引入调度域的讨论可以参考这篇文章。这篇笔记重点分析了内核调度域相关的数据结构以及内核用于构建调度域的代码实现,以此来加深对调度域的理解。调度域是调度器进行负载均衡的基础。
调度域拓扑层级
整个系统的调度域组成一个层级结构,内核设计了struct sched_domain_topology_level来描述一层调度域拓扑。
typedef const struct cpumask *(*sched_domain_mask_f)(int cpu);
typedef int (*sched_domain_flags_f)(void);
struct sched_domain_topology_level {
sched_domain_mask_f mask;
sched_domain_flags_f sd_flags;
int flags;
int numa_level;
struct sd_data data;
#ifdef CONFIG_SCHED_DEBUG
char *name;
#endif
};- mask:该回调用于指定该层级的调度域的CPU掩码。
- sd_flags:该回调用于获取该层级的调度域标记。
- data:该层级的调度域对象,见下面单独分析。
- name:层级名字,如MC、DIE,这些名字会在用户态的/proc/sys/kernel/sched_domain目录中体现。
系统的调度域拓扑用sched_domain_topology_level[]数组表示,保存在全局变量sched_domain_topology中,数组的每一个元素代表一个层级。default_topology是系统定义的默认调度域拓扑层级数组。各体系结构可以定义自己的调度域拓扑层级数组,然后通过set_sched_topology()函数替换该默认值。
// 不考虑超线程,默认的由MC(多核)和DIE(socket)两个层级组成,手机产品基本上只有这两个层级
static struct sched_domain_topology_level default_topology[] = {
#ifdef CONFIG_SCHED_SMT
{ cpu_smt_mask, cpu_smt_flags, SD_INIT_NAME(SMT) }, // 支持超线程时开启
#endif
#ifdef CONFIG_SCHED_MC
{ cpu_coregroup_mask, cpu_core_flags, SD_INIT_NAME(MC) },
#endif
{ cpu_cpu_mask, SD_INIT_NAME(DIE) },
{ NULL, },
};
struct sched_domain_topology_level *sched_domain_topology = default_topology;
// MC层级包含了属于同一个cluster的所有CPU
const struct cpumask *cpu_coregroup_mask(int cpu)
{
return &cpu_topology[cpu].core_sibling;
}
// DIE层级包含了系统所有的CPU(不考虑NUMA)
static inline const struct cpumask *cpu_cpu_mask(int cpu)
{
return cpumask_of_node(cpu_to_node(cpu));
}sd_data
该结构用于辅助定义调度域拓扑层级,包含了一个拓扑层级所有的调度域对象,这些对象每个CPU一份。由于Per-CPU变量也是动态分配的,所以类型是二级指针。此外,由于整个调度域拓扑层级一旦建立就基本不会再发生变化,每个CPU一份可以提高访问效率。
struct sd_data {
struct sched_domain **__percpu sd;
struct sched_group **__percpu sg;
struct sched_group_capacity **__percpu sgc;
};构建系统调度域拓扑结构时,会使用__sdt_alloc()为sd_data分配内存,对应的释放函数为__sdt_free()。
static int __sdt_alloc(const struct cpumask *cpu_map)
{
struct sched_domain_topology_level *tl;
int j;
for_each_sd_topology(tl) { // 遍历所有的拓扑层级,为每一个tl->sd_data分配空间
struct sd_data *sdd = &tl->data;
// 分配调度域指针对象,这些指针每个CPU一份
sdd->sd = alloc_percpu(struct sched_domain *);
sdd->sg = alloc_percpu(struct sched_group *);
sdd->sgc = alloc_percpu(struct sched_group_capacity *);
// 为每个CPU分配这三个调度域对象
for_each_cpu(j, cpu_map) {
struct sched_domain *sd;
struct sched_group *sg;
struct sched_group_capacity *sgc;
sd = kzalloc_node(sizeof(struct sched_domain) + cpumask_size(),
GFP_KERNEL, cpu_to_node(j));
*per_cpu_ptr(sdd->sd, j) = sd;
sg = kzalloc_node(sizeof(struct sched_group) + cpumask_size(),
GFP_KERNEL, cpu_to_node(j));
sg->next = sg;
*per_cpu_ptr(sdd->sg, j) = sg;
sgc = kzalloc_node(sizeof(struct sched_group_capacity) + cpumask_size(),
GFP_KERNEL, cpu_to_node(j));
*per_cpu_ptr(sdd->sgc, j) = sgc;
}
}
return 0;
}调度域对象
有3个调度域对象:
- struct sched_domain:调度域代表可以共享属性和调度参数的一组CPU。每个CPU在每一个调度域拓扑层级中都有一个shced_domain对象。
- struct sched_group:调度域可以由一个或多个调度组构成,每个调度组也代表可以共享属性和调度参数的一组CPU,属于同一个调度域的调度组的集合组成了调度域代表的CPU。调度域进行负载均衡的目的就是要保证其内部各个调度组之间的负载均衡。
- struct sched_capacity:包含了调度组的captacity内容,和调度组管理的CPU的能力强相关。
调度域: sched_domain
struct sched_domain {
// 组成调度域拓扑层级
struct sched_domain *parent; /* top domain must be null terminated */
struct sched_domain *child; /* bottom domain must be null terminated */
struct sched_group *groups; /* the balancing groups of the domain */
// 暂时忽略诸多调度参数
...
