kafka权限认证 topic权限认证 权限动态认证-亲测成功
kafka动态认证 自定义认证 安全认证-亲测成功
MacBook Linux安装Kafka
Linux解压安装Kafka
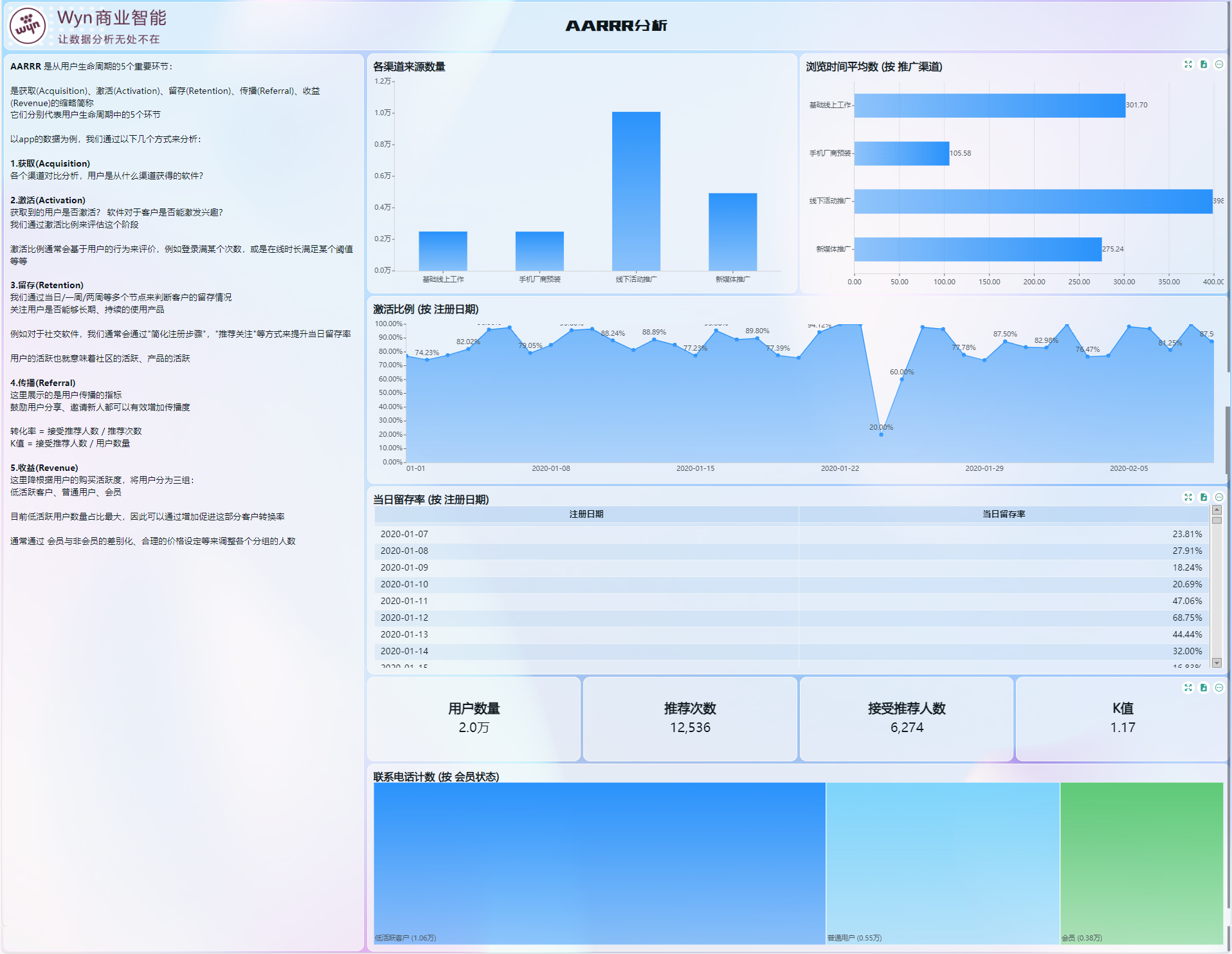
介绍
1、Kafka的权限分类
-
身份认证(Authentication):对client 与服务器的连接进行身份认证,brokers和zookeeper之间的连接进行Authentication(producer 和 consumer)、其他 brokers、tools与 brokers 之间连接的认证。上一篇博文介绍了连接的身份认证。
-
权限控制(Authorization):实现对于消息级别的权限控制,clients的读写操作进行Authorization:(生产/消费/group)数据权限。这节我们讲解Topic权限的控制。
kafka配置自定义权限认证
修改配置文件,在kafka主目录下,D:\kafka_2.12-3.5.0\config\server.properties
enable_db_acl = true
authorizer.class.name=com.liang.kafka.auth.handler.MyAclAuthorizer
super.users=admin;liang
druid.name = mysql_db
druid.type = com.alibaba.druid.pool.DruidDataSource
druid.url = jdbc:mysql://127.0.0.1:3306/test?useSSL=FALSE&useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Shanghai
druid.username = root
druid.password = root
druid.filters = stat
druid.driverClassName = com.mysql.cj.jdbc.Driver
druid.initialSize = 5
druid.minIdle = 2
druid.maxActive = 50
druid.maxWait = 60000
druid.timeBetweenEvictionRunsMillis = 60000
druid.minEvictableIdleTimeMillis = 300000
druid.validationQuery = SELECT 'x'
druid.testWhileIdle = true
druid.testOnBorrow = false
druid.poolPreparedStatements = false
druid.maxPoolPreparedStatementPerConnectionSize = 20
其中:
- enable_db_acl用来控制是否开启动态权限认证。
- authorizer.class.name配置自定义权限的类
windows完整配置如下:
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
#
# This configuration file is intended for use in ZK-based mode, where Apache ZooKeeper is required.
# See kafka.server.KafkaConfig for additional details and defaults
#
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id=0
############################# Socket Server Settings #############################
# The address the socket server listens on. If not configured, the host name will be equal to the value of
# java.net.InetAddress.getCanonicalHostName(), with PLAINTEXT listener name, and port 9092.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
#listeners=PLAINTEXT://:9092
