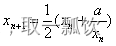目录
1. 指令与架构
2. Load
3. 计算MMA
4. Set, Step 与thread group
5. OCTET
6. Tensor Core微架构
7. Final
Nvidia自从Volta/Turing(2018)架构开始,在stream multi processor中加入了tensor core,用于加速矩阵计算。如下图所示,其中每个SM有两个tensor core。相信大家也看了这个图很多次,那么一个tensor core里面的64个绿色小格子代表的是什么级别的计算呢?
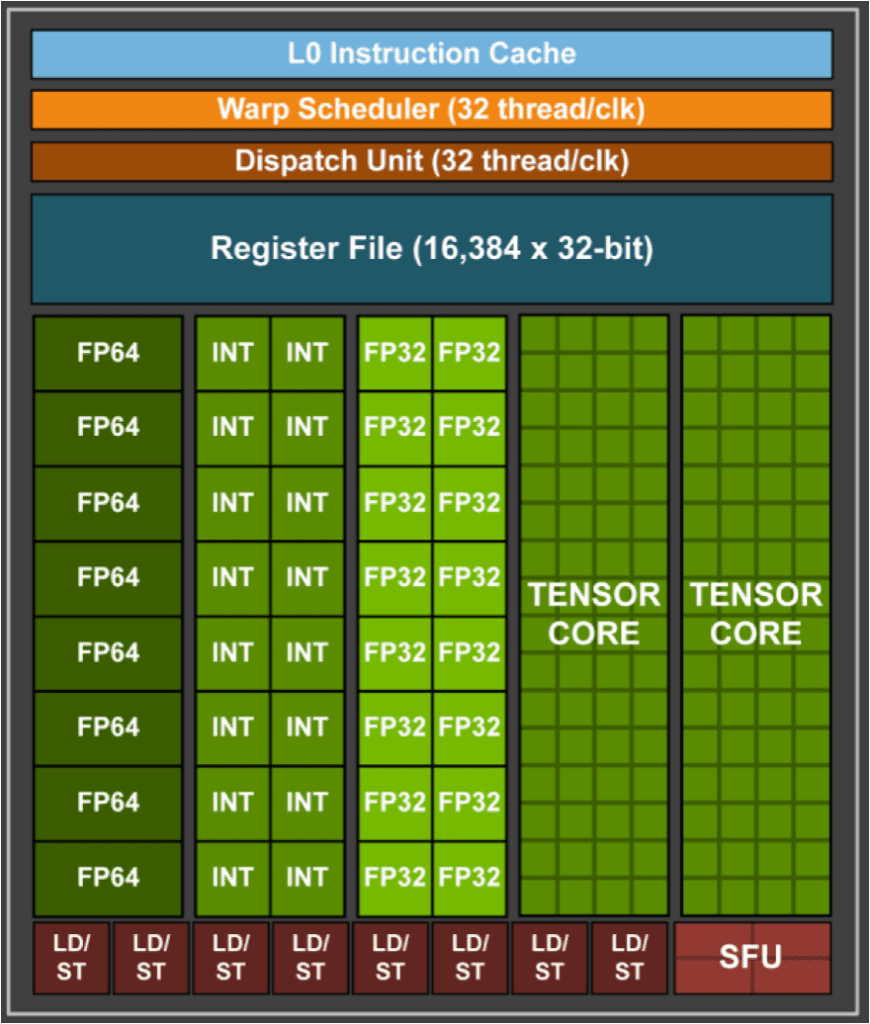
图自[3]
指令与架构
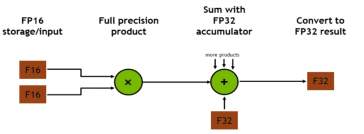
Tensor core支持mixed precision和FP16矩阵计算:D = A x B + C. mixed precision指的是 A和B为FP16,但是C和D为FP32或FP16.
CUDA9.0支持的最小矩阵乘法为16x16x16(不是一个周期就能计算完毕的),下图所示为Tensor Core load A, B, C,进行mma(matrix multiply-accumulate),而后store结果D的PTX指令,其中每个指令都有sync,用于进行warp-wide的同步。

