🚩纸上得来终觉浅, 绝知此事要躬行。
🌟主页:June-Frost
🚀专栏:C++入门宝典

🔥本文主要探讨C++的语法,并深入了解C++如何针对C语言中存在的不合理之处进行优化改进。
目录:
- ⌛️ 引用
- ✉️ 特性
- ✉️ 常引用
- ✉️ 使用场景
- ✉️ 引用和指针
- ⌛️ inline内敛函数
- ⌛️ auto关键字
- ⌛️ 基于范围的for循环
- ⌛️ 空指针nullptr
- ❤️ 结语
⌛️ 引用
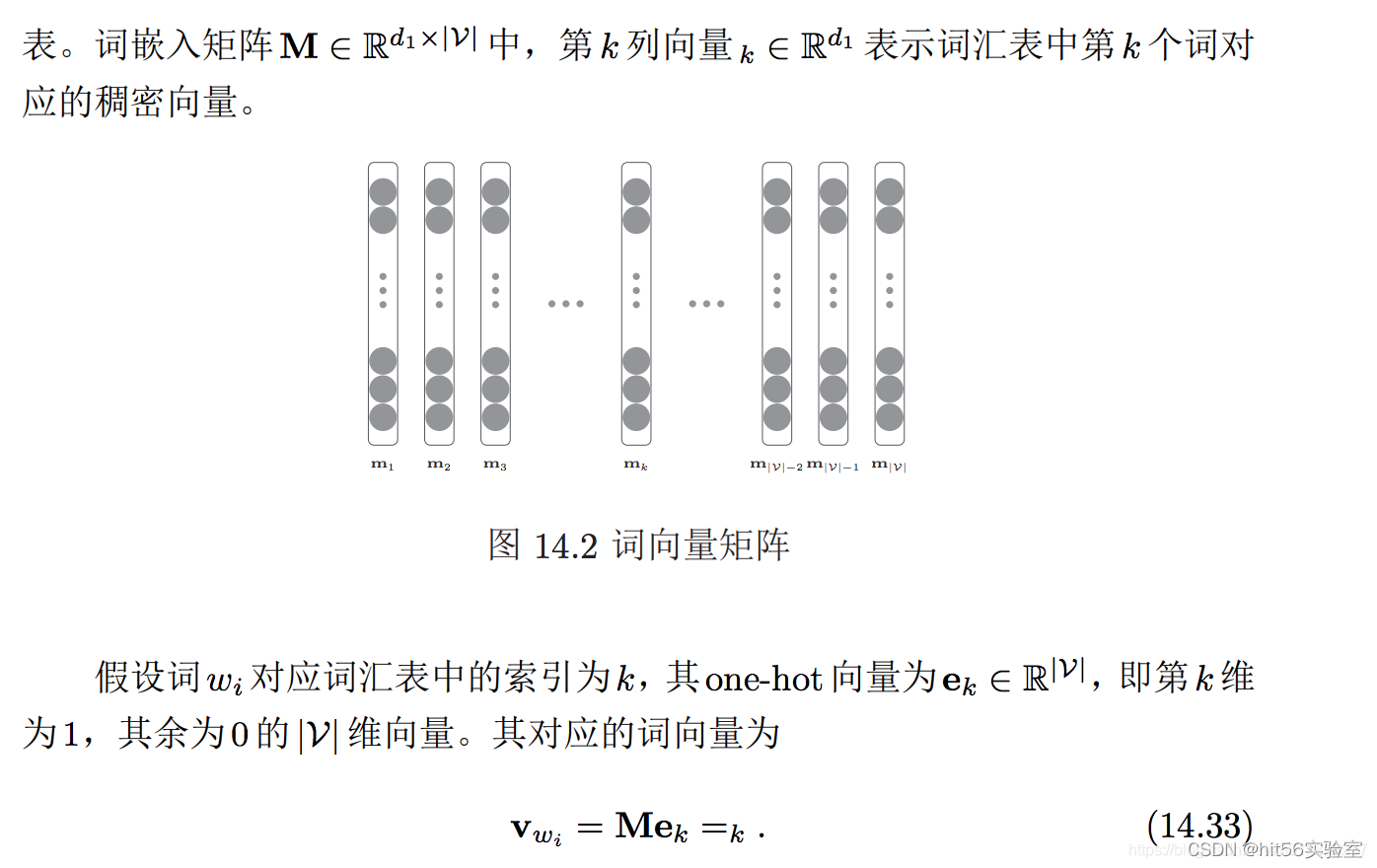
在C++中,引用是C语言的重要扩充。在语法层面上,引用是给已存在的变量取了一个别名,对引用的操作与对原变量的操作是完全相同的。编译器不会为引用变量开辟新的内存空间,而是让它和原变量共用同一块内存空间。
引用被声明为变量的类型,后面跟着一个&符号,表示这是一个引用类型。可以按照type& name = variable的形式来定义一个引用类型。
int main()
{
int value = 0;
int& tmp = value; //tmp是value的引用
tmp = 10;//修改tmp的值,value的值也会变为10
return 0;
}
注意:引用类型必须和引用实体是同种类型的,否则将会导致编译错误。
✉️ 特性
📙在前文中,我们提到了引用的概念,现在我们将阐述引用的特性。
- 引用在定义时必须初始化。
引用需要一个有效的对象,如果不初始化,会在编译时出错。
- 一旦引用一个实体,就不能引用其他实体。
这个特性是引用与指针的一个主要区别。指针可以在任何时候被重新指向另一个实体,而引用一旦被初始化,就不能改变其引用的实体。
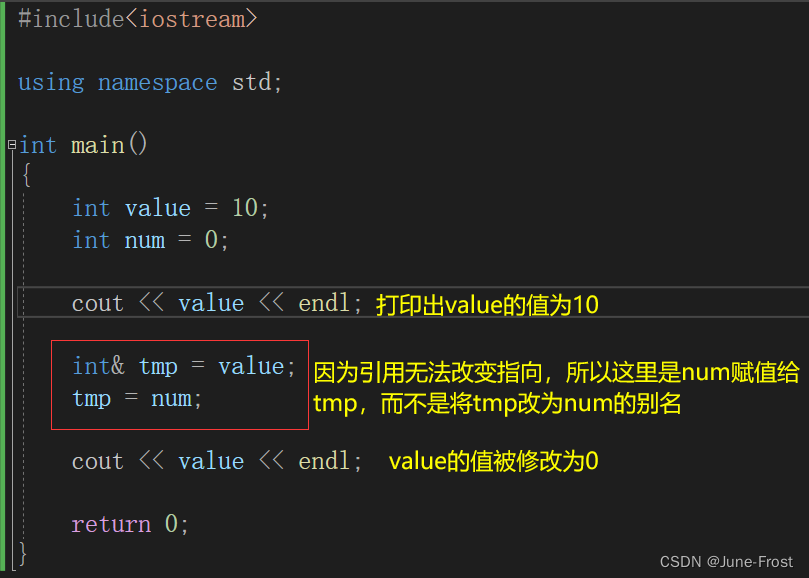
- 一个变量可以有多个引用。
可以为一个变量创建多个引用,每个引用都是这个变量的别名,也可以对别名继续取别名。

✉️ 常引用
