个人博客:Sekyoro的博客小屋
个人网站:Proanimer的个人网站
之前学过一段时间NLP,因为其中涉及到一些深度学习常用的知识或者框架,但苦于不系统以及没有任务focus不能长久.这里借助微软的教程写点东西.
tokenization&&representation
将一句话中的单词分割就是分词(tokenization),英文分词比较简单.中文就比较麻烦了.需要把握分词的粒度.
import torchtext
import torch
tokenizer = torchtext.data.utils.get_tokenizer('basic_english')
tokenizer('He said: hello')
分词之后就需要表示每个分词的含义了,需要某种方式将文本表示为张量.可以分为
- 字符级表示(Character-level representation),当我们通过将每个字符视为一个数字来表示文本时。鉴于我们的文本语料库中有 C (如果是英语也就26个字符)不同的字符,单词 Hello 将由 5xC 张量表示。每个字母将对应于一个独热编码中的张量列。
- 单词级表示(Word-level representation),其中我们创建文本中所有单词的词汇表(vocabulary ),然后使用独热编码表示单词。这种方法在某种程度上更好,因为每个字母本身没有太多意义,因此通过使用更高层次的语义概念 - 单词 - 我们简化了神经网络的任务。但是,鉴于字典大小较大,我们需要处理高维稀疏张量。
无论表示方式如何,我们首先需要将文本转换为一系列标记(tokens),一个标记是字符、单词,有时甚至是单词的一部分(也即是上面说的分词)
然后,我们将token转换为一个数字,通常使用词汇表(vocabulary)(也就是使用单词级表示),并且可以使用独热编码(one-hot encoding)将这个数字输入神经网络。
常用的方法包括BOW或者N-Grams
Bag-of-Words
在解决文本分类等任务时,我们需要能够通过一个固定大小的向量来表示文本,我们将将其用作最终分类器的输入。
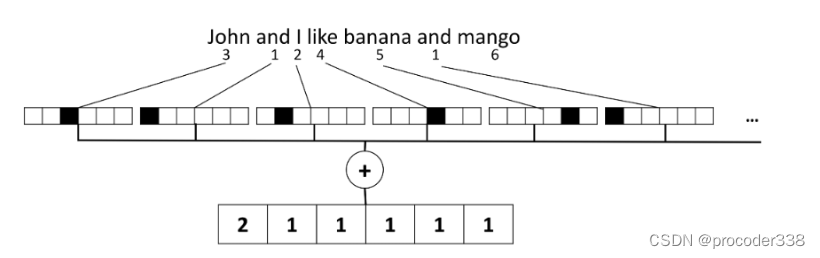
最简单的方法之一是组合所有单独的单词表示,例如。通过添加它们。如果我们为每个单词添加独热编码,我们最终会得到一个频率向量,显示每个单词在文本中出现的次数。文本的这种表示称为词袋(BoW)
BoW 本质上表示文本中出现的单词和数量,这确实可以很好地指示文本的内容
counter = collections.Counter()
for (label, line) in train_dataset:
counter.update(tokenizer(line))
vocab = torchtext.vocab.vocab(counter, min_freq=1)
vocab_size = len(vocab)
print(f"Vocab size if {vocab_size}")
stoi = vocab.get_stoi() # dict to convert tokens to indices
def encode(x):
return [stoi[s] for s in tokenizer(x)]
encode('I love to play with my words')
vocab_size = len(vocab)
def to_bow(text,bow_vocab_size=vocab_size):
res = torch.zeros(bow_vocab_size,dtype=torch.float32)
for i in encode(text):
if i<bow_vocab_size:
res[i] += 1
return res
print(to_bow(train_dataset[0][1]))
简单来说就是根据原本的语义资料,统计词频先建立一个counter,类似于一个字典,key是词,value是频次.根据counter(或者OrderDict)建立一个vocab. vocab建立一个词汇到index的一个字典,然后根据这个字典获得一个词的index,但是并直接使用index作为词的表示,而是使用类似one-hot encoding,出现了一个词,获取其index,再在一个大小为vocab_size的tensor上的index处加1,这样一个句子的BOW就有了.

BoW 的问题在于某些常用词,例如 and、is 等出现在大多数文本中,并且它们的频率最高,掩盖了真正重要的单词。我们可以通过考虑单词在整个文档集合中出现的频率来降低这些单词的重要性。
N-Grams
在自然语言中,单词的精确含义只能在上下文中确定。例如,神经网和钓鱼网.
一种解决办法是使用单词对(pairs of words)(也就是不使用单个单词而是多个单词,因为单个单词在不同语境下含义由差异),然后将单词对(pairs of words)视为单独的词汇标记。
这样相当于把一个句子的表示变多了,除了所有单个单词,还有单词对.
这种方法的问题在于字典大小显着增长,并且像go fishing和go shopping这样的组合由不同的标记呈现,尽管动词相同,但它们没有任何语义相似性。
在某些情况下,我们也可以考虑使用三元语法 - 三个单词的组合。因此,这种方法通常被称为n-grams。此外,使用具有字符级表示的 n 元语法是有意义的,在这种情况下,n-gram 将大致对应于不同的音节。
可以使用sklearn或者pytorch库,均能实现.
bigram_vectorizer = CountVectorizer(ngram_range=(1, 2), token_pattern=r'\b\w+\b', min_df=1)
corpus = [
'I like hot dogs.',
'The dog ran fast.',
'Its hot outside.',
]
bigram_vectorizer.fit_transform(corpus)
print("Vocabulary:\n",bigram_vectorizer.vocabulary_)
print(len(bigram_vectorizer.vocabulary_))
bigram_vectorizer.transform(['My dog likes hot dogs on a hot day.']).toarray()

counter = collections.Counter()
for (label, line) in train_dataset:
l = tokenizer(line)
counter.update(torchtext.data.utils.ngrams_iterator(l,ngrams=2))
bi_vocab = torchtext.vocab.vocab(counter, min_freq=1)
print("Bigram vocabulary length = ",len(bi_vocab))

TF-IDF
在 BoW 表示中,无论单词本身如何,单词出现次数都是均匀加权的。但是,很明显,与专业术语相比,常用词(例如a,in等)对于分类的重要性要低得多。事实上,在大多数NLP任务中,有些单词比其他单词更相关。
TF-IDF 代表术语频率 – 反向文档频率。它是BOW的变体,其中使用浮点值而不是指示单词在文档中出现的二进制 0/1 值,这与语料库中单词出现的频率有关。
主要引入了document文档概念,如果一个词在多个文档中出现,那么其权重会降低.
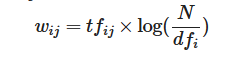
其中tfij表示在j文档中i词出现的次数,N表示总文档数,dfi表示出现i这个词的文档数.