Tensor Core PTX指令
Volta的每个SM core内部有两个tensor core,每个Tensor Core每个周期可以完成一个 4x4x4的MACC操作,如下图所示:
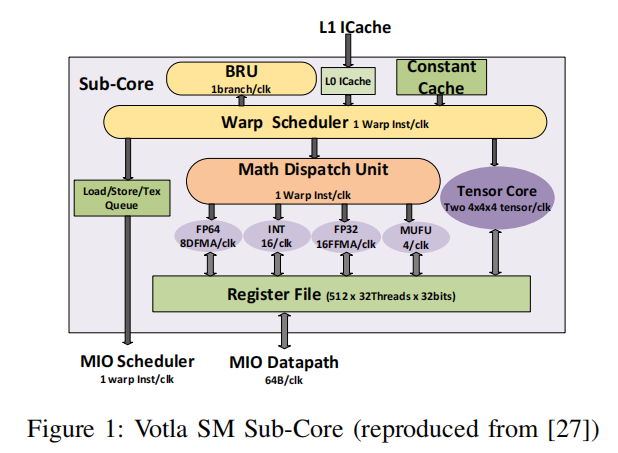
这里的4x4x4指的是A*B矩阵中A的维度为4x4, B的维度为4x4,A*B的计算量即为4x4x4。
这里写的two 4x4x4是因为有两个tensor core。
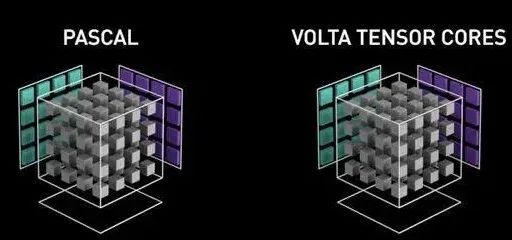
下图右侧即为Turing架构新引入的tensor core,在A和B矩阵的精度为FP16时,每次A的4x4,B的矩阵4x4,每次进行乘法累加,得到下方绿色的4x4。INT8和INT4复用乘法单元,计算能力分别x2,x4。
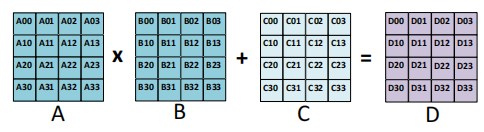
传统的CUDA教学里面,每个线程的寄存器是private,仅自己可见。
但是对于Tensor Core来说,一个warp内的线程,互相之间的寄存器都是可见的。因此一个warp的32个线程,可以各自load输入矩阵A,B,C的一部分,加载到register file,读取时也可以复用其他寄存器加载的寄存器。
与传统CUDA相同,tensor core的一个warp仍然是32个thread,但是不同的是,32个thread被切成了8个thread group,每个thread group 4个线程。
Load
首先将是将矩阵加载到寄存器中:
如左图所示,一共16行,每4行为一个segment,每个segment由两个thread group一同加载。一行16个元素,每个元素16bit,共计256bit,需要两条load.E.128指令完成。
这里个人理解,因为一共四行,每行可以两个thread加载,所以可以每个thread执行一个load.E.128,一共32个thread。
32(thread 个数)*128(load.E.128) = 16(矩阵行数)*16(矩阵列数)*16(每个元素大小)
文章未具体介绍。
计 算MMA
加载之后就是计算了,一条mma 16*16*16的指令如下图所示,
![]()
在Nvidia的SASS汇编级别会被展开成16条指令:

这里只展示了mixed precision的汇编。FP16的汇编指令与此相同,但是概念相通,这里就不赘述。
上图右侧显示了计算完毕一条16x16x16需要的时间,54个cycle,除了开始需要10个cycle,后面每条指令基本上只需要2个cycle。
需要注意的是,这里的16条指令会在一个warp的32个thread上同时执行。
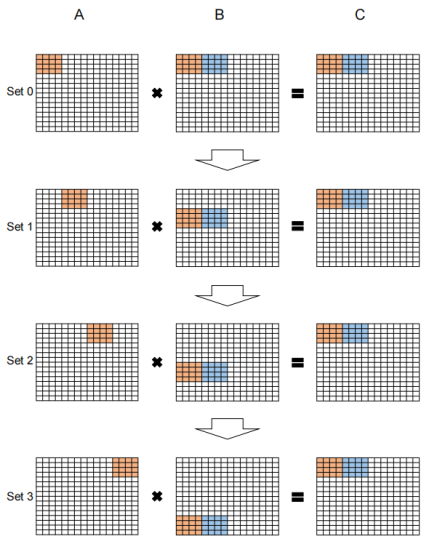
上图左侧,一共有4个set,每个set内部又有4个step。
Set, Step与Thread Group
Set,step都是汇编级别的指令,都是逐一计算的,但是thread,thread group这些thread的概念,是同时进行的。具体step,set和thread group的切分如下图所示。
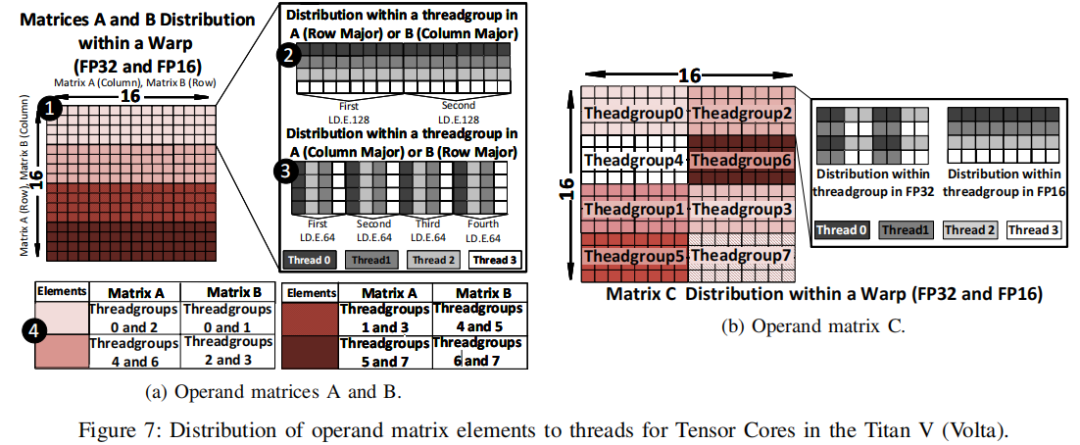
从set的角度看矩阵的计算:
如上图所示的是thread group 0的计算每个set可以计算完毕一个4*4*8的计算,4次set计算完毕之后,就可以得到最终的C矩阵中的一个4*8小矩阵。与此同时,其他的thread group 1-7也在进行计算,最终我们就可以得到完整的C矩阵。

