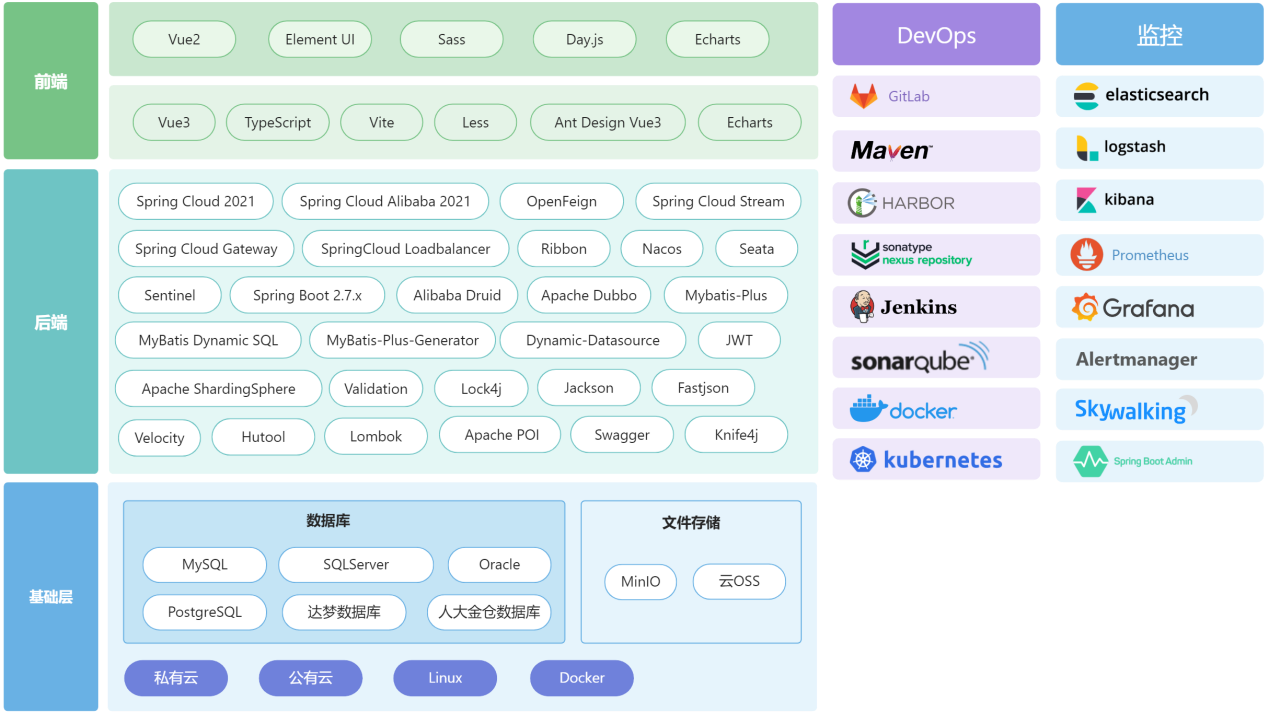
视频云AI进化新纪元。
最近Gartner发布2024年十大战略技术趋势,AI显然成为其背后共同的主题。全民化的生成式人工智能、AI增强开发、智能应用......我们正在进入一个AI新纪元。
从ChatGPT的横空出世,到开发者大会的惊艳亮相,OpenAI以一己之力掀起生成式AI产业变革。与此同时我们也看到,AI正以超乎想象的进化速度,给云服务和音视频带来了更多机遇与挑战。
在“云智深度融合”的行业共识之下,如何用好大模型,构建出符合行业需求的垂直场景模型,如何将生成式AI更好地与实际业务相结合,最大化发挥云服务“最佳拍档”的优势,已成为视频云领域甚是关心的话题。
同时,我们也对AI技术在音视频的进一步渗透,以及视频云应用场景的拓宽充满好奇与期待。
我们对话了「阿里云视频云」视觉算法方向负责人刘国栋、媒体服务负责人邹娟,一起围绕视频云大模型探索与AIGC实践应用,聊聊阿里云视频云在AI方向的新进展与新思考。

01 一场AI的热力风暴
高热的OpenAI开发者大会,给大模型与生成式AI风潮再次升温。在AI的遽变中,我们看到音视频的“危”与“机”都面临着更为深刻的变革。同时,我们希望获得AI的全面加持,在音视频全链路中将云智进行更深入地融合,从而提升整体音视频服务水平。
Q1:最近OpenAI开发者大会可以说是AI届的“科技春晚”,哪些令你印象深刻?