int level; // 代表的调度域拓扑等级,MC为0,其它依次加1
#ifdef CONFIG_SCHED_DEBUG
char *name;
#endif
union {
void *private; /* used during construction */
struct rcu_head rcu; /* used during destruction */
};
unsigned int span_weight; // 该调度域包含的CPU个数和CPU掩码
unsigned long span[0];
};- parent、child、groups:组成了调度域拓扑等级。parent指针指向更高层的sched_domain对象,最低层的sched_domain对象(如MC层)的该指针为NULL。child则是和parent相反。groups指向了属于该调度域的所有调度组对象链表,见sched_group部分的介绍。
- private:指向所属的sched_domain_topology_level.sd_data。
- span_weight、span:包含了该调度域包含的CPU信息,span数组在构建系统调度域拓扑结构时根据sched_domain_topology中定义的系统调度域拓扑等级描述动态分配。
构建调度域: build_sched_domain()
sched_domain对象的分配是在__sdt_alloc()函数中完成的,但是其大多数字段的设置以及系统拓扑层级结构中sched_domain之间的父子关系是在build_sched_domain()函数中完成的。
// 构建cpu上tl层级的sched_domain对象(tl->sd_data.sd[cpu]),其包含的CPU为cpu_map,child为其下一级
struct sched_domain *build_sched_domain(struct sched_domain_topology_level *tl,
const struct cpumask *cpu_map, struct sched_domain_attr *attr,
struct sched_domain *child, int cpu)
{
struct sched_domain *sd = sd_init(tl, cpu); // 初始化该sched_domain中的各字段
if (!sd)
return child;
// 设置sched_domain的CPU掩码,即span数组
cpumask_and(sched_domain_span(sd), cpu_map, tl->mask(cpu));
if (child) {
sd->level = child->level + 1;
sched_domain_level_max = max(sched_domain_level_max, sd->level);
child->parent = sd; // 相邻层级的sched_domain对象之间建立父子关系
sd->child = child;
// 检查确保低层级的sched_domain的CPU掩码必须是高层级的sched_domain的CPU掩码的子集
if (!cpumask_subset(sched_domain_span(child),
sched_domain_span(sd))) {
#ifdef CONFIG_SCHED_DEBUG
pr_err(" the %s domain not a subset of the %s domain\n",
child->name, sd->name);
#endif
cpumask_or(sched_domain_span(sd),
sched_domain_span(sd),
sched_domain_span(child));
}
}
set_domain_attribute(sd, attr);
return sd;
}
如上可见,sched_domain对象的大部分字段都是在sd_init()函数中设置的,下面我们先忽略其中调度策略参数的设置,这部分内容在负载均衡相关的笔记中再来分析(结合负载均衡上下文更容易理解)。
static struct sched_domain *
sd_init(struct sched_domain_topology_level *tl, int cpu)
{
// 找到要初始化的sched_domain对象
struct sched_domain *sd = *per_cpu_ptr(tl->data.sd, cpu);
int sd_weight, sd_flags = 0;
*sd = (struct sched_domain) {
...