更细致的计算解释如下图所示:
如上图(b)所示,每个step完成了2*4*4的计算,得到了2*4的矩阵输出(上图b的ADBC标错了,应该是ABCD)。
那么是如何完成2*4*4的计算的呢?
OCTET
这里又要引入一个新的概念OCTET,具体的OCTET负责的计算一个8*8的小矩阵具体如下图所示:

之所以引入这个概念,是因为OCTET内部的threadgroup存在加载数据的依赖关系,比如上图b)中,每个小方块为4x4的矩阵。
-
d,c,b,a,D,C,B,A由thread group 0加载
-
h,g,f,e,H,G,F,E由thread group4加载
因此当thread group0计算a*A和a*E时,需要等待thread group4加载完毕,也就是Octet内部的计算需要另一个thread group load完毕数据,但是Octet之间不存在数据依赖关系。
而这个依赖关系,个人理解后面会体现在thread group 0和4公用的matrix buffer上。
如下图所示,step0/1,threadgroup0和4公用thread0加载的A,step2/3,threadgroup0和4公用thread0加载的E.

这里的a[0:1]代表a的0行和1行
而再回忆一下刚才介绍的输出C的矩阵:
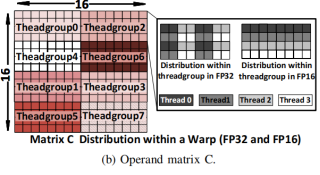
可以看出OCTET 0的这个部分是由Thread group 0和 Thread group 4共同计算完成的。
Tensor Core 微架构
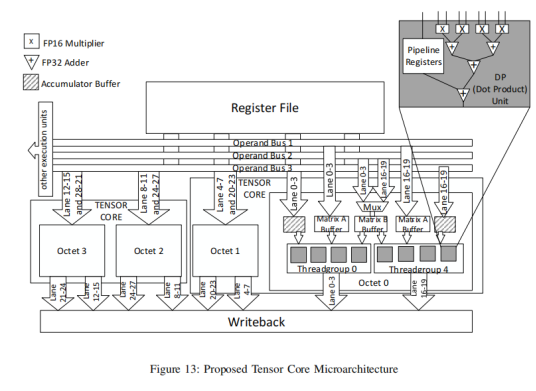
如上图所示,右上角的为一个FEDP unit (four-element dop-product),这个灰色的单元,每个可以完成一个行矩阵和一个列矩阵的点乘计算,即一个1*4的行矩阵和一个4*1的列矩阵的点乘计算。这个4次的乘法累加,每周期可以计算完毕一次。
每个thread group内部有4个,那么就是4*4,可以理解成一个1*4的A矩阵和一个4*4的B矩阵,每个周期可以计算完毕一次A和B的成累加,那么两个周期,就可以计算完毕一个两行四列的A矩阵和一个4行4列的B矩阵的计算,得到一个两行四列的C矩阵。对应了上面的单个step的计算图。
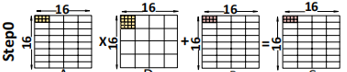
我们再回忆一下,tensor core支持每周期4*4*4的矩阵计算,这里一个thread group每个周期可以计算完毕1*4*4的计算,每个Octet内部有两个thread group,即2*4*4,而每个tensor core内部又有两个Octet,这样每个周期就可以有4*4*4的计算量了。
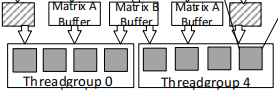
Octet0内部的Thread group0和Thread group共用了一个matrix B buffer,利用了计算时复用矩阵的B的特点,减轻了加载操作数到计算单元的负担。
Final
到这里我们已经从架构,指令,指令分解到微架构已经明白了Volta的tensor core是如何计算的。
那么具体的每个tensor core内部有2个Octet,每个Octet有2个thread group,每个thread group有4个thread,每个thread执行在一个FEDP上,每个FEDP内部有四个乘法单元,2*2*4*4 = 64.
也就是说最开始的那个问题,tensor core里面的绿色小格子就是一个乘法单元:
也就是微架构图里的这个:
本文是基于文章[1]和[2]的理解。
[1] Modeling Deep Learning Accelerator Enabled GPUs
[2] Dissecting the NVIDIA Volta GPU Architecture via Microbenchmarking
[3] https://learnopencv.com/demystifying-gpu-architectures-for-deep-learning-part-2/