恶意软件是指恶意软件犯罪者用来感染个人计算机或整个组织的网络的软件。 它利用目标系统漏洞,例如可以被劫持的合法软件(例如浏览器或 Web 应用程序插件)中的错误。
恶意软件渗透可能会造成灾难性的后果,包括数据被盗、勒索或网络系统瘫痪。

在线工具推荐: Three.js AI纹理开发包 - YOLO合成数据生成器 - GLTF/GLB在线编辑 - 3D模型格式在线转换 - 可编程3D场景编辑器
1、为什么检测恶意软件很重要?
恶意软件是当今互联网上最严重的安全威胁之一。 事实上,大多数互联网问题(例如垃圾邮件和拒绝服务攻击)的根本原因都是恶意软件。 也就是说,受到恶意软件攻击的计算机通常会联网形成僵尸网络,并且许多攻击都是使用这些恶意的、攻击者控制的网络发起的。
为了应对新产生的恶意软件,需要采用新技术来检测它们并防止它们造成的任何损害。
2、为什么选择深度学习?
如今深度学习已经主导了各种计算机视觉任务。 这些深度学习技术不仅使本次比赛取得了快速进步,而且在许多比赛中甚至超越了人类的表现。 这些任务之一是图像分类。
与更传统的机器学习技术方法不同,深度学习分类器是通过特征学习而不是特定于任务的算法进行训练的。 这意味着机器将学习所呈现的图像中的模式,而不是要求人类操作员定义机器应在图像中寻找的模式。 简而言之,它可以自动提取特征并将数据分类为各种类别。
早期层学习如何检测边缘等低级特征,后续层将早期层的特征组合成更全面、更完整的表示。
我们可以使用后面描述的方法将恶意软件/良性文件转换为灰度图像。 然后我们可以将这些深度学习技术应用于生成的图像,将它们分类为恶意软件或良性图像。
3、如何将恶意软件变换为图像?
要使用深度学习模型对图像进行分类,我们需要来自良性文件和恶意软件文件的图像。 我们只会进行二元分类(恶意软件和良性类别)。 多类分类也可以使用这种技术来完成,其想法是恶意软件文件的变体将具有与其他文件不同的图像。
准备好数据集后,我们将通过对每个图像执行以下步骤将每个文件转换为 256x256 灰度图像(每个像素的值在 0 到 255 之间):
- 从文件中一次读取 8 位。
- 将8位视为二进制数,并将其转换为对应的整数。
- 输入数字作为像素值。
最大为 64 KB 的文件可以容纳 256 x 256 的图像。 任何大小超过 64 KB 的文件,其剩余内容将被删除。另一方面,如果文件大小小于 64 KB,则剩余图像将用 0 填充。
由于恶意软件检测是实时完成的,我们需要在几秒钟内将图像分类为良性或恶意软件。 因此,保持图像生成过程简单、简短将帮助我们节省宝贵的时间。
4、数据集的准备
这一步非常简单。 生成所有图像后,将它们分成两个文件夹 - 训练和验证。 每个文件夹都将包含两个文件夹,即恶意软件和良性文件夹。
将这两个文件夹存储在另一个名为“dataset.tar”的文件夹中,并压缩生成.tar 文件。
所以最终的目录结构将是→ dataset.tar 包含验证和训练。 验证将包含恶意软件和良性文件夹。 火车将有文件夹 Malware 和 Benign。
将压缩文件夹移动到包含代码的 Jupyter 笔记本所在的目录中。
5、深度模型实现
要从 Google 云端硬盘读取数据集,请添加以下代码行:
!pip install PyDrive #
import os
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
auth.authenticate_user()
gauth=GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)运行上述代码的最后 4 行后,Google SDK 会要求您输入验证码。 它会提到一个链接,点击它后,你将获得安全代码。