#ifdef CONFIG_SCHED_DEBUG
.name = tl->name,
#endif
};
...
sd->private = &tl->data;
// private指向sched_domain_topology_level.sd_data
return sd;
}调度组: sched_group
调度域进一步可以划分为若干个调度组,这些调度组的CPU的并集就是调度域的CPU集合。
struct sched_group {
struct sched_group *next; /* Must be a circular list */
atomic_t ref;
unsigned int group_weight; // cpumask中CPU的个数
struct sched_group_capacity *sgc;
// 调度组的CPU掩码
unsigned long cpumask[0];
};- next:同一个调度域下的多个调度组用该指针组成一个单向循环链表,链表的表头结点为sched_domain.groups指针。
- ref:同一个sched_group对象可能被多个CPU上的sched_domain对象引用,所以需要一个引用计数。
- sgc:用来描述该调度组的capacity,见下面介绍。
- group_weight、cpumask:该调度组包含了哪些CPU和CPU的个数。
构建调度组: build_sched_groups()
__sdt_alloc()函数中完成sched_group对象的分配,每个CPU在每个调度域拓扑层级都分配了一个sched_group对象,但是这些对象并不会全部被使用。在构建系统调度域拓扑时,会调用build_sched_groups()函数为指定CPU的sched_domain对象构建其所有的sched_group对象。
static int build_sched_groups(struct sched_domain *sd, int cpu)
{
struct sched_group *first = NULL, *last = NULL;
struct sd_data *sdd = sd->private;
const struct cpumask *span = sched_domain_span(sd); // span为该调度域的CPU集合
struct cpumask *covered;
int i;
// 为调度域对象sdd->sd_data.sd[cpu]确定调度组,将确定的调度组对象及其sgc指针
// 保存在sdd->sd_data.groups[cpu]中,该函数会修改sd->groups的指向
get_group(cpu, sdd, &sd->groups);
atomic_inc(&sd->groups->ref);
// 后面的逻辑只有在处理调度域对象的第一个CPU时才会执行,
// 对于MC层就是每个cluster的第一个CPU,对于DIE层就是整个系统的第一个CPU
if (cpu != cpumask_first(span))
return 0;
lockdep_assert_held(&sched_domains_mutex);
covered = sched_domains_tmpmask;
cpumask_clear(covered);
for_each_cpu(i, span) {
// 检查调度域内的每个CPU,判断其是否可以作为一个独立的sched_group
struct sched_group *sg;
int group, j;
if (cpumask_test_cpu(i, covered))
continue;
group = get_group(i, sdd, &sg);
cpumask_setall(sched_group_mask(sg)); // 这个逻辑非常奇怪,为什么要设置所有的CPU到调度组?
// 找到那些属于同一个sched_group的CPU,将其设置到调度组对象的CPU掩码中
for_each_cpu(j, span) {
if (get_group(j, sdd, NULL) != group)
continue;
cpumask_set_cpu(j, covered);
cpumask_set_cpu(j, sched_group_cpus(sg));
}
// 将同一个调度域对象下面的若干个调度组对象通过sched_group.next指针组织成单向循环链表
if (!first)
first = sg;
if (last)
last->next = sg;
last = sg;
}
last->next = first;
return 0;
}
// 为调度域对象sdd->sd[cpu]确定调度组,将确定的调度组对象及其sgc指针保存在sg中
static int get_group(int cpu, struct sd_data *sdd, struct sched_group **sg)
{
struct sched_domain *sd = *per_cpu_ptr(sdd->sd, cpu);
struct sched_domain *child = sd->child;
if (child)
cpu = cpumask_first(sched_domain_span(child));
if (sg) {
*sg = *per_cpu_ptr(sdd->sg, cpu);
(*sg)->sgc = *per_cpu_ptr(sdd->sgc, cpu);
atomic_set(&(*sg)->sgc->ref, 1); /* for claim_allocations */
}
return cpu;
}get_group()函数非常关键,该函数对第一层拓扑和更高层拓扑的逻辑不同。对于第一层拓扑,其child为NULL,这时传入的cpu不会发生变化,这样调度域对象sdd->sd[cpu]关联的调度组对象就是该CPU的调度组对象。对于更高层拓扑,其child不是NULL,这时调度组对象来自其第一层拓扑的第一个CPU对应的对象。这样的get_group()函数实现的效果见下面"构建系统调度域拓扑"中第二组for循环后的示意图。
调度组能力: sched_group_capacity
每个sched_group对象都关联一个sched_group_capacity对象来描述调度组的能力。
struct sched_group_capacity {
atomic_t ref; // 同sched_group中的ref
// 调度组的capacity
unsigned int capacity, capacity_orig;
unsigned long next_update;
...