# Listener name, hostname and port the broker will advertise to clients.
# If not set, it uses the value for "listeners".
#advertised.listeners=PLAINTEXT://your.host.name:9092
advertised.listeners=SASL_PLAINTEXT://localhost:9092
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
#listener.security.protocol.map=PLAINTEXT:PLAINTEXT,SSL:SSL,SASL_PLAINTEXT:SASL_PLAINTEXT,SASL_SSL:SASL_SSL
sasl.enabled.mechanisms = PLAIN
sasl.mechanism.inter.broker.protocol = PLAIN
security.inter.broker.protocol = SASL_PLAINTEXT
listeners = SASL_PLAINTEXT://localhost:9092
enable_db_acl = true
authorizer.class.name=com.liang.kafka.auth.handler.MyAclAuthorizer
super.users=admin;liang
enable_db_auth = true
listener.name.sasl_plaintext.plain.sasl.server.callback.handler.class=com.liang.kafka.auth.handler.MyPlainServerCallbackHandler
druid.name = mysql_db
druid.type = com.alibaba.druid.pool.DruidDataSource
druid.url = jdbc:mysql://127.0.0.1:3306/testdb?useSSL=FALSE&useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Shanghai
druid.topic.url = jdbc:mysql://127.0.0.1:3306/topicdb?useSSL=FALSE&useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Shanghai
druid.username = root
druid.password = root
druid.filters = stat
druid.driverClassName = com.mysql.cj.jdbc.Driver
druid.initialSize = 5
druid.minIdle = 2
druid.maxActive = 50
druid.maxWait = 60000
druid.timeBetweenEvictionRunsMillis = 60000
druid.minEvictableIdleTimeMillis = 300000
druid.validationQuery = SELECT 'x'
druid.testWhileIdle = true
druid.testOnBorrow = false
druid.poolPreparedStatements = false
druid.maxPoolPreparedStatementPerConnectionSize = 20
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=D:\kafka_2.12-3.5.0\kafka-logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
#log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=localhost:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