这样就计算出了单个文档中词i的权重,这里的文档也可以是单个句子.
from sklearn.feature_extraction.text import TfidfVectorizer
corpus = [
'I like hot dogs.',
'The dog ran fast.',
'Its hot outside.',
]
vectorizer = TfidfVectorizer(ngram_range=(1,2))
vectorizer.fit_transform(corpus)
vectorizer.transform(['My dog likes hot dogs on a hot day.']).toarray()
这里结合了N-gram和TF-IDF. 由于其中使用了TfidfVectorizer,默认参数如下

将其中的I,I like去掉了,所以词汇表少了两个.此外sklearn库中的算法与上面的公式也不同.默认为log [ n / df(t) ] + 1(设置smooth_idf=False)
上面的方法对于句子中词的语义理解能力有限,而且通常维度是整个训练资料的vocab大小,维度高且稀疏.
Embedding
嵌入的想法是通过低维密集向量来表示单词,这在某种程度上反映了单词的语义含义。
也就是从上面简单的text representation中的vocab_size变为embedding_size,输出不是one hot encoding的高维向量了。
训练方式与BOW类似,但是需要填充.比如一个batch中有多个句子,每个句子长度不同,需要padding成这个batch中最大的句子的encode(就是计算BOW)长度.
class EmbedClassifier(torch.nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super().__init__()
self.embedding = torch.nn.Embedding(vocab_size, embed_dim)
self.fc = torch.nn.Linear(embed_dim, num_class)
def forward(self, x):
x = self.embedding(x)
print("after embedding",x.shape)
x = torch.mean(x,dim=1)
print(x.shape)
return self.fc(x)
def padify(b):
# b is the list of tuples of length batch_size
# - first element of a tuple = label,
# - second = feature (text sequence)
# build vectorized sequence
v = [encode(x[1]) for x in b]
# first, compute max length of a sequence in this minibatch
l = max(map(len,v))
return ( # tuple of two tensors - labels and features
torch.LongTensor([t[0]-1 for t in b]),
torch.stack([torch.nn.functional.pad(torch.tensor(t),(0,l-len(t)),mode='constant',value=0) for t in v])
)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, collate_fn=padify, shuffle=True)
需要将所有序列填充到相同的长度,以便将它们放入小批量中。这不是表示可变长度序列的最有效方法.
另一种选择是使用偏移向量,这将保留存储在一个大向量中的所有序列的偏移量。
class EmbedClassifier(torch.nn.Module):
def __init__(self, vocab_size, embed_dim, num_class):
super().__init__()
self.embedding = torch.nn.EmbeddingBag(vocab_size, embed_dim)
self.fc = torch.nn.Linear(embed_dim, num_class)
def forward(self, text, off):
x = self.embedding(text, off) //它以内容向量和偏移向量为输入
return self.fc(x)
def offsetify(b):
# first, compute data tensor from all sequences
x = [torch.tensor(encode(t[1])) for t in b]
# now, compute the offsets by accumulating the tensor of sequence lengths
o = [0] + [len(t) for t in x]
o = torch.tensor(o[:-1]).cumsum(dim=0)
return (
torch.LongTensor([t[0]-1 for t in b]), # labels
torch.cat(x), # text
o
)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, collate_fn=offsetify, shuffle=True)
可以看到数据集多了一个数据,
net = EmbedClassifier(vocab_size,32,len(classes)).to(device)
def train_epoch_emb(net,dataloader,lr=0.01,optimizer=None,loss_fn = torch.nn.CrossEntropyLoss(),epoch_size=None, report_freq=200):
optimizer = optimizer or torch.optim.Adam(net.parameters(),lr=lr)
loss_fn = loss_fn.to(device)
net.train()
total_loss,acc,count,i = 0,0,0,0
for labels,text,off in dataloader:
optimizer.zero_grad()
labels,text,off = labels.to(device), text.to(device), off.to(device)
out = net(text, off)
loss = loss_fn(out,labels) #cross_entropy(out,labels)
loss.backward()
optimizer.step()
total_loss+=loss
_,predicted = torch.max(out,1)
acc+=(predicted==labels).sum()
count+=len(labels)
i+=1
if i%report_freq==0:
print(f"{count}: acc={acc.item()/count}")
if epoch_size and count>epoch_size:
break
return total_loss.item()/count, acc.item()/count
train_epoch_emb(net,train_loader, lr=4, epoch_size=25000)
在前面的示例中,模型嵌入层学习将单词映射到向量表示,但是这种表示没有太多的语义意义。应该学到的是:相似的单词或同义词将对应于在某些向量距离(例如欧几里得距离)方面彼此接近的向量
Word2Vec
为此,我们需要以特定方式在大量文本上预训练我们的嵌入模型。
训练语义嵌入的第一种方法称为Word2Vec。它基于两个主要体系结构,用于生成单词的分布式表示,包括COW和Skip-Ngram.
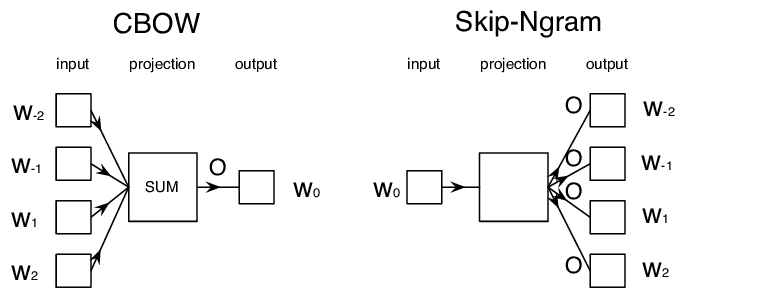
在CBOW,我们训练模型从周围上下文中预测单词。给定 ngram (W−2,W−1,W0,W1,W2),模型的目标是从 (W−2,W−1,W1,W2) 预测 W0。
FastText
通过学习每个单词的向量表示以及每个单词中的字符 n 元语法来构建 Word2Vec。然后在每个训练步骤中将表示值平均为一个向量。虽然这为预训练增加了大量额外的计算,但它使词嵌入能够对子词信息进行编码。
GloVe
GloVe利用分解共现矩阵( co-occurrence matrix)的思想,使用神经方法将共现矩阵分解为更具表现力和非线性的词向量。

传统的预训练嵌入表示(如 Word2Vec)的一个关键限制是词义消歧问题。虽然预训练嵌入可以在上下文中捕获单词的某些含义,但单词的每个可能含义都编码到相同的嵌入中。这可能会导致下游模型中出现问题,因为许多单词(例如“play”)具有不同的含义,具体取决于它们使用的上下文。
为了克服这个限制,我们需要基于语言模型构建嵌入,该语言模型在大量文本语料库上进行训练,并且知道如何在不同上下文中将单词组合在一起(我的理解是相当于自己训练一个专注于自己下游任务的embedding)
Language Modeling
语言建模背后的主要思想是以无监督的方式在未标记的数据集上训练它们。这很重要,因为我们有大量的未标记文本可用,而标记文本的数量始终受到我们可以在标记上花费的工作量的限制。
大多数情况下,我们可以构建可以预测文本中缺失单词的语言模型,因为很容易屏蔽文本中的随机单词并将其用作训练样本.
