TPC-H是一个决策支持基准(Decision Support Benchmark),它由一套面向业务的特别查询和并发数据修改组成。查询和填充数据库的数据具有广泛的行业相关性。这个基准测试演示了检查大量数据、执行高度复杂的查询并回答关键业务问题的决策支持系统。TPC-H报告的性能指标称为TPC-H每小时复合查询性能指标(QphH@Size),反映了系统处理查询能力的多个方面。这些方面包括执行查询时所选择的数据库大小,由单个流提交查询时的查询处理能力,以及由多个并发用户提交查询时的查询吞吐量。
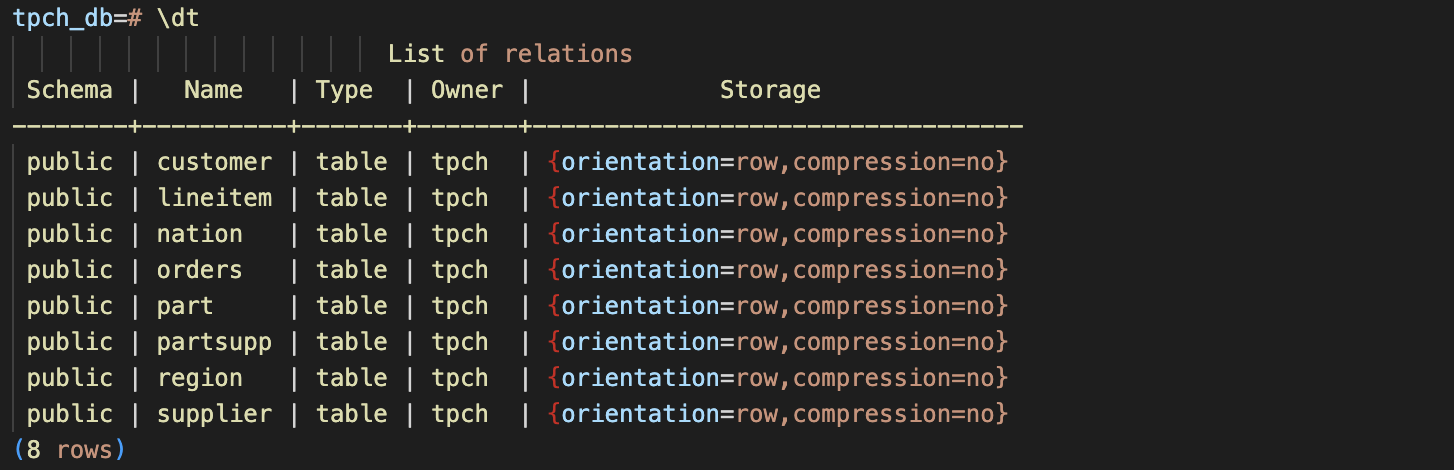
TPC-H 测试标准模拟了一个零部件在线销售的系统,共定义了8个表:
| 表名称 | 说明 |
|---|---|
| REGION | 区域表 |
| NATION | 国家表 |
| SUPPLIER | 供应商表 |
| PART | 零部件表 |
| PARTSUPP | 零部件供应表 |
| CUSTOMER | 客户表 |
| ORDERS | 订单表 |
| LINEITEM | 订单明细表 |
对应测试有22条SQL,涉及不同类型的业务。
| 查询语句 | 说明 | 主要涉及业务 |
|---|---|---|
| Q1 | 价格统计报告查询 | 带有分组、排序、聚集操作并存的单表查询操作。这个查询会导致表上的数据有95%到97%行被读取到。 |
| Q2 | 最小代价供货商查询 | 带有排序、聚集操作、子查询并存的多表查询操作。查询语句没有从语法上限制返回多少条元组,但是TPC-H标准规定,查询结果只返回前100行(通常依赖于应用程序实现)。 |
| Q3 | 运送优先级查询 | 带有分组、排序、聚集操作并存的三表查询操作。查询语句没有从语法上限制返回多少条元组,但是TPC-H标准规定,查询结果只返回前10行(通常依赖于应用程序实现)。 |
| Q4 | 订单优先级查询 | 带有分组、排序、聚集操作、子查询并存的单表查询操作。子查询是相关子查询。 |
| Q5 | 本地供应商收入量查询 | 带有分组、排序、聚集操作、子查询并存的多表连接查询操作。 |
| Q6 | 预测收入变化查询 | 带有聚集操作的单表查询操作。查询语句使用了BETWEEN-AND操作符,有的数据库可以对BETWEEN-AND进行优化。 |
| Q7 | 批量出货查询 | 带有分组、排序、聚集、子查询操作并存的多表查询操作。子查询的父层查询不存在其他查询对象,是格式相对简单的子查询。 |
| Q8 | 国家市场份额查询 | 带有分组、排序、聚集、子查询操作并存的查询操作。子查询的父层查询不存在其他查询对象,是格式相对简单的子查询,但子查询自身是多表连接的查询。 |
| Q9 | 产品类型利润估量查询 | 带有分组、排序、聚集、子查询操作并存的查询操作。子查询的父层查询不存在其他查询对象,是格式相对简单的子查询,但子查询自身是多表连接的查询。子查询中使用了LIKE操作符,有的查询优化器不支持对LIKE操作符进行优化。 |