unsigned long cpumask[0]; /* iteration mask */
};初始化调度组能力: init_sched_groups_capacity()
在构建系统调度域拓扑过程中,会调用该函数将初始化指定调度域的所有调度组能力。调度组的能力和调度组中CPU的capacity强相关,这里不详细展开,在CPU能力相关笔记中再详细分析。
static void init_sched_groups_capacity(int cpu, struct sched_domain *sd)
{
struct sched_group *sg = sd->groups;
// 为该调度域的所有调度组计算其管理的CPU个数
do {
sg->group_weight = cpumask_weight(sched_group_cpus(sg));
sg = sg->next;
} while (sg != sd->groups);
// 只有调度组中的第一个CPU才需要执行计算capacity的过程,因为其他CPU都会共享该sgc
if (cpu != group_balance_cpu(sg))
return;
update_group_capacity(sd, cpu); // 计算capacity
atomic_set(&sg->sgc->nr_busy_cpus, sg->group_weight);
}根域: root_domain
根域定义了一些全局信息,所有CPU共用一个根域对象。初始时系统会定义一个def_root_domain作为系统根域,后续整个调度域拓扑结构建立时会重新建立一个根域对象来替换默认的根域对象。
/*
* By default the system creates a single root-domain with all cpus as
* members (mimicking the global state we have today).
*/
struct root_domain def_root_domain;
struct root_domain {
atomic_t refcount;
...
struct rcu_head rcu;
cpumask_var_t span;
cpumask_var_t online;
};
// 最终系统拓扑层级中的调度域和根域对象会关联到rq中
struct rq {
...
#ifdef CONFIG_SMP
struct root_domain *rd;
struct sched_domain *sd;
#endif
}cpu_attach_domain()
系统调度域拓扑建立完毕后会调用该函数将每个CPU上的调度域对象(第一级)和根域对象保存到CPU运行队列rq中。
static void
cpu_attach_domain(struct sched_domain *sd, struct root_domain *rd, int cpu)
{
struct rq *rq = cpu_rq(cpu);
struct sched_domain *tmp;
// 遍历系统调度域拓扑结构,去掉那些对调度没有意义的荣誉层级(如相邻两个层级的调度域管理的CPU相同)
for (tmp = sd; tmp; ) {
struct sched_domain *parent = tmp->parent;
if (!parent)
break;
if (sd_parent_degenerate(tmp, parent)) {
tmp->parent = parent->parent;
if (parent->parent)
parent->parent->child = tmp;
if (parent->flags & SD_PREFER_SIBLING)
tmp->flags |= SD_PREFER_SIBLING;
