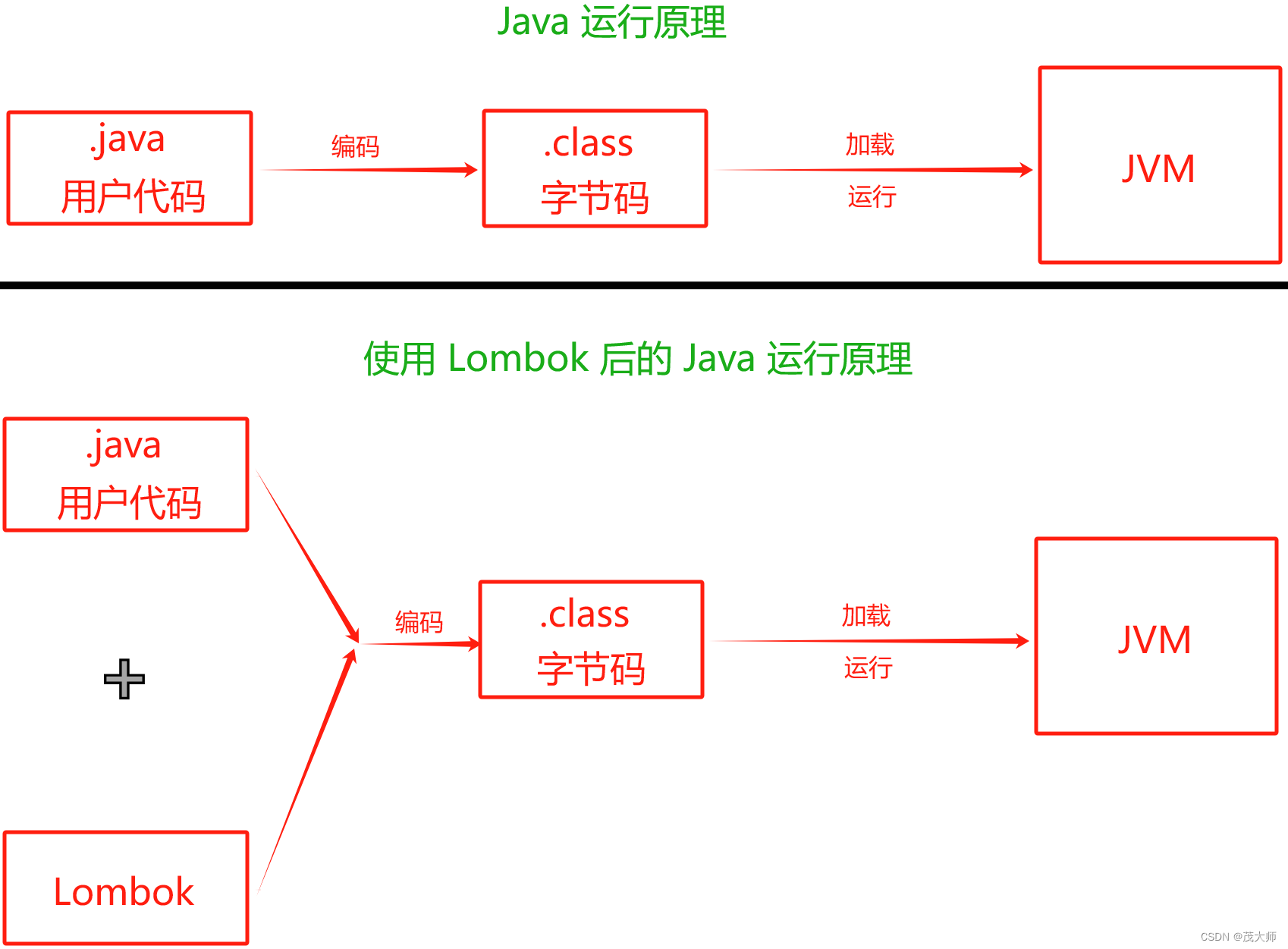
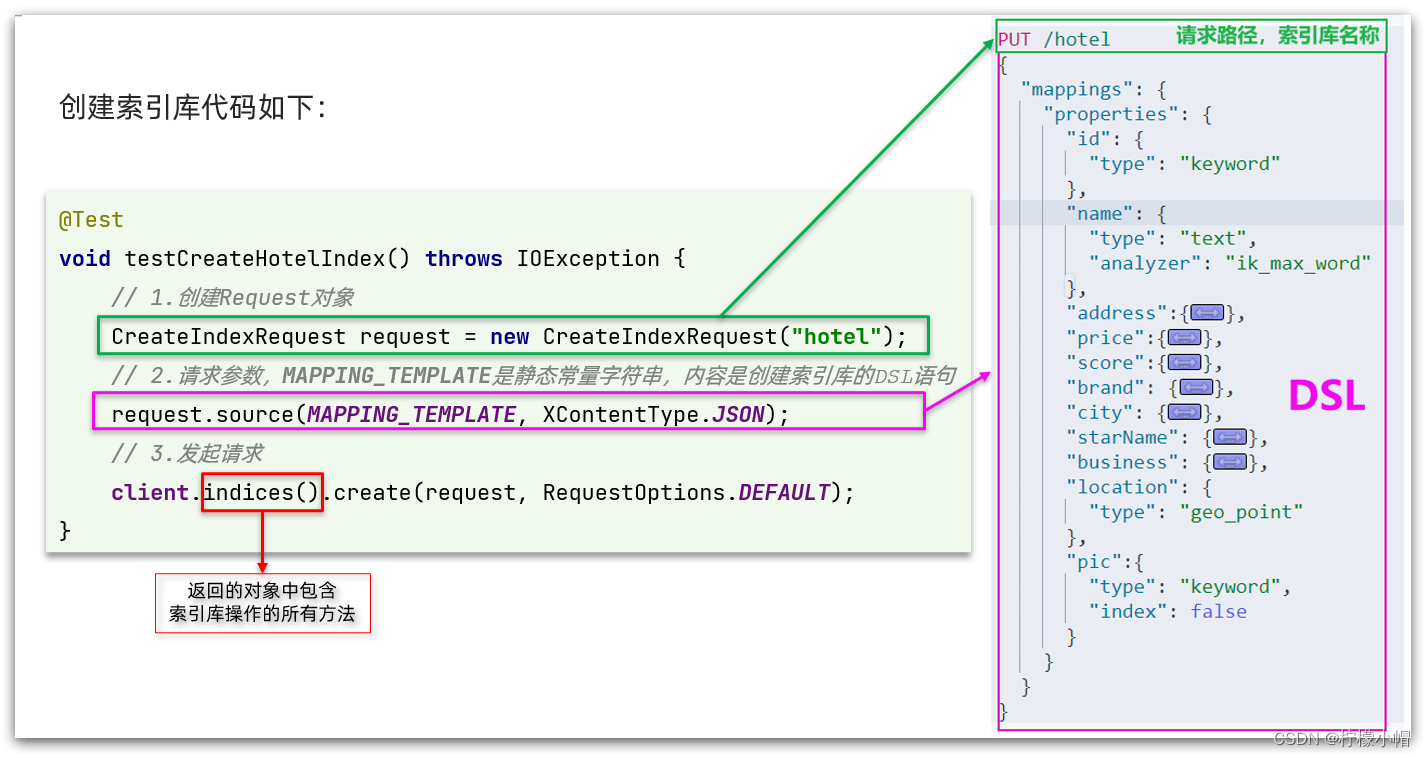
一、介绍
近几年自然语言处理有很大的进展,从 2018 年 Google 推出的 BERT,到后来的 GPT、ChatGPT 等,这些模型当时能取得这样的成果,除了庞大的数据量及损害资源外,最重要的是的就是背后的Transformer模型,以及其使用的Attention Mechanism。
今天这篇文章将分为两个部分,上一篇介绍序列到序列模型遇到的困难,为何要引入 Attentino 以及机制;下一篇则作用在 Transformer 背后的 Scaled Dot-Product Attention 以及实际的使用示例。
二、机器翻译
在开始之前,我们先介绍一个自然语言处理的领域:机器翻译。
翻译是一种典型的序列到序列(Sequence to Sequence)问题,意思就是:
- 输入是一个长度可以改变的序列(例如一个中文句子。“今天天气很晴朗”)
- 输出是一个长度可以改变的序列(例如一个英文句子。“今天阳光明媚”)
假设今天 Transformer 还没有被发明,电脑会如何处理这类问题呢?