| Q10 | 货运存在问题的查询 | 带有分组、排序、聚集操作并存的多表连接查询操作。查询语句没有从语法上限制返回多少条元组,但是TPC-H标准规定,查询结果只返回前10行(通常依赖于应用程序实现)。 |
| Q11 | 库存价值查询 | 带有分组、排序、聚集、子查询操作并存的多表连接查询操作。子查询位于分组操作的HAVING条件中。 |
| Q12 | 货运模式和订单优先级查询 | 带有分组、排序、聚集操作并存的两表连接查询操作。 |
| Q13 | 消费者订单数量查询 | 带有分组、排序、聚集、子查询、左外连接操作并存的查询操作。 |
| Q14 | 促销效果查询 | 带有分组、排序、聚集、子查询、左外连接操作并存的查询操作。 |
| Q15 | 头等供货商查询 | 带有分排序、聚集、聚集子查询操作并存的普通表与视图的连接操作。 |
| Q16 | 零件/供货商关系查询 | 带有分组、排序、聚集、去重、NOT IN子查询操作并存的两表连接操作。 |
| Q17 | 小订单收入查询 | 带有聚集、聚集子查询操作并存的两表连接操作。 |
| Q18 | 大订单顾客查询 | 带有分组、排序、聚集、IN子查询操作并存的三表连接操作。查询语句没有从语法上限制返回多少条元组,但是TPC-H标准规定,查询结果只返回前100行(通常依赖于应用程序实现)。 |
| Q19 | 折扣收入查询 | 带有分组、排序、聚集、IN子查询操作并存的三表连接操作。 |
| Q20 | 供货商竞争力查询 | 带有排序、聚集、IN子查询、普通子查询操作并存的两表连接操作。 |
| Q21 | 供应商留单等待查询 | 带有分组、排序、聚集、EXISTS子查询、NOT EXISTS子查询操作并存的四表连接操作。查询语句没有从语法上限制返回多少条元组,但是TPC-H标准规定,查询结果只返回前100行(通常依赖于应用程序实现)。 |
| Q22 | 全球销售机会查询 | 带有分组、排序、聚集、EXISTS子查询、NOT EXISTS子查询操作并存的四表连接操作。 |
如下是openGaus/MogDB测试TPCH的流程。可供参考:
上传TPCH的工具包
链接: https://pan.baidu.com/s/1REqknBiMWtkE5ECbQPXJzg 提取码: qjbc
一、创建压测的数据库和用户
MogDB=# create database tpch_db;
CREATE DATABASE
MogDB=# create user tpch with password 'Abcd@1234' sysadmin;
NOTICE: The encrypted password contains MD5 ciphertext, which is not secure.