为了建立一个网络来预测下一个单词,我们需要提供相邻单词作为输入,并获取单词编号作为输出。
CBoW网络的架构如下:
输入单词通过嵌入层传递。这个嵌入层将是我们的 Word2Vec 嵌入,因此我们将它单独定义为嵌入变量。在这个例子中,我们将使用嵌入大小 = 30,即使你可能想尝试更高的维度(真正的 word2vec 有 300)
然后,嵌入向量将被传递到预测输出字的线性层。因此它具有vocab_size神经
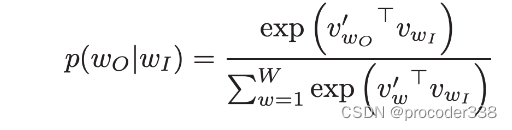
def load_dataset(ngrams = 1, min_freq = 1, vocab_size = 5000 , lines_cnt = 500):
tokenizer = torchtext.data.utils.get_tokenizer('basic_english')
print("Loading dataset...")
test_dataset, train_dataset = torchtext.datasets.AG_NEWS(root='./data')
train_dataset = list(train_dataset)
test_dataset = list(test_dataset)
classes = ['World', 'Sports', 'Business', 'Sci/Tech']
print('Building vocab...')
counter = collections.Counter()
for i, (_, line) in enumerate(train_dataset):
counter.update(torchtext.data.utils.ngrams_iterator(tokenizer(line),ngrams=ngrams))
if i == lines_cnt:
break
vocab = torchtext.vocab.Vocab(collections.Counter(dict(counter.most_common(vocab_size))))
return train_dataset, test_dataset, classes, vocab, tokenizer
def encode(x, vocabulary, tokenizer = tokenizer):
return [vocabulary[s] for s in tokenizer(x)]
def to_cbow(sent,window_size=2):
res = []
for i,x in enumerate(sent):
for j in range(max(0,i-window_size),min(i+window_size+1,len(sent))):
if i!=j:
res.append([sent[j],x])
return res
print(to_cbow(['I','like','to','train','networks']))
print(to_cbow(encode('I like to train networks', vocab)))
在设计数据集的时候,得到的就是例如[2,3],[4,3],其中3是预测的词,2,4是其周围的词,这样也不需要padding了.
class SimpleIterableDataset(torch.utils.data.IterableDataset):
def __init__(self, X, Y):
super(SimpleIterableDataset).__init__()
self.data = []
for i in range(len(X)):
self.data.append( (Y[i], X[i]) )
random.shuffle(self.data)
def __iter__(self):
return iter(self.data)
ds = SimpleIterableDataset(X, Y)
dl = torch.utils.data.DataLoader(ds, batch_size = 256)
def train_epoch(net, dataloader, lr = 0.01, optimizer = None, loss_fn = torch.nn.CrossEntropyLoss(), epochs = None, report_freq = 1):
optimizer = optimizer or torch.optim.Adam(net.parameters(), lr = lr)
loss_fn = loss_fn.to(device)
net.train()
for i in range(epochs):
total_loss, j = 0, 0,
for labels, features in dataloader:
optimizer.zero_grad()
features, labels = features.to(device), labels.to(device)
out = net(features)
loss = loss_fn(out, labels)
loss.backward()
optimizer.step()
total_loss += loss
j += 1
if i % report_freq == 0:
print(f"Epoch: {i+1}: loss={total_loss.item()/j}")
return total_loss.item()/j

关键是生成了一堆数据,句子中的某个单词由周围N个单词生成(CBOW).模型是简单的embedding层加一个全连接,输出特征大小是vocab_size,用softmax损失,最后就能无监督训练得到一个embedding层.
RNN(Recurrent Neural Networks)
之前直接使用的是全连接层,这种架构的作用是捕获句子中单词的聚合含义,但它没有考虑单词的顺序,因为嵌入之上的聚合操作从原始文本中删除了此信息。由于这些模型无法对单词排序进行建模,因此它们无法解决更复杂或模糊的任务,例如文本生成或问答。
给定标记 X0,…,Xn 的输入序列,RNN 创建一个神经网络块序列,并使用反向传播端到端地训练该序列。每个网络块将一对(Xi,Si)作为输入,并产生Si+1。最终状态 Sn 或(输出 Yn)进入线性分类器以产生结果。所有网络块共享相同的权重,并使用一个反向传播通道进行端到端训练。
为了捕捉文本序列的含义,我们需要使用另一种神经网络架构,称为递归神经网络或RNN。在 RNN 中,我们通过网络一次传递一个符号,网络产生一些状态,然后我们用下一个符号再次传递给网络。
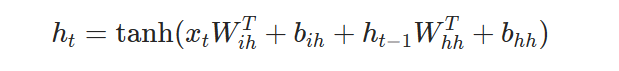
pytorch中普通RNN隐状态通过了tanh激活,每一层的隐状态与输出是一样.
RNN循环网络是每次拿每个batch中的一个sequence中的一个,大小是embed_size(或者直接是one-hot编码的vacab_size,同时可以输入一个初始状态,shape是hidden_size,然后两个矩阵分别是(embed_size,hidden_size),(hidden_size,hidden_size),其实就是连个全连接然后直接concat通过激活函数,这就是简单的RNN,),

对于一个句子的数据,X是(seq_length,embedding_size),权重W是(embedding_size,hidden_dim),H是(hidden_dim,hidden_dim),S是(seq_length,hidden_dim),S是上一层的输出,也就是W×Xi+H×Si-1+b.
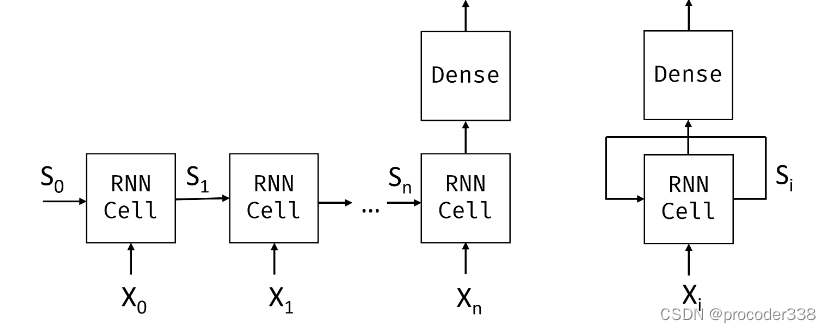
由于状态向量 S0,…,Sn 通过网络传递,因此它能够学习单词之间的顺序依赖关系。例如,当单词没有出现在序列中的某个地方时,它可以学习否定状态向量中的某些元素,从而导致否定.
