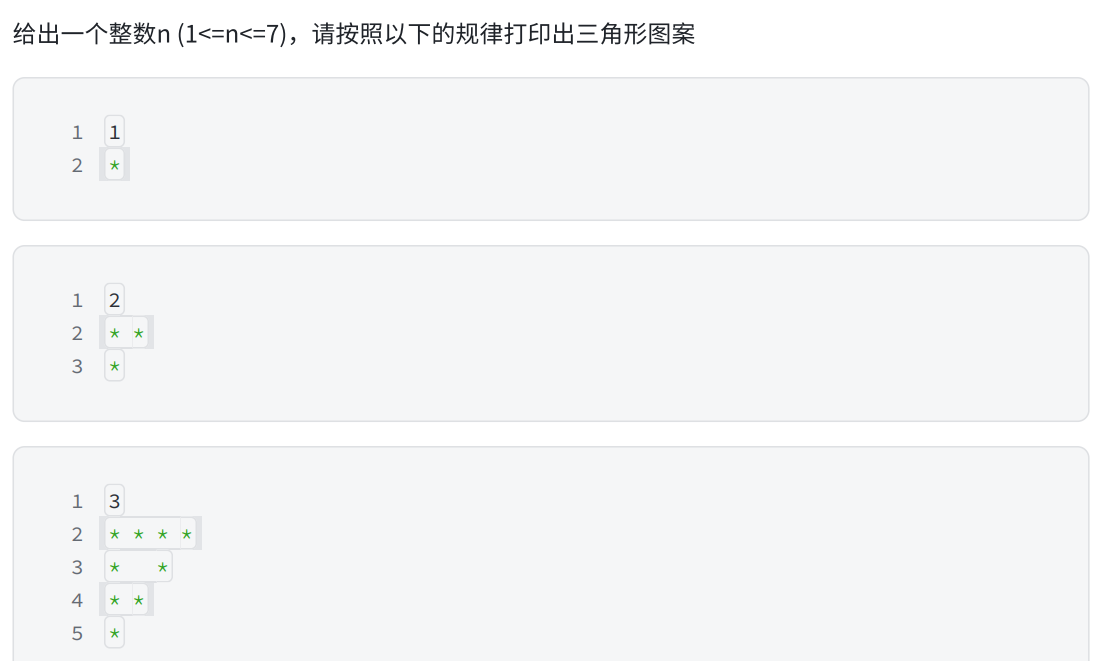
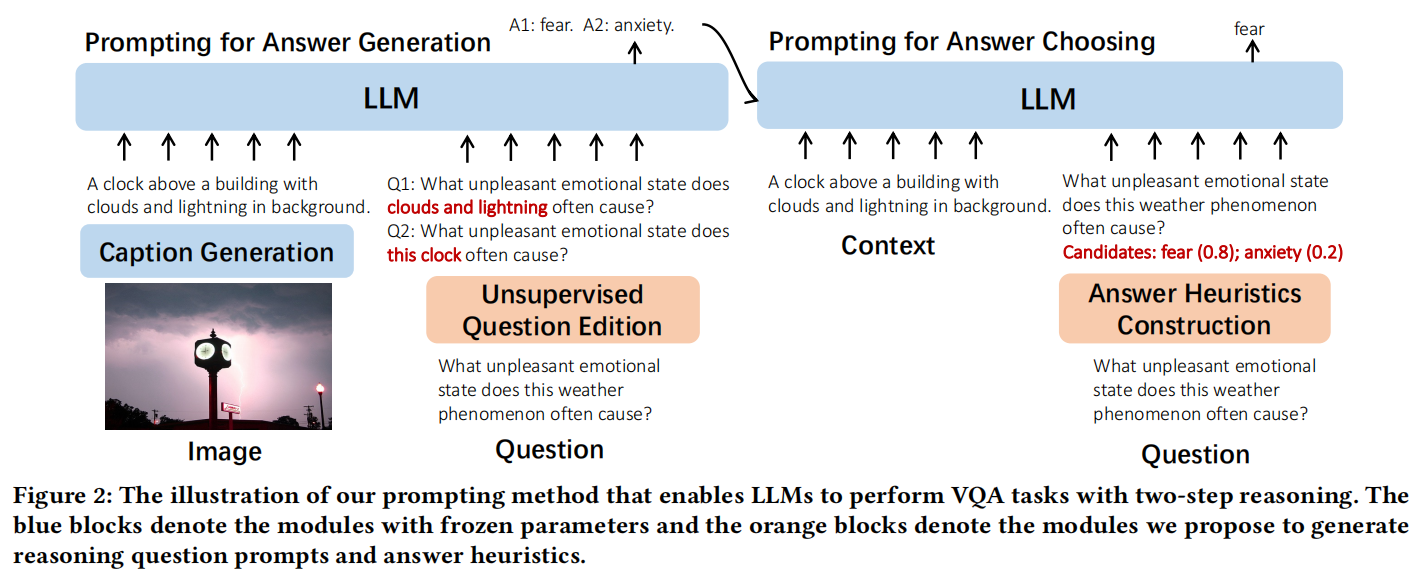
多模态机器学习(MultiModal Machine Learning, MMML)是一种机器学习方法,它旨在解决复杂任务,如多模态情感分析、跨语言图像搜索等,这些任务需要同时考虑多种模态的数据并从中提取有用的信息。
得益于各种语言、视觉、视频、音频等大模型的性能不断提升,多模态机器学习也逐渐兴起,它可以帮助人工智能更全面、深入地理解周围环境,提高模型的泛化能力和鲁棒性,同时还可以促进各学科之间的交流和融合。
在发展过程中,多模态机器学习的研究也面临着许多方面的挑战,对于想要发论文的同学来说,了解这些挑战并掌握已有的解决方案十分重要,可以帮助我们在此基础上做出创新,快速找到自己的idea。
为了帮助同学们发出自己的paper,我这次又爆肝整理了多模态机器学习相关的81篇论文,包含表征、对齐、推理、生成、迁移、量化6个核心技术挑战分类,篇幅原因每个分类只做简单介绍。
需要论文及源码的同学看文末
表征(12篇)
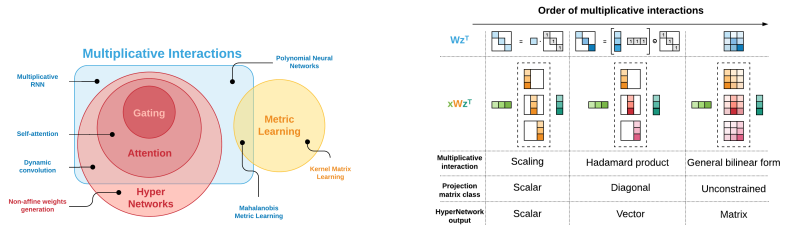
1.Multiplicative Interactions and Where to Find Them
乘法交互作用及其来源
简述:论文探讨了乘法交互在神经网络设计中的作用,它是一种可以描述多种神经网络架构模式(如门控、注意力层、超网络和动态卷积等)的统一框架。作者认为,乘法交互层可以丰富神经网络的函数类,并且在融合多信息流或条件计算时提供强大的归纳偏差。通过在大型复杂强化学习和序列建模任务中的应用,作者证明了乘法交互的潜力和有效性,它可以提高神经网络的表现,并提供设计新神经网络体系结构的新思路。
-
2.Tensor fusion network for multimodal sentiment analysis
-
3.On the Benefits of Early Fusion in Multimodal Representation Learning
-
4.Extending long short-term memory for multi-view structured learning
-
5.Devise: A deep visual-semantic embedding model
-
6.Learning transferable visual models from natural language supervision
-
7.Order-embeddings of images and language
-
8.Learning Concept Taxonomies from Multi-modal Data
-
9.Does my multimodal model learn cross-modal interactions? It’s harder to tell than you might think!
-
10.Learning factorized multimodal representations
-
11.Multimodal clustering networks for self-supervised learning from unlabeled videos
-
12.Deep multimodal subspace clustering networks
对齐(10篇)
1.Visual Referring Expression Recognition: What Do Systems Actually Learn?
视觉参照表达识别:系统实际学到了什么?