CREATE ROLE
MogDB=# alter database tpch_db owner to tpch ;
ALTER DATABASE
tpch_db=# alter schema public owner to tpch ;
ALTER SCHEMA
二、建测试表
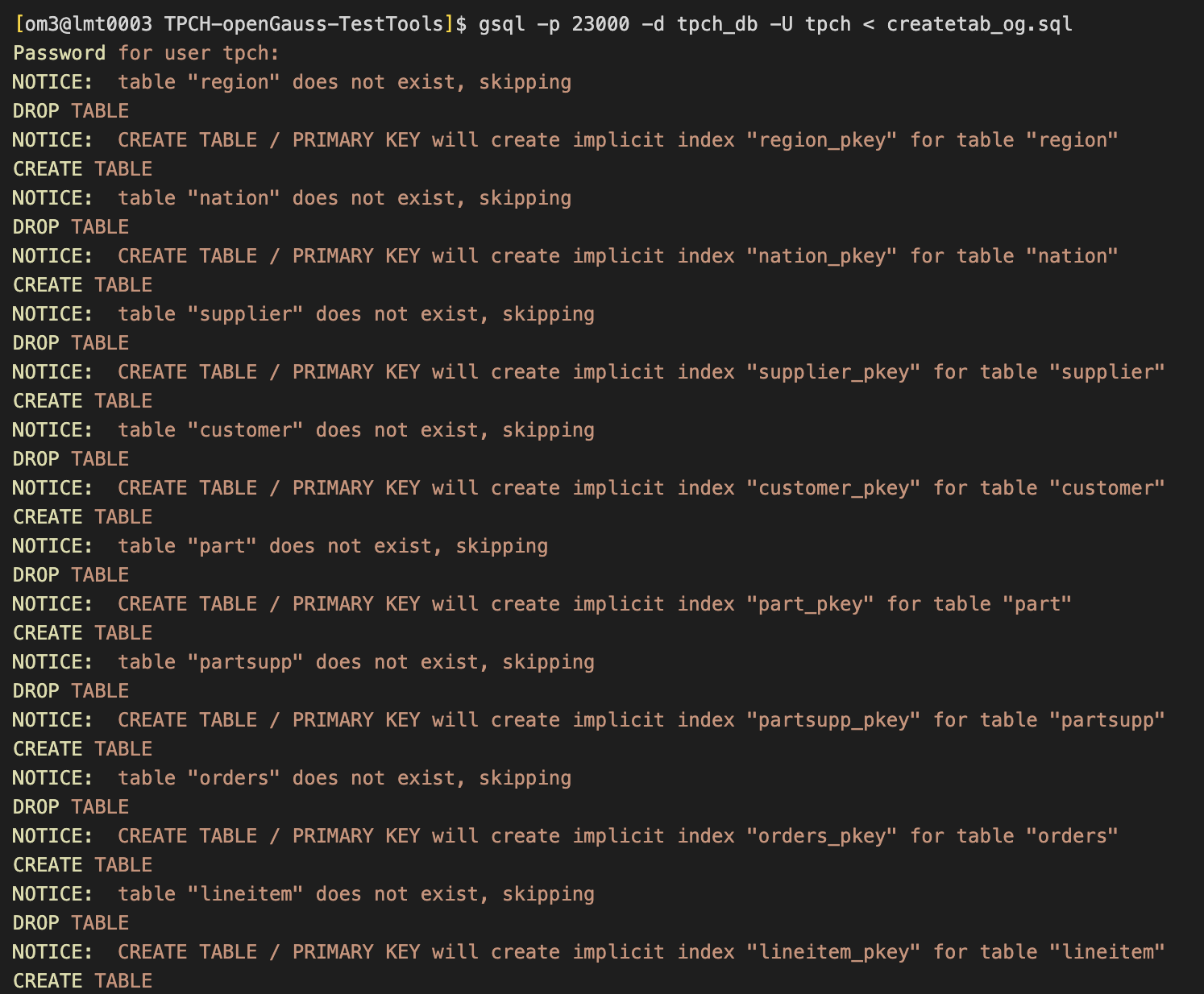
gsql -p 23000 -d tpch_db -U tpch < createtab_og.sql
三、编译dbgen软件
解压TPCH的包,进入dbgen的目录
1.修改makefile文件
[om3@lmt0003 TPC-H_Tools_v3.0.0]$ pwd
/home/om3/TPCH-openGauss-TestTools/TPCH-openGauss-TestTools/TPC-H_Tools_v3.0.0
[om3@lmt0003 TPC-H_Tools_v3.0.0]$ cd dbgen/
[om3@lmt0003 dbgen]$ ls
answers build.c dists.dss dsstypes.h permute.h queries rnd.h tests tpch.vcproj
bcd2.c check_answers driver.c HISTORY PORTING.NOTES README rng64.c text.c update_release.sh