常引用是C++中引用的一种特殊形式,它在声明时必须在引用前面加上const关键字。常引用的主要目的是为了防止通过引用来修改所引用的变量。
- 权限不能放大,可以平移。


- 权限可以缩小。

🔭 此外,还需要注意一种情况:类型转换。
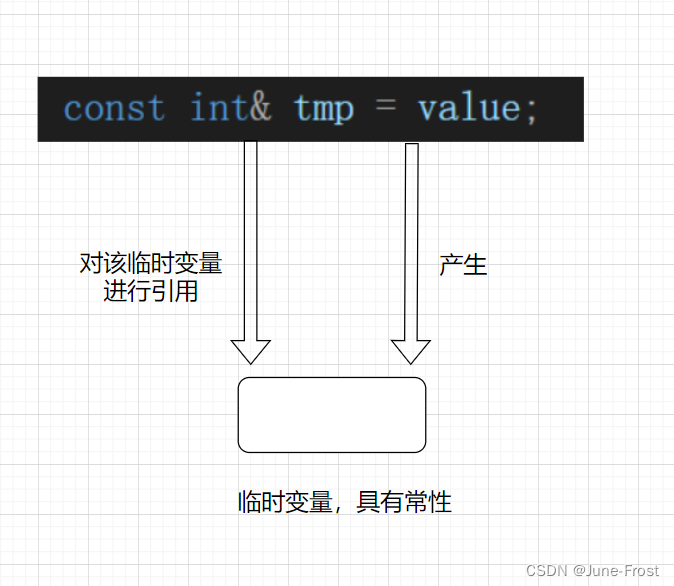
double value = 3.14;
const int& tmp = value;
📙 value是double类型,如果用int& tmp对value进行引用,会出现类型转换。实际上,tmp是引用了一个value产生的临时变量,这个临时变量具有常性,所以必须加上const进行修饰,防止权限扩大。
✉️ 使用场景
C++的引用在传参和作返回值上具有重要应用价值。
- 传参:
//交换两个值
void Swap(int& value, int& num)
{
int tmp = value;
value = num;
num = value;
}
📙引用传参有两个价值:① 由于引用相当于别名,所以在函数中可以对引用实体直接操作。②引用没有分配实际的内存空间,可以节省大量的内存空间,提高效率。
- 作返回值
#include<iostream>
#include<assert.h>
using namespace std;
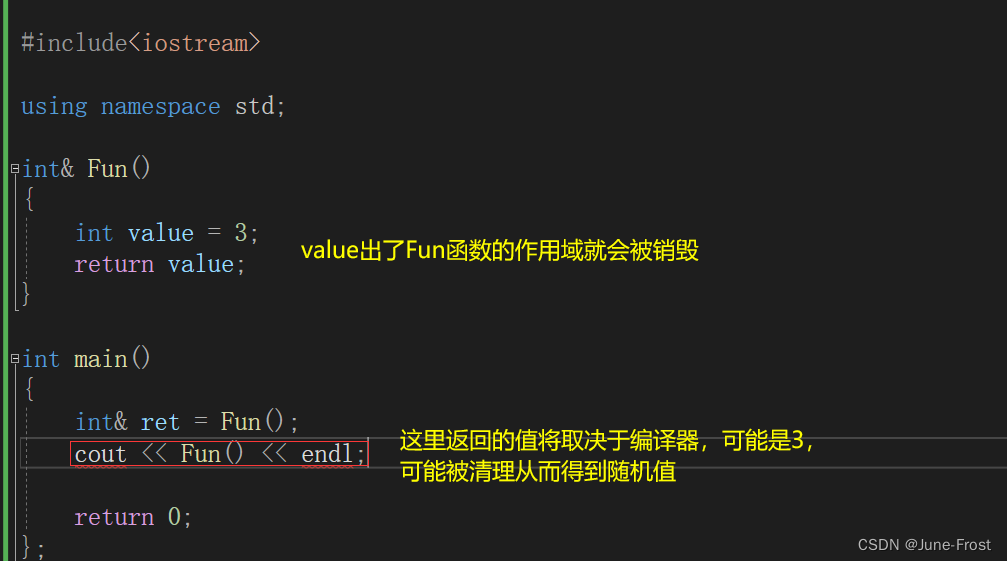
int& Fun(int* arr, int pos)//传引用返回
{
assert(arr);
return arr[pos];
}
int main()
{
int arr[] = { 1,2,3,4,5,6,7,8,9 };
Fun(arr, 3) = 10; // 数组第4个元素被修改为10
cout << arr[3] << endl;
return 0;
}
📙引用作返回值除了能提高效率外,最重要的是可以通过引用返回来修改返回对象。
注意:
传引用返回的方式适用于出了函数作用域(栈帧销毁)后,仍然还存在的对象。如果对象一旦出了函数作用域就被销毁,这时候引用返回的对象是未知的,这种情况最好使用传值返回。
