AtomicLong能保证并发情况下计数的准确性,其内部通过CAS来解决并发安全性的问题。
AtomicLong的缺点:
可以看到在高并发情况下,当有大量线程同时去更新一个变量,任意一个时间点只有一个线程能够成功,绝大部分的线程在尝试更新失败后,会通过自旋的方式再次进行尝试,这样严重占用了CPU的时间片,进而导致系统性能问题。
LongAdder在【高并发】的场景下会比AtomicLong具有更好的性能,代价是消耗更多的内存空间。
工作原理
1、LongAdder设计思想上,采用分段的方式降低并发冲突的概率。通过维护一个基准值【base】和【Cell数组】
2、当没有出现多线程竞争的情况,线程会直接对base里面的value进行修改,这个操作其实和AtomicLong操作是一样的。
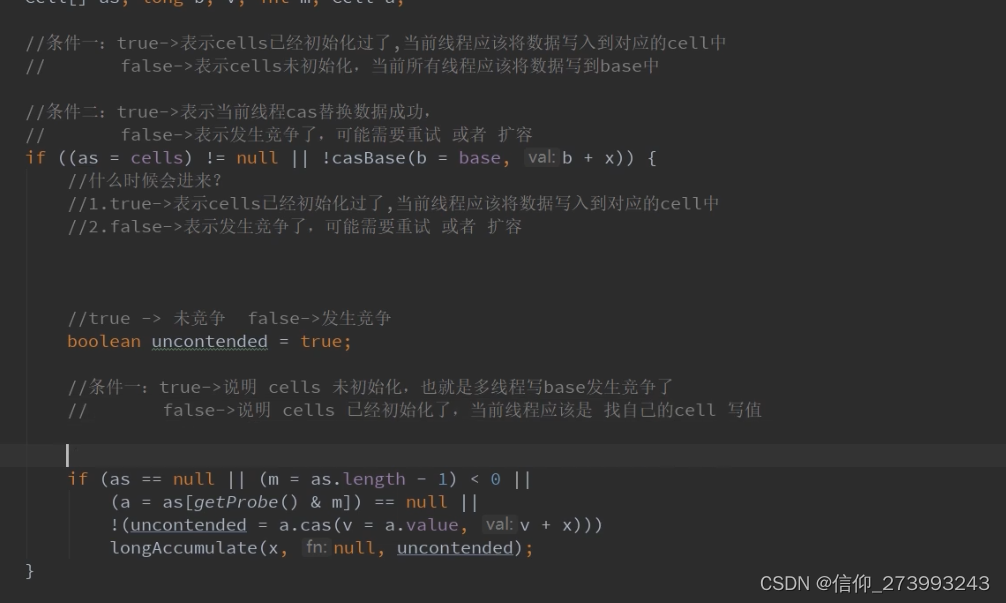
3、当多线程的时候,那么LongAdder会初始化一个cell数组,然后对每个线程获取对应的hash值,之后通过hash & (size -1)[size为cell数组的长度]
将每个线程定位到对应的cell单元格,之后这个线程将值写入对应的cell单元格中的value,之后将所有【cell单元格的value】和【base中的value】进行累加求和得到最终的值。并且每个线程竞争的Cell的下标不是固定的,如果CAS失败,会重新获取新的下标去更新,从而极大地减少了CAS失败的概率。
缺点:只能用做计数器,如果要获取总数,他是通过累加多个数组的值进行相加的,所以不是原子性的操作,实时获取值不一定准确。