bcd2.h column_split.sh dss.ddl load_stub.c print.c reference rng64.h tpcd.h variants
bm_utils.c config.h dss.h makefile.suite qgen.c release.h shared.h tpch.dsw varsub.c
BUGS dbgen.dsp dss.ri permute.c qgen.vcproj rnd.c speed_seed.c tpch.sln
[om3@lmt0003 dbgen]$ cp makefile.suite makefile
[om3@lmt0003 dbgen]$ vi makefile
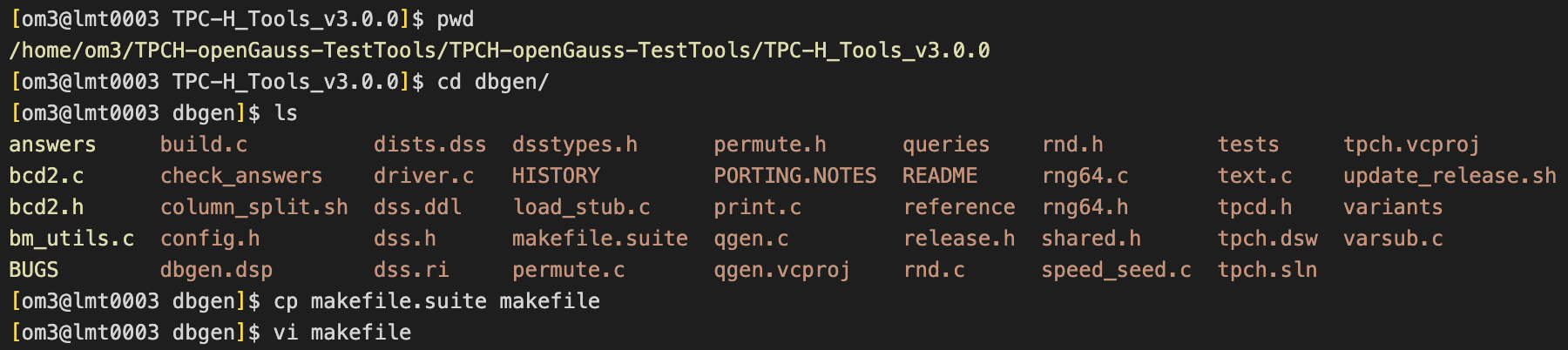
修改其中103到112行
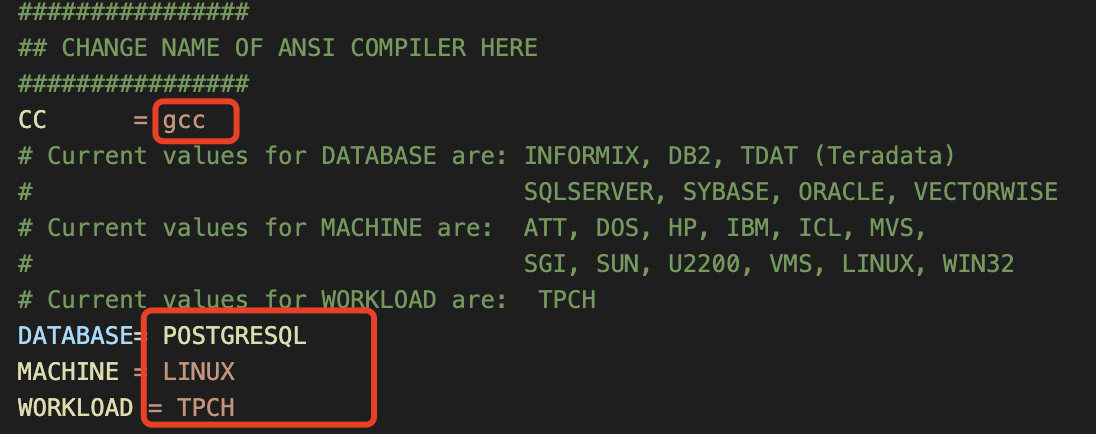
2.修改tpcd.h
[om3@lmt0003 dbgen]$ vi tpcd.h
在文件末尾加上
#ifdef POSTGRESQL
#define GEN_QUERY_PLAN "EXPLAIN PLAN"
#define START_TRAN "SET TRANSACTION"
#define END_TRAN "COMMIT;"