简述:论文对最先进的指称表达式识别系统进行了实证分析,发现这些系统可能会忽略语言结构,而依赖数据选择和注释过程中的浅层相关性。作者以一个在没有输入指称表达式的情况下在输入图像上训练和测试的系统为例,发现该系统可以在前两名预测中达到71.2%的精度。此外,只给定输入即可预测对象类别的系统在前两名预测中可以达到84.2%的精度。这些结果说明,在追求基于语言的实际任务上取得实质性进展时,仔细分析模型正在学习什么以及数据是如何构建的是至关重要的。

-
2.Unsupervised multimodal representation learning across medical images and reports
-
3.Clip-event: Connecting text and images with event structures
-
4.Learning by aligning videos in time
-
5.Multimodal adversarial network for cross-modal retrieval
-
6.Videobert: A joint model for video and language representation learning
-
7.Visualbert: A simple and performant baseline for vision and language
-
8.Decoupling the role of data, attention, and losses in multimodal transformers
-
9.Vilbert: Pretraining task-agnostic visiolinguistic representations for vision-and-language tasks
-
10.MTAG: Modal-Temporal Attention Graph for Unaligned Human Multimodal Language Sequences
推理(18篇)
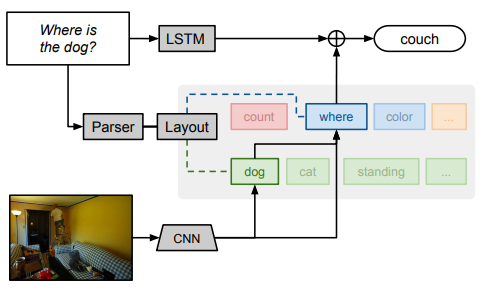
1.Neural module networks
神经模块网络
简述:论文描述了一种构建和学习神经模块网络的程序,该程序将联合训练的神经“模块”组合成用于问题回答的深度网络。作者的方法将问题分解为其语言子结构,并使用这些结构动态实例化模块网络(带有可重用的组件以识别狗、对颜色进行分类等)。所得的复合网络是联合训练的。作者在两个具有挑战性的视觉问题回答数据集上评估了该方法,在VQA自然图像数据集和关于抽象形状的复杂问题的新数据集上都取得了最佳结果。
-
2.Dynamic memory networks for visual and textual question answering
-
3.A Survey of Reinforcement Learning Informed by Natural Language
-
4.Mfas: Multimodal fusion architecture search
-
5.Multi-view intact space learning
-
6.Neuro-Symbolic Visual Reasoning: Disentangling Visual from Reasoning
-
7.Probabilistic neural symbolic models for interpretable visual question answering
-
8.Learning by abstraction: The neural state machine
-
9.Socratic models: Composing zero-shot multimodal reasoning with language
-
10.Vqa-lol: Visual question answering under the lens of logic
-
11.Multimodal logical inference system for visual-textual entailment
-
12.Towards causal vqa: Revealing and reducing spurious correlations by invariant and covariant semantic editing
-
13.Counterfactual vqa: A cause-effect look at language bias
-
14.Exploring visual relationship for image captioning
-
15.KAT: A Knowledge Augmented Transformer for Vision-and-Language
-
16.Building a large-scale multimodal knowledge base system for answering visual queries
-
17.Visualcomet: Reasoning about the dynamic context of a still image
-
18.From Recognition to Cognition: Visual Commonsense Reasoning
生成(12篇)
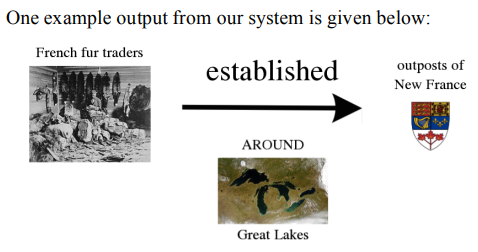
1.Multimodal summarization of complex sentences
复杂句的多模态总结
简述:论文提出了将复杂句子自动说明为多模态总结的想法,这些总结结合了图片、结构和简化压缩文本。除了图片之外,多模态总结还提供了关于发生了什么、谁做的、对谁做和如何做的额外线索,这可能有助于阅读困难的人或希望快速浏览的人。作者提出了ROC-MMS,一个用于自动创建复杂句子的多模态总结(MMS)的系统,通过生成图片、文本摘要和结构,作者发现,仅凭图片不足以帮助人们理解大多数句子,尤其是对不熟悉该领域的读者而言。
-
2.Extractive Text-Image Summarization Using Multi-Modal RNN
-
3.Multi-modal Summarization for Asynchronous Collection of Text, Image, Audio and Video
-
4.Multimodal abstractive summarization ` for how2 videos
-
5.Deep fragment embeddings for bidirectional image sentence mapping
-
6.Phrase-based image captioning
-
7.Style transfer for co-speech gesture animation: A multi-speaker conditional-mixture approach
-
8.You said that?: Synthesising talking faces from audio
-
9.Zero-shot text-to-image generation
-
10.Stochastic video generation with a learned prior
-
