列来说更加干净的隔离。
如何有效利用资源?例如水平的扩展实现 QPS 的简单增加,从 500 QPS 到扩展1000 QPS 只需要简单加一倍资源即可,让资源管理更加简单。 - 成本优化需求
如何降低开发成本?例如上线新业务,基于同一份数据,但是使用新的计算资源。
如何降低资源资源?例如基于定时和负载做弹性,应对洪峰、日夜变化,用完即销毁,Endpoint 保持不变。
如何降低学习成本?例如开发接口是否通用,是否能对接主流的BI产品。
于是实时数仓在接收了这么多需求后,自然而然将 Severless 定义为平台核心演进方向,Hologres 在 年的 Serverless 演进过程中,总结下来了 4 项 Serverless 实时数仓关键技术挑战:
存算分离
不管是 Hologres, 还是说其他的大数据产品,经常讲一个词叫存算分离。为什么要做存算分离?因为存算分离是实现 Serverless 化的一个前置条件,Serverless 核心关注是计算资源的弹性,这就要求存储和计算必须分离。Hologres 从产品第一天开始,就是一个存算分离的架构。
如果不做存算分离的话有什么问题呢?传统上像 Greenplum,数据是存在本地磁盘的,而本地磁盘有一个容量限制,存满了就会有搬迁,代价很大。第二个问题是数据的访问,Serverless 本质上来说,希望计算资源随时可以拉起,然后就可以去访问数据,任何计算资源都能访问到这个数据。但如果你要存在本地的话,就不能够让任何一个计算资源访问,只有本地盘能访问。
所以在 Serverless 的情况下,一般来说数据肯定是存在一个分布式的文件系统上的。通过分布式文件系统,首先第一个是解除了容量限制,第二个任何的计算资源都可以去访问到这份数据,计算资源和存储资源都能池化。如果是一个离线数仓的话,这个问题就解决了,因为数据都在分布式文件系统上,任何计算资源都能访问到这个数据。
对于实时数仓来说有一个挑战在于数据是不是足够实时。实时数仓,我们强调一个实时性,就要求写进去的数据马上就能访问到,所以在这件事情上,不同的产品可能会有他的各自的取舍。