RNN内部结构
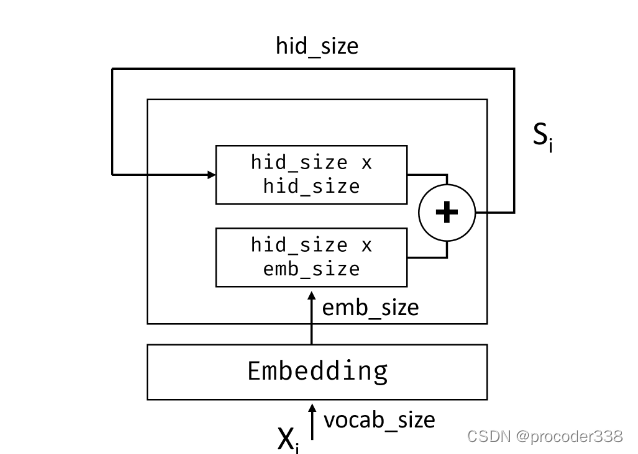
简单的RNN接受先前的状态 Si-1和当前符号 Xi作为输入,并且必须产生输出状态 Si(有时,我们也对其他一些输出 Yi 感兴趣,例如生成网络的情况)
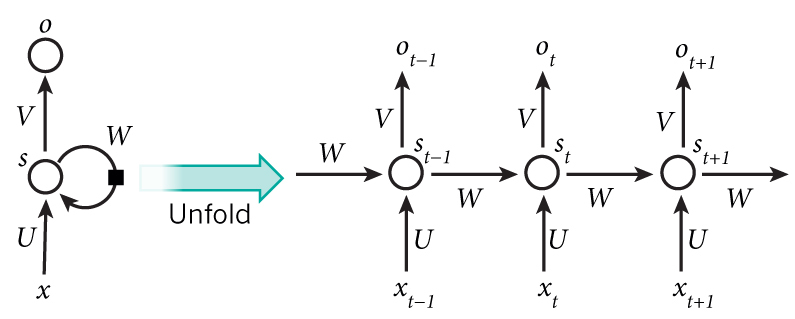
注意,上面的seq_length是输入的长度,但并不是每一句的长度,因为每一句长度很可能不一样,这样RNN无法计算,是一个batch中vocab最大的长度,也就是在一个batch中padding到最大长度
def padify(b,voc=None,tokenizer=tokenizer):
# b is the list of tuples of length batch_size
# - first element of a tuple = label,
# - second = feature (text sequence)
# build vectorized sequence
v = [encode(x[1],voc=voc,tokenizer=tokenizer) for x in b]
# compute max length of a sequence in this minibatch
l = max(map(len,v))
return ( # tuple of two tensors - labels and features
torch.LongTensor([t[0]-1 for t in b]),
torch.stack([torch.nn.functional.pad(torch.tensor(t),(0,l-len(t)),mode='constant',value=0) for t in v])
)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, collate_fn=padify, shuffle=True)
在许多情况下,输入token在进入 RNN 之前通过嵌入层以降低维度。每一层输出是σ(W×Xi+H×Si-1+b)
import torch
import torch.nn as nn
input_size = 100 # 输入数据编码的维度
hidden_size = 20 # 隐含层维度
num_layers = 4 # 隐含层层数
rnn = nn.RNN(input_size=input_size,hidden_size=hidden_size,num_layers=num_layers)
print("rnn:",rnn)
seq_len = 10 # 句子长度
batch_size = 1
x = torch.randn(seq_len,batch_size,input_size) # 输入数据
h0 = torch.zeros(num_layers,batch_size,hidden_size) # 输入数据
out, h = rnn(x, h0) # 输出数据
print("out.shape:",out.shape)
print("h.shape:",h.shape)
注意,pytorch RNN默认输入数据是(seq_length,batch_size,embedding_size),除非设置batch_first=True
LSTM&&GRU
class LSTMClassifier(torch.nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_class):
super().__init__()
self.hidden_dim = hidden_dim
self.embedding = torch.nn.Embedding(vocab_size, embed_dim)
self.embedding.weight.data = torch.randn_like(self.embedding.weight.data)-0.5
self.rnn = torch.nn.LSTM(embed_dim,hidden_dim,batch_first=True)
self.fc = torch.nn.Linear(hidden_dim, num_class)
def forward(self, x):
batch_size = x.size(0)
x = self.embedding(x)
x,(h,c) = self.rnn(x)
return self.fc(h[-1])
net = LSTMClassifier(vocab_size,64,32,len(classes)).to(device)
train_epoch(net,train_loader, lr=0.001)
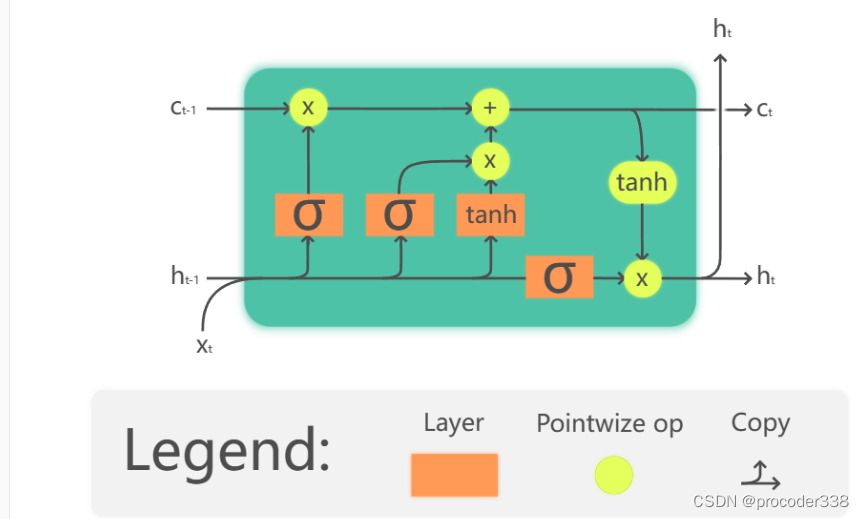
LSTM增加了三个门用来控制隐状态,输入.