印象深刻的内容有很多,比如,OpenAI最新推出的GPT-4 Turbo模型,拓展到了128K的上下文窗口长度,实现了模型知识库的全面升级,支持DALL.E 3、GPT4-Vision、TTS等多模态API,以及支持模型微调定制;在开发者生态构建方面,OpenAI发布了GPT Assistants API和GPT Store,让开发者可以更方便地调用模型以及共享GPT的创意玩法;首次推出可为特定目的进行自定义的GPT,让不懂代码的用户也可轻松创建自己的ChatGPT版本。
毫无疑问,OpenAI带来的震撼是巨大的。它不只带来革命性的技术,而且已经开始构建自己的生态系统了,从炼丹走向商业化。同时,它也让我们看到AI技术已经进化到了更高层次,特别是在多模态理解与生成,语言理解与生成,以及GPT-4 Turbo作为决策中心的能力等方面,这些都与音视频技术有着直接或间接的联系,让我们看到了音视频技术发展的更多可能性。
Q2:你提到AI技术为音视频带来更多可能性,与此同时是否也带来了新的冲击?音视频领域对AI的要求是否更苛刻?
在音视频领域中,我们看到,音视频服务已广泛应用于互娱、广电传媒、教育、金融等各种行业,对场景的渗透也越来越深。这些行业、场景对体验的追求愈来愈高,同时用户希望用得起、更普惠,这都要求音视频服务具有高度的智能化。将提升音视频服务质量寄希望于AI,已逐渐成为业界共识。
随着AIGC的日新月异,音视频领域的AI技术也呈现出了新的趋势,即对算法的通用性、理解能力、生成能力都提出了更高的要求。过去纯粹的定制小模型开发、单模态处理和预测范式不再完美适配,而是走向了泛化能力非常强的预训练大模型、多模态信息融合、生成式范式等技术领域。
通过分析业务中发现的痛点问题,我们总结出几点视频云对AI算法的更高要求,即:追求效果性能上的极致体验,追求算法的泛化性、通用性,提升AI自主决策、规划处理链路的能力,降低开发、接入、使用的成本。
音视频领域对AI的要求无疑比自然语言领域更为苛刻,尤其是AI大模型如何更泛化地与音视频结合。就像何恺明博士提到的,相比于自然语言处理领域的预训练模型,在计算机视觉领域,还没有一个类似的视觉基础模型来覆盖大多数任务处理。视频云也会对AGI在音视频方向的进展保持时刻关注。
Q3:在音视频领域中,如何更好地“取AI之长”,来提升整体音视频服务水平?
从音视频的全链路视角来看,我们可以在音视频生命周期的各环节“取AI之长”。无论是音视频内容的采集、前处理与编码、视频的分析与理解、文件或实时流的处理与传输、以及媒体消费侧的互动反馈等,都可以从不同的角度和姿势使用AI技术,为音视频生命周期的多个模块提供更高效、更高质量的能力加持。
经过多年的实践,AI对阿里云视频云的赋能也是全栈的,覆盖了音视频“生产、处理、传输、消费”的全链路。当前AI技术与视频云业务高度绑定,在视频云为客户提供的涵盖媒体采集、媒资管理、内容生产制作和分发的一站式媒体服务能力集,以及视频直播、视频点播、音视频通信产品中,AI无处不在。而随着大模型和AIGC的爆发,AI还将为视频云带来新的业务模式和想象空间。

02 视频云大模型,让全链路进化
更好的通用性、更强大的理解生成能力,大模型的出现为视频云提供了新的思路与解法。然而,大模型在音视频全链路的赋能,既要考虑底层算法的原子化能力进化,也要考虑与音视频具体场景的完美适配,真正实现让大模型“为我所用”的绝佳效果。
(该部分源自与刘国栋的深入对话编辑而成)
Q4:从算法层面上来讲,你觉得大模型可以解决以往技术方案中的“沉疴旧疾”吗?
过去我们在设计算法时一般均采用小模型、传统算法或是两者结合的方法。这样的设计虽然可以少占用训练资源且速度快,部署容易,端侧落地性强,但是问题也比较突出,比如模型的泛化能力差,效果上限比较低,理解、生成能力比较差等。
而大模型出现后,它的通用性、多模态协同能力,强大的理解、生成能力等都让我们惊叹不已,这些正是小模型和传统算法所欠缺的。用大模型方法去重做一遍之前的算法,提高算法效果的上限是我们认为比较可行的做法。此外,我们也尝试使用大模型,来处理新的领域或问题,比如端侧的大模型设计。
Q5:视频云在设计大模型算法系统时,可以与我们分享一些“智能化”的思路吗?
我们根据视频云的业务特点,设计和搭建了一套视频云大模型算法开发的系统架构。整个系统涵盖了分析、规划、推理、评价、训练与微调的全链路,并且是可进化、可决策的。
可进化体现在,对于给定的任务,系统会进行从分析到训练的循环过程,并保持整个过程的不断迭代。可决策是指,系统会先借助视频云的知识库进行检索,再利用语言大模型给出执行路径。同时,知识库本身也在不断地丰富,我们会把评价高的规划信息、解决方法以及业务中沉淀的数据持续输入到知识库中,确保决策依据的与时俱进。
Q6:在大模型的算法探索上,视频云有没有一套研究路径或者总结出来的方法论?