如果我们能容忍一个五分钟或者十分钟的查询延迟,所有的数据客户端攒 5-10 分钟后发送过来,直接写到分布式文件系统上,别的计算资源就能访问到了。但是这个对用户体验其实是很差的。因为等于说数据写了,那边查不出来(延迟 5-10 分钟)。Hologres 采用的是一个对用户比较友好的方案:写入即可查。
写入即可查是有经典方案的,就是 Mem Table +LSM Tree。比方说像 Hbase 或者其他一些产品都是采用这样一个架构,这个架构本质就是有一部分持久化的数据,这些数据是存在分布式文件系统上的,别人也能看到。但是最新的数据是在 mem Table 中的,这部分数据只有本机能看到。
同时 Hologres 支持高频的 CRUD, 就是高频的更新与删除。因为有很多应用,希望基于主键,做非常高频的更新或者删除,就要求一定要有一个主键索引。而这个主键索引一定要在内存里,否则的话就是性能跟不上。并且这个主键索引还在不停的被更新。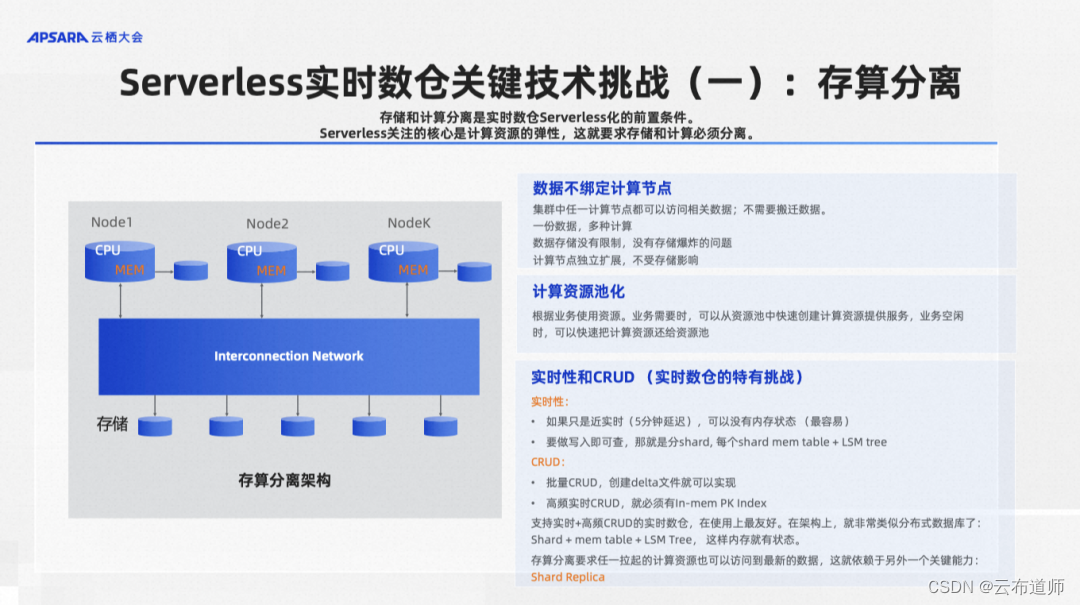
Shard Replica
Hologres 将实时写入+高频 CRUD 这两点结合,让实时数仓保持高频的实时更新或删除,且写入即可见,这样在使用体验上会非常像一个数据库,对用户非常友好。但是同时它也带来了一个新的问题,就是最新的几分钟数据是在内存里。刚才说Serverless 的场景下,我们希望任何拉起的计算资源,都能访问到这些数据。但是那些数据是在内存里的,所以这是一个很特别的挑战。Hologres 解这个问题的方法,我们称之为叫做 Shard Replica(Shard副本)。
简单来说就是每个 Shard Replica 在实现机制上,很像数据库里面的物理复制。数据库的物理复制是有一个从实例,通过同步了主实例的 write ahead log,然后重放这些 log,然后构建 B+ tree,把数据刷下去。在数据库的实现中,主从两个实例的数据也是各自存各的。Hologres 在这个地方有一个创新,Shard Replica 做了物理复制,但仅在内存中构建了自己的 MEM Table, 这样子 Shard 副本就能看到最新的数据。但是 Shard 副本是不会去 flush 数据到文件系统的。这样,分布式文件系统上的数据就只有一份。这样 Replica 通过自己的 MEM Table 与主 Shard 的存算分离的落盘数据,就可以完整的访问所有数据了,实现了实时的可见性。