#define SET_OUTPUT ""
#define SET_ROWCOUNT "LIMIT %d\n"
#define SET_DBASE ""
#endif
修改完编译配置文件,可以编译出程序
3.编译dbgen
[om3@lmt0003 dbgen]$ make -f makefile
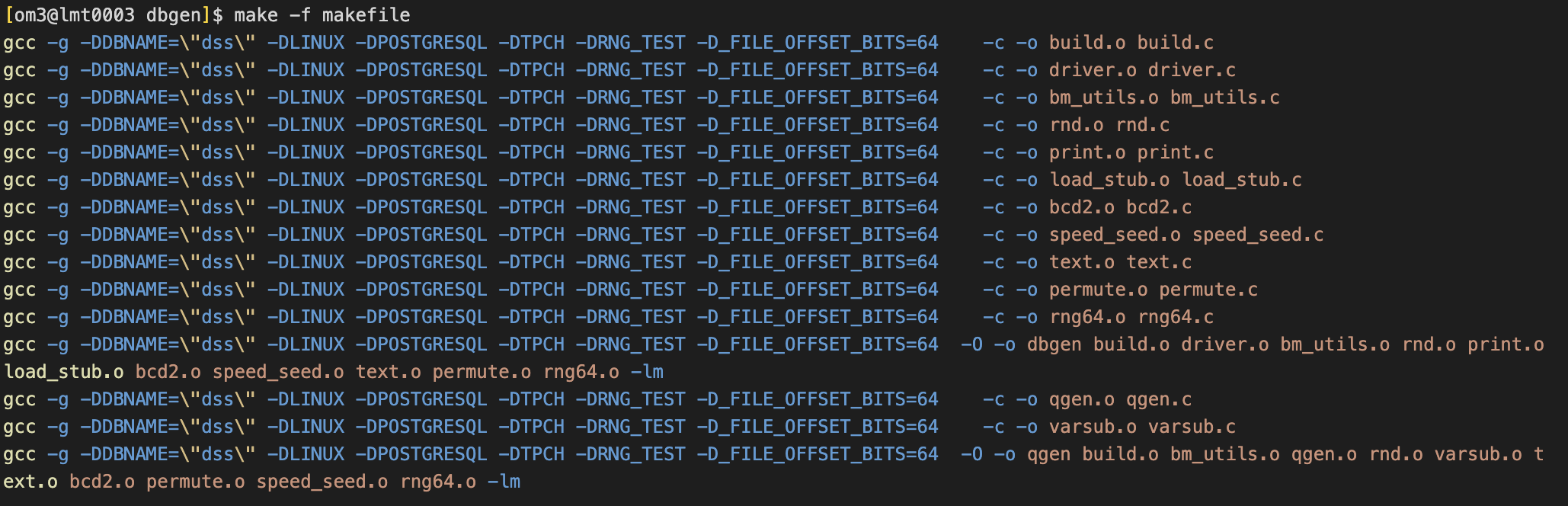

参数说明:
-v:详细信息
-f:覆盖之前的文件
-s:生成数据大小,单位GB
-C参数:表示把生成的数据分为几份
-S参数:切分数据用,表示第几个文件,例如:“-S 1”表示第1个文件,“-S 2”表示第2个文件
四、生成数据
例:
1.生成1G数据
./dbgen vf -s 1
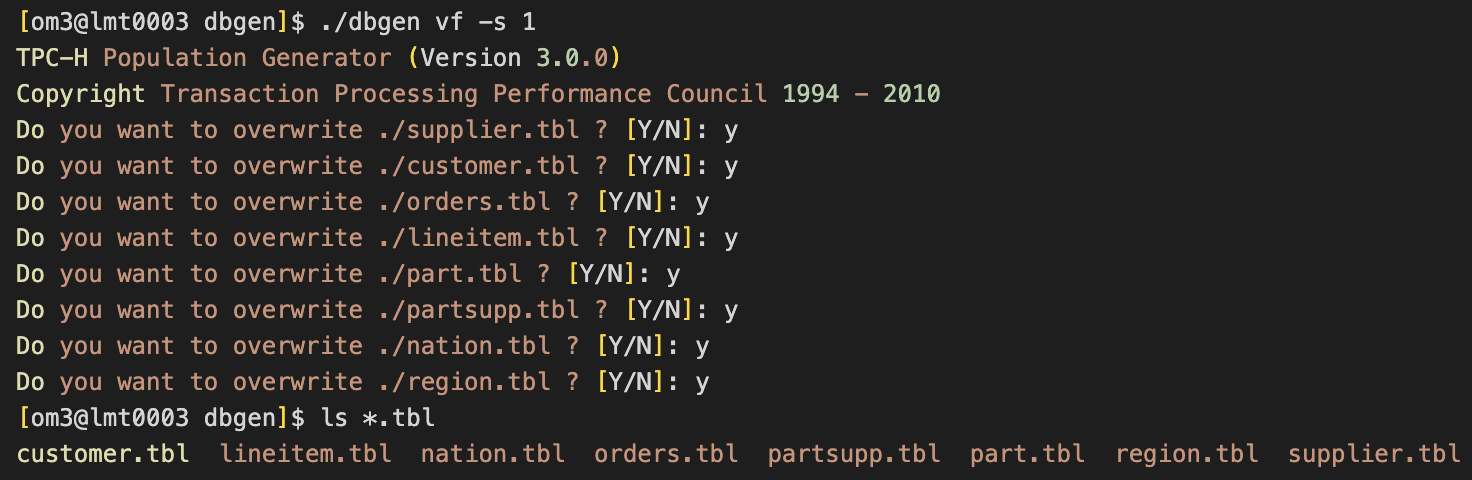
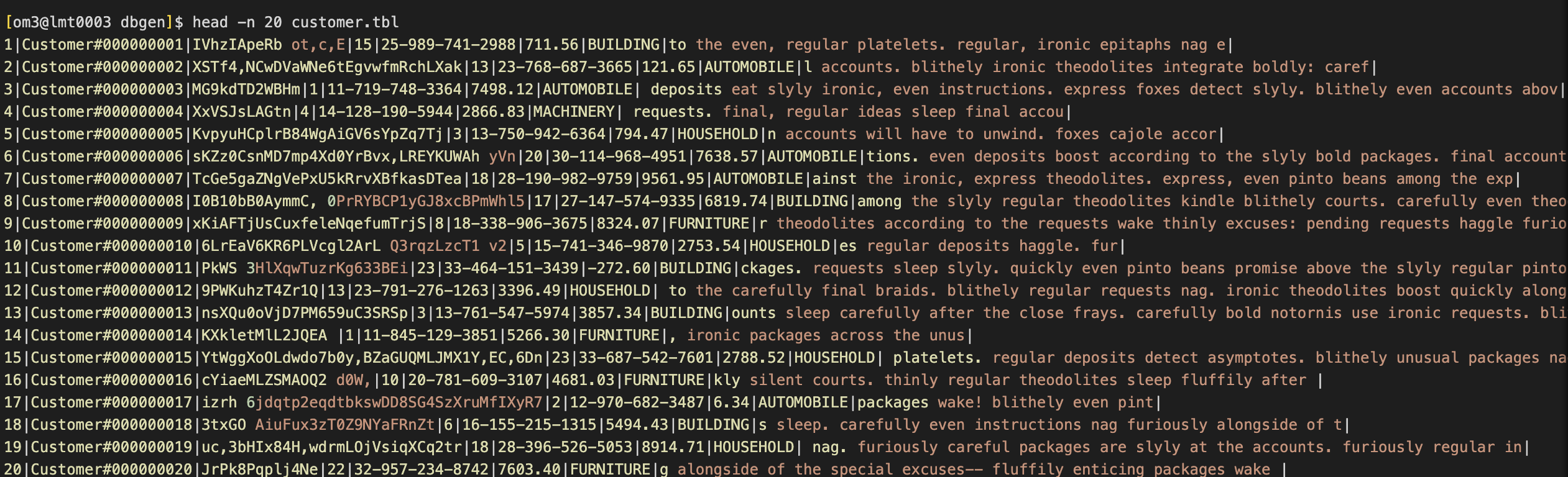
生成8个tbl文件,对应8张表的数据。
也可以使用多个线程产生数据,加块速率。例:8线程生成500G数据
#!/bin/sh
./dbgen -vf -s 500 -S 1 -C 8 &
./dbgen -vf -s 500 -S 2 -C 8 &
./dbgen -vf -s 500 -S 3 -C 8 &
./dbgen -vf -s 500 -S 4 -C 8 &