基于大模型算法系统框架,我们不断地在业务中实践、演进,提炼出一套通用的大模型算法“方法论”,使其能高质量地解决业务中的实际问题。
例如,在完成实际任务时,单纯依靠大模型可以实现一些核心基本功能,但离解决得好还有不小距离,因此我们针对性提出了几种大小模型协同的方法,让大小模型互相配合,发挥其各自优势,获得了比较好的效果。
再比如,在大模型落地过程中,我们发现大模型更多针对通用场景,在音视频实际业务中往往效果不佳,当然这并不意味这些模型完全不可用。我们基于自己的业务场景,筛选出相对高质量的大模型,再结合已沉淀的数据、知识库进行大模型微调,使得模型准确度有了大幅提升。
另外,针对大模型训练优化、推理性能、显存占用等方面,视频云都在实践过程中总结出基于大模型的算法优化路径,从而为音视频业务的智能化打好基础、铺好路。
Q7:相较于图文生成,视频生成大模型的技术门槛更高,需要克服的技术挑战也更多,视频云在这方面是怎样实践的?
无论是闭源的Midjourney,还是开源的stable diffusion,在图像生成方面都取得了惊人的效果。视频云的业务中也需要一些图像生成的能力,特别是云剪辑、云导播等产品,其中一个非常直接的需求就是背景图像的生成,我们在开源的stable diffusion等模型以及阿里通义大模型的基础上,结合视频云场景做了一些算法创新实践,使得生成图像与场景更匹配、生成质量更高。
对于门槛更高的视频生成,我们也关注到runway等公司在这方面取得的长足进步,它生成视频的单帧质量接近sd等的效果,而且帧间一致性表现也挺好,不过离人们的预期还有距离。我们从视频云的业务场景出发,选择视频编辑赛道,重点开发视频转绘功能,即把视频转成不同的风格,从而提升剪辑产品的竞争力。此外,我们也选择较为合适的文生动画作为视频生成的一个细分场景进行探索。
Q8:在大模型算法实践方面,目前阿里云视频云在音视频全链路的哪些环节取得了新进展?
在过去近一年的时间内,视频云在大模型方面做了深入探索,开发了多个算法原子,所做工作涉及音视频生产、处理、管理、传输与分发、播放与消费全链路的多个环节。
比如,在音视频生产环节,我们开发了实景抠图、人声克隆、文生图、图生图、AI作曲等多个基于大模型的算法。其中人声克隆,经过算法的深入打磨,克隆出的声音跟本人的原始声音基本无法分辨。同时,结合语音驱动的数字人技术,人声克隆还可以打造出高度真实、自然的数字人,目前视频云的数字人产品也已上线,受到广泛关注。
此外,视频云在处理、媒资管理以及消费环节,都已经开发了基于大模型的算法,在算法效果方面有了不错的提升。
Q9:未来,结合大模型本身的进化(未来的多模态),阿里云视频云的思考以及探索路线?
目前大模型技术发展很快,如何“趁势而为”,更好地与音视频业务结合,有很多值得探索的方向,比如之前提到的端侧处理等。
我们知道大模型提供了多种解决问题的工具,比如问答、对话、文生图、图生图、视频描述等等,这些工具正在不断完善,能力越来越强,但基本都是解决单方面问题。我们希望大模型具有感知、规划、行动的能力,而这就是当前Agent的概念。这里的感知是多模态的,可以是音频、视频、文本等,不断提升大模型作为决策大脑的能力,让它能根据业务的需要,自主分析、规划行动路径,调度工具大模型。实际上不只在算法方面,在视频云的引擎、调度、业务层都已经涉及到非常多AI的能力。

03 AIGC,效率效果的「智能跃迁」
从单纯的辅助决策,到像人类一样思考,甚至再到超越人类的决策效果,也许AIGC的想象空间,只局限于我们的想象力,但视频云的全智能布局并不如此,要在音视频智能化的高速列车中保持优势,需要兼顾效率与效果的双轮提升,更需要视频云的长期布局与顶层设计。
(该部分源自与邹娟的深入对话编辑而成)
Q10:从业务的视角出发,大模型等AI技术在音视频场景中落地需要攻克哪些难题?是否需要“顶设”?