副本的维护代价大概是主的 1/4 或者 1/8 的样子。
Shard Replica 能力是 Hologres 实现存算分离、高可用、容灾、高 QPS 等等的基础。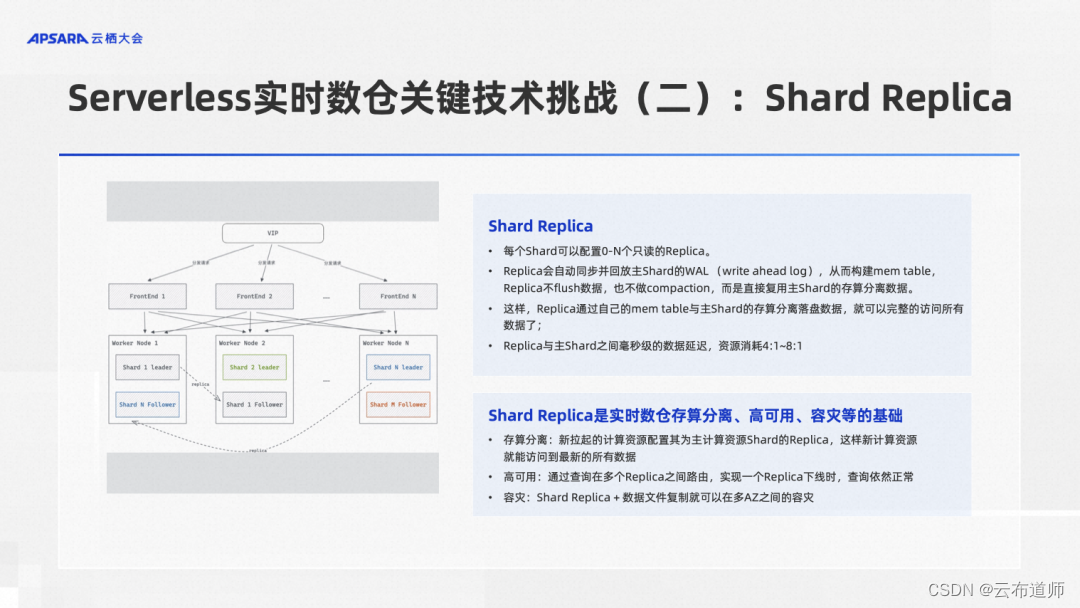
隔离与弹性
有了这个存算分离能力以后,下面怎么样做?刚才说到有了存算分离,那可以任意地拉起计算资源并访问,所以这个时候就可以做强的资源隔离,并且自然可以弹性的伸缩,也能够自适应的去响应负载。

高可用
在高可用上,实时数仓跟一般的离线数仓做 Serverless 上有一些差异。因为一般离线数仓更关注的是资源能不能用满,但实时数仓要求有很高的 SLA 保证。比方说延迟或抖动,这种都是不允许有的。我们如何能保证在强隔离的情况下,还能做到各种自由的弹性伸缩与高可用性。
离线数仓不是基于连接的,每次提交一条 SQL,执行完给出结果,然后再来一条。但是实时数仓是基于连接的,有点像数据库,在资源的变化的过程中(各种变更、扩缩容等),如何做到自动的路由负载均衡。在计算资源弹性时,连接与现有查询不受影响,在后台计算资源改变时,原有连接资源可自动路由到新的计算资源上,保证连接不断。这些能力对于 Serverless 实时数仓来说非常有挑战性。
Hologres 的 Serverless 演进之路
刚才说到的这些难题与挑战,Hologres 也不是一下子解决的,接下来我们向大家介绍下 Hologres 在 6 年的发展中,在 Serverless 是如何逐步演进的,希望能和大家有一些交流。
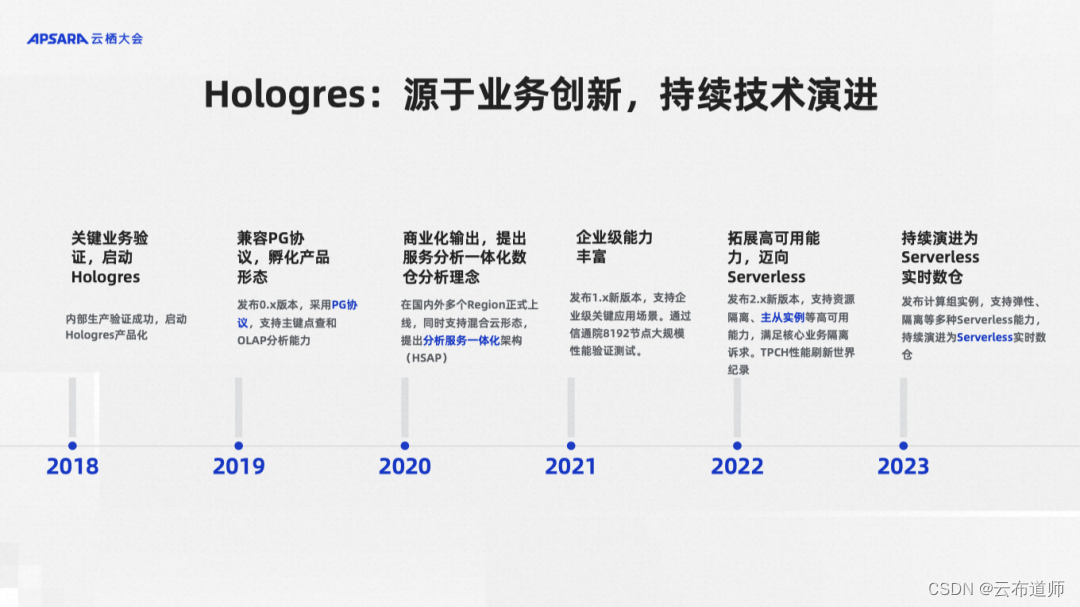