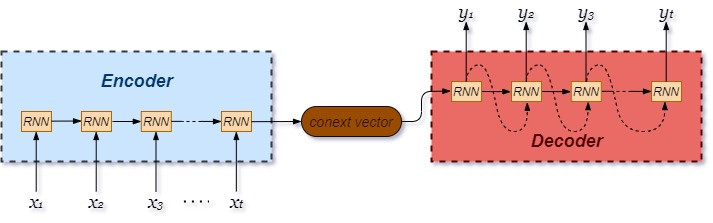
直觉上会想到的作法大概就像上面这张图一样,分为两个步骤:
- 把输入序列(中文句子)一个字一个字读完
在上面的表格中,每个 x 对应的就是一个字,而电脑会去读第一个字,读完后存起来,再读下一个字(先读「今」,再读「天」……),之后把所有资讯存在中间的上下文向量。 - 计算输出序列(中文句子)
输出时,模型会根据上下文向量存储的信息,一个字一个字的输出(“it”, “'s”, “sunny”, ……)。
实践上确实可以用这样的模型制作机器翻译,但是上面的例句很短,如果今天我希望机器处理长一点的输入(例如这篇文章),那么会遇到下面的问题:
- 上下文向量维度太小,把比较前面的字给忘了
- 读完前面才能读后面,速度很慢
针对这一个问题,下面的模型提出了解方
通过联合学习对齐和翻译进行神经机器翻译
这篇论文试图解决上面提出的第一点问题,概念其实很简单,既然 Context Vector 不可能存下整个输入句的信息,那我就在每次输出字的时候都看一遍整个句子就好了。
注意的做法就是在输出每个字的时候分别给输入的字每个一个权重,再让输入的句子做加权平均。
在下面的模型中,输入的每个字会被先转成隐藏状态(下面的h,可以想成词嵌入),然后模型根据目前翻译到的字和每个字各自的隐藏状态来计算Attention分数。
计算分数的函式会由模型自己学会。
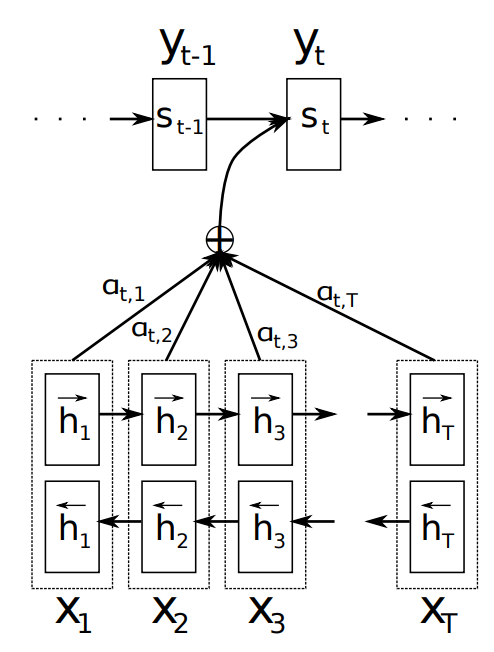
举例:假设现在模型已经输出“It's sunny”,准备要输出下一个字
但是在输出前,需要先确定哪些中文字对下一个输出来说比较重要,所以它用某个函数 α 来计算每个字该有的分数,α("sunny", 今) = 0.8, α (“晴”,天) = 0.6 ……
按理来说,下一个字是“今天”,所以输入中和「今天」两个字有关的部分会比较高分。
因此,在输出“今天”之前,每个中文字可能会有下面的分数。
- 「今」:0.8
- 「天」:0.6
- 「气」:0.05
- 「很」:0.01
- ……
接下来把「今」的隐藏状态乘上 0.8、把「天」的隐藏状态乘上 0.6 ……,接着把所有的隐藏状态加起来,用它来计算下一个输出的英文字应该是什么。
这个模型其实就是Attention的雏型,Attention的概念就是:
- 赋予输入每个字一个权重
- 将输入的字做加权计算
之后讲话注意的时候经常会提到三个东西,Query、Key 和 Value,虽然本文没有明确提到这三个词,但是从上面的模型架构已经可以看出一些端倪:
- 查询:翻译到的前一个字(“sunny”)
- Key、Value:每个字的隐藏状态
- 注意分数:α函式算出的分数
你可以用下面的句子来理解注意,对于现在的查询(正在翻译的英文字)来说,哪个键(中文字)最重要。
而在这个模型中,Value 和 Key 本质上是一样的东西。
三、结论
这篇文章详细介绍了Attention机制的起源,虽然现在在做自然语言处理时使用的大多不是这个模型,但是通过前面的介绍可以理解为什么需要推出这个机制,以及Attention的核心概念是什么。
下一篇文章将介绍现在大家使用缩放点积注意力的逻辑以及使用示例。欢乐哭泣