destroy_sched_domain(parent, cpu);
} else
tmp = tmp->parent;
}
if (sd && sd_degenerate(sd)) {
tmp = sd;
sd = sd->parent;
destroy_sched_domain(tmp, cpu);
if (sd)
sd->child = NULL;
}
// 将sd和rd指针保存到rq->sd和rq->rd中
rq_attach_root(rq, rd);
tmp = rq->sd;
rcu_assign_pointer(rq->sd, sd);
destroy_sched_domains(tmp, cpu);
update_top_cache_domain(cpu);
}构建系统调度域拓扑
在开机过程中,会调用init_sched_domains()函数根据定义的系统调度域拓扑层级结构构建系统调度域拓扑。
// 传入的cpu_map为cpu_active_mask
static int init_sched_domains(const struct cpumask *cpu_map)
{
int err;
arch_update_cpu_topology(); // 构建系统调度域拓扑之前让体系结构更新一次自己的cpu_map
ndoms_cur = 1;
doms_cur = alloc_sched_domains(ndoms_cur);
if (!doms_cur)
doms_cur = &fallback_doms;
cpumask_andnot(doms_cur[0], cpu_map, cpu_isolated_map); // 去掉隔离的CPU
err = build_sched_domains(doms_cur[0], NULL); // 构建系统调度域拓扑结构
// 系统调度域拓扑构建完毕,根据结果创建/proc/sys/kernel/domain目录
register_sched_domain_sysctl();
return err;
}核心的系统调度域拓扑建立由build_sched_domains()函数完成。
// 该临时数据结构用来保存分配的调度域对象
struct s_data {
struct sched_domain ** __percpu sd;
struct root_domain *rd;
};
static int build_sched_domains(const struct cpumask *cpu_map,
struct sched_domain_attr *attr)
{
enum s_alloc alloc_state;
struct sched_domain *sd;
struct s_data d;
int i, ret = -ENOMEM;
// 为调度域拓扑层级数组sched_domain_topology分配调度域对象
alloc_state = __visit_domain_allocation_hell(&d, cpu_map);
if (alloc_state != sa_rootdomain)
goto error;
// 为每个CPU都建立一个sched_domain对象组成的层级结构(通过sched_domain的parent和child字段)
for_each_cpu(i, cpu_map) {
struct sched_domain_topology_level *tl;
sd = NULL;
for_each_sd_topology(tl) { // 拓扑层级从低到高遍历,sd为child
// 每构建一层sched_domain对象都是下一层的child
sd = build_sched_domain(tl, cpu_map, attr, sd, i);
// 保存每个CPU的最低层次sched_domain对象到临时变量d.sd中,后面有用处