# The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
group.initial.rebalance.delay.ms=0
Linux下完整配置如下
# Licensed to the Apache Software Foundation (ASF) under one or more
# contributor license agreements. See the NOTICE file distributed with
# this work for additional information regarding copyright ownership.
# The ASF licenses this file to You under the Apache License, Version 2.0
# (the "License"); you may not use this file except in compliance with
# the License. You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# see kafka.server.KafkaConfig for additional details and defaults
############################# Server Basics #############################
# The id of the broker. This must be set to a unique integer for each broker.
broker.id = 999
############################# Socket Server Settings #############################
# The address the socket server listens on. It will get the value returned from
# java.net.InetAddress.getCanonicalHostName() if not configured.
# FORMAT:
# listeners = listener_name://host_name:port
# EXAMPLE:
# listeners = PLAINTEXT://your.host.name:9092
# listeners=PRIVATE://:9092,PUBLIC://:9093
sasl.enabled.mechanisms = PLAIN
sasl.mechanism.inter.broker.protocol = PLAIN
security.inter.broker.protocol = SASL_PLAINTEXT
listeners = SASL_PLAINTEXT://:9092
enable_db_acl = true
authorizer.class.name=com.liang.kafka.auth.handler.MyAclAuthorizer
super.users=admin;liang
enable_db_auth = true
listener.name.sasl_plaintext.plain.sasl.server.callback.handler.class=com.liang.kafka.auth.handler.MyPlainServerCallbackHandler
druid.name = mysql_db
druid.type = com.alibaba.druid.pool.DruidDataSource
druid.url = jdbc:mysql://192.168.1.77:3306/testdb?useSSL=FALSE&useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Shanghai
druid.topic.url = jdbc:mysql://192.168.1.77:3306/topicdb?useSSL=FALSE&useUnicode=true&characterEncoding=UTF-8&allowMultiQueries=true&serverTimezone=Asia/Shanghai
druid.username = root
druid.password = root
druid.filters = stat
druid.driverClassName = com.mysql.cj.jdbc.Driver
druid.initialSize = 5
druid.minIdle = 2
druid.maxActive = 50
druid.maxWait = 60000
druid.timeBetweenEvictionRunsMillis = 60000
druid.minEvictableIdleTimeMillis = 300000
druid.validationQuery = SELECT 'x'
druid.testWhileIdle = true
druid.testOnBorrow = false
druid.poolPreparedStatements = false
druid.maxPoolPreparedStatementPerConnectionSize = 20
# Hostname and port the broker will advertise to producers and consumers. If not set,
# it uses the value for "listeners" if configured. Otherwise, it will use the value
# returned from java.net.InetAddress.getCanonicalHostName().
advertised.listeners = SASL_PLAINTEXT://192.168.1.77:10092
# Maps listener names to security protocols, the default is for them to be the same. See the config documentation for more details
# The number of threads that the server uses for receiving requests from the network and sending responses to the network