- 忘记门采用隐藏的向量并确定我们需要忘记向量 c 的哪些分量,以及要通过哪些分量。
- 输入门从输入和隐藏向量中获取一些信息,并将其插入状态。
- 输出门通过具有tanh激活的某个线性层转换状态,然后使用隐藏向量Hi选择其部分组件以产生新的状态ci+1。
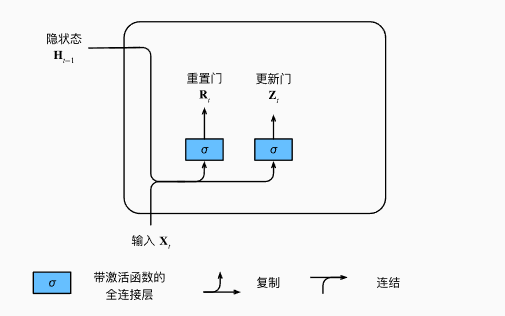
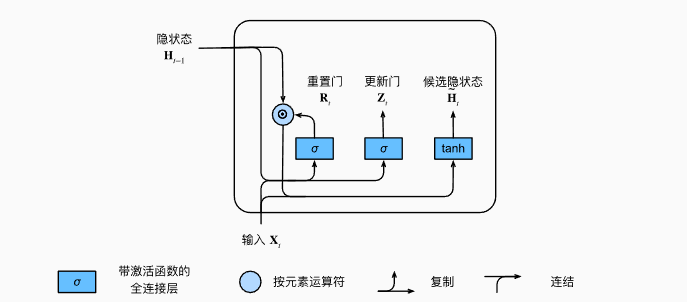
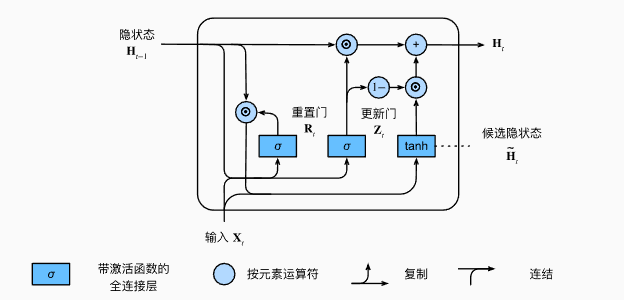
而GRU结构要简单一些,支持隐状态的门控. 重置门允许我们控制“可能还想记住”的过去状态的数量, 更新门将允许我们控制新状态中有多少个是旧状态的副本。
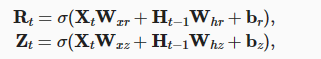
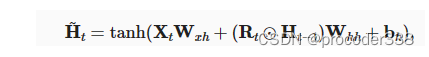
PACKED SEQUENCE
填充一批可变长度序列
我们必须用零向量填充小批量中的所有序列。虽然这会导致一些内存浪费,但对于 RNN,为填充的输入项创建额外的 RNN 单元更为重要,这些输入项参与训练,但不携带任何重要的输入信息。仅将 RNN 训练到实际序列大小会好得多。
from torch.nn.utils.rnn import pack_padded_sequence, pad_packed_sequence
seq = torch.tensor([[1, 2, 0], [3, 0, 0], [4, 5, 6]])
lens = [2, 1, 3]
packed = pack_padded_sequence(seq, lens, batch_first=True, enforce_sorted=False)
packed
seq_unpacked, lens_unpacked = pad_packed_sequence(packed, batch_first=True)
seq_unpacked
lens_unpacked
def pad_length(b):
# build vectorized sequence
v = [encode(x[1]) for x in b]
# compute max length of a sequence in this minibatch and length sequence itself
len_seq = list(map(len,v))
l = max(len_seq)
return ( # tuple of three tensors - labels, padded features, length sequence
torch.LongTensor([t[0]-1 for t in b]),
torch.stack([torch.nn.functional.pad(torch.tensor(t),(0,l-len(t)),mode='constant',value=0) for t in v]),
torch.tensor(len_seq)
)
train_loader_len = torch.utils.data.DataLoader(train_dataset, batch_size=16, collate_fn=pad_length, shuffle=True)
class LSTMPackClassifier(torch.nn.Module):
def __init__(self, vocab_size, embed_dim, hidden_dim, num_class):
super().__init__()
self.hidden_dim = hidden_dim
self.embedding = torch.nn.Embedding(vocab_size, embed_dim)
self.embedding.weight.data = torch.randn_like(self.embedding.weight.data)-0.5
self.rnn = torch.nn.LSTM(embed_dim,hidden_dim,batch_first=True)
self.fc = torch.nn.Linear(hidden_dim, num_class)
def forward(self, x, lengths):
batch_size = x.size(0)
x = self.embedding(x)
pad_x = torch.nn.utils.rnn.pack_padded_sequence(x,lengths,batch_first=True,enforce_sorted=False)
pad_x,(h,c) = self.rnn(pad_x)
x, _ = torch.nn.utils.rnn.pad_packed_sequence(pad_x,batch_first=True)
return self.fc(h[-1])
net = LSTMPackClassifier(vocab_size,64,32,len(classes)).to(device)
train_epoch_emb(net,train_loader_len, lr=0.001,use_pack_sequence=True)
要生成打包序列,我们可以使用torch.nn.utils.rnn.pack_padded_sequence函数。所有循环层,包括RNN,LSTM和GRU,都支持打包序列作为输入,并产生可以使用torch.nn.utils.rnn.pad_packed_sequence解码打包输出。
训练时,传入len_seq = list(map(len,v)),使用torch.nn.utils.rnn.pack_padded_sequence
pad_x = torch.nn.utils.rnn.pack_padded_sequence(x,lengths,batch_first=True,enforce_sorted=False)
pad_x,(h,c) = self.rnn(pad_x)
再使用
x, _ = torch.nn.utils.rnn.pad_packed_sequence(pad_x,batch_first=True)
可以解码打包的输出
def train_epoch_emb(net,dataloader,lr=0.01,optimizer=None,loss_fn = torch.nn.CrossEntropyLoss(),epoch_size=None, report_freq=200,use_pack_sequence=False):
optimizer = optimizer or torch.optim.Adam(net.parameters(),lr=lr)
loss_fn = loss_fn.to(device)
net.train()
total_loss,acc,count,i = 0,0,0,0
for labels,text,off in dataloader:
optimizer.zero_grad()
labels,text = labels.to(device), text.to(device)
if use_pack_sequence:
off = off.to('cpu')
else:
off = off.to(device)
out = net(text, off)
loss = loss_fn(out,labels) #cross_entropy(out,labels)
loss.backward()
optimizer.step()
total_loss+=loss
_,predicted = torch.max(out,1)
acc+=(predicted==labels).sum()
count+=len(labels)
i+=1
if i%report_freq==0:
print(f"{count}: acc={acc.item()/count}")
if epoch_size and count>epoch_size:
break
return total_loss.item()/count, acc.item()/count
目前,pack_padded_sequence函数要求长度序列张量位于CPU设备上,因此训练函数在训练时需要避免将长度序列数据移动到GPU。
if use_pack_sequence:
off = off.to('cpu')
else:
off = off.to(device)
Bidirectional and Multilayer RNNs
由于在许多实际情况下,我们可以随机访问输入序列,因此在两个方向上运行循环计算可能是有意义的。这样的网络被称为双向RNN。在处理双向网络时,我们需要两个隐藏状态向量,每个方向一个。
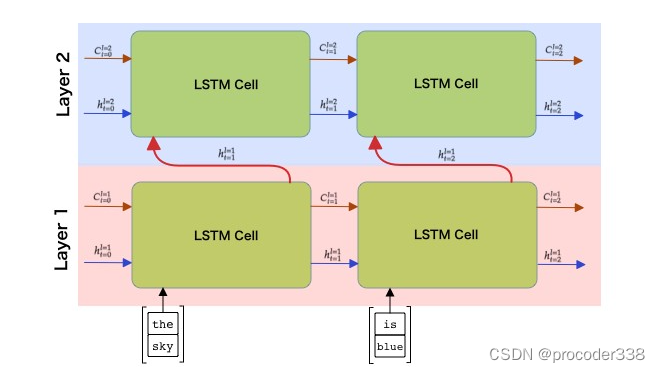
与卷积网络一样,可以在第一层之上构建另一个循环层,以捕获更高级别的模式,并从第一层提取的低级模式进行构建。这导致我们得出多层RNN的概念,它由两个或多个循环网络组成,其中前一层的输出作为输入传递到下一层。
GRN(Generative Recurrent Networks)
递归神经网络(RNN)及其门控细胞变体,如长短期记忆细胞(LSTM)和门控循环单元(GRU)为语言建模提供了一种机制,因为它们可以学习单词顺序并为序列中的下一个单词提供预测。这使我们能够将 RNN 用于生成任务,例如普通文本生成、机器翻译,甚至图像字幕。
每个 RNN 单元产生下一个隐藏状态作为输出。但是,我们也可以为每个循环单元添加另一个输出,这将允许我们输出一个序列(长度等于原始序列)。此外,我们可以使用在每一步都不接受输入的 RNN 单元,只需获取一些初始状态向量,然后生成一系列输出。分别对应多对多与一对多.