2018 年 Hologres 在阿里内部立项。2019 年产品化并在阿里集团内部大规模使用。到 2020 年,我们在阿里云上正式商业化,并且在业界第一个提出了分析服务一体化。到了 2021 年我们主要增强一些企业级的能力。2022 年 Hologres 重点发布了主从实例。主从实例是我们 Serverless 演进过程中的一个关键步骤,有非常多的客户在生产环境中用上了我们的主从实例,实现了一份数据,多种计算。跟传统数据库的主从不一样,它的数据只有一份,因为大数据场景下数据量很大,对用户来说一份数据可以极大地节约存储成本。同时存算分离下的主从实例,允许大家为不同的业务,快速的拉起一个从实例干不同的工作,如果不需要的话,也可以快速地把它给销毁掉,没有任何数据搬迁的过程。到了 2023 年我们正式发布计算组实例。是Hologres 面向完全的 Serverless 化的基本产品形态。
阶段一:独享实例
独享实例是 Hologres 常用的形态,基于之前我们提到的存算分离架构,底下是阿里盘古文件系统,上面是计算实例,用户想要扩容、缩容都非常方便,不需要做数据搬迁。但是唯一的问题是用户必须要小心翼翼地控制规格大小,比方 QPS 压力太大了,那你就要扩容,不能做到资源按需使用,按需付费。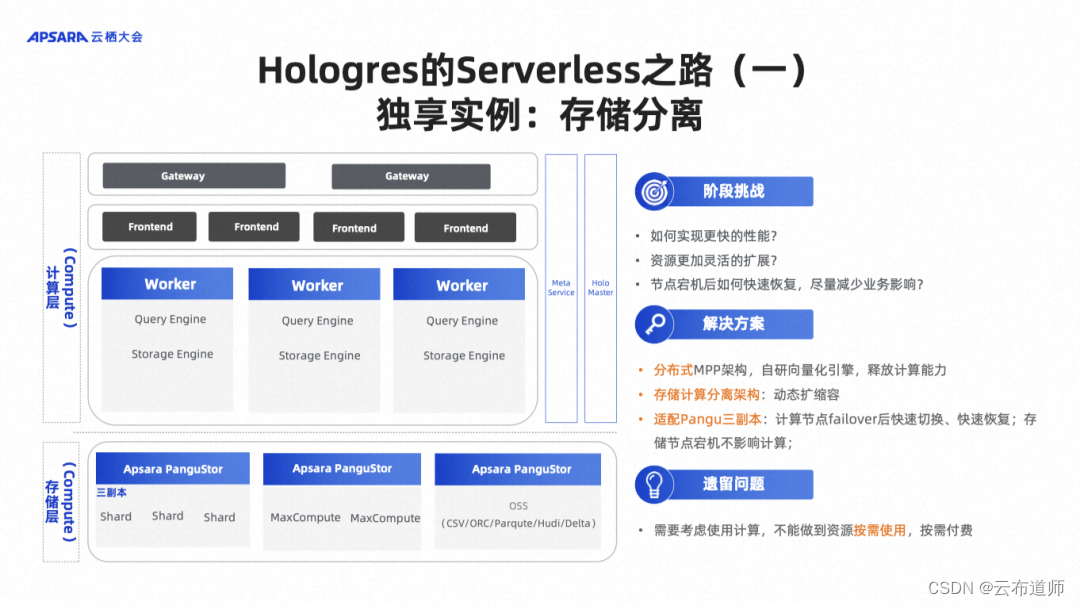
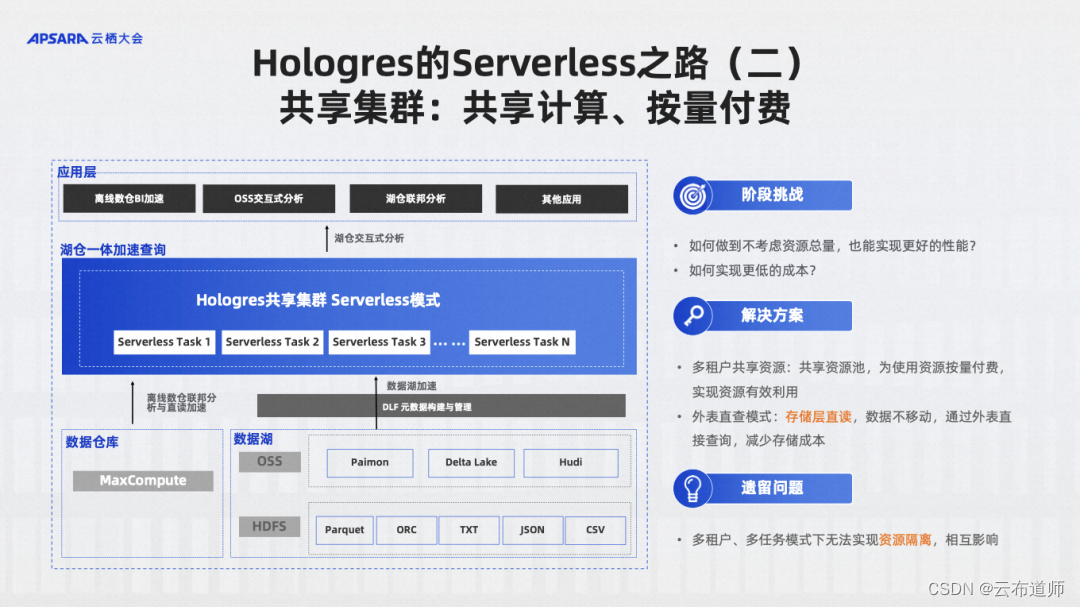
阶段二:共享集群
Hologres 在 2020 年就推出了一个完全 Serverless 化的湖仓共享集群,它是不带存储,只会按量收取计算费用。首先 Hologres 与离线数仓 MaxCompute 做了一体化的融合,如果想要更快地查询 MaxCompute 中的离线数据,不需要将数据导出,也不需要预留任何资源,运行一条 SQL 直接查询就可以,最终只按照 SQL 查询量收费,用户在不使用的时候,不会收任何的费用,也不需要任何的启停操作。这是我们做的非常彻底 Serverless 的产品,不仅仅是 MaxCompute 中的数据,还可以查询 OSS 中数据湖的数据。
共享集群仅适用离线数仓与数据湖加速查询的场景,没有很好的 SLA 的保证。
阶段三:主从实例
为了实现资源的强隔离,同时支持一份数据、多种计算的愿景,Hologres 推出了主从实例,实现一份数据多种计算,计算之间完全隔离。