num.network.threads=3
# The number of threads that the server uses for processing requests, which may include disk I/O
num.io.threads=8
# The send buffer (SO_SNDBUF) used by the socket server
socket.send.buffer.bytes=102400
# The receive buffer (SO_RCVBUF) used by the socket server
socket.receive.buffer.bytes=102400
# The maximum size of a request that the socket server will accept (protection against OOM)
socket.request.max.bytes=104857600
############################# Log Basics #############################
# A comma separated list of directories under which to store log files
log.dirs=/opt/kafka/kafka-logs
# The default number of log partitions per topic. More partitions allow greater
# parallelism for consumption, but this will also result in more files across
# the brokers.
num.partitions=1
# The number of threads per data directory to be used for log recovery at startup and flushing at shutdown.
# This value is recommended to be increased for installations with data dirs located in RAID array.
num.recovery.threads.per.data.dir=1
############################# Internal Topic Settings #############################
# The replication factor for the group metadata internal topics "__consumer_offsets" and "__transaction_state"
# For anything other than development testing, a value greater than 1 is recommended to ensure availability such as 3.
offsets.topic.replication.factor=1
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
############################# Log Flush Policy #############################
# Messages are immediately written to the filesystem but by default we only fsync() to sync
# the OS cache lazily. The following configurations control the flush of data to disk.
# There are a few important trade-offs here:
# 1. Durability: Unflushed data may be lost if you are not using replication.
# 2. Latency: Very large flush intervals may lead to latency spikes when the flush does occur as there will be a lot of data to flush.
# 3. Throughput: The flush is generally the most expensive operation, and a small flush interval may lead to excessive seeks.
# The settings below allow one to configure the flush policy to flush data after a period of time or
# every N messages (or both). This can be done globally and overridden on a per-topic basis.
# The number of messages to accept before forcing a flush of data to disk
#log.flush.interval.messages=10000
# The maximum amount of time a message can sit in a log before we force a flush
#log.flush.interval.ms=1000
############################# Log Retention Policy #############################
# The following configurations control the disposal of log segments. The policy can
# be set to delete segments after a period of time, or after a given size has accumulated.
# A segment will be deleted whenever *either* of these criteria are met. Deletion always happens
# from the end of the log.
# The minimum age of a log file to be eligible for deletion due to age
log.retention.hours=168
# A size-based retention policy for logs. Segments are pruned from the log unless the remaining
# segments drop below log.retention.bytes. Functions independently of log.retention.hours.
#log.retention.bytes=1073741824
# The maximum size of a log segment file. When this size is reached a new log segment will be created.
log.segment.bytes=1073741824
# The interval at which log segments are checked to see if they can be deleted according
# to the retention policies
log.retention.check.interval.ms=300000
############################# Zookeeper #############################
# Zookeeper connection string (see zookeeper docs for details).
# This is a comma separated host:port pairs, each corresponding to a zk
# server. e.g. "127.0.0.1:3000,127.0.0.1:3001,127.0.0.1:3002".
# You can also append an optional chroot string to the urls to specify the
# root directory for all kafka znodes.
zookeeper.connect=127.0.0.1:2181
# Timeout in ms for connecting to zookeeper
zookeeper.connection.timeout.ms=18000
############################# Group Coordinator Settings #############################
# The following configuration specifies the time, in milliseconds, that the GroupCoordinator will delay the initial consumer rebalance.
# The rebalance will be further delayed by the value of group.initial.rebalance.delay.ms as new members join the group, up to a maximum of max.poll.interval.ms.
# The default value for this is 3 seconds.
# We override this to 0 here as it makes for a better out-of-the-box experience for development and testing.
# However, in production environments the default value of 3 seconds is more suitable as this will help to avoid unnecessary, and potentially expensive, rebalances during application startup.
