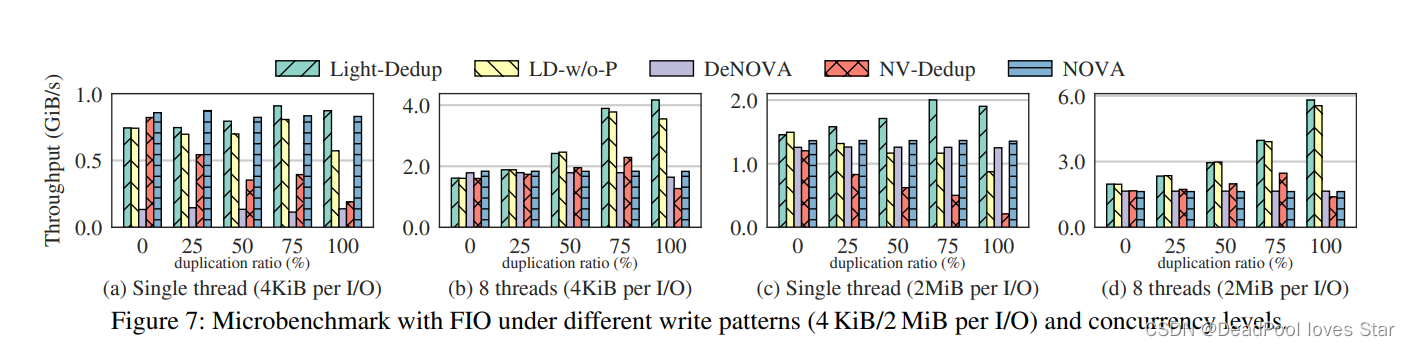
文章目录
- 主方法调用
- LetterDrawing
- WordDoingImage
上图

你也想玩的话,可以直接上码云去看 码云链接
主方法调用
import analysisdata.WordDoingImage as WordDoingImage
import analysisdata.LetterDrawing as LetterDrawing
if __name__ == '__main__':
# 输入的文本,生成的动态图,没弄英文的
text_str = '天生我材必有用,千金散尽还复来'
#移除中文符号
text_str = WordDoingImage.remove_number(text_str)
# 生成汉字图片的模版
WordDoingImage.main_method(text_str)
# 将汉字做成散点图合成gif
LetterDrawing.main_method(text_str=text_str, bg_color='#9ACD32')
#清除使用完毕的图片
LetterDrawing.delete_word_photo(text_str=text_str)
封装了两个类,调用起来更清晰了
散点图部分,参考了下面朋友的分析,大家可以去看看
https://blog.csdn.net/cainiao_python/article/details/117137163
下面是
LetterDrawing
的类
# *_m 代表独立方法,*_p 代表运行过程的方法
import os
import numpy as np
import matplotlib.pyplot as plt
import imageio
import random
import cv2
# 跟据数据情况,转化为多个随机点
def random_point_m(text, intensity=2):
# 多个随机点填充字母
random.seed(420)
x = []
y = []
for i in range(intensity):
x = x + random.sample(range(0, 1000), 500)
y = y + random.sample(range(0, 1000), 500)
if text == ' ':
return x, y
# 获取图片的mask
mask = cv2.imread(f'../photomodel/word/{text}.png', 0)
mask = cv2.flip(mask, 0)
# 检测点是否在mask中
result_x = []
result_y = []
for i in range(len(x)):
if (mask[y[i]][x[i]]) == 0:
result_x.append(x[i])
result_y.append(y[i])
# 返回x,y
return result_x, result_y
# 将输入的文本进行切割
def split_text_m(text, repeat=True, intensity=2):
print('将文本转换为数据\n')
letters = []
for i in text.upper():
letters.append(random_point_m(i, intensity=intensity))
# 如果repeat为1时,重复第一个字母
if repeat:
letters.append(random_point_m(text[0], intensity=intensity))
return letters
# 画图,生成git
def build_git_m(coordinates_lists, gif_name, n_frames, bg_color, marker_color, marker_size, font_color):
print('生成图表\n')
filenames = []
for index in np.arange(0, len(coordinates_lists) - 1):
# 获取当前图像及下一图像的x与y轴坐标值
x = coordinates_lists[index][0]
y = coordinates_lists[index][1]
x1 = coordinates_lists[index + 1][0]
y1 = coordinates_lists[index + 1][1]
# 查看两点差值
while len(x) < len(x1):
diff = len(x1) - len(x)
x = x + x[:diff]
y = y + y[:diff]
while len(x1) < len(x):
diff = len(x) - len(x1)
x1 = x1 + x1[:diff]
y1 = y1 + y1[:diff]
# 计算路径
x_path = np.array(x1) - np.array(x)
y_path = np.array(y1) - np.array(y)
for i in np.arange(0, n_frames + 1):
# 计算当前位置
x_temp = (x + (x_path / n_frames) * i)
y_temp = (y + (y_path / n_frames) * i)
# 绘制图表
fig, ax = plt.subplots(figsize=(6, 6), subplot_kw=dict(aspect="equal"))
ax.set_facecolor(bg_color)
plt.xticks([]) # 去掉x轴
plt.yticks([]) # 去掉y轴
plt.axis('off') # 去掉坐标轴
plt.scatter(x_temp, y_temp, c=marker_color, s=marker_size)