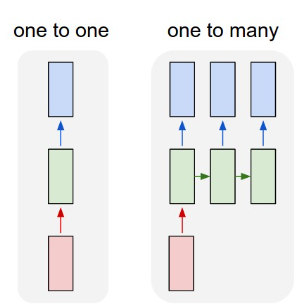
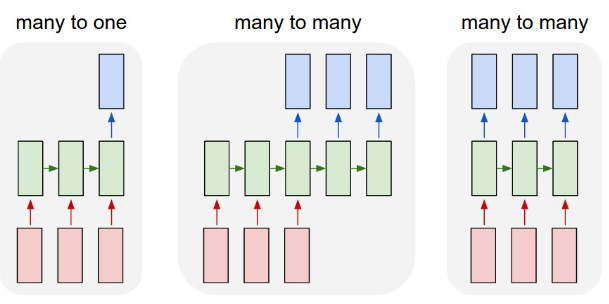
- 一对一是一个输入和一个输出的传统神经网络
- 一对多是一种生成式体系结构,它接受一个输入值,并生成一系列输出值。例如,如果我们想训练一个图像字幕网络来生成图片的文本描述,我们可以将图片作为输入,通过CNN传递以获得其隐藏状态,然后让循环链逐字生成标题。
- 多对一对应于我们在上一个单元中描述的 RNN 架构,例如文本分类
- 多对多或序列到序列对应于机器翻译等任务,其中我们首先让 RNN 将所有信息从输入序列收集到隐藏状态,另一个 RNN 链将此状态展开到输出序列中。
对于生成序列任务而言,在每一步中,我们将获取长度为 nchars 的字符序列,并要求网络为每个输入字符生成下一个输出字符
在生成文本时(在推理过程中),从一些提示开始,该提示通过 RNN 单元格生成其中间状态,然后从该状态开始生成。我们一次生成一个字符,并将状态和生成的字符传递给另一个 RNN 单元以生成下一个,直到我们生成足够的字符。
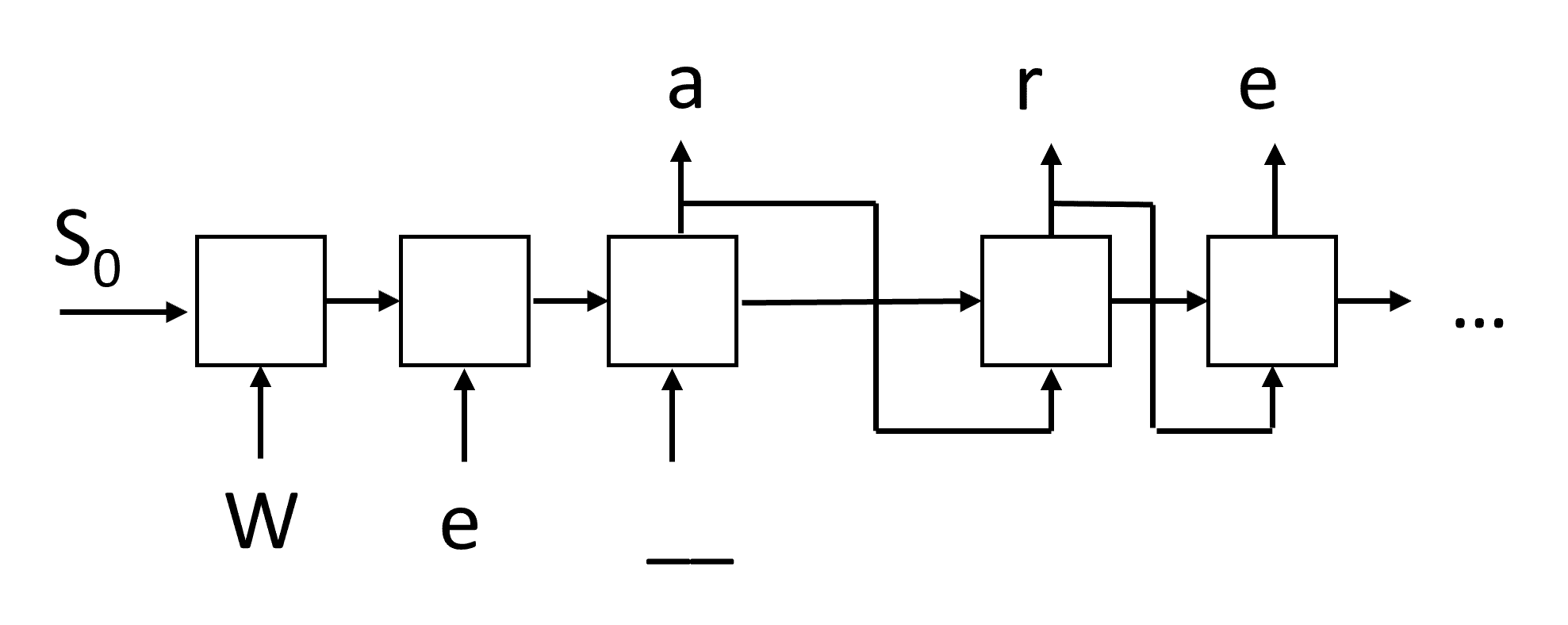
这样需要添加一些特殊字符表明开始与结尾,比如<eos>(在训练数据中添加).
如果只需要无穷的生成字符,只需要固定序列大小,比如为nchars,在l长的序列中就有l-nchars这么多个数据.