link = '1sL4I4xNh657AhrIOOwbr6TX58ahyC'(add the link here )创建一个变量,其中包含 .tar 文件的链接,该文件包含存储在 Google 云端硬盘中的数据。要获取 URL,请打开驱动器中的 .tar 文件并获取该文件的可共享链接。 你不需要整个 URL,只需要其中的一部分。
获取数据的路径:
downloaded = drive.CreateFile({'id':link})
downloaded.GetContentFile('dataset.tar')
import tarfile
tar = tarfile.open("dataset.tar")
path = tar.extractall('DS/')
tar.close()
path = Path.cwd().joinpath("DS/dataset/")
path.ls()
data = ImageDataBunch.from_folder(path, ds_tfms=get_transforms(), size=224)
## To view data in a batch
data.show_batch(rows=3, figsize=(7,6))
## To know the number of classes in a dataset
print(data.c)
## To know the names of the classes in a dataset
print( data.classes)创建模型:
learn = create_cnn(data, model.resnet34, metrics = error_rate)
## To know the model architecture
learn.model
## Training the model
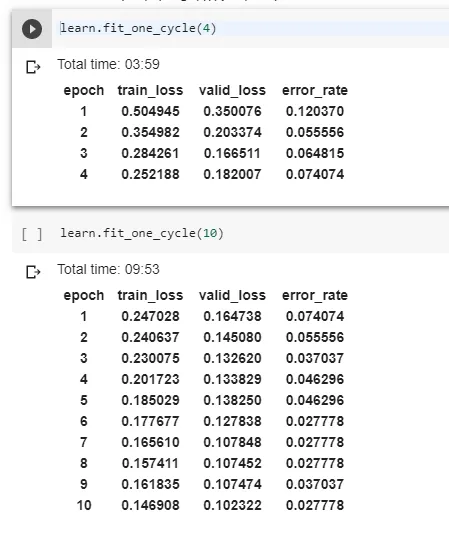
learn.fit_one_cycle(4)
learn.fit_one_cycle(10)这是运行上述代码后得到的输出的屏幕截图:
interp = ClassificationInterpretation.from_learner(learn)
losses,idxs = interp.top_losses()
interp.plot_top_losses(9,figsize=(9,6))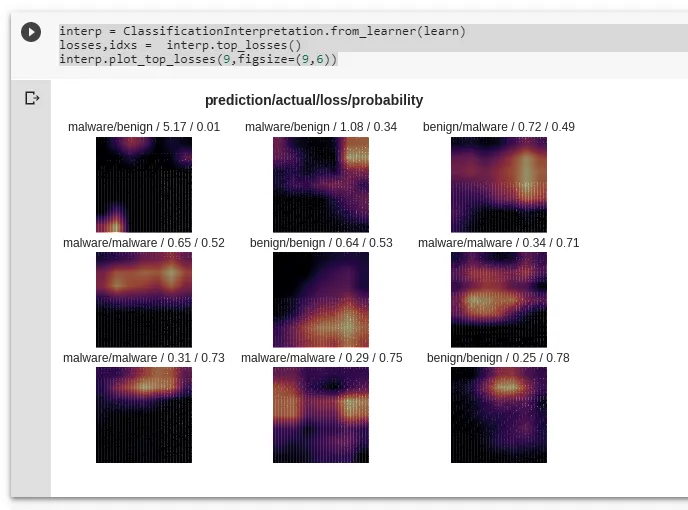
6、如何找到并设置一个好的学习率?
到目前为止,我们还没有告诉模型在训练模型时使用什么学习率,我们都知道这是训练时最重要的超参数之一。
为了找到良好的学习率,请执行以下操作:
learn.lr_find()
learn.recorder.plot()
learn.fit_one_cycle(5, max_lr=slice(1e-6,1e-4))
## Saving the weights of the model
learn.save('stage-1-malware-detection')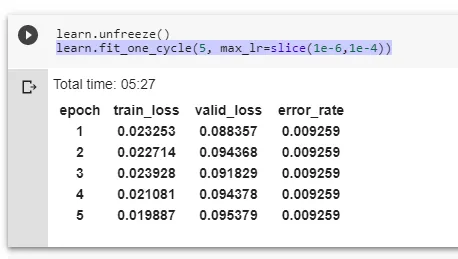
注意:每次调用 fit_one_cycle() 函数时,权重都不会重新初始化。 因此,如果依次调用该函数,则epoch会累加,这意味着如果你先调用 fit_one_cycle(5),然后调用 fit_one_cycle(10),则模型已训练了大约 15 个epoch。
完整的代码可以在我的 GitHub 帐户上找到。
原文链接:恶意软件检测实战 - BimAnt