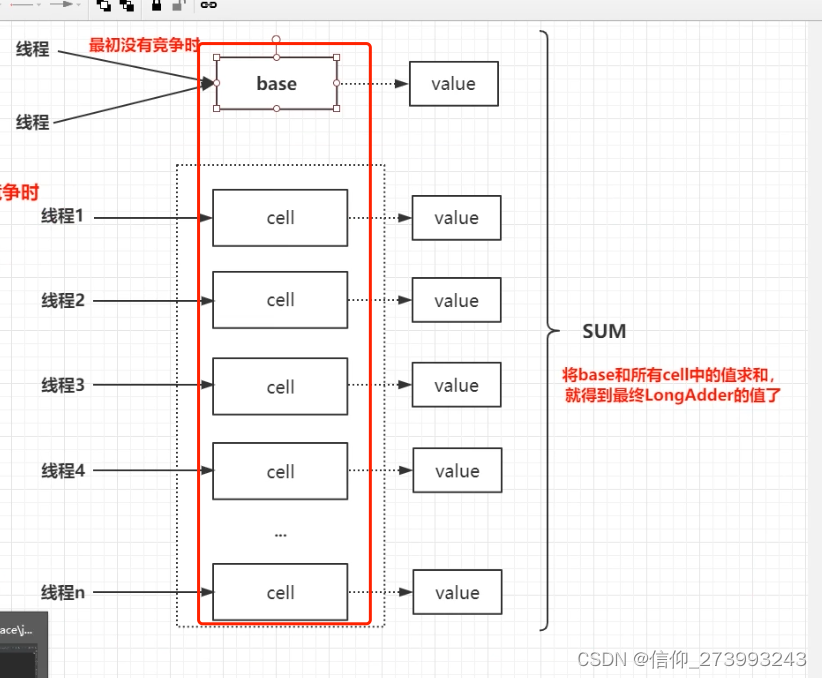
当需要拿到总数时 =base+cell[0]+cell[1]+cell[2]+cell[3]+…
LongAdder和AtomicLong性能对比
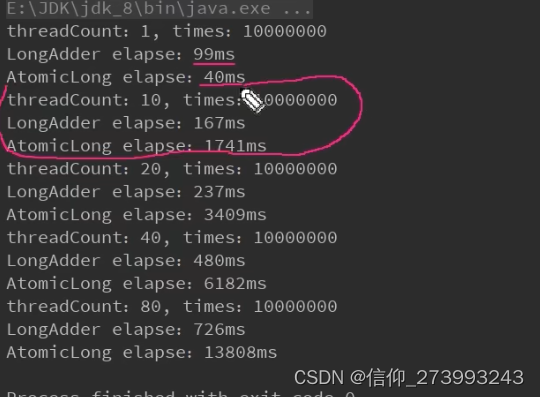
下面是记录1个线程,分别通过LongAdder、AtomicLong计算从0累加到100000000,耗时对比。
treadCount表示线程数:线程一次从1增加到80个。
结论:
1、1个线程时速度是最快的。并且AtomicLong比LongAdder还要快。
2、多个线程执行的情况下,单个线程执行的效率是最高的。
3、多个线程执行的情况下,LongAdder要快很多。
所以这也是在高并发下syn....性能很高的原因。因为AtomicLong里面还有很多无用的for自选操作。
源码

拓展
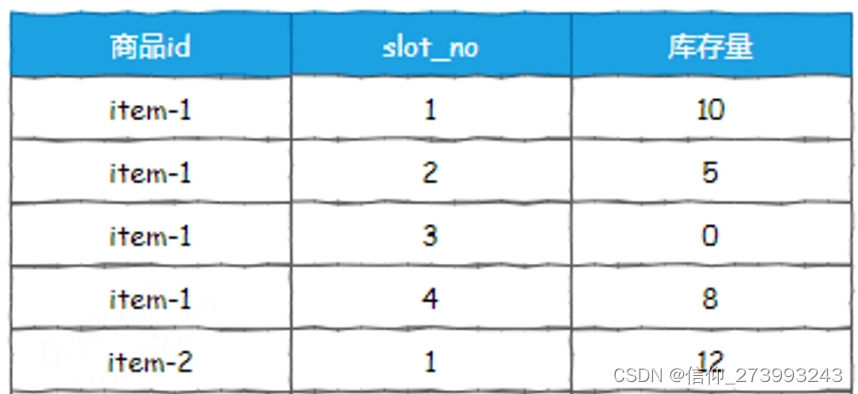
高并发的场景下,通过这种思想,还可以把同一个商品库存拆分多条数据,一条数据拆成多条数据,就变成了1个行锁,变成了多个行锁。
比如下面这种
一张表里面同一个商品Id,通过多行数据记录库存,总库存等于各行库存之后,当请求进来,通过路由策略,选择扣减指定行的库存,
这样就极大的增加了并发能力,而且就算路由到某行数据因为库存为0,但是总库存不为0,这样也没关系,因为高并发下,速度是很快的,所以也可以忽略。
当然也可以通过一些方式让库存为0的行,不参与并发的扣减
原文链接:跳转