def char_tokenizer(words):
return list(words) #[word for word in words]
counter = collections.Counter()
for (label, line) in train_dataset:
counter.update(char_tokenizer(line))
vocab = torchtext.vocab.vocab(counter)
def enc(x):
return torch.LongTensor(encode(x,voc=vocab,tokenizer=char_tokenizer))
def get_batch(s,nchars=nchars):
ins = torch.zeros(len(s)-nchars,nchars,dtype=torch.long,device=device)
outs = torch.zeros(len(s)-nchars,nchars,dtype=torch.long,device=device)
for i in range(len(s)-nchars):
ins[i] = enc(s[i:i+nchars])
outs[i] = enc(s[i+1:i+nchars+1])
return ins,outs # 获得成对的数据 每个数据长度nchars
def generate(net,size=100,start='today '):
chars = list(start)
out, s = net(enc(chars).view(1,-1).to(device))
for i in range(size):
nc = torch.argmax(out[0][-1])
chars.append(vocab.get_itos()[nc])
out, s = net(nc.view(1,-1),s)
return ''.join(chars)
因为网络以字符作为输入,词汇量很小,我们不需要嵌入层,独热编码输入可以直接进入LSTM单元。
但是,由于我们将字符号作为输入传递,因此我们需要在传递给 LSTM 之前对它们进行独热编码。输出编码器将是一个线性层,它将隐藏状态转换为独热编码输出。
class LSTMGenerator(torch.nn.Module):
def __init__(self, vocab_size, hidden_dim):
super().__init__()
self.rnn = torch.nn.LSTM(vocab_size,hidden_dim,batch_first=True)
self.fc = torch.nn.Linear(hidden_dim, vocab_size)
def forward(self, x, s=None):
x = torch.nn.functional.one_hot(x,vocab_size).to(torch.float32)
x,s = self.rnn(x,s)
return self.fc(x),s
在训练期间希望能够对生成的文本进行采样。定义 generate 函数,该函数将从初始字符串开始生成长度大小的输出字符串。
首先将通过传递整个起始字符串,并取出输出状态 s 和下一个预测字符。由于 out 是独热编码的,我们采用 argmax 来获取词汇表中字符 nc 的索引,并使用 itos 找出实际字符并将其附加到生成的字符字符列表中。生成一个字符的过程是重复size次数以生成所需数量的字符。
说人话就是,搭建的模型输出shape是vacab_size(就是RNN或者LSTM的输出),其中最大值的index就是vocab的index.使用交叉熵损失,
net = LSTMGenerator(vocab_size,64).to(device)
samples_to_train = 10000
optimizer = torch.optim.Adam(net.parameters(),0.01)
loss_fn = torch.nn.CrossEntropyLoss()
net.train()
for i,x in enumerate(train_dataset):
# x[0] is class label, x[1] is text
if len(x[1])-nchars<10:
continue
samples_to_train-=1
if not samples_to_train: break
text_in, text_out = get_batch(x[1])
optimizer.zero_grad()
out,s = net(text_in)
loss = torch.nn.functional.cross_entropy(out.view(-1,vocab_size),text_out.flatten()) #cross_entropy(out,labels)
loss.backward()
optimizer.step()
if i%1000==0:
print(f"Current loss = {loss.item()}")
print(generate(net))
可以改进的地方
- 我们准备训练数据的方式是从一个样本生成一个小批量。这并不理想,因为小批量的大小都不同,其中一些甚至无法生成,因为文本小于 nchars。此外,小批量不能充分利用GPU。更明智的做法是从所有样本中获取一大块文本,然后生成所有输入输出对,打乱它们,并生成大小相等的小批量。
- 多层 LSTM。尝试 2 或 3 层 LSTM 单元是有意义的。正如我们在上一个单元中提到的,LSTM 的每一层都从文本中提取某些模式,在字符级生成器的情况下,我们可以期望较低的 LSTM 级别负责提取音节,而较高的级别负责提取单词和单词组合。这可以通过将层数参数传递给 LSTM 构造函数来简单地实现。
soft text generation and temperature
在前面的 generate 定义中,我们始终将概率最高的字符作为生成文本中的下一个字符。这导致文本经常一次又一次地在相同的字符序列之间“循环”(来回就是那那几个字符,类似石头剪刀布,石头经常赢剪刀,剪刀经常赢布)
但是,如果我们看一下下一个字符的概率分布,可能是几个最高概率之间的差异并不大,例如一个字符的概率为 0.2,另一个字符的概率为 0.19,等等。例如,当在序列“play”中查找下一个字符时,下一个字符同样可以是空格或e。
所以选择概率较高的字符并不总是“公平的”,因为选择第二高的字符仍可能使我们获得有意义的文本。从网络输出给出的概率分布中对字符进行采样更为明智。可以使用实现所谓多项式分布的多项式函数( multinomial distribution)进行此采样。实现此软文本生成的函数定义如下:
def generate_soft(net,size=100,start='today ',temperature=1.0):
chars = list(start)
out, s = net(enc(chars).view(1,-1).to(device))
for i in range(size):
#nc = torch.argmax(out[0][-1])
out_dist = out[0][-1].div(temperature).exp()
nc = torch.multinomial(out_dist,1)[0]
chars.append(vocab.get_itos()[nc])
out, s = net(nc.view(1,-1),s)
return ''.join(chars)
for i in [0.3,0.8,1.0,1.3,1.8]:
print(f"--- Temperature = {i}\n{generate_soft(net,size=300,start='Today ',temperature=i)}\n")
引入了一个称为温度的参数,用于指示应该坚持最高概率的力度(温度越低越严格).
如果温度为 1.0,我们进行公平的多项式采样,当温度变为无穷大时.
所有概率都变得相等,我们随机选择下一个字符。当我们过度升高温度时,文本变得毫无意义,当它接近 0 时,它类似于“循环”的硬生成文本。
核心是下面代码
out_dist = out[0][-1].div(temperature).exp()
nc = torch.multinomial(out_dist,1)[0]
chars.append(vocab.get_itos()[nc])
Transformers
NLP领域最重要的问题之一是机器翻译,这是谷歌翻译等工具的基本任务,或者更一般地说,任何序列到序列的任务.
循环网络的一个主要缺点是序列中的所有单词对结果都有相同的影响。这会导致标准 LSTM 编码器-解码器模型在序列到序列任务(如命名实体识别和机器翻译)中性能欠佳。实际上,输入序列中的特定单词通常比其他单词对顺序输出的影响更大。
GRN,LSTM等引入遗忘门,更新门这种机制试图解决长序列遗忘问题,但不能解决不同单词权重的问题
注意力机制提供了一种加权每个输入向量对RNN的每个输出预测的上下文影响的方法。它的实现方式是在输入 RNN 的中间状态和输出 RNN 之间创建快捷方式。
Positional Encoding/Embedding
使用 RNN 时,token的相对位置由步数表示(因为RNN不是并行的,由第一个token开始累积状态),因此不需要显式表示。然而,如果使用注意力层,就需要知道token在序列中的相对位置(因为将整个sequence作为整体).
为了获得位置编码,使用序列中的标记位置序列(即数字序列 0,1 等)与token本身相加.
要将位置(整数)转换为向量,我们可以使用不同的方法:
- 可训练嵌入,类似于token嵌入。这就是我们在这里考虑的方法。我们在标记及其位置之上应用嵌入层,从而产生相同维度的嵌入向量,然后将它们相加。
- 固定位置编码(比如使用一个余弦函数,使用0~len作为输入).
class TokenAndPositionEmbedding(keras.layers.Layer):
def __init__(self, maxlen, vocab_size, embed_dim):
super(TokenAndPositionEmbedding, self).__init__()
self.token_emb = keras.layers.Embedding(input_dim=vocab_size, output_dim=embed_dim)
self.pos_emb = keras.layers.Embedding(input_dim=maxlen, output_dim=embed_dim)
self.maxlen = maxlen
def call(self, x):
maxlen = self.maxlen
positions = tf.range(start=0, limit=maxlen, delta=1)
positions = self.pos_emb(positions)
x = self.token_emb(x)
return x+positions
这里使用两个embedding,分别处理token和position.