group.initial.rebalance.delay.ms=0
自定义实现topic权限认证
用户查询,订阅或发送topic时,判断是否有此topic的权限,订阅时有没有订阅分组的权限等。
maven项目引入相关的依赖包,pom添加如下依赖包
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.13</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>cn.hutool</groupId>
<artifactId>hutool-cache</artifactId>
<version>5.7.21</version>
</dependency>
动态topic权限认证完整代码如下:
package com.liang.kafka.auth.handler;
import cn.hutool.core.collection.CollUtil;
import com.alibaba.druid.pool.DruidDataSource;
import com.liang.kafka.auth.cache.LocalCache;
import com.liang.kafka.auth.util.DataSourceUtil;
import org.apache.kafka.common.Endpoint;
import org.apache.kafka.common.acl.AclBinding;
import org.apache.kafka.common.acl.AclBindingFilter;
import org.apache.kafka.common.acl.AclOperation;
import org.apache.kafka.common.resource.PatternType;
import org.apache.kafka.common.resource.ResourcePattern;
import org.apache.kafka.common.resource.ResourceType;
import org.apache.kafka.server.authorizer.*;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.sql.Connection;
import java.sql.PreparedStatement;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.*;
import java.util.concurrent.CompletionStage;
import java.util.stream.Collectors;
import static com.liang.kafka.auth.constants.Constants.*;
/**
* kafka acl 自定义鉴权
* 配置方法:在server.properties添加如下配置:
* super.users 超级用户,多个用;隔开
* authorizer.class.name=com.liang.kafka.auth.handler.MyAclAuthorizer
* liang
*/
public class MyAclAuthorizer implements Authorizer {
private static final Logger logger = LoggerFactory.getLogger(MyAclAuthorizer.class);
/**
* 数据源
*/
private DruidDataSource dataSource = null;
private static final String SUPER_USERS_PROP = "super.users";
/**
* 超级管理员
*/
private Set<String> superUserSet;
/**
* 是否开启数据库acl验证
*/
private boolean enableDbAcl;
@Override
public Map<Endpoint, ? extends CompletionStage<Void>> start(AuthorizerServerInfo authorizerServerInfo) {
//logger.info("------------------start");
return new HashMap<>();
}
/**
* 实现你的访问控制逻辑
*/
@Override
public List<AuthorizationResult> authorize(AuthorizableRequestContext authorizableRequestContext, List<Action> list) {
return list.stream().map(action -> authorizeAction(authorizableRequestContext, action)).collect(Collectors.toList());
}
/**
* 访问控制逻辑处理
*/
private AuthorizationResult authorizeAction(AuthorizableRequestContext authorizableRequestContext, Action action) {
ResourcePattern resource = action.resourcePattern();
if (resource.patternType() != PatternType.LITERAL) {
throw new IllegalArgumentException("Only literal resources are supported. Got: " + resource.patternType());
}
//是否开启数据库acl验证
if (!enableDbAcl) {
return AuthorizationResult.ALLOWED;
}
String principal = authorizableRequestContext.principal().getName();
AclOperation operation = action.operation();
//logger.info("------resource type:{}---name:{}----operation:{}------用户名principal:{}", resource.resourceType(), resource.name(), operation.name(), principal);
//1 超级用户直接通过
if (superUserSet.contains(principal)) {
//logger.info("-------------------超级用户直接通过");
return AuthorizationResult.ALLOWED;
}
//2 资源类型为 Cluster 直接不通过
if (resource.resourceType().equals(ResourceType.CLUSTER)) {
logger.error("-------------------资源类型为Cluster直接不通过");
return AuthorizationResult.DENIED;
}
//3 资源类型为 TransactionalId、DelegationToken 直接通过
if (resource.resourceType().equals(ResourceType.TRANSACTIONAL_ID) || resource.resourceType().equals(ResourceType.DELEGATION_TOKEN)) {
//logger.info("-------------------资源类型为 TransactionalId、DelegationToken 直接通过");
return AuthorizationResult.ALLOWED;
}
String username = principal;
//4 资源类型为 group 只能用默认组消费
if (resource.resourceType().equals(ResourceType.GROUP)) {
if (isGroup(resource.name(), username)) {
return AuthorizationResult.ALLOWED;
}