✉️ 引用和指针
从语法角度看,引用自身没有开辟空间,而是与引用对象共用同一块空间。然而,从底层来看,引用的实现需要开辟空间,并且底层是依靠指针实现的。之所以使用方法不同,是因为对引用的封装。
两者的汇编代码也是非常相似的。

📘 指针和引用的区别:
-
内存分配:语法层面上,引用本身不分配内存空间,它是对已有变量的别名,与被引用变量共享内存空间。而指针变量需要分配内存空间来存储变量的地址。
-
初始化:引用在定义时必须被初始化,指针没有要求。
-
指向:引用一旦初始化后就不能再被改变。而指针可以在任何时候被重新指向一个不同的变量。
-
自增(++)运算:引用自加即引用的实体增加1,指针自加即指针向后偏移一个类型的大小。
-
没有NULL引用,但有NULL指针。
-
在sizeof中含义不同:引用结果为引用类型的大小,但指针始终是地址空间所占字节个数(32位平台下占4个字节,64位平台下占8个字节)。
-
有多级指针,但是没有多级引用。
-
访问实体方式不同,指针需要显式解引用,引用则为编译器处理。
因为引用必须被初始化,还不可以被更改等一些特性,造就了引用相对于指针更安全。
⌛️ inline内敛函数
在C语言中,宏是一种预处理指令,它提供了一种方便的宏定义和替换的方式。宏的作用主要是增强代码的复用性,提高性能。例如:一个加法函数就可以被写为#define Add(x,y) ((x)+(y)),这种方式不用创建栈帧,可以提高性能 。但是,宏也有缺点,容易出错,语法细节多,没有类型安全的检查,而且也不方便调试(预编译阶段进行了替换)。
C++中除了使用const 和 enum 的方式来代替宏之外,还可以使用内联函数。
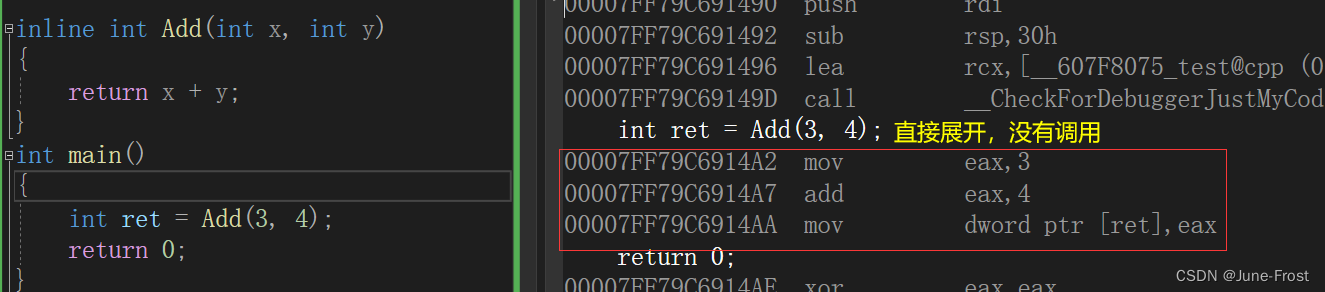
用inline修饰的函数就叫做内联函数,内联函数通常是为了提高程序的执行效率而设计的,编译时,C++编译器会在调用内联函数的地方展开,不会开辟栈帧,避免了函数调用的开销,从而提升程序运行的效率。