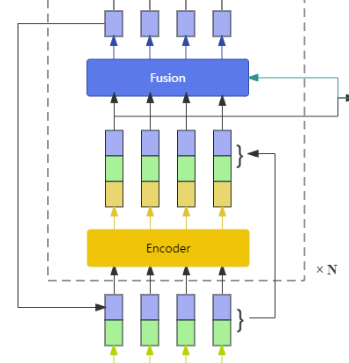
transformer层如图,主要使用了multi-head attn,然后使用了resnet中的思想添加了输入x,也就是x+f(x),normalization使用layernorm,对一个sample中的所有维进行规范化.
class TransformerBlock(keras.layers.Layer):
def __init__(self, embed_dim, num_heads, ff_dim, rate=0.1):
super(TransformerBlock, self).__init__()
self.att = keras.layers.MultiHeadAttention(num_heads=num_heads, key_dim=embed_dim, name='attn')
self.ffn = keras.Sequential(
[keras.layers.Dense(ff_dim, activation="relu"), keras.layers.Dense(embed_dim),]
)
self.layernorm1 = keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = keras.layers.Dropout(rate)
self.dropout2 = keras.layers.Dropout(rate)
def call(self, inputs, training):
attn_output = self.att(inputs, inputs)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(inputs + attn_output)
ffn_output = self.ffn(out1)
ffn_output = self.dropout2(ffn_output, training=training)
return self.layernorm2(out1 + ffn_output)
embed_dim = 32 # Embedding size for each token
num_heads = 2 # Number of attention heads
ff_dim = 32 # Hidden layer size in feed forward network inside transformer
maxlen = 256
vocab_size = 20000
model = keras.models.Sequential([keras.layers.experimental.preprocessing.TextVectorization(max_tokens=vocab_size,output_sequence_length=maxlen, input_shape=(1,)),
TokenAndPositionEmbedding(maxlen, vocab_size, embed_dim),
TransformerBlock(embed_dim, num_heads, ff_dim),
keras.layers.GlobalAveragePooling1D(),
keras.layers.Dropout(0.1),
keras.layers.Dense(20, activation="relu"),
keras.layers.Dropout(0.1),
keras.layers.Dense(4, activation="softmax")
])
model.summary()
print('Training tokenizer')
model.layers[0].adapt(ds_train.map(extract_text))
model.compile(loss='sparse_categorical_crossentropy',metrics=['acc'], optimizer='adam')
model.fit(ds_train.map(tupelize).batch(128),validation_data=ds_test.map(tupelize).batch(128))
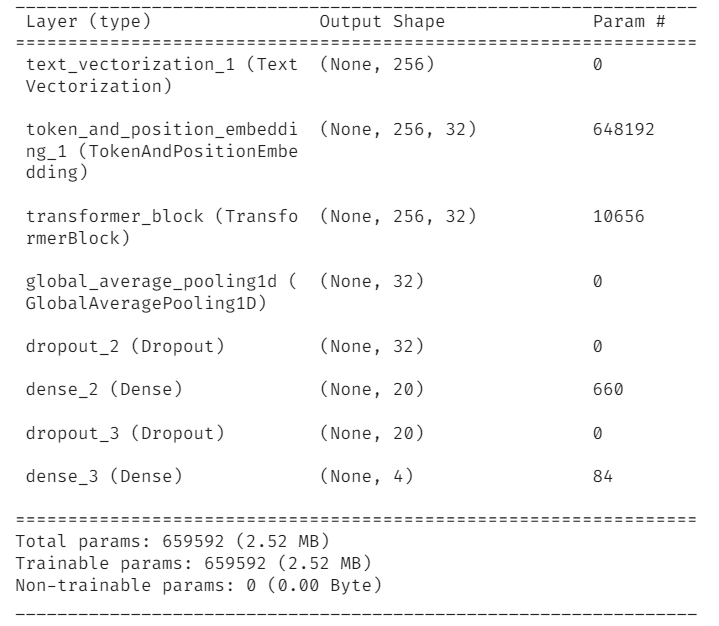
网络结构如上.
可以看看这篇文章注意力,多头注意力,自注意力及Pytorch实现 - 知乎 (zhihu.com)
BERT
BERT是一个非常大的多层transformer网络,其中 12 层用于 BERT 基础,24 层用于 BERT-large。该模型首先使用无监督训练(预测句子中的掩饰词)在大型文本数据语料库(WikiPedia + 书籍)上进行预训练。
在预训练期间,模型吸收了大量语言理解,然后可以通过微调将其与其他数据集一起使用。这个过程称为迁移学习。
Vit
Named Entity Recognition
到目前为止,我们主要关注一项 NLP 任务——分类。然而,还有其他 NLP 任务可以通过神经网络来完成。其中一项任务是命名实体识别 (NER),它处理识别文本中的特定实体,例如地点、人名、日期时间间隔、化学式等。
假设您想开发一个自然语言聊天机器人,类似于 Amazon Alexa 或 Google Assistant。智能聊天机器人的工作方式是通过对输入句子进行文本分类来了解用户想要什么。这种分类的结果就是所谓的意图(intent),它决定了聊天机器人应该做什么。
然而,用户可以提供一些参数作为短语的一部分。例如,当询问天气时,她可能会指定地点或日期。机器人应该能够理解这些实体,并在执行操作之前相应地填充参数槽。这正是 NER 发挥作用的地方。
也就是说,从原本的一句话分类变成对一个单词的分类和理解。
NER 模型本质上是 token 分类模型,因为对于每个输入 token,我们需要决定它是否属于一个实体,如果属于,则属于哪个实体类。
由于 NER 模型本质上是一个 token 分类模型,因此我们可以使用我们已经熟悉的 RNN 来完成此任务。在这种情况下,循环网络的每个块都会返回token ID。
也就是说每个token会给一个tag,这个tag包含这个entity是否是第一个,以及所属得类别.类似下面的tag.
| Token | Tag |
|---|---|
| Tricuspid | B-DIS |
| valve | I-DIS |
| regurgitation | I-DIS |
| and | O |
| lithium | B-CHEM |
| carbonate | I-CHEM |
| toxicity | B-DIS |
| in | O |
| a | O |
| newborn | O |
| infant | O |
| . | O |
Pre-Trained Large Language Models
在我们之前的所有任务中,我们都在使用标记数据集训练神经网络来执行特定任务。对于大型转换器模型,如BERT,我们以自监督的方式使用语言建模来构建语言模型,然后通过进一步的领域特定训练将其专门用于特定的下游任务。
然而,已经证明,大型语言模型也可以在没有任何特定领域训练的情况下解决许多任务。一个能够做到这一点的模型家族被称为GPT: Generative Pre-Trained Transformer。

因为GPT已经根据大量数据进行了训练,以理解语言和代码,所以它们会根据输入(提示)提供输出。提示是GPT输入或查询,用于向模型提供下一次完成任务的指令。为了获得想要的结果,你需要最有效的提示,包括选择正确的单词、格式、短语甚至符号.
如有疑问,欢迎各位交流!
服务器配置
宝塔:宝塔服务器面板,一键全能部署及管理
云服务器:阿里云服务器
Vultr服务器
GPU服务器:Vast.ai