plt.xlim(0, 1000)
plt.ylim(0, 1000)
# 移除框线
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
# 网格线
ax.set_axisbelow(True)
ax.yaxis.grid(color=font_color, linestyle='dashed', alpha=0.1)
ax.xaxis.grid(color=font_color, linestyle='dashed', alpha=0.1)
# 保存图片
filename = f'../photomodel/frame_{index}_{i}.png'
if (i == n_frames):
for i in range(5):
filenames.append(filename)
filenames.append(filename)
# 保存
plt.savefig(filename, dpi=96, facecolor=bg_color)
plt.close()
print('保存图表\n')
# 生成GIF
print('生成GIF\n')
with imageio.get_writer(f'../photomodel/{gif_name}.gif', mode='I') as writer:
for filename in filenames:
image = imageio.v2.imread(filename)
writer.append_data(image)
print('保存GIF\n')
print('删除图片\n')
# 删除图片
for filename in set(filenames):
os.remove(filename)
print('完成')
pass
def main_method(text_str, bg_color):
coordinates_obj = split_text_m(text_str, repeat=True, intensity=50)
build_git_m(coordinates_obj,
gif_name=text_str[0:5],
n_frames=7,
bg_color=bg_color,
marker_color='#000000',
marker_size=0.2,
font_color='#000000')
pass
def delete_word_photo(text_str):
text_list = [text_str[i:i + 1] for i in range(0, len(text_str), 1)]
for t in text_list:
file_name = f'../photomodel/word/{t}.png'
os.remove(file_name)
pass
以下是图片生成类
WordDoingImage
,使用的词云工具,每个字生成一个图片,不用费劲的去找网络的模版图片,直接自己弄多好
# 2号词云:面朝大海,春暖花开
# B站专栏:同济子豪兄 2019-5-23
import wordcloud
import multiprocessing
import re
# 将生成的词云保存为output2-poem.png图片文件,保存到当前文件夹中
# 将汉字生成黑底的图片
def split_text_m(text_str):
"""
拆分字符串
通过slice语法切割字符串成单个汉字,形成一个数组
:return:
"""
# [word_list_analysis[i:i + num] for i in range(0, len(word_list_analysis), num)]
return [text_str[i:i + 1] for i in range(0, len(text_str), 1)]
# 作图,根据汉字形状
def draw_image(word):
# 构建词云对象w,设置词云图片宽、高、字体、背景颜色等参数,生成白底黑字的图片
for w in word:
file_name = f'../photomodel/word/{w}.png'
w = wordcloud.WordCloud(width=1000, height=1000,
background_color='white',
font_path='../fontmodel/mashanzhengmaobikaishu.ttf',
color_func=lambda *args, **kwargs: (0, 0, 0)).generate(w)
# 调用词云对象的generate方法,将文本传入
w.to_file(file_name)
# 多进程处理,加快速度
def multi_process(text_list, num):
pool = multiprocessing.Pool(num)
# 将数组拆分为多块
parts = [text_list[i:i + num] for i in range(0, len(text_list), num)]
pool.map(draw_image, parts)
pool.close()
pass
# 过滤中文符号
def remove_number(text_str):
pattern = re.compile(u'[^a-zA-Z0-9\u4e00-\u9fa5]')
return re.sub(pattern, '', text_str)
# 主方法
def main_method(text_str):
text_str = remove_number(text_str)
text_list = split_text_m(text_str)
multi_process(text_list, 4)
感谢各位能够看完,想玩的,欢迎大家踊跃讨论!!!!