./dbgen -vf -s 500 -S 5 -C 8 &
./dbgen -vf -s 500 -S 6 -C 8 &
./dbgen -vf -s 500 -S 7 -C 8 &
./dbgen -vf -s 500 -S 8 -C 8 &
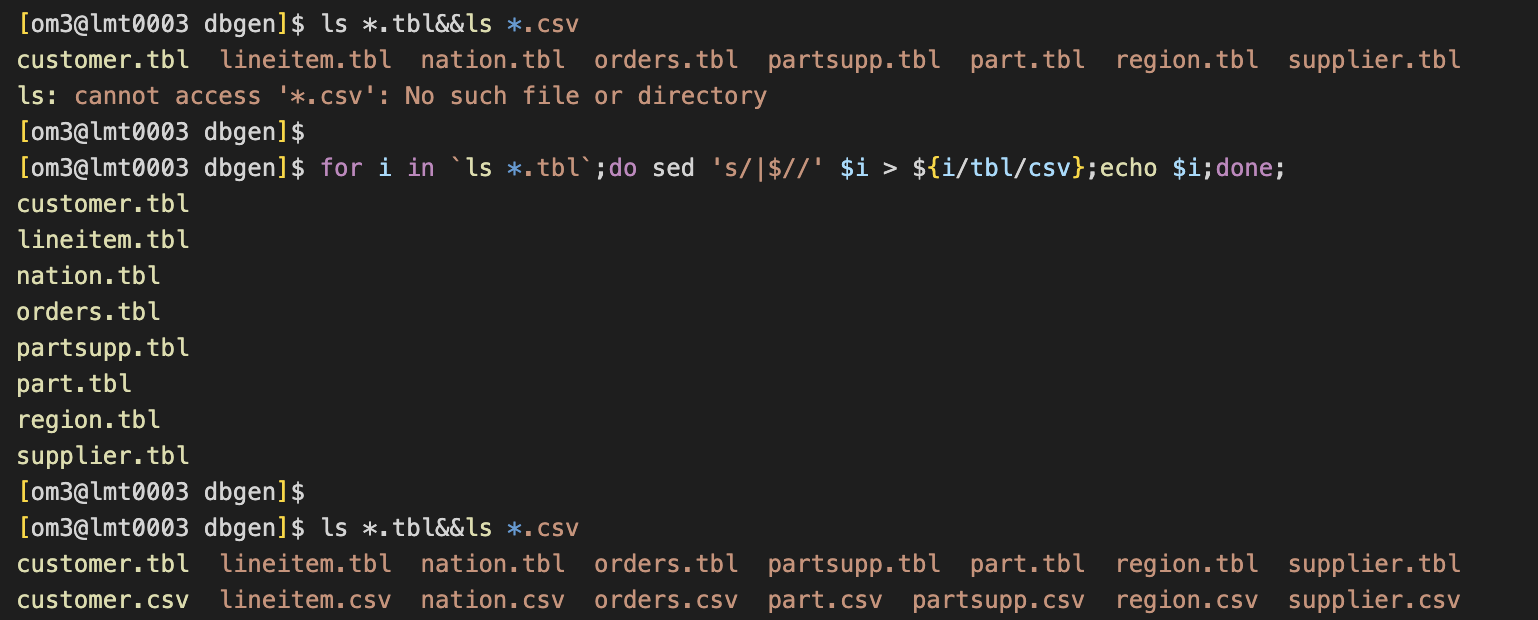
2.转换数据(把tbl文件转换为csv文件)
for i in `ls *.tbl`;do sed 's/|$//' $i > ${i/tbl/csv};echo $i;done;
五、导入数据
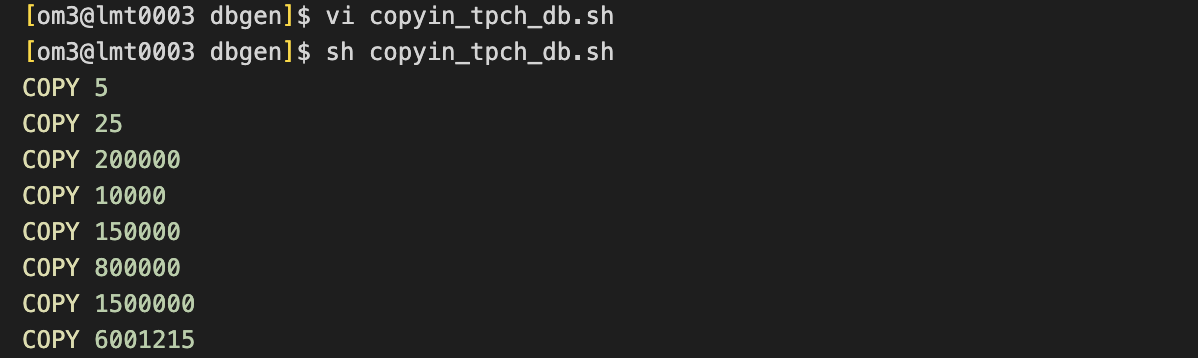
创建脚本,导入数据
[om3@lmt0003 dbgen]$ vi copyin_tpch_db.sh
下面需要修改的部分为dir和opts部分,dir为上述csv的路径。opts是gsql后需要加的参数,包含端口,数据库名等,sch是指定schema。
dir=/home/om3/TPCH-openGauss-TestTools/TPCH-openGauss-TestTools/TPC-H_Tools_v3.0.0/dbgen
opts='-p 23000 -d tpch_db'
sch=public
gsql $opts -c "COPY $sch.region FROM '$dir/region.csv' WITH (FORMAT csv,DELIMITER '|')"