特性:
内联函数是一种空间换时间的方式,虽然没有函数调用的开销,但是增加了文件的大小。
需要注意,内敛函数不可以声明和定义分离。内敛函数的地址是不进入符号表的,如果函数的定义和调用不在同一个文件,在链接环节中,符号表里找不到函数的地址就会报错。因此,编译器需要在编译时能够访问到函数的完整定义,所以建议将内敛函数的定义和声明都写入头文件中。
inline对于编译器而言只是一个建议,不同编译器关于inline实现机制可能不同。如果内敛函数较长,或为递归函数,这些请求可能会被编译器忽略。也就是说,是否展开是由编译器决定的。
⌛️ auto关键字
在C++中,auto是一个关键字,它用于声明变量的类型。auto关键字可以使编译器根据变量的初始值自动推断其类型。这也就说明了使用auto定义变量时必须对其进行初始化,auto x; //无法通过编译。
当一个对象的类型较长,使用auto就会很方便。
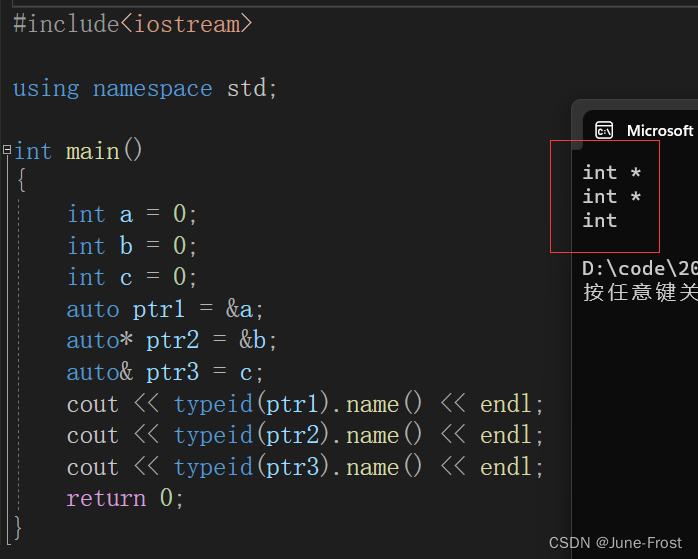
📙用auto声明指针类型时,用auto和auto*没有任何区别,但用auto声明引用类型时则必须加&
📙当在同一行声明多个变量时,这些变量必须是相同的类型,否则编译器将会报错,因为编译器实际只对第一个类型进行推导,然后用推导出来的类型定义其他变量。
auto x = 3, y = 4;
auto a = 3.0 , b = 4; //类型不同,会编译失败,
注意:
- auto不可以作函数的参数和返回值,因为编译器无法对形参的实际类型进行推导。
auto Fun(auto x) {} //错误使用示例- auto不能直接用来声明数组,
auto arr[] = { 1,2,3 };//错误使用示例。
⌛️ 基于范围的for循环
基于范围的for循环是C++11引入的一种新特性,用于简化对容器(如数组、向量、列表等)中元素的遍历。
语法:
for循环后的括号由冒号“ :”分为两部分:第一部分是范围内用于迭代的变量,第二部分则表示被迭代的范围。for (auto element : container) { // 操作element }
#include<iostream>
using namespace std;
int main()
{
int arr[] = { 1,2,3,4,5,6 };
//依次取数组中元素赋值给x
for (int x : arr)//不会改变数组的值
{
cout << x << ' ';
}
//自动判断结束,自动++往后走
cout << endl;
for (int& x : arr)//使用了引用,可以改变数组的值
{
x++;//对数组每个元素++
cout << x << ' ';
}
cout << endl;
return 0;
}
注意:for循环迭代的范围必须是确定的,对于数组而言,就是数组中第一个元素和最后一个元素的范围;对于类而言,应该提供begin和end的方法,begin和end就是for循环迭代的范围。
⌛️ 空指针nullptr
在C语言中,如果出现了一个未初始化的指针,没有合适的指向一般会赋NULL以防止形成野指针。
C语言中的NULL实际上是一个宏,被定义为0。在一些特殊的情况下会出问题。例如:
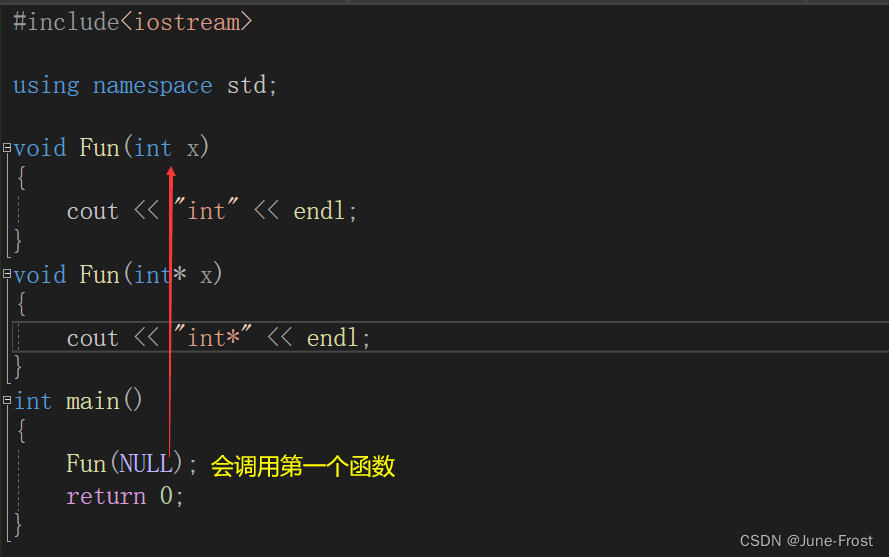
编译器默认情况下将其看成是一个整形常量,如果要将其按照指针方式来使用,必须对其进行强转(void *)0。
在C++11中,将nullptr作为关键字引入,它表示一个空指针。为了提高代码的健壮性,在后续表示指针空值时建议最好使用nullptr。
❤️ 结语
文章到这里就结束了,如果对你有帮助,你的点赞将会是我的最大动力,如果大家有什么问题或者不同的见解,欢迎大家的留言~





![[Kettle] 获取系统信息](https://img-blog.csdnimg.cn/aa0aa17db82e4de2a9ab4ea24e724b77.png)