if (tl == sched_domain_topology)
*per_cpu_ptr(d.sd, i) = sd;
if (tl->flags & SDTL_OVERLAP || sched_feat(FORCE_SD_OVERLAP))
sd->flags |= SD_OVERLAP;
// 构建的拓扑层级最高层次只需要覆盖所有active_cpu_mask即可,这样可以防止数组sched_domain_topology
// 定义多余的高层次拓扑层级,比如在DIE上面再定义一层,但是DIE层已经可以覆盖系统所有CPU了
if (cpumask_equal(cpu_map, sched_domain_span(sd)))
break;
}
}
// 为每个CPU的各层sched_domain对象构建调度组对象
for_each_cpu(i, cpu_map) {
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) {
// 由低到高为每一层调度域拓扑层级的sched_domain对象构建调度组对象
sd->span_weight = cpumask_weight(sched_domain_span(sd));
if (sd->flags & SD_OVERLAP) {
// 调度域中各调度组的CPU存在重叠的情况,我们不考虑
if (build_overlap_sched_groups(sd, i))
goto error;
} else {
// 为CPU i上的调度域对象sd构建调度组对象
if (build_sched_groups(sd, i))
goto error;
}
}
}
// 1. 为每个CPU的各层sched_domain对象中的sched_group对象设置capacity。
// 2. 标记系统调度域拓扑中不需要的调度域对象,后续根据标记结果释放。
for (i = nr_cpumask_bits-1; i >= 0; i--) {
if (!cpumask_test_cpu(i, cpu_map))
continue;
for (sd = *per_cpu_ptr(d.sd, i); sd; sd = sd->parent) {
claim_allocations(i, sd);
init_sched_groups_capacity(i, sd);
}
}
// 将调度域对象和根域对象保存到CPU运行队列中
rcu_read_lock();
for_each_cpu(i, cpu_map) {
sd = *per_cpu_ptr(d.sd, i);
cpu_attach_domain(sd, d.rd, i);
}
rcu_read_unlock();
ret = 0;
error:
__free_domain_allocs(&d, alloc_state, cpu_map);
return ret;
}- __visit_domain_allocation_hell()函数只负责调度对象的分配。下图是6小核+2大核的系统在该函数调用之后,系统调度域拓扑层级结构中的调度域对象分配示意图。
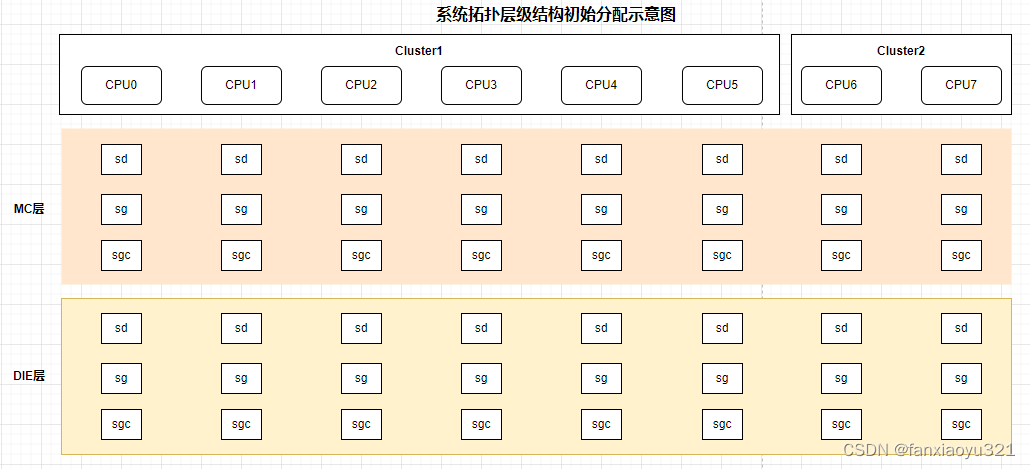
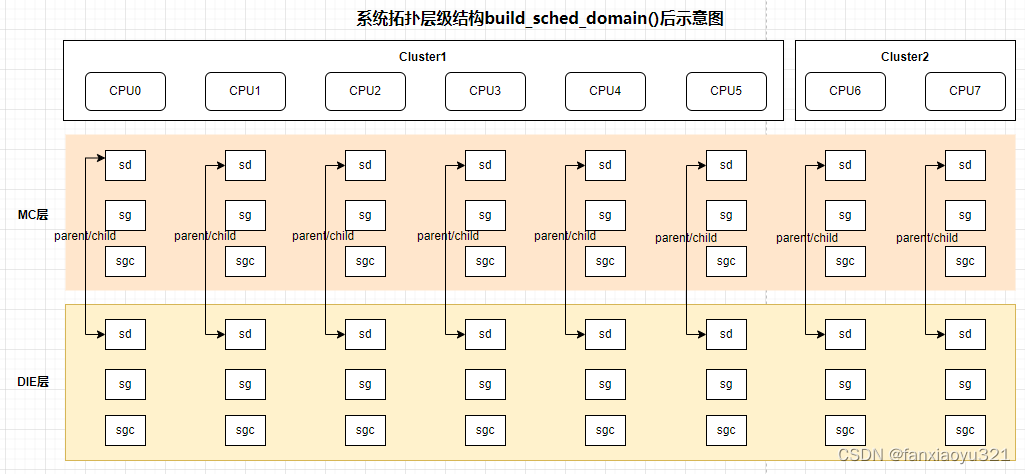
- 第一组for循环中,通过build_sched_domain()函数为每个CPU都建立一个sched_domain对象组成的层级结构(通过sched_domain的parent和child字段)。下图是6小核+2大核的系统在该组for循环之后,系统调度域拓扑层级结构中的调度域对象关系示意图。
- 第二组for循环中,通过build_sched_groups()函数为每个CPU的各层sched_domain对象构建调度组对象(保存到sched_domain的groups字段中)。下图是6小核+2大核的系统在该组for循环之后,系统调度域拓扑层级结构中的调度域对象关系示意图。