大模型在落地音视频业务时,需要解决两个问题:
首先,大模型要能与音视频处理的pipeline进行很好的融合,同时这个融合不能是粗粒度的,而最好是帧粒度的,这样才能避免多次编码带来的效率和画质损耗。
其次,由于大模型计算比传统AI计算更复杂,因此需要在算法工程优化层面做更多的工作,如利用多线程保证实时性、软硬一体提升性能、算法毛刺消除与降级等,这些工作都需要在媒体引擎层面进行整体设计和各种细节处理。
Q11:我们知道阿里云很早就开始在AI+视频的领域里扎根,而AIGC迎来爆发潮,对音视频而言是否产生了“质的飞跃”?
阿里云视频云长期坚持在AI领域进行技术布局,将AI与音视频技术相结合,并广泛应用于视频云的产品中。
事实上2017年我们已经将智能封面、AI审核、智能摘要、智能集锦、以及多种AI识别能力应用于媒体处理、视频点播、视频直播产品中,通过在部分业务环节中引入AI能力进行辅助处理,帮助客户缩短内容生产环节的耗时,助力其更快地发布视频内容。
如今AI技术爆发,我们看到它对音视频的赋能完成了从效率高到效果优的飞跃,以前我们认为AI的产出不如人工产出效果好,但现在这个局面已经发生了改变,无论是AI修复的图像画质,还是AI生成的素材质量,亦或AI可以像人一样去理解媒资内容,分析与提炼视频结构时甚至比人更细致,如今似乎已经到了音视频所有业务重新用AI去审视一遍,大部分场景可以用AI重构的时候。
Q12:针对用AI及大模型重构业务,目前阿里云视频云已经开展了哪些技术实践?
媒体内容生产有三大板块:媒资、生产制作、媒体处理,目前阿里云视频云在这三个板块都应用了AIGC技术,并在不少场景进行了技术实践。
比如在媒资领域,我们的方向是实现基于语义分析和自然语言理解的新媒资体系,将视觉内容、音频、文本内容统一到一个高维空间内,避免像传统的智能标签一样,将视频转换到文本时,出现语义的丢失或不一致。而针对搜索文本也无需使用多关键词组合的方式,可以直接输入自然语言,不再依赖分词进行搜索,整体相较于传统的智能标签,具有更好的泛化性。
在媒体处理板块,我们的技术实践则聚焦在效果优化上,无论是针对高清画质的增强,还是低清画质的修复,以及针对声音的智能全景声处理,我们令AI算法与音视频前处理算法,前处理算法与编码器有更好的配合,尽量保持真实感与细节还原,用户使用普通的播放设备也能享受高清晰度的音视频体验。
在生产制作的虚拟演播室场景,我们将基于大模型的分割算法进行了裁剪与优化,以支持实时场景的性能,同时实现了多层分割与多实体抠像,可以根据需求动态调整实景抠像的目标范围。另外,对于抠像边缘和光影的处理较之前会更加逼真,对于复杂背景的降噪也更强大,哪怕在新闻外场或者展会现场,复杂的拍摄背景+头发丝飞扬的人物,也能拥有比较完美的alpha通道成像,再结合RTC技术与虚拟背景融合,让多人实时互动虚拟演播效果提升一个台阶。
Q13:在AIGC的发展推动下,目前视频云媒体服务与LVS上海站分享时相比,解锁了哪些新场景、新能力?
LVS上海站是在7月底,在最近的3个多月,视频云媒体服务在AIGC方面有了更多的技术实践与应用,云剪辑、媒资、实时流制作、媒体处理都上线了新的AI能力,比如基于语义分析的自然语言媒资搜索、基于复杂背景的实景抠像、数字人智能剪辑合成等,这些能力大多用到了基于大模型的AIGC技术。
Q14:未来在AIGC的助力下,媒体内容生产的智能化程度有可能达到什么水平?会“类人”吗?
我认为媒体内容生产的未来趋势是进入全智能时代,即:AI从“向人学习”,到“像人一样”,最终到部分场景“超越人”,比如AI可以自主创作有故事的视频,可以对媒资内容进行全语义理解,可以自行优化音视频编码和前处理,可以尝试做一些决策处理等等,我们期待那一天的到来。

04 视频云,AI不止
Topic 1:《AI新范式下,阿里云视频云大模型算法实践》
本次演讲将分享阿里云视频云大模型算法系统架构,以及实操中的关键技术,此外还将展现大模型算法典型实践案例,以及对于未来大模型落地更多可能的思考。

Topic 2:《AIGC时代下,阿里云视频云媒体内容生产技术实践》
本次演讲将分享阿里云视频云媒体服务的整体技术架构,融合AI与传统媒体处理的一体化媒体引擎的关键技术,还将分享如何应用AIGC技术,重构媒体内容生产的三大模块—内容创作、媒体处理、媒资管理,以及AIGC落地相关场景的技术实践。

于AI中见天地
从大模型到内容生成
期待阿里云视频云的AI主题与实践分享