一个典型的场景:首先有一个读写的独享主实例,负责数据的写入,然后按需创建多个只读的从实例。这个创建过程非常快,没有任何数据搬迁。比方说现在线上业务在跑着,突然发现线上业务数据不太对。那怎么办呢?用户可以临时拉起一个从实例,然后在上面做数据分析,找出问题在哪里,这对用户来说是一个非常易用的一种体验。
这种场景我们做了非常强的隔离,存储层面依托盘古强大的分布式文件系统的能力,基本可以保证 IO 之间没有竞争。计算层面,我们通过 K8S 实现隔离,做到了计算之间也没有竞争。存储与计算都没有竞争,让用户实现了很干净的强隔离,体验也非常好。我们见过最多的一个客户是一主九从,挂了非常多的从实例干各种各样的事情,比如分配一个从实例给经常做分析的同事,或者分配一个从实例给某个特定部门。
但是这种主从实例也有它的问题,由于每一个都是一个独立的实例,每个都有一个入口,用户如果要用新的从实例,必须要去改他的代码,把代码指向这个新的实例才能用起来,这样用户体验就不够好,不够灵活,所以今年我们正式推出了计算组实例。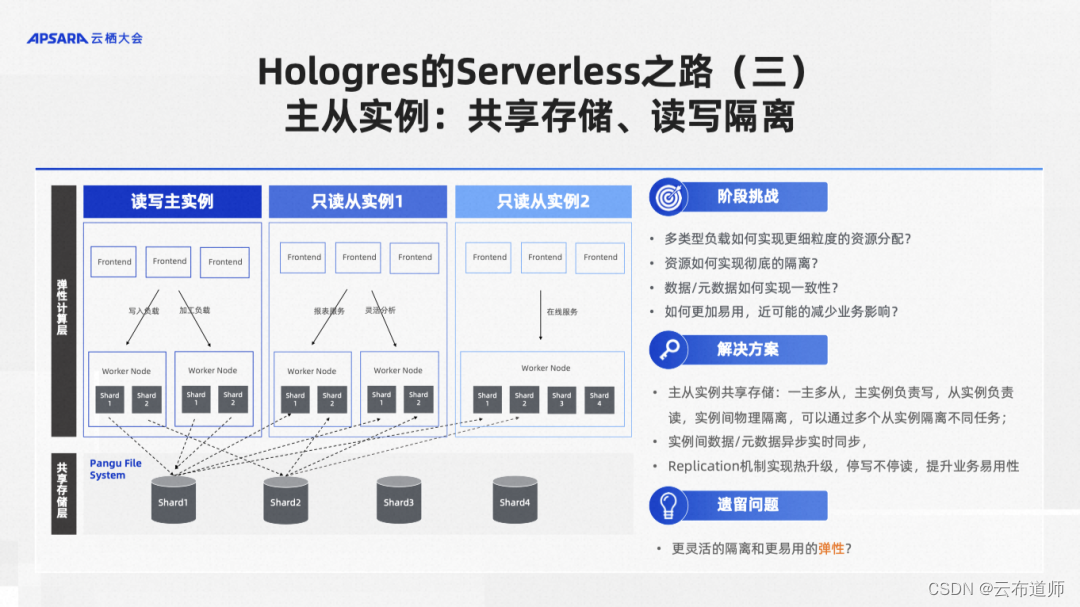
阶段四:计算组实例
计算组实例内部有多个计算组,计算组之间还是强隔离,但是它是一个实例,有一个统一的路由,于是在计算组内部,各种强隔离、弹性自动路由等等都可以做了。
计算组上面有一个 gateway, 这是一个网关,用户所有的请求都会通过这个网关打过来。下面的计算组跟刚才的从实例很像。每个计算组都是一组独立的计算资源。计算组和计算组之间是强隔离的,由网关来进行这个任务的路由。这样对用户来说永远看到的是同一个网关。所有的弹性扩缩容等操作,都是管理员做的事情,对用户来说是无感的,也解决了我们在主从实例中留下的不够灵活的问题。
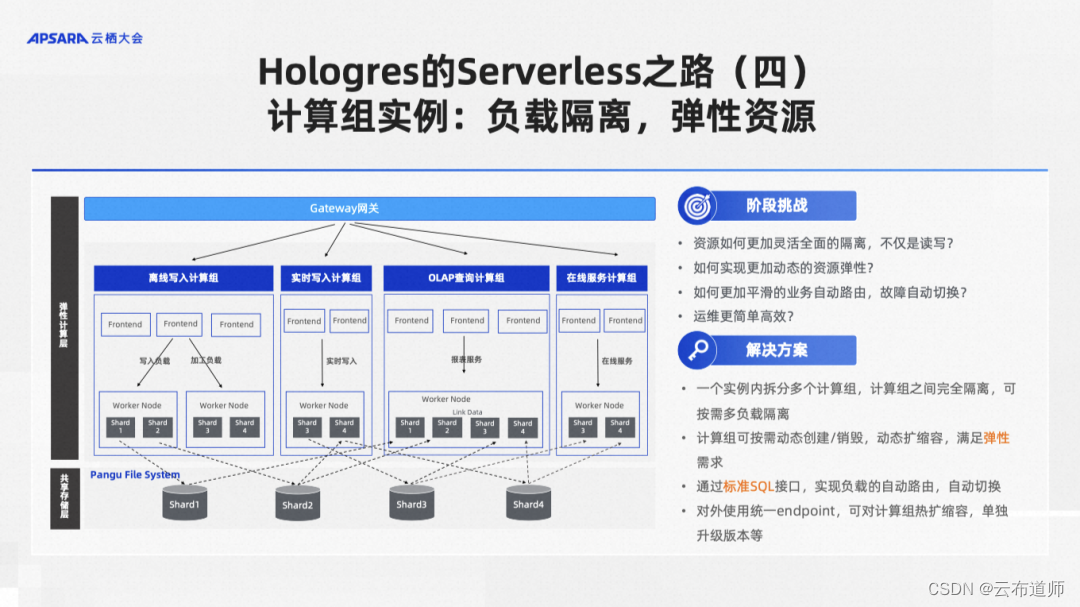
举几个典型应用场景:
- 计算组实例应用:动态扩容
一般我们分 2 个计算组,包括默认计算组和查询计算组,其中默认计算组只承担写入&ETL 等流程,查询计算组负责对外查询,实现读写隔离。当实时数仓使用人更多,服务更多部门时,读写隔离不能完全满足需求,写入与写入之间会有资源争抢,查询之间也有资源争抢。我们就可以需要提供扩容多种计算组,比如离线写入计算组、实时写入计算组、OLAP 查询计算组、在线服务计算组,实现不同场景/业务之间的完全隔离。