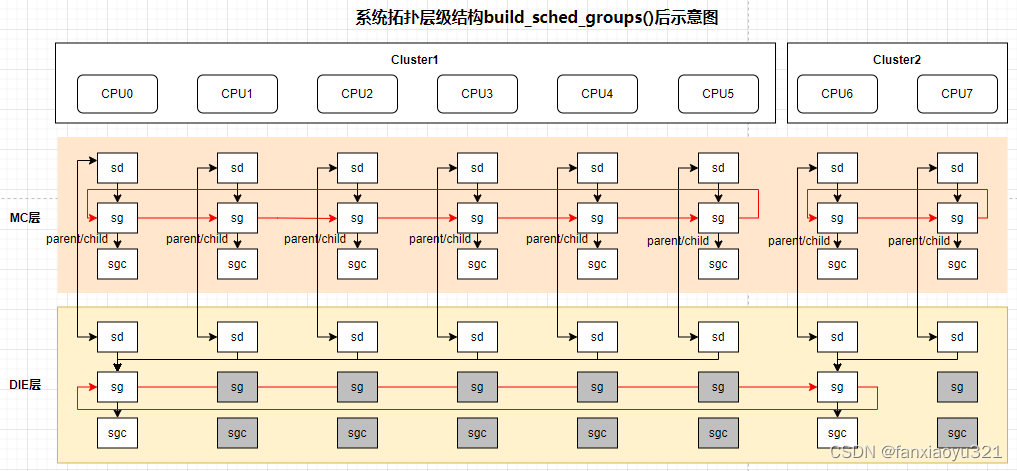
上图中置灰部分表示这些对象没有关联到拓扑结构中。在MC层,每个CPU为一个调度组,同一个cluster内的调度组组成该层的调度域。在DIE层,每个cluster内的CPU为一个调度组,多个cluster的调度组组成该层的调度域。
- 第三组for循环中,通过claim_allocations()函数将系统调度域拓扑中不需要的调度域对象标记为NULL(上图中置灰部分调度域对象),这样最后的__free_domain_allocs()函数根据标记结果释放这些对象。通过init_sched_groups_capacity()函数为所有的sched_group对象初始化capacity。
- 第四组for循环中,通过cpu_attach_domain()函数将调度域对象和根域对象保存到CPU运行队列中。
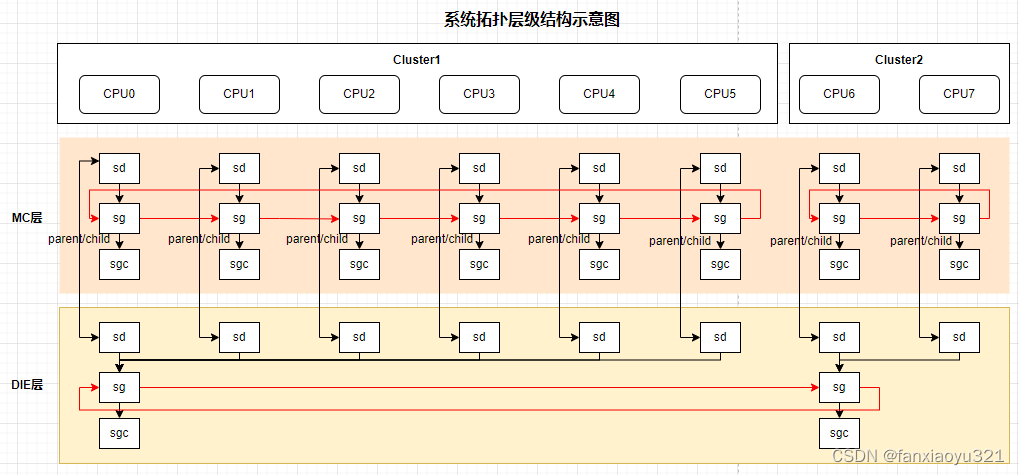
- 最后,通过__free_domain_allocs()函数释放那些不需要的调度域对象。下图是6小核+2大核的系统在多余的调度域对象被释放之后的示意图。
__visit_domain_allocation_hell()
该函数为系统调度域拓扑层级数组sched_domain_topology分配调度域对象。
static enum s_alloc __visit_domain_allocation_hell(struct s_data *d,
const struct cpumask *cpu_map)
{
memset(d, 0, sizeof(*d));
// 为所有的sched_domain_topology_level.sd_data分配对象
if (__sdt_alloc(cpu_map))
return sa_sd_storage;
// 该临时的Per-CPU变量用于的后续流程,用于指向__sdt_alloc()中分配的调度对象
d->sd = alloc_percpu(struct sched_domain *);
if (!d->sd)
return sa_sd_storage;
// 分配并初始化根域对象
d->rd = alloc_rootdomain();
if (!d->rd)
return sa_sd;
return sa_rootdomain;
}claim_allocations()
将调度域sd中使用到的相关调度域对象指针标记为NULL,这样最后的__free_domain_allocs()函数就可以通过判断非NULL指针来将那些未使用到的调度域对象进行回收。需要注意的是这里将tl->sdd.xxx指针设置为NULL并不会导致内存泄漏,因为这些对象的指针在build_sched_domains()函数的临时变量d中还保存了一份,而且最后会通过cpu_attach_domain()函数将sd指针保存到CPU运行队列中。
static void claim_allocations(int cpu, struct sched_domain *sd)
{
struct sd_data *sdd = sd->private;
WARN_ON_ONCE(*per_cpu_ptr(sdd->sd, cpu) != sd);
*per_cpu_ptr(sdd->sd, cpu) = NULL;
if (atomic_read(&(*per_cpu_ptr(sdd->sg, cpu))->ref))
*per_cpu_ptr(sdd->sg, cpu) = NULL;
if (atomic_read(&(*per_cpu_ptr(sdd->sgc, cpu))->ref))
*per_cpu_ptr(sdd->sgc, cpu) = NULL;
}