11.Parallel wavenet: Fast high-fidelity speech synthesis
-
12.Arbitrary talking face generation via attentional audio-visual coherence learning
迁移(13篇)
1.Integrating Multimodal Information in Large Pretrained Transformers
在大型预训练Transformer中集成多模态信息
简述:这篇论文提出了一个叫做Multimodal Adaptation Gate(MAG)的装置,可以附加到BERT和XLNet上,让它们在微调期间接受多模态非语言数据。这个装置通过生成对BERT和XLNet内部表示的转变来实现,而这个转变是有条件于视觉和声学模态的。实验表明,微调MAG-BERT和MAG-XLNet可以显著提高情感分析性能,超过了以前的基线和仅语言微调的BERT和XLNet。在CMU-MOSI数据集上,MAG-XLNet首次实现了人类级别的多模态情感分析性能。

-
2.Multimodal few-shot learning with frozen language models
-
3.HighMMT: Towards Modality and Task Generalization for High-Modality Representation Learning
-
4.FLAVA: A Foundational Language And Vision Alignment Model
-
5.Pretrained transformers as universal computation engines
-
6.Scaling up visual and visual language representation learning with noisy text supervision
-
7.Foundations of multimodal co-learning
-
8.Found in translation: Learning robust joint representations by cyclic translations between modalities
-
9.Vokenization: Improving Language Understanding with Contextualized, VisualGrounded Supervision
-
10.Combining labeled and unlabeled data with co-training
-
11.Cross-modal data programming enables rapid medical machine learning
-
12.An information theoretic framework for multi-view learning
-
13.Comprehensive Semi-Supervised Multi-Modal Learning
量化(16篇)
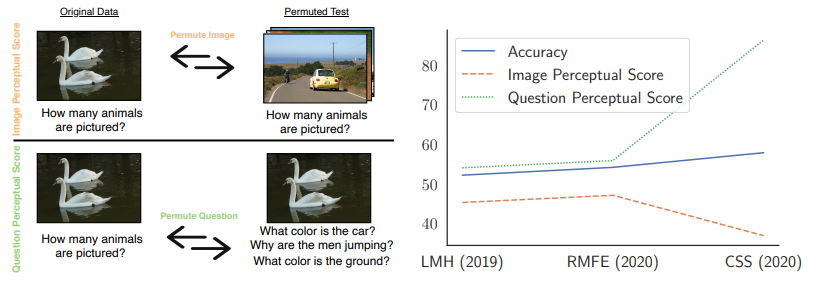
1.Perceptual Score: What Data Modalities Does Your Model Perceive?
你的模型感知到什么样的数据模式?
简述:这篇论文介绍了一种新的度量方法,称为感知分数,用于评估模型对输入特征的不同子集(即模态)的依赖程度。通过使用感知分数,作者发现四个流行数据集上的一种惊人一致趋势:最近更准确、最先进的视觉问题回答或多模态对话视觉模型往往不如其前辈对视觉数据的感知。这种趋势令人担忧,因为答案越来越多地从文本线索中推断出来。使用感知分数还可以通过将分数分解为数据子集的贡献来帮助分析模型偏差。作者希望就多模态模型的感知能力展开讨论,并鼓励从事多模态分类器工作的社区开始通过提出的感知分数来量化感知能力。
-
2.Multimodal explanations: Justifying decisions and pointing to the evidence
-
3.Women also snowboard: Overcoming bias in captioning models
-
4.FairCVtest Demo: Understanding Bias in Multimodal Learning with a Testbed in Fair Automatic Recruitment
-
5.Smil: Multimodal learning with severely missing modality
-
6.VL-InterpreT: An Interactive Visualization Tool for Interpreting Vision-Language Transformers
-
7.Behind the scene: Revealing the secrets of pre-trained vision-and-language models
-
8.Winoground: Probing Vision and Language Models for Visio-Linguistic Compositionality
-
9.Does my multimodal model learn cross-modal interactions? It’s harder to tell than you might think!
-
10.MultiViz: Towards Visualizing and Understanding Multimodal Models
-
11.M2Lens: Visualizing and explaining multimodal models for sentiment analysis
-
12. HighMMT: Towards Modality and Task Generalization for High-Modality Representation Learning
-
13.One model to learn them all
-
14.What Makes Training Multi-Modal Classification Networks Hard?
-
15.Characterizing and overcoming the greedy nature of learning in multi-modal deep neural networks
-
16.MultiBench: Multiscale Benchmarks for Multimodal Representation Learning
关注下方《学姐带你玩AI》🚀🚀🚀
回复“多模态ML”领取全部论文及源码
码字不易,欢迎大家点赞评论收藏!
![sql注入 [极客大挑战 2019]HardSQL1](https://img-blog.csdnimg.cn/4d2eb3b71a5144d4912d593d0d1e3844.png)

![集成多元算法,打造高效字面文本相似度计算与匹配搜索解决方案,助力文本匹配冷启动[BM25、词向量、SimHash、Tfidf、SequenceMatcher]](https://img-blog.csdnimg.cn/d553c7dadca54bdb82a3a234befb74d8.png#pic_center)