- 计算组实例应用:弹性伸缩
在大促或者某些场景下,我们经常遇到资源不足的情况,当流量洪峰来临时,根据业务需求对单个计算组扩容,低峰期对计算组进行缩容,同时系统支持热扩缩容方式,将业务影响降到最低,并且防止资源的浪费。
- 计算组实例应用:自动路由
某一个计算组出了问题或者压力太大发生 Failover 后,影响业务,需要快速止血时,我们希望给它减少流量或者完全停掉。原来是解不了这个问题,用户只能改应用程序。现在管理员只需要通过 SQL 命令实现自动路由机制,无需改动应用接口,快速将 Failover 计算组的负载路由至默认/指定计算组,实现业务快速恢复。
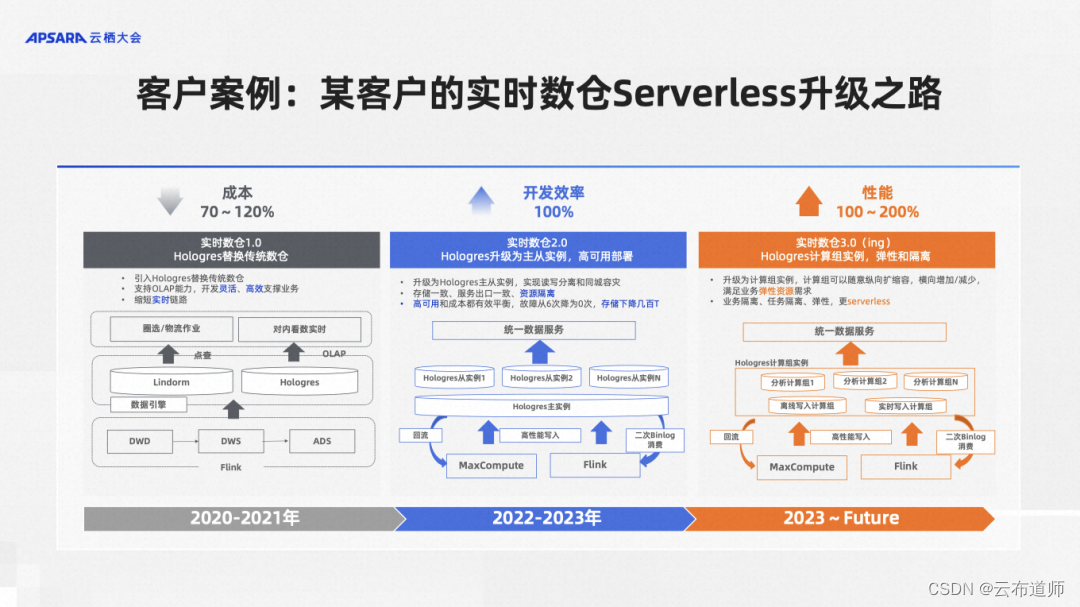
客户案例: 某客户Serverless实时数仓升级之路
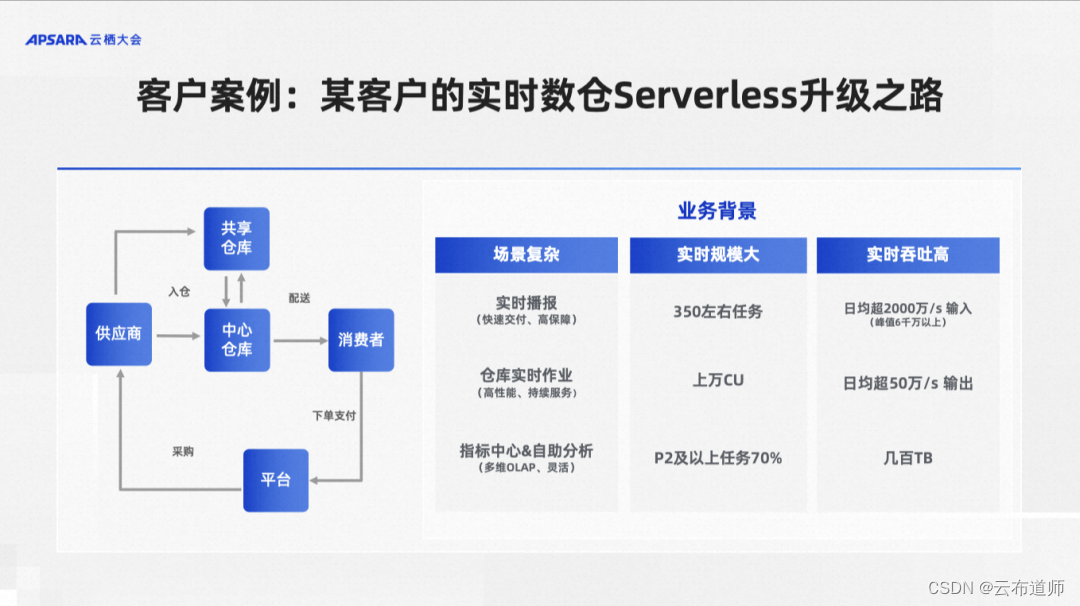
刚才我们是从 Hologres 自身的视角来看待实时数仓的发展与演进,最后我们来看一个我们长期的资深用户是如何一步一步基于 Hologres 来做自己业务实时数仓的升级与 Serverless 化的。
这是一个物流的客户,他们业务主要做仓储的管理,有好几类业务,第一类业务叫实时播报,需要一个快速开发的,高保障的一个业务。第二个业务就是仓库的各种实时作业,指导仓库这种货放到哪里去等等,需要一个作业调度系统,要求高性能并且要持续服务高 SLA 的保证。第三类像传统的大屏,或者说类似指标中心的自助分析,要求更强的灵活性。整体业务规模上,大概有 350 个左右的实时任务,消耗 1 万 CU,量非常大。同时 P2 级以上的重点任务占了 70%,对 SLA 的要求也非常高。从性能要求上,日均大概是每秒钟写入 2000 万条记录,峰值能达到每秒 6000 万条,然后每秒输出大概 50 万条记录,整体的实时吞吐性能非常高。
可以看到这是一个业务复杂,对性能、SLA、成本等都有非常多要求的客户场景。