gsql $opts -c "COPY $sch.nation FROM '$dir/nation.csv' WITH (FORMAT csv,DELIMITER '|')"
gsql $opts -c "COPY $sch.part FROM '$dir/part.csv' WITH (FORMAT csv,DELIMITER '|')"
gsql $opts -c "COPY $sch.supplier FROM '$dir/supplier.csv' WITH (FORMAT csv,DELIMITER '|')"
gsql $opts -c "COPY $sch.customer FROM '$dir/customer.csv' WITH (FORMAT csv,DELIMITER '|')"
gsql $opts -c "COPY $sch.partsupp FROM '$dir/partsupp.csv' WITH (FORMAT csv,DELIMITER '|')"
gsql $opts -c "COPY $sch.orders FROM '$dir/orders.csv' WITH (FORMAT csv,DELIMITER '|')"
gsql $opts -c "COPY $sch.lineitem FROM '$dir/lineitem.csv' WITH (FORMAT csv,DELIMITER '|')"
六、创建所需函数
create or replace function NUMTOYMINTERVAL(float8, text) returns interval as $$ select ($1||' '||$2)::interval;
$$ language sql strict immutable;
create or replace function NUMTODSINTERVAL(float8, text) returns interval as $$ select ($1||' '||$2)::interval;
$$ language sql strict immutable;

七、执行SQL文件夹下SQL(共22种SQL)

如下是遍历执行全部22种SQL的脚本
#!/bin/bash
opts='-p 23000 -d tpch_db -U tpch -W 'Abcd@1234''
for i in `seq 1 22`
do
echo $i"'s result"
gsql ${opts} -f ${i}.sql
done
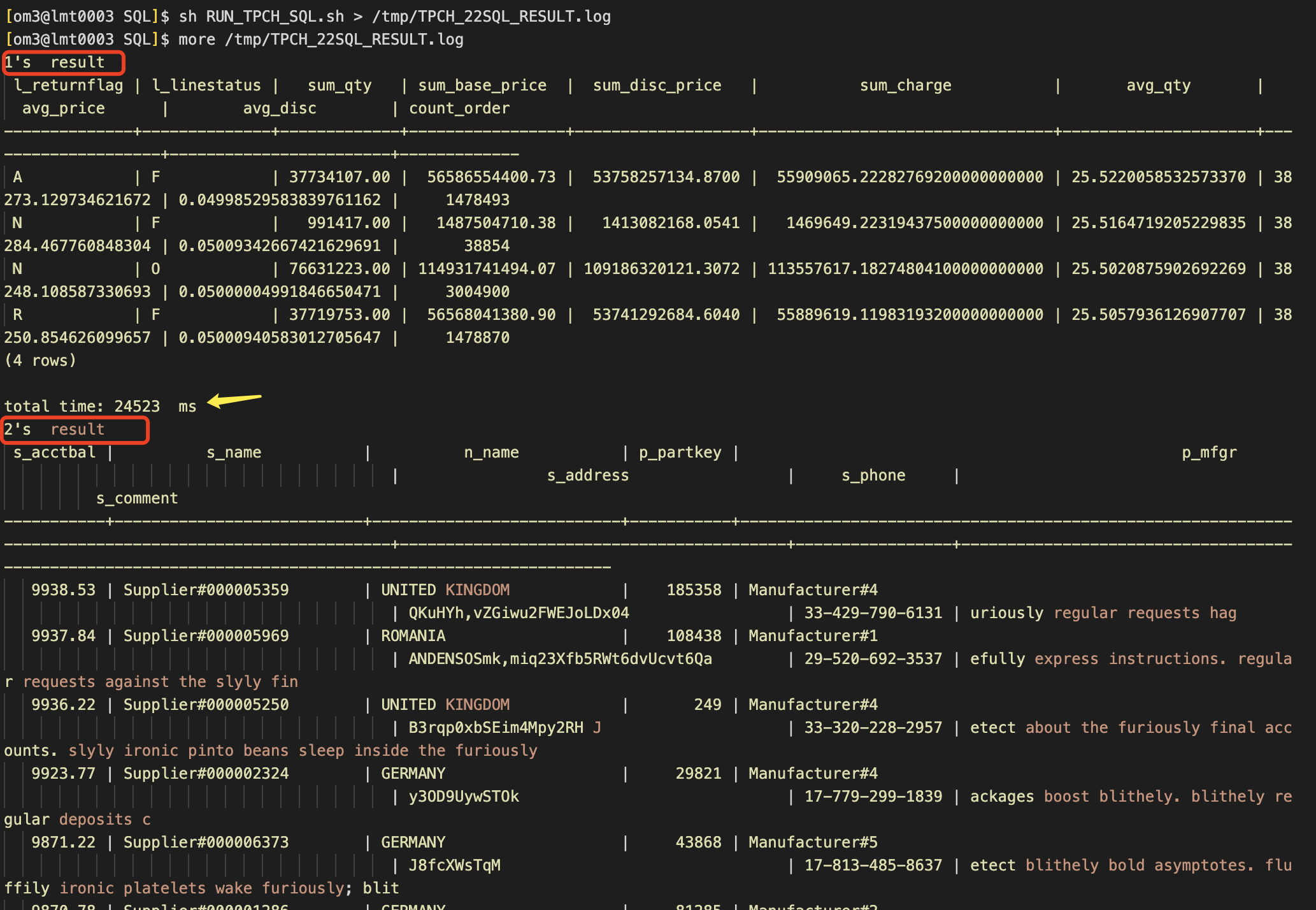
可以将8张表的导入耗时以及22种SQL的执行耗时记录下来,并做相应对比(测表导入耗时可以copy前开启\timing)。