logger.error("------------------资源类型为 group:{} 只能用默认分组消费,直接不通过", resource.name());
return AuthorizationResult.DENIED;
}
//5 查询数据库权限配置表信息,找到则通过,否则不通过
if (isAcls(resource.name(), username)) {
return AuthorizationResult.ALLOWED;
}
return AuthorizationResult.DENIED;
}
/**
* 判断是否为 默认分组: default_group
*/
private boolean isGroup(String resourceName, String username) {
String defaultGroup = username + KAFKA_GROUP_SPLIT + "default_group";
if (resourceName.equals(defaultGroup)) {
return true;
}
return false;
}
/**
* 查询数据库,判断是否有权限
*/
private Boolean isAcls(String resourceName, String username) {
List<String> topics = LocalCache.getCache(username);
if (CollUtil.isEmpty(topics)) {
//从数据库查询
topics = queryDb(username);
if (CollUtil.isEmpty(topics)) {
return Boolean.FALSE;
}
LocalCache.addCache(username, topics);
}
Boolean checkBool = checkTopic(resourceName, topics, username);
return checkBool;
}
/**
* 检查是否有topic权限, topic:username&topic
*/
private Boolean checkTopic(String resourceName, List<String> topics, String username) {
for (String topic : topics) {
if (topic == null || topic.length() == 0) {
continue;
}
String tmp = username + KAFKA_TOPIC_SPLIT + topic;
if (tmp.equals(resourceName)) {
return Boolean.TRUE;
}
}
return Boolean.FALSE;
}
/**
* 查询数据库
*/
private List<String> queryDb(String username) {
List<String> dbList = new ArrayList<>();
String userQuery = "select t.topic\n" +
" from topic t\n" +
" left join mq_info i on t.mq_id = i.mq_id\n" +
" where i.default_instance = 1 and t.del_status = 0 and t.username = ?";
Connection conn = null;
try {
conn = dataSource.getConnection();
PreparedStatement statement = conn.prepareStatement(userQuery);
statement.setString(1, tenantId);
ResultSet resultSet = statement.executeQuery();
while (resultSet.next()) {
dbList.add(resultSet.getString("topic"));
}
} catch (Exception e) {
logger.error("-------------------数据库查询topic异常:{}", e);
throw new RuntimeException(e);
} finally {
if (conn != null) {
try {
conn.close();
} catch (SQLException e) {
throw new RuntimeException(e);
}
}
}
return dbList;
}
/**
* 创建权限
*/
@Override
public List<? extends CompletionStage<AclCreateResult>> createAcls(AuthorizableRequestContext authorizableRequestContext, List<AclBinding> list) {
logger.error("------------------createAcls----没有创建权限操作");
throw new UnsupportedOperationException();
}
/**
* 删除权限
*/
@Override
public List<? extends CompletionStage<AclDeleteResult>> deleteAcls(AuthorizableRequestContext authorizableRequestContext, List<AclBindingFilter> list) {
logger.error("------------------deleteAcls----没有删除权限操作");
throw new UnsupportedOperationException();
}
@Override
public Iterable<AclBinding> acls(AclBindingFilter aclBindingFilter) {
//logger.info("------------------acls-----获取符合查询条件的Acl操作");
ArrayList aclBindings = new ArrayList();
return aclBindings;
}
@Override
public void close() throws IOException {
if (dataSource != null) {
dataSource.close();
}
}
@Override
public void configure(Map<String, ?> map) {
String superUsers = (String) map.get(SUPER_USERS_PROP);
//logger.info("------------------superUsers:{}", superUsers);
if (superUsers == null || superUsers.isEmpty()) {
superUserSet = new HashSet<>();
} else {
superUserSet = Arrays.stream(superUsers.split(";")).map(String::trim).collect(Collectors.toSet());
}
Object endbAclObject = map.get(ENABLE_DB_ACL);
if (Objects.isNull(endbAclObject)) {
logger.error("------------------缺少开关配置 enable_db_acl!");
enableDbAcl = Boolean.FALSE;
return;
}
enableDbAcl = TRUE.equalsIgnoreCase(endbAclObject.toString());
if (!enableDbAcl) {
return;
}
dataSource = DataSourceUtil.getIotInstance(map);
}
}
编译打包运行
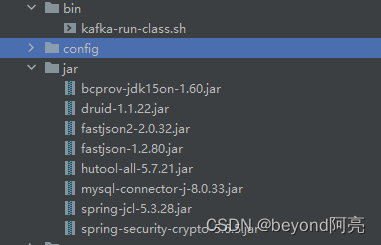
编译打成jar包之后,需要放到libs上当,D:\kafka_2.12-3.5.0\libs\xxx。
注意:还有代码中使用了第三方相关依赖包也需要一起放入。
重启kafka后生效,观察日志,可以看到用户连接后,发送和订阅就会去查询数据库,查询到用户没有权限时,会提示报错如下。