实时数仓 1.0-Hologres 替换传统数仓
最早的时候实时数仓 1.0,底下实时数据从 DWD 到 DWS 到 ADS, 这个加工层是通过消息队列 Kafka 加上 Flink 来做的。他们会把结果数据同时写两个地方,一个是 Lindorm,类似于 Hbase,因为刚才我们提到的物流库存作业是一个高稳定性保障业务,所以他用这个来对外提供点查的能力。同时将数据写入 Hologres,提供交互式分析与 OLAP 查询等服务。
实时数仓 2.0-Hologres 升级主从实例,高可用部署
2022 年随着 Hologres 推出了主从实例,他们做了一次架构的变更。首先,从实时数据加工链路上,本来 Flink+Kafka 实现的 DWD、DWS、ADS 层加工,现在改成用 Hologres+Flink 来做,把 DWD 层写到 Hologres 里面去,同时 Flink 订阅Hologres 的 Binlog。这样任何一张表的变更,Flink 都能感知到。Flink 加工得到的 DWS 层再写到 Hologres 里面去。然后再通过 Flink 订阅 Binlog, 加工 ADS 层写到 Hologres 里面去。这时候大家可能觉得这个场景有点奇怪,为什么要这么搞来搞去。其实这个架构最大的好处是,每一层数据都是可查可对外服务的。原来架构中,数据在 Kafka 中,只能给 Flink 用。如果数据有问题,要去查一下问题都很困难。而在这个架构中,每一层的数据都是 Hologres 对外提供服务的。不需要数据冗余,同一份数据既可以给 Flink 应用,也可以对外提供服务。
同时,为了支持隔离与高可用,他们建了好几个从实例来给不同的业务用。需要的时候就再创建一个。实现了读写分离和同城容灾,故障从 6 次降为 0 次,存储下降几百 T,开发效率提升 100%。
实时数仓 3.0(ing)-Hologres 计算组实例,弹性和隔离
2023 年随着我们推出了计算组实例后,他们把整个主从实例替换成了计算组实例。通过拉起不同的计算组,统一对外提供服务。整个实时数仓的架构更加 Serverless化,拉起一个新的计算组,不再需要去改应用,每个计算组又能提供很好的隔离。
最后讲一下我们对未来趋势的一些看法,,虽然 Hologres 推出了计算组实例,坦率地说这只是我们 Serverless 化的开始。作为一个云产品,我们希望让客户通过 Serverless,使用起来更简单,成本更低。因此我们在未来主要有两个目标,第一个是 Down To Zero,简单来说,当用户不用任何计算的时候,不问用户收取任何计算的费用。并且在这种情况下,如果有请求进来,计算资源能秒级恢复并响应,并不是说停掉了以后请求来了就断掉了。第二个目标,我们希望能够把独享实例和共享实例统一在一起,变成一个统一的对外的形态,实现自助资源切换。最终用户在没有计算的时候可以不花一分钱,请求来了能及时响应,业务变化又能灵活满足多种资源需求,这是我们希望给用户提供的终极形态。
除了 Severless,Hologres 在本次云栖大会还将物化视图升级 DynamicTable 进行升级,与 Flink 结合构建流批一体的数仓分层架构,用户只需描述数据的应用场景、产生逻辑、实时性要求、分层依赖,DynamicTable 负责高效的一体化工程实现,保持数据高性能的实时写入、实时更新、实时查询,解决离线实时重复开发、数据不一致,学习成本搞,运维复杂等难题。
在淘天集团直播数据决策分析产品中,Dynamic Table 数仓分层架构让实时数仓整体性能提升 200%,延迟下降 85%,在淘天集团营销活动分析场景中,Dynamic Table 数仓分层架构让实时性能提升 30%,离线性能提升 800%,这个功能在不久之后也会在公共云开放给客户使用。
可以看到无论是 Serverless 还是物化视图的升级,Hologres 在演进过程中始终紧紧围绕实时场景,不断提高实时数仓的性能、可用性、用户体验。Hologres 希望替换企业纷繁芜杂的数仓架构,通过一站式的理念让实时数仓更加干净、友好、高效,并帮助企业不断降低成本,加速数字化转型升级。






![C题目11:数组a[m]排序](https://img-blog.csdnimg.cn/bcc4787ddf2e4c38